
http://localhost:8888/lab/tree/%ED%8C%8C%EC%9D%B4%EC%8D%AC%209.16%20(9).ipynb
[ 15일 문제 복습 ]
- matc, search, findall, finditer 차이점. p298
match: 문자열 처음부터 검색
search: 문자열 전체를 검색
findall: 리스트로 돌려줌
finditer: 반복 가능한 객체를 돌려줌 interator 출력.
- match 메소드 4 가지. p301
: group,start,end,span()
- ['Life', 'is', 'too', 'short']. p298
import re
a = "Life is too short"
p = re.compile("[A-z]+")
print(p.findall(a))
- 정규식 문자클래스를 괄호안에 넣으시오. P294
[^a-zA-Z0-9_ ] : \W
- 정규식 문자클래스를 괄호안에 넣으시오. P294
\d : [0-9]
- 정규식을 사용하여 숫자만 출력해보시오. p298
data = """이름:김철수
전화번호 : 010-1234-1234
나이 : 30
성별 : 남 """
p = re.compile("\d+")
print(p.findall(data))
-> ['010', '1234', '1234', '30']
#(1)
s="black, blue and brown"
p = re.compile("black|blue")
print(p.findall(s))
[ 오전 수업 ]
[ 지문 크롤링, 정규표현식 ]
import urllib.request as req
import re
req. urlopen("http://daum.net")
data = req. urlopen("http://daum.net").read().decode("utf-8")정답:
data = req. urlopen("http://daum.net").read().decode("utf-8")
p = re.compile("https://\S+[.]js")
li = re.findall(p, data)
for i in li:
print(i)
순서(1)
# 아무것도 안나옴. 문장이 이어져있어서
p = re.compile(".js$")
li = re.findall(p, data)
for i in li:
print(i)
순서(2)
# .이 모든 걸로 나오는구나
p = re.compile(".js")
li = re.findall(p, data)
for i in li:
print(i) 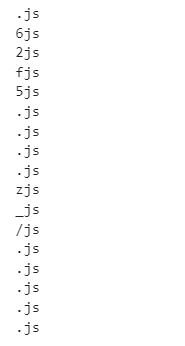
순서(3)
# .내가 생각하는 .이 나옴
p = re.compile("[.]js")
li = re.findall(p, data)
for i in li:
print(i)
순서(4)
# 또는으로 연결
p = re.compile("h[:./\w]*[.]js")
li = p.findall(data)
for i in li:
print(i)
순서(5)
# h만 있는거 없애줄려고
p = re.compile("https[:./\w]*[.]js")
li = p.findall(data)
for i in li:
print(i)
#세개밖에 안나와서 정답이 정답일듯하다.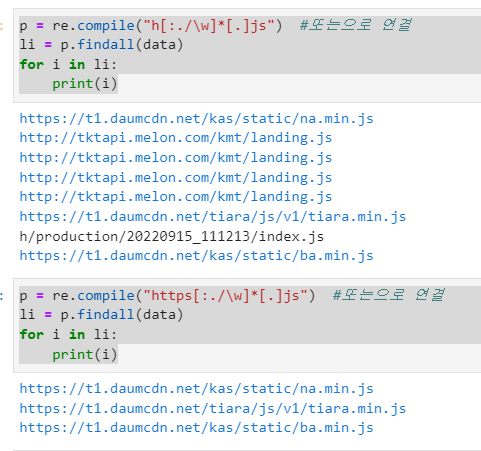
빵집문제{120} -> 미완성 정답 없음...
자주 쓰이는 패턴 문제 {전화번호242 ,이메일262, 주민번호424}
#전화번호
data = '010-1234-3434 '
p = re.compile('\d{3}-\d{3,4}-\d{4}')
print(p.findall(data))
-> ['010-1234-3434']
#이메일
data= '''prince@naver.com hello@daum.net morning@company.co.kr'''
a = re.compile(".+@[a-z]+[.][a-z]+")
li = a.findall(data)
for i in li:
print(i)
-> prince@naver.com hello@daum.net morning@company.co
a = re.compile("[\w]+@[0-9a-z]+[.][a-z.]+")
li = a.findall(data)
for i in li:
print(i)
-> prince@naver.com
hello@daum.net
morning@company.co.kr
#주민번호
data = '210202-2134765'
ii = re.compile("\d{6}[-][123456]\d{6}")
li = ii.findall(data)
li
-> ['210202-2134765']
i = re.compile("(\d{6})[-](\d{7})")
li = i.findall(data)
for i in li:
print(i)
-> ('210202', '2134765')[ 컴파일 옵션 p303 ]
- DOTALL(S) - . 이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
- IGNORECASE(I) - 대소문자에 관계없이 매치할 수 있도록 한다.
- MULTILINE(M) - 여러줄과 매치할 수 있도록 한다. (^, $ 메타문자의 사용과 관계가 있는 옵션이다)
- VERBOSE(X) - verbose 모드를 사용할 수 있도록 한다. (정규식을 보기 편하게 만들수 있고 주석등을 사용할 수 있게된다.)
- 옵션을 사용할 때는 re.DOTALL처럼 전체 옵션 이름을 써도 되고 re.S처럼 약어를 써도 된다.
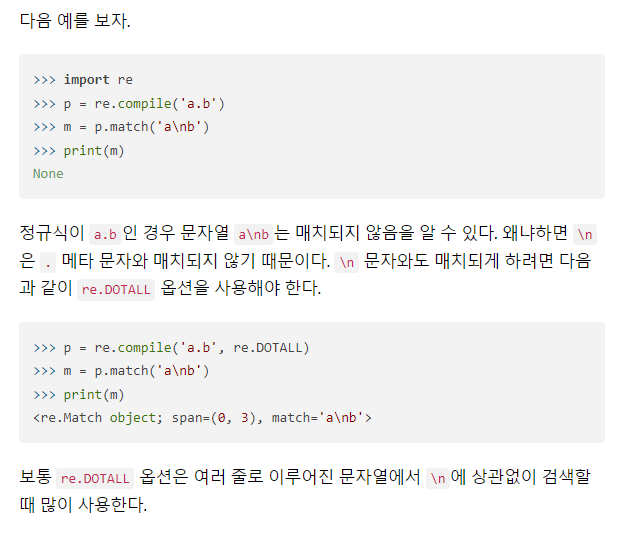
DOTALL, S
. 메타 문자는 줄바꿈 문자(\n)를 제외한 모든 문자와 매치되는 규칙이 있다.
만약 \n 문자도 포함하여 매치하고 싶다면 re.DOTALL 또는 re.S 옵션을 사용해 정규식을 컴파일하면 된다.
IGNORECASE, I
re.IGNORECASE 또는 re.I 옵션은 대소문자 구별 없이 매치를 수행할 때 사용하는 옵션이다

MULTILINE, M
re.MULTILINE 또는 re.M 옵션은 조금 후에 설명할 메타 문자인 ^, 와 연관된 옵션이다. 이 메타 문자에 대해 간단히 설명하자면 ^는 문자열의 처음을 의미하고, $는 문자열의 마지막을 의미한다. 예를 들어 정규식이 ^python인 경우 문자열의 처음은 항상 python으로 시작해야 매치되고, 만약 정규식이 python이라면 문자열의 마지막은 항상 python으로 끝나야 매치된다는 의미이다.
VERBOSE, X
지금껏 알아본 정규식은 매우 간단하지만 정규식 전문가들이 만든 정규식을 보면 거의 암호수준이다. 정규식을 이해하려면 하나하나 조심스럽게 뜯어보아야만 한다. 이렇게 이해하기 어려운 정규식을 주석 또는 줄 단위로 구분할 수 있다면 얼마나 보기 좋고 이해하기 쉬울까? 방법이 있다. 바로 re.VERBOSE 또는 re.X 옵션을 사용하면 된다.
http://localhost:8888/lab/tree/%ED%8C%8C%EC%9D%B4%EC%8D%AC%209.16%20(9).ipynb
{문제 166}
-['http', 'https', 'ftp']만 뽑아라.
->{165}
p = re.compile("\w+(?=://)")
p.findall(text)
{문제 172}
- ['50.24', '35.25', '100']만 뽑아라.
->{175}
p = re.compile('(?<=[$]).+')
p.findall(text)
{문제 188}
- ['이른 아침 문을 여는 빵집입니다',
'가볍게 아침을 해결하고자 하는 여행자나 현지인은 들러보면 좋을 장소입니다',
'참고로 식빵 나오는 시간은 오전시시 입니다']만 뽑아라.
-> {191}
p = re.compile("(?<=).+(?=
)")
p.findall(text)
[ 오후 수업 시작 ]
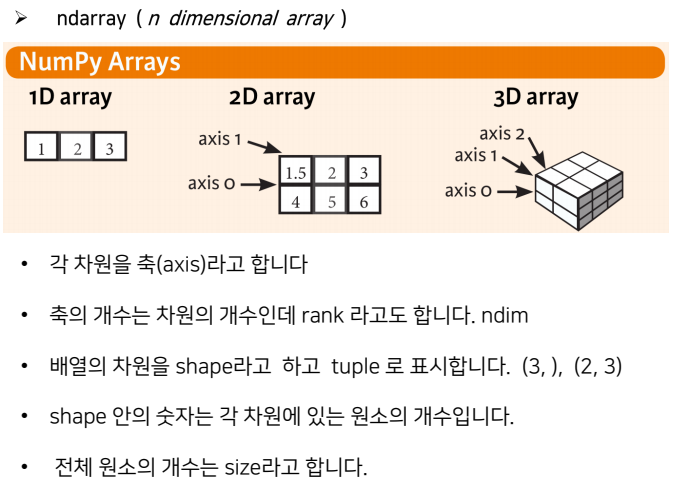
Numpy 개요
- numpy란, (numerical python, numeric python)
육각형의 상자, array:배열
1차원 2차원 3차원
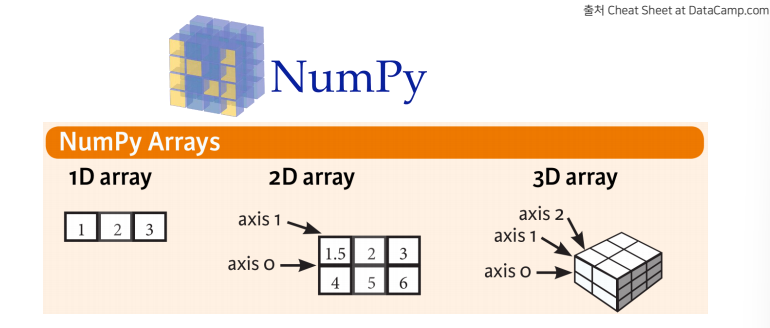
axis : 축
ex) (2,3) = (2행, 3열) / (axis0 , axis1)
-
numpy 왜 사용하냐?
:파이썬을 직접 하게 한다???. -
pandas:연산
pandas, sum -
numpy 특징
- list 보다 빠르다
- 반복문 안씀. 브로드케스팅 가능.
- 선형대수학, 푸리에 변환 및 난수 기능
- c/c++ 및 포트란 코드 통합
※ 참조
- 유투브
park 널널한 교수
teamlab x inflearn
1) import (p11)
import numpy as np
np.sum()
: 모듈(라이브러리)을 호출하여 속성과 메소드를 사용한다.
2) ndarray(배열이란)
#2개이상 숫자 들어가면 리스트로 묶어주어라
a=np.array([0,1,2,3])
a -> array([0, 1, 2, 3])
#1차원 자료 4개 들어있다.
print(a.shape)
-> (4,)
print(a.size) :원소의 개수
-> 4
type(a)
-> numpy.ndarray
print(a.dtype)
-> int32
- array 객체 속성

-numpy만의 데이터 타입

3) array(배열:숫자만 들어감) vs matrix(행렬: 2차원만 가능)
둘의 연산법이 다르다.
배열 만들기 {p24}
1차원 만들기
#1차원
import numpy as np
a=np.array([0,1,2,3])
a
-> array([0, 1, 2, 3])
#몇차원이냐
print(a.ndim)
-> 1
2차원 만들기, arange {p26}
#2차원
np.array([[1,2,3,4],[5,6,7,8]])
-> array([[1, 2, 3, 4],
[5, 6, 7, 8]])
#2행5열은 10 상태다. shape모양.
np.arange(10).reshape(2,5)
-> array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
#3행 4열은 12
np.arange(12).reshape(3,4)
-> array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
#-1은 자동으로 숫자 대입 의미
np.arange(12).reshape(3,-1)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])3차원 만들기 {p29}
#3차원
#종이 2장 3행 4열 임.
np.arange(24).reshape(2,3,4)
-> array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
#문제 {p31}
np.arange(36).reshape(3,4,3)
-> array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]],
[[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]],
[[24, 25, 26],
[27, 28, 29],
[30, 31, 32],
[33, 34, 35]]])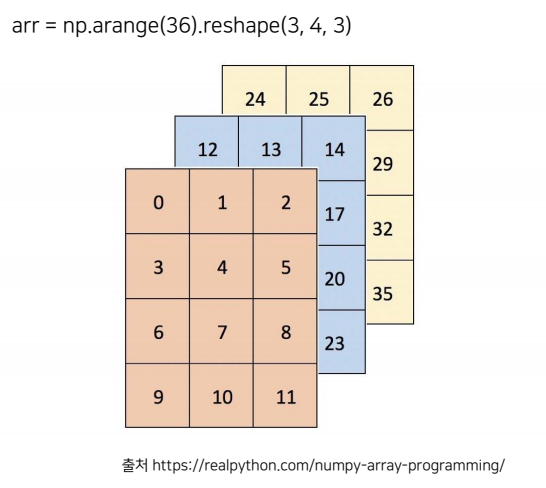
배열의 연산 (operation) {p32~p44}
element wise :원소들 끼리끼리
- 리스트의 연산과 비슷하지만 약간 다르다.
- numpy 함수를 쓰는 것보다
- numpy의 연산은 원소들끼리 이루어진다.
- arrat 형태가 안 맞으면, 자동으로 맞춰주기도 한다.(broadcasting)


문제 6x6 노란색만 뽑아주세요 {p100~p108}
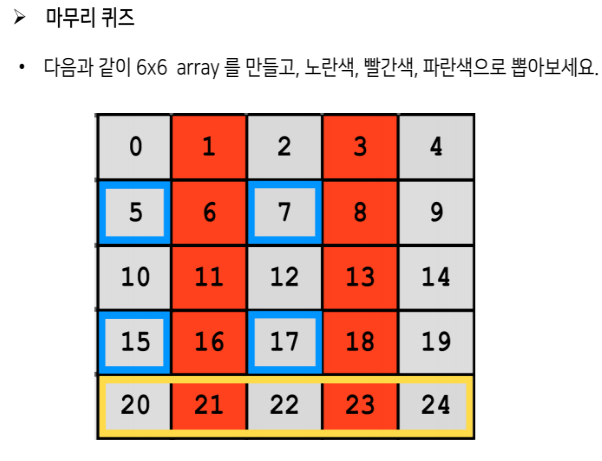
#노란색만 뽑아라
a=np.arange(25).reshape(5,5)
a[4]
->array([20, 21, 22, 23, 24])
#빨간줄만 뽑아라
a = np.arange(25).reshape((5, 5))
a[:,(1, 3)]
-> array([[ 1, 3],
[ 6, 8],
[11, 13],
[16, 18],
[21, 23]])
#파란칸만 뽑아라
a = np.arange(25).reshape((5, 5))
a[[1, 1, 3, 3], [0, 2, 0, 2]]
-> array([ 5, 7, 15, 17])
#만약 이거라면
a = np.arange(25).reshape((5, 5))
a[1::2, 0::2]
-> array([[ 5, 7, 9],
[15, 17, 19]])
출처:
https://walkingplow.tistory.com/32
https://wikidocs.net/4308#multiline-m -> 점프 투 파이썬
