앙상블 학습 개요
- 앙상블 학습(Ensemble Learning)을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말한다.
- 쉽고 편하면서도 강력한 성능을 보유하고 있는 것이 앙상블 학습의 특징
- 전통적으로 보팅(Voting):뽑기, 배깅(Bagging), 부스팅(Boosting)의 세 가지로 나눌 수 있으며, 이외에도 스태깅을 포함한 다양한 앙상블 방법이 있다.
- 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이다.
- 다른점은 보팅은 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는 방식이고, 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것이다.
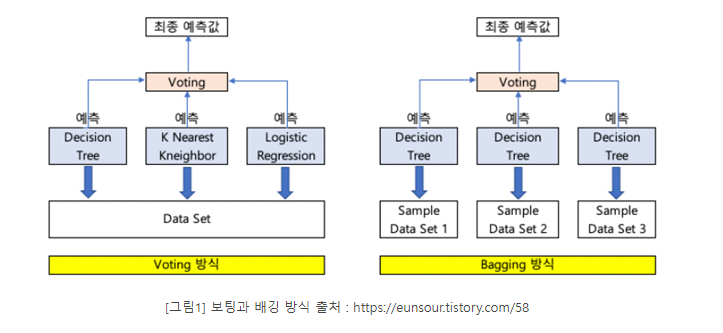
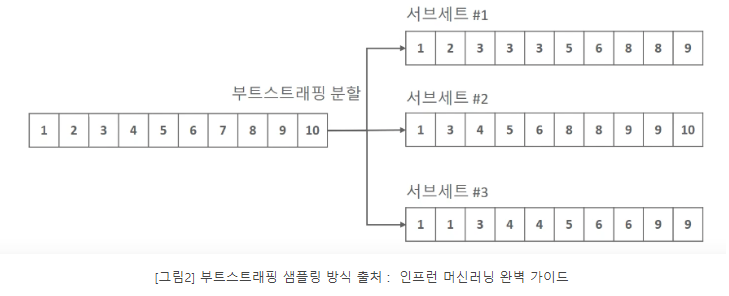
*개별 Classifier에게 데이터를 샘플링해서 추추랗는 방식을 부트스트래핑(Bootstrapping)분할 방식이라고 부른다.
개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적인 예측을 수행한 결과를 보팅을 통해서 최종 예측 결과를 선정하는 방식이 배깅 앙상블 방식
배깅 방식은 중첩을 허용
부스팅은 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에게는 가중치(weight)를 부여하면서 학습과 예측을 진행하는 것이다.

-
조건
- 각각의 분류기는 상호 독립적이어야 한다.
- 가 분류기의 오분률은 적어도 50%보다는 낮아야 한다.
% 독립성을 만족하지 않아도 예측력은 높아지는 것으로 알려져 있다.
-
장단점
- 이상치에 대한 대응력이 높아지고, 전체적인 분산을 감소시킴으로써 예측의 정확도가 올라간다고 알려져 있다.
- 모형의 투명성이 떨어지게 되어 해석하기 어려워진다.
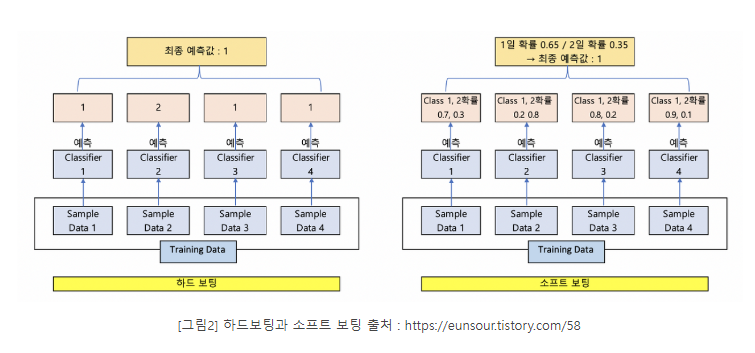
보팅 유형 - 하드 보팅(Hard Voting)과 소프트 보팅(Soft Voting)
- 하드 보팅을 이용한 분류는 다수결 원칙과 비슷하다.
- 소프트 보팅은 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다.
- 일반적으로 소프트 보팅 사용
보팅 분류기(Voting Classifier)
- 사이킷런은 보팅 방식의 앙상블을 구현한 VotingClassifier 클래스를 제공한다.
# 로지스틱 회귀와 KNN 기반 보팅 분류기
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_df.head(3)
# 보팅 분류기 생성
# 개별 모델은 로지스틱 회귀와 KNN
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier(estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='soft') # default는 HARD
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target,\
test_size=0.2, random_state=156)
# VotingClassifier 학습/예측 평가
vo_clf.fit(x_train, y_train)
pred = vo_clf.predict(x_test)
print('Voting 분류기 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))
# 개별 모델의 학습/예측/평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(x_train ,y_train)
pred = classifier.predict(x_test)
class_name = classifier.__class__.__name__
print('{0} 정확도 : {1:4f}'.format(class_name, accuracy_score(y_test, pred)))
랜덤 포레스트 개요 및 실습
- 배깅(bagging)은 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘
- 배깅의 대표적 알고리즘인 랜덤 포레스트
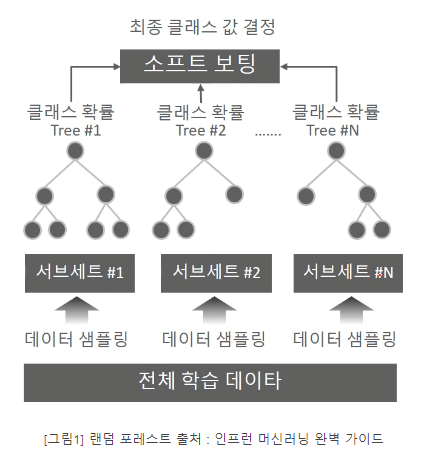
- 랜덤 포레스트는 개별적인 분류기의 기반 알고리즘은 결정 트리지이만 개별 트리가 학습하는 데이터세트는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트다.
- 여러 개의 데이터 세트를 중첩되게 분리하는 것을 부트스트래핑(bootstrapping) 분할 방식이라고 한다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings. filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset() 이용해 학습/ 테스트용 DataFrame 변환
x_train, x_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 세트로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state= 0)
rf_clf.fit(X_train, y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print("랜덤 포레스트 정확도 : {0:.4f}".format(accuracy))
GridSearchCV를 이용해 랜덤 포레스트의 하이퍼 파라미터를 튜닝
- n_estimators : 랜덤포레스트에서 결정 트리의 개수 지정한다. 디폴트는 10개, 많이 설정할수록 좋지만 무조건적은 아니고, 수행시간이 늘어난다.
- max_features는 결정 트리에 사용된 max_features 파라미터와 같다.
- max_depth나 min_samples_leaf와 같이 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터가 랜덤 포레스트에도 똑같이 적용될 수 있다.
GridSearchCV를 이용해 랜덤 포레스트의 하이퍼 파라미터를 튜닝
# GridSearchCV 이용해 하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6,8,10,12],
'min_samples_leaf' : [8,12,18],
'min_samples_split' : [8,16,20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터:\n ', grid_cv.best_params_)
print('최고 예측 정확도 : {0:.4f}'.format(grid_cv.best_score_))
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8,\
min_samples_split=8, random_state=0)
rf_clf1.fit(x_train, y_train)
pred = rf_clf1.predict(x_test)
print('예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))
막대그래프로 시각화
# 막대그래프로 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index=x_train.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature inmportances Top 20')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show()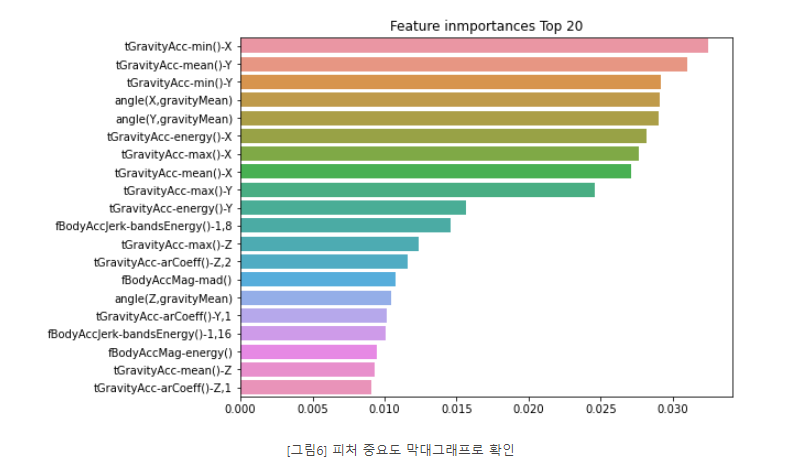
GBM의 개요 및 실습
- 부스팅 알고리즘은 여러 개의 약한 학습기(weak learner)를
순차적으로학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다. - 부스팅 대표적인 구현은 AdaBoost(Adaptive boosting)와 그래디언트 부스트가 있다.
- 에이다 부스트는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘이다.
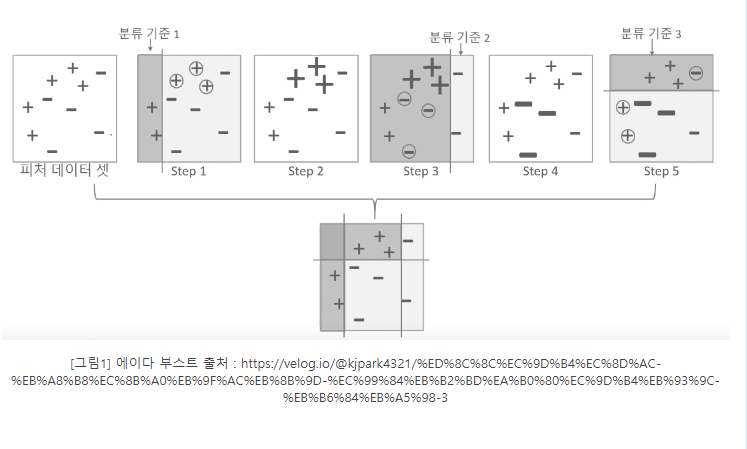
GBM(Gradient Boost Machine)
- 에이다 부스트와 유사하나, 가중치 업데이트를 경사 하강법(Grident Descent)을 이용하는 것이 큰 차이다.
- 오류 값은 실제 값 - 예측값이다.
- 오류식 h(x) = y - F(x)를 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것이 경사 하강법이다.
- '반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')
x_train, x_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(x_train ,y_train)
gb_pred = gb_clf.predict(x_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도 : {0:.4f}'.format(gb_accuracy))
print('GBM 수행 시간 : {0:.1f}초'.format(time.time() - start_time))GBM(Gradient Boost Machine)
- 에이다 부스트와 유사하나, 가중치 업데이트를 경사 하강법(Grident Descent)을 이용하는 것이 큰 차이다.
- 오류 값은 실제 값 - 예측값이다.
- 오류식 h(x) = y - F(x)를 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것이 경사 하강법이다.
- '반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train ,y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도 : {0:.4f}'.format(gb_accuracy))
print('GBM 수행 시간 : {0:.1f}초'.format(time.time() - start_time))예측 정확도 확인
# GridSearhCV를 이용해 최적으로 estimator로 예측 수행
gb_pred = grid_cv.best_estimator_.predict(x_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도 : {0:.4f}'.format(gb_accuracy))GBM 하이퍼 파라미터 및 튜닝
- loss : 경사 하강법에서 사용할 비용 함수 지정, default = 'deviance'
- learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률
- n_estimators : wark learner의 개수다.
- subsample : weak learner가 학습에 사용하는 데이터의 샘플링 비율
GirdSearchCV를 이용해 하이퍼 파라미터 최적화
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100,500],
'learning_rate' : [0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터 :\n', grid_cv.best_params_)
print('최고 예측 정확도 : {0:.4f}'.foramt(gird_cv.best_score_))XGBoost 개요
- 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나
- GBM 기반이지만, GBM 단점인 느린 수행 시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결해 각광받고 있다.
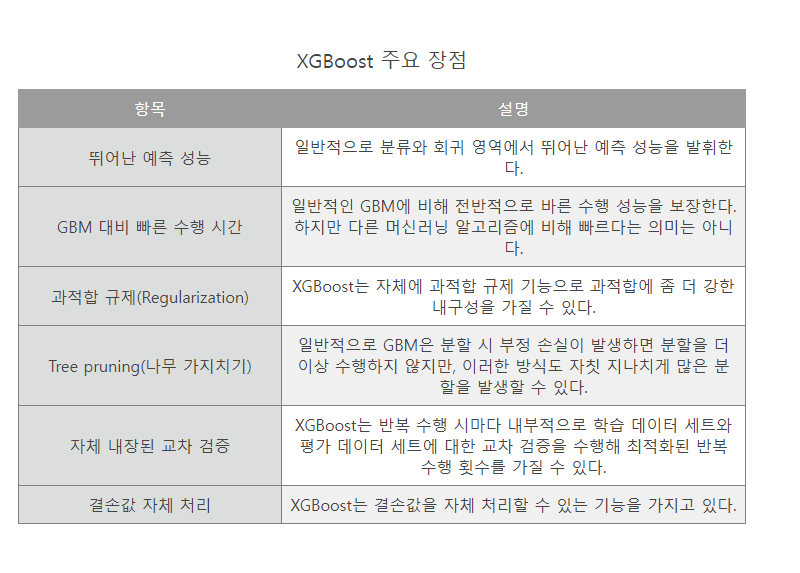
파이썬 래퍼 XGBoost 하이퍼 파라미터
- XGBoost는 GBM과 유사한 하이퍼 파라미터를 동일하게 가지고 있으며, 여기에 조기 중단(early stopping), 과적합을 규제하기 위한 하이퍼 파라미터 등이 추가되었다.
- 일반 파라미터 : 일반적으로 실행 시 스레드의 silent 모드 등의 선택을 위한 파라미터로서 디폴트 파라미터 값을 바꾸는 경우는 거의 없다.
- 부스터 파라미터 : 트리 최적화, 부스팅, regularization 등과 관련 파라미터 등을 지칭한다.
- 학습 태스크 파라미터 : 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정하는 파라미터다.
XGBoost 버전 확인
# XGBoost 버전 확인
import xgboost
print(xgboost.__version__)파이썬 래퍼 XGBoost 적용 - 위스콘신 유방암 예측
import xgboost as xgb
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
dataset = load_breast_cancer()
x_features = dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=x_features, columns=dataset.feature_names)
cancer_df['target'] = y_label
cancer_df.head(3)!pip install xgboost
import xgboost
from xgboost import XGBClassifier
# load_breast_cancer()로 내장 데이터 호출
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = .2, random_state= 156)
# 위에서 만든 X_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리함
X_tr,X_val,y_tr,y_val = train_test_split(X_train,y_train,test_size = .2, random_state= 156)
# Warning 메세지를 없애기 위해 eval_metric 값을 XGBClassifier 생성인자로 입력
xgb_wrapper = XGBClassifier(n_estimators= 400, learning_rate= 0.05, max_depth= 3,
eval_metric ="logloss")
xgb_wrapper.fit(X_train,y_train,verbose= True)
pred = xgb_wrapper.predict(X_test)
pred_proba = xgb_wrapper.predict_proba(X_test)[:,1]
# get_clf_eval()모델 예측 성능 평가
get_clf_eval(y_test, pred, pred_proba)
출처: https://asthtls.tistory.com/1273?category=904088 [포장빵의 IT:티스토리]

새싹 빅테이터 개발자