
ㄷ-ㄱ-ㄴ
콘텐츠 기반 필터링 실습 - TMDB 5000 영화 데이터 세트
장르 속성을 이용한 영화 콘텐츠 기반 필터링
콘텐츠 기반 필터링은 사용자가 특정 영화를 감상하고 그 영화를 좋아했다면, 그 영화와 비슷한 특성/속성, 구성요소를 가진 다른 영화를 추천하는 것입니다.
유사성을 판단하는 기준에는 장르, 감독, 배우 등이 있습니다.
콘텐츠 기반 필터링 추천 시스템을 영화 장르 속성을 기반으로 만들어 보겠습니다.
장르 칼럼 값의 유사도를 비교한 뒤 그 중 높은 평점을 가지는 영화를 추천하는 방식입니다.
데이터 로딩 및 가공
장르 속성을 이용해 콘텐츠 기반 필터링을 수행하겠습니다.
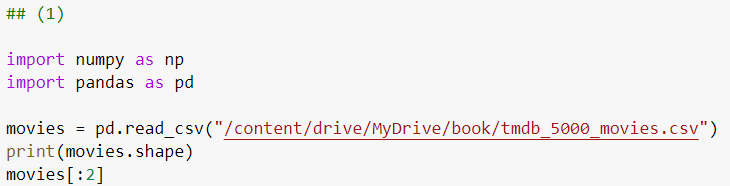
- shape (4803, 20) 나옴.
다양한 칼럼들 중 콘텐츠 기반 필터링 추천 분석에 사용할 주요 칼럼만 추출해 DataFrame으로 만들겠습니다.
추출할 주요 칼럼은 id, title, genres, vote_average(평균 평점), vote_count(평점 투표수), popularity(인기), keywords(영화를 설명하는 주요 키워드), overview(영화의 개요)입니다.

'genres', 'keywords'와 같은 칼럼은 [{"id": 28, "name": "Action"}, {"id": 12, "name": "Advanture"}]와 같은 list 내부에 여러 딕셔너리(dict)가 있는 형태의 문자열로 표기돼 있습니다.
이 칼럼이 DataFrame으로 만들어질 때는 단순히 문자열 형태로 로딩되므로 칼럼을 가공해 사용해야 합니다.
genres 칼럼에서 개별 장르의 명칭은 데이터 속 딕셔너리의 키(Key)인 'name'으로 추출할 수 있습니다. Keywords 역시 마찬가지의 구조를 가집니다. genres 칼럼의 문자열을 분해해서 개별 장르를 파이썬 리스트 객체로 추출하겠습니다.
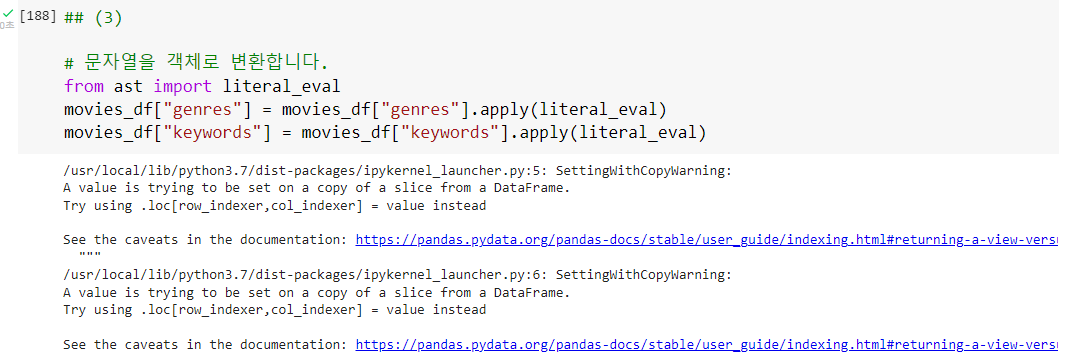
ast.literal_eval
ast 모듈의 literal_eval()함수를 이용하면 list[dict1, dict2] 객체로 만들 수 있습니다. Series 객체의 apply()에 literal_eval 함수를 적용합니다.
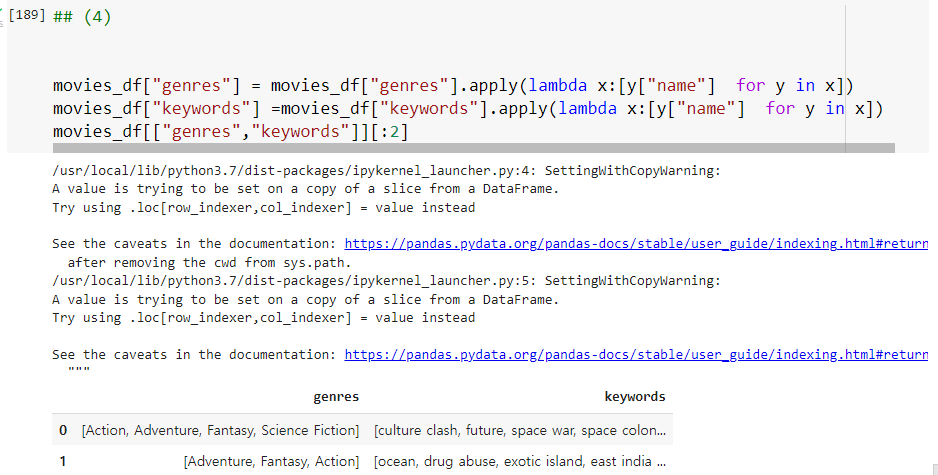
이제 genres 칼럼은 dict 객체들의 list로 구성돼있습니다. 이제 genres 칼럼에서 'name' 키에 해당하는 값을 추출하기 위해 apply lambda 식을 이용합니다.
장르 콘텐츠 유사도 측정
0번 영화의 genres 칼럼은 [Action, Adventure ...]로 되어 있습니다. 만약 1번 영화의 genres 칼럼과 장르별 유사도를 측정하려면 어떻게 해야할까요?
가장 간단한 방법은 genres를 문자열로 변경한 뒤 CountVectorizer로 피처 벡터화한 행렬 데이터 값을 코사인 유사도로 비교하는 것입니다. 이 과정을 정리하면 아래와 같습니다.
- 문자열로 변환한 genres 칼럼을 Count 기반으로 피처 벡터화 변환합니다.
- 피처 벡터화 행렬로 변환된 데이터 세트를 코사인 유사도를 통해 비교합니다. 이를 위해 레코드 별로 타 레코드와 장르에서 코사인 유사도 값을 가지는 객체를 생성합니다.
- 장르 유사도가 높은 영화 중에 평점이 높은 순으로 영화를 추천합니다.
리스트 객체 내의 개별 값을 연속된 문자열로 변환하려면 일반적으로 ('구분문자').join(리스트 객체)를 사용하면 됩니다.
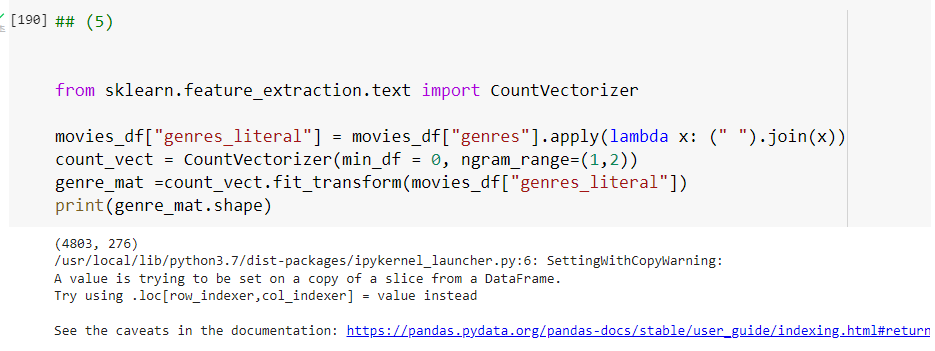
- shape(4803,276) 나온다.
4803개의 레코드(영화)와 276개의 단어 피처(칼럼)으로 구성된 피처 벡터 행렬이 만들어졌습니다. 이렇게 생성된 피처 벡터 행렬에 사이킷런의 cosine_siimilarity()함수로 코사인 유사도를 계산하겠습니다.
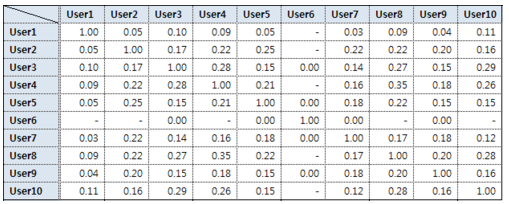
코사인 유사도는 위 사진과 같이 기준 행과 비교 행의 코사인 유사도를 행렬 형태로 반환합니다. 대각선은 자기 자신과의 유사도이므로 1이 나옵니다.

genre_sim은 데이터 행(레코드)별 유사도 정보를 가지고 있습니다.
즉, 영화와 영화 간에 얼마나 비슷한 장르를 가지고 있느냐를 담고 있습니다.
콘텐츠 기반 필터링을 수행하려면 개별 레코드에 대해서 가장 장르 유사도가 높은 순으로 다른 레코드를 추출해야하는데, 이를 위해 genre_sim 객체를 사용합니다.
genr_sim 객체의 기준 행별로 유사도가 높은 행(비교 행)의 인덱스값을 추출하면 됩니다. 유사도가 아니라 비교 대상 행의 인덱스임에 주의합니다.

반환값이 의미하는 것은 0번 레코드의 경우 3494번, 813번 ... 순으로 유사도가 높다는 뜻입니다.
genre_sin_sorted_ind를 통해 특정 레코드와 유사도가 높은 다른 레코드를 추출할 수 있습니다.
장르 콘텐츠 필터링을 이용한 영화 추천
장르 유사도에 따라 영화를 추천하는 함수를 생성하겠습니다.

find_sim_movie() 함수를 이용해 '대부'와 유사한 영화 10개를 추천해보겠습니다.

The Godfather: 2, Goodfellas도 대부와 비슷한 유형으로 추천할만한 영화입니다.
하지만, Light Sleeper, kids 같은 영화는 대부를 좋아하는 사람에게 추천할만한 영화는 아닙니다.
Mi America는 평점이 0점인 영화로 조금 더 개선이 필요해 보입니다.
이번에는 좀 더 많은 후보군을 선정한 뒤 영화의 평점에 따라 필터링하는 방식을 최종 방식으로 정하겠습니다.
주의해야할 점은 'vote_average' 칼럼값을 이용해를 오름차순으로 정렬할 경우, 소수의 관객이 추천한 영화는 만점이 나올 확률이 높다는 문제점이 있습니다.
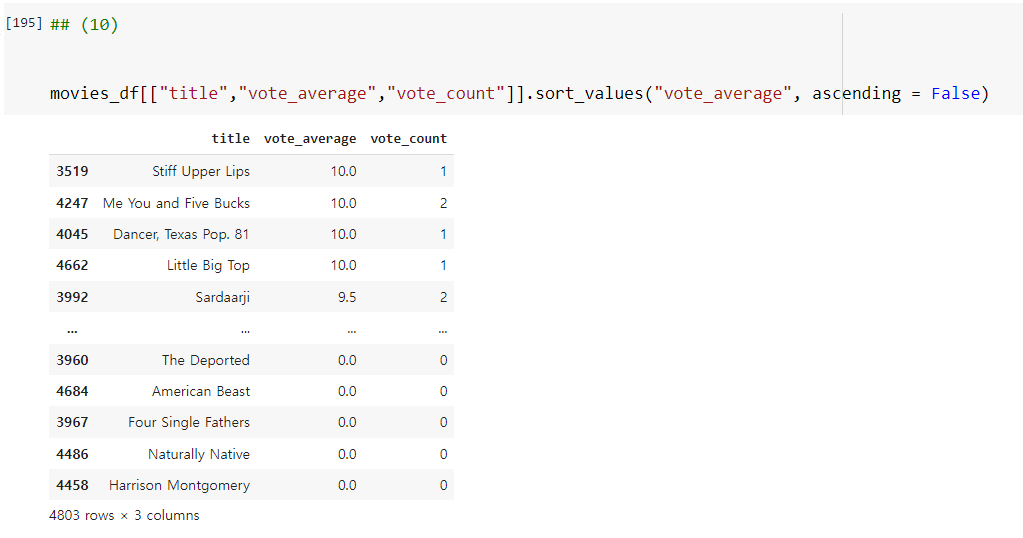
'쇼생크 탈출', '대부'보다 이름도 들은 적 없는 영화가 더 높은 평점을 가지고 있습니다.
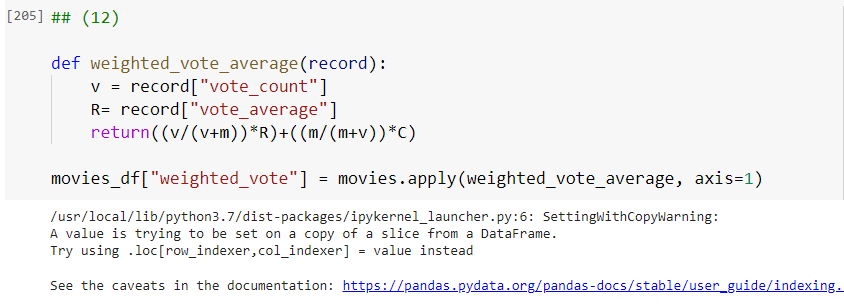
이런 문제를 해결하기 위해 IMDB 사에서는 평가 횟수에 대한 가중치를 부여한 가중 평점을 사용합니다. 가중 평점 공식은 다음과 같습니다.

- v는 movies_df의 vote_count 칼럼값이며,
- R값은 vote_average 칼럼값입니다.
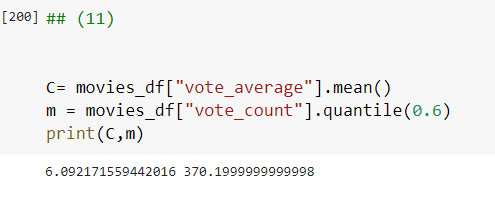
- C는 movies_df['vote_average'].mean()이고,
- m은 투표 횟수가 많은 영화에 더 많은 가중 평점을 부여하는 상수입니다.
m값은 전체 투표 횟수에서 상위 60%에 해당하는 횟수를 기준으로 하겠습니다. Series.quantile()을 이용해 추출합니다.
기존 평점을 가중 평점으로 바꾸는 함수 weighted_vote_average() 함수를 만들겠습니다.
가중 평점 weighted_vote 평점이 높은 순으로 상위 10개의 영화를 추출해보겠습니다.
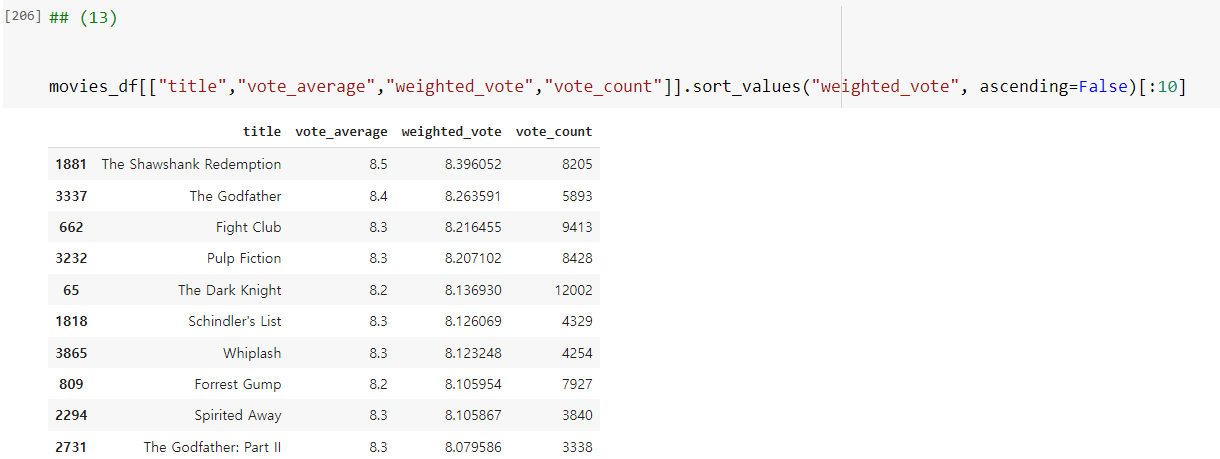
모두 유명한 영화들로 출력됐습니다. Spirited Away는 센과 치히로의 행방불명입니다.
find_sim_movie() 함수를 top_n의 2배수만큼 후보군을 추출하고 weighted_vote 칼럼값 순으로 정렬한 후 top_n 수만큼 영화를 출력하는 함수로 변경하겠습니다.
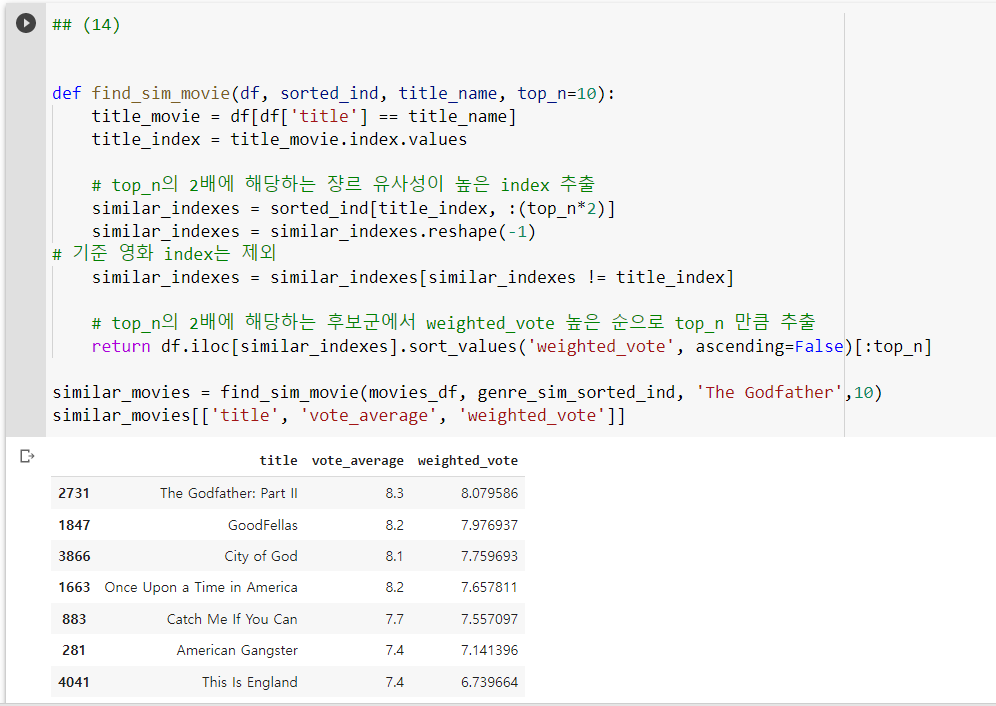
이전에 추천된 영화보다 더 나은 영화가 추천됐습니다.
특히 'Once Upon a Time in America'는 대부를 좋아하는 사람이라면 대부분 좋아하는 영화입니다.
하지만, 장르만으로는 개인의 성향을 반영하기엔 무리가 있습니다.
아마 좋아하는 감독, 배우를 보고 영화를 선택하는 경우가 더 많을 것인데, 장르 뿐 아니라 감독, 배우 등을 통해 더 다양한 콘텐츠를 기반으로 하는 알고리즘으로 확장시킬 수 있을 것입니다.
surprise p630
surprise 라이브러리를 설치한다. pip와 conda 모두 지원한다.
conda install -c conda-forge scikit-surprise
pip install surprise
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
예제로 내장된 무비렌즈(MovieLens) 데이터를 불러온다. 최초로 불러올 때 데이터를 다운로드 받을 것인지 물어보는데, 이때 Y를 입력한다.
data = Dataset.load_builtin("ml-100k")
출처:
https://live-with-wisdom.tistory.com/27
https://live-with-wisdom.tistory.com/28
파이썬 머신러닝 완벽 가이드(권철민)
https://choi-kyumin.tumblr.com/post/91364657580
https://joyfuls.tistory.com/57?category=731429
