Day57일때 휴가 냈음. 하루 수업 못들음..!
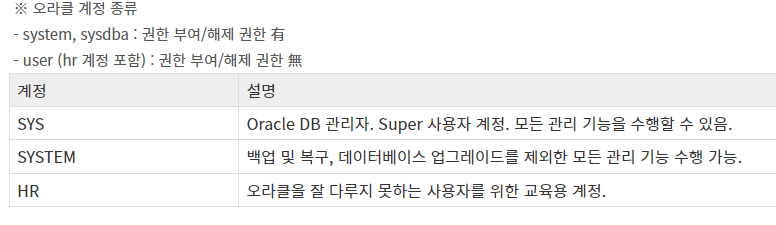
SQL의 종류
SQL : 구조화된 질의 언어. 오라클에 사용됨.
DCL: 데이터 제어 언어
-->
- GRANT : 권한 부여
- REVOKE : 권한 해제

TCL(Transaction Control Languge): 트랜잰션 언어 P302
일괄처리 INSERT, UPDATE,DELETE에서만 사용.
-->
- COMMIT : 정상적으로 저장, 트랜잭슨 작업을 데이터베이스에 영구히 반영.
- ROLLBACK :취소, 지금까지 한 작업을 취소할때

DML(Data Manipulation Language): 데이터 조작어
단위 : Row 단위 (가로줄)
DML만 COMMIT/ROLLBACK가능. 나머지 안됨.
--> [ CRUD ]
- select : 데이터 검색
- insert : 데이터 추가
- update,: 데이터 수정
- delete : 데이터 삭제
DDL(Data Definition Language): 데이터 정의어
단위 : column (세로줄)
-->
- CREATE TABLE : 생성
- ALTER TABLE : 수정(MODIFY), 삭제(DROP), 추가(ADD)
- RENAME TABLE : 테이블 명, 칼럼명 변경
- DROP TABLE : 테이블의 구조 자체를 삭제
- TRUNCATE : 테이블의 구조는 남겨두고 데이터만 전부 삭제
11장. 트랜잭션 제어와 세션 P290
-
트랜잭션이란? P291
: 더 이상 분할할 수 없는 최소 수행 단위 -
세션이란? P298
:데이터베이스 접속 시작부터 접속이 종료되기까지의 전체 기간 -
읽기 일관성의 중요란? P299
: 현재 트랜잭션이 종료될 때까지 다른 세션에서는 데이터 조작 전 상태의 데이터만 조회할 수 있는 특성
12장. 데이터 정의어 P310
- 데이터 정의어란? P311
: 데이터베이스 데이터를 보관하고 관리하기 위해 제공되는 여러 객체의 생성,변경,삭제 관련 기능을 수행합니다.
DDL
- CREATE TABLE : 테이블을 생성하는
- ALTER TABLE : 테이블을 변경하는
- RENAME TABLE : 테이블의 이름을 변경하는
- DROP TABLE : 테이블을 삭제하는
13장. 객체 종류 P324
-
데이터 사전이란? P327
: 데이터베이스 메모리.성능.사용자.권한.객체 등 오라클 데이터베이스 운영에 중요한 데이터가 보관되어있다. -
인덱스란? P334
: 테이블 열에 사용하는 객체 -
뷰란? P338
: 가상의 테이블, 하나 이상의 테이블을 조회하는 SELECT문을 저장한 객체를 뜻합니다. -
스퀀스란? P348
: 오라클 데이터베이스에서 특정 규칙에 맞는 연속 숫자를 생서어하는 객체입니다. -
동의어란? P354
: 테이블, 뷰, 시퀀스 등 객체 이름 대신 사용할 수 있는 다른 이름을 부여하는 객체입니다.
14장. 제약조건(CONSTRAINT) P359
: 제약 조건이란 데이터의 무결성을 지키기 위해 제한된 조건을 의미한다, 테이블의 특정 열을 지정한다.
쉽게 말해 테이블이나 속성에 부적절한 데이터가 들어오는 것을 사전에 차단하도록 정해 놓은 것이라 생각하면 된다.
제약조건의 종류 P360
- NOT NULL: NULL을 허용하지 않는다. P362
- UNIQUE: 지정한 열에 NULL 값을 제외한 값의 중복이 불가능하다. P370
- CHECK : 데이터 형태와 범위를 지정한다. P390
- PRIMARY KEY : NULL 값과 데이터 붕복을 모두 허용하지 않다. P377
- FOREIGN KEY : 다른 테이블을 참조하는 P382
- DEFAULT : 기본값을 지정한다. P392
데이터의 무결성 P361
-
영역 무결성 : 열에 지정되는 값의 적정 여부확인. 자료형, 적절한 형식의 데이터, NULL여부 같은 정해 놓은 범위를 만족하는 데이터임을 규정.
-
개체 무결성 : 테이블 데이터를 유일하게 식별할 수 있는 기본키는 반드시 값을 가지고 있어야 하며 NULL이 될 수 없고 중복될 수도 없음을 규정.
-
참조 무결성 : 참조 테이블의 외래키 값은 참조 테이블의 기본키로서 존재해야 하며 NULL이 가능.
제약 조건 조회
:제약조건을 조회하는 방법에는 여러가지가 존재하는데, 다 알 필요는 없지만 보통 다음과 같다.
- all_constraints, dba_constraints 이 두 개가 비슷한 내용을 품고 있다.
- user_constraints를 일반적으로 많이 사용한다.
제약 조건 삭제
제약조건을 삭제하기 위해서는 제약조건명이 필요한데, 나중에 보면 알겠지만 컬럼 옆에 써주는 것보다 따로 추가해주는 방식을 선호한다. PK(기본키)나 FK(외래 키) 같은 경우에는 말이다.
ALTER TABLE [테이블명] DROP CONSTRAINT [제약조건명]
PRIMARY KEY
어떤 테이블이든 거의 무조건 하나는 들어간다 생각되는 기본키이다.
- 기본키 역시 기본적으로 다른 제약조건과 마찬가지로 테이블을 생성할 때 같이 정의한다.
- 테이블당 하나만 정의 가능하다. (두개 이상의 기본키는 조합키/복합키 라고 불린다.)
- PK는 NOT NULL + UNIQUE의 기능을 가지고 있다.
- 주키 / 기본키 / 식별자 등 다양한 명칭으로 불리고 있다.
- 자동 INDEX가 생성되는데, 이는 검색키로서 검색 속도를 향상시키는 역할을 한다.
테이블을 생성하며 제약조건 지정하기
CREATE TABLE TABLE_PK(
LOGIN_ID VARCHAR2(20) PRIMARY KEY,
LOGIN_PWD VARCHAR2(20) NOT NULL,
TEL VARCHAR2(20)
);
DESC TABLE_PK;FOREIGN KEY
:외래키 역시 PK와 마찬가지로 매우 중요한 제약조건이다.
- 외부키, 외래키, 참조키, 외부 식별자 등으로 불리며 흔히 FK라고도 한다.
- FK가 정의된 테이블을 자식 테이블이라고 칭한다.
- 참조되는 테이블 즉, PK가 있는 테이블을 부모 테이블이라 한다.
- 부모 테이블의 PK 컬럼에 존재하는 데이터만 자식 테이블에 입력할 수 있다.
- 부모 테이블은 자식의 데이터나 테이블이 삭제된다고 영향을 받지 않는다.
- 참조하는 데이터 컬럼과 데이터 타입이 반드시 일치해야 한다.
- 참조할 수 있는 컬럼은 기본키(PK)나 UNIQUE만 가능하다.(보통 PK랑 엮는다.)
제약조건을 추가할 때 사용되는 구문은 다음과 같다.
ON DELETE CASCADE
참조되는 부모 테이블 행에 대한 DELETE를 허용한다.
즉, 참조되는 부모 테이블 값이 삭제되면 연쇄적으로 자식 테이블 값 역시 삭제된다는 의미이다.
ON DELETE SET NULL
참조되는 부모 테이블 행에 대한 DELETE를 허용한다.
이건 CASCADE와는 다른데, 부모 테이블의 값이 삭제되면 해당 참조하는 자식 테이블의 값들이 NULL로 설정되는 옵션이다.
일반적으로 ON DELETE CASCADE 옵션을 많이 사용한다.
해당 옵션을 사용하지 않으면 엮여있는 모든 자식 테이블의 값을 먼저 다 지워줘야 하기 때문이다.
15장. 사용자,권한,롤 관리 P395
(1) 사용자 관리
-
사용자(USER): 데이터베이스에 접속하여 데이터를 관리하는 계정
-
스키마(SCHEMA): 데이터베이스의 접속한 사용자와 연결된 객체
※ 사용자와 스키마를 연동하여 사용하기도 함. -
계정,사용자이름, 스키마, 계정, 케이블, 인덱스
(2) 권한관리
- 데이터베이스는 접속 사용자에 따라 접근 할 수 있는 데이터 영역과 권한을 지정해 줄 수 있는데, 오라클에서는 권한을 시스템 권한(SYSTEM PRIVILEGE)과 객체 권한(OBJECT PRIVILEGE)으로 분류하고 있다.
(롤)
- 롤 : 여러 종류의 권한을 묶어 놓은 그룹을 뜻한다.
- CONNECT 롤 : 사용자가 데이터베이스에 접속하는데 필요한 CREATE SESSION 권한을 가지고 있다.
- RESOURCE 롤 : 사용자가 테이블, 시퀸스를 비롯한 여러 객체를 생성할 수 있는 기본 시스템 권한을 묶어 놓은 롤.
1. MADANG 사용자를 만들어 주세요.
(1)SYSTEM에서
CREATE USER MADANG
IDENTIFIED BY MADANG;
GRANT CONNECT, RESOURCE TO MADANG;2. BOOKS라는 테이블을 만들어 주세요. 칼럼은 BNAME, PUB
(2)MADANG에서
CREATE TABLE BOOKS(
BNAME VARCHAR2(40),
PUB VARCHAR2(40)
);SQL>@demo_madang.sql; , 선생님이 주신 파일.
-- 처음 실행시는 아래 4문장의 오류는 무시한다. DROP TABLE Orders ; DROP TABLE Book ; DROP TABLE Customer ; DROP TABLE Imported_Book ; CREATE TABLE Book ( bookid NUMBER(2) PRIMARY KEY, bookname VARCHAR2(40), publisher VARCHAR2(40), price NUMBER(8) ); CREATE TABLE Customer ( custid NUMBER(2) PRIMARY KEY, name VARCHAR2(40), address VARCHAR2(50), phone VARCHAR2(20) ); CREATE TABLE Orders ( orderid NUMBER(2) PRIMARY KEY, custid NUMBER(2) REFERENCES Customer(custid), bookid NUMBER(2) REFERENCES Book(bookid), saleprice NUMBER(8) , orderdate DATE ); -- Book, Customer, Orders 데이터 생성 INSERT INTO Book VALUES(1, '축구의 역사', '굿스포츠', 7000); INSERT INTO Book VALUES(2, '축구아는 여자', '나무수', 13000); INSERT INTO Book VALUES(3, '축구의 이해', '대한미디어', 22000); INSERT INTO Book VALUES(4, '골프 바이블', '대한미디어', 35000); INSERT INTO Book VALUES(5, '피겨 교본', '굿스포츠', 8000); INSERT INTO Book VALUES(6, '역도 단계별기술', '굿스포츠', 6000); INSERT INTO Book VALUES(7, '야구의 추억', '이상미디어', 20000); INSERT INTO Book VALUES(8, '야구를 부탁해', '이상미디어', 13000); INSERT INTO Book VALUES(9, '올림픽 이야기', '삼성당', 7500); INSERT INTO Book VALUES(10, 'Olympic Champions', 'Pearson', 13000); INSERT INTO Customer VALUES (1, '박지성', '영국 맨체스타', '000-5000-0001'); INSERT INTO Customer VALUES (2, '김연아', '대한민국 서울', '000-6000-0001'); > INSERT INTO Customer VALUES (3, '장미란', '대한민국 강원도', '000-7000-0001'); INSERT INTO Customer VALUES (4, '추신수', '미국 클리블랜드', '000-8000-0001'); INSERT INTO Customer VALUES (5, '박세리', '대한민국 대전', NULL); -- 주문(Orders) 테이블의 책값은 할인 판매를 가정함 INSERT INTO Orders VALUES (1, 1, 1, 6000, TO_DATE('2014-07-01','yyyy-mm-dd')); INSERT INTO Orders VALUES (2, 1, 3, 21000, TO_DATE('2014-07-03','yyyy-mm-dd')); INSERT INTO Orders VALUES (3, 2, 5, 8000, TO_DATE('2014-07-03','yyyy-mm-dd')); INSERT INTO Orders VALUES (4, 3, 6, 6000, TO_DATE('2014-07-04','yyyy-mm-dd')); INSERT INTO Orders VALUES (5, 4, 7, 20000, TO_DATE('2014-07-05','yyyy-mm-dd')); INSERT INTO Orders VALUES (6, 1, 2, 12000, TO_DATE('2014-07-07','yyyy-mm-dd')); INSERT INTO Orders VALUES (7, 4, 8, 13000, TO_DATE( '2014-07-07','yyyy-mm-dd')); INSERT INTO Orders VALUES (8, 3, 10, 12000, TO_DATE('2014-07-08','yyyy-mm-dd')); INSERT INTO Orders VALUES (9, 2, 10, 7000, TO_DATE('2014-07-09','yyyy-mm-dd')); INSERT INTO Orders VALUES (10, 3, 8, 13000, TO_DATE('2014-07-10','yyyy-mm-dd')); -- 여기는 3장에서 사용되는 Imported_book 테이블 CREATE TABLE Imported_Book ( bookid NUMBER , bookname VARCHAR(40), publisher VARCHAR(40), price NUMBER(8) ); INSERT INTO Imported_Book VALUES(21, 'Zen Golf', 'Pearson', 12000); INSERT INTO Imported_Book VALUES(22, 'Soccer Skills', 'Human Kinetics', 15000); COMMIT;
마당 질문들
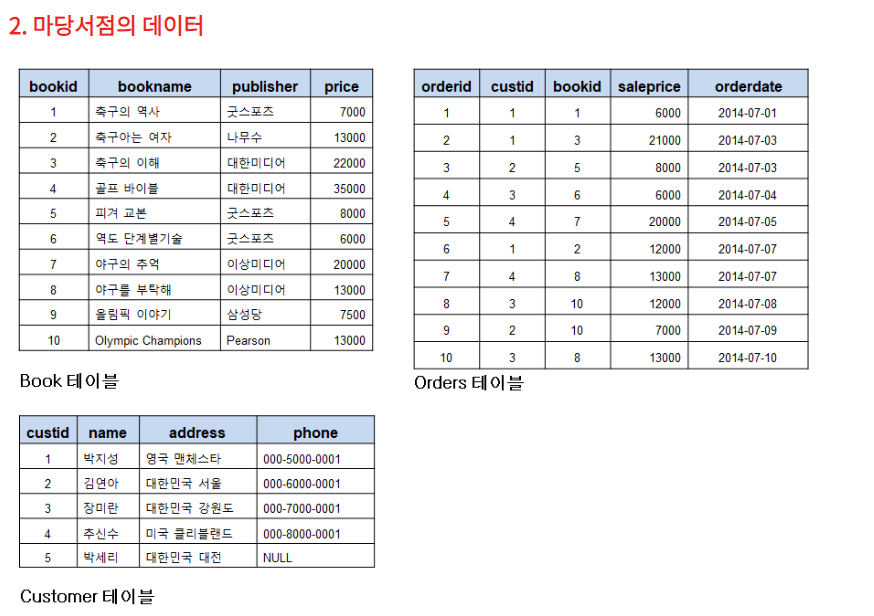



1. 마당서점의 고객이 요구하는 다음 질문에 대해 작성하시오.
(1) 도서번호가 1인 도서의 이름은?
SELECT BOOKNAME
FROM BOOK
WHERE BOOKID = 1;
(2) 가격이 20,000원 이상인 도서의 이름은?
SELECT * FROM BOOK
WHERE PRICE>=20000;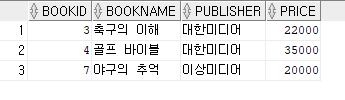
(3) 박지성의 책값의 합은?
SELECT SUM(SALEPRICE)
FROM CUSTOMER C JOIN ORDERS O USING (CUSTID)
WHERE CUSTID = 1; SELECT SUM(O.SALEPRICE)
FROM ORDERS O, CUSTOMER C
WHERE O.CUSTID = C.CUSTID AND C.NAME = '박지성'; SELECT*FROM CUSTOMER;
SELECT*FROM ORDERS;
SELECT *FROM BOOK;SELECT SUM(SALEPRICE)
FROM ORDERS
WHERE CUSTID =1;SELECT CUSTID
FROM CUSTOMER
WHERE NAME ='박지성'; (4) 박지성이 구매한 도서의 수
SELECT COUNT(*)
FROM ORDERS O, CUSTOMER C
WHERE O.CUSTID = C.CUSTID
AND C.NAME = '박지성'; 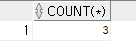
(5) 박지성이 구매한 도서의 출판사 수
-- (1)번 방법
SELECT COUNT(PUBLISHER)
FROM BOOK B, ORDERS O
WHERE B.BOOKID = O.BOOKID
AND O.CUSTID = (SELECT CUSTID
FROM CUSTOMER
WHERE NAME = '박지성');-- (2)번 방법
SELECT COUNT(*) AS CNT
FROM CUSTOMER C ,ORDERS O
WHERE C.CUSTID=O.CUSTID
AND C.NAME LIKE'%박지성%'
GROUP BY C.NAME; --(3)번 방법
SELECT COUNT(DISTINCT PUBLISHER)
FROM BOOK B, ORDERS O, CUSTOMER C
WHERE B.BOOKID = O.BOOKID
AND O.CUSTID = C.CUSTID
AND C.NAME= '박지성'; -- (4)번 방법
SELECT UNIQUE PUBLISHER
FROM CUSTOMER JOIN ORDERS USING (CUSTID)
JOIN BOOK USING (BOOKID)
WHERE NAME = '박지성'; 
마당서점의 운영자와 경영자가 요구하는 다음 질문에 대해 SQL문을 작성하시오.
(1) 마당서점 도서의 총 개수
SELECT COUNT(BOOKID)FROM BOOK;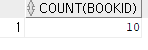
(2) 마당서점에 도서를 출고하는 출판사의 총 개수
SELECT COUNT(DISTINCT PUBLISHER) FROM BOOK; 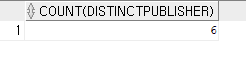
(3) 모든 고객의 이름, 주소
SELECT NAME, ADDRESS
FROM CUSTOMER;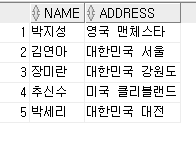
(4) 2014-7-4~ 7-7일 사이에 주문 받은 도서의 주문번호?
--(1)번 방법
SELECT ORDERID
FROM ORDERS
WHERE ORDERDATE BETWEEN '2014/07/04' AND '2014/07/07'; --(2)번 방법
SELECT ORDERID, ORDERDATE
FROM ORDERS
WHERE ORDERDATE BETWEEN TO_DATE('2014/07/04') AND TO_DATE('2014/07/07'); --(3)번 방법
SELECT ORDERID
FROM ORDERS
WHERE ORDERDATE BETWEEN TO_DATE('2014-07-04', 'YYYY-MM-DD')
AND TO_DATE('2014-07-07', 'YYYY-MM-DD'); 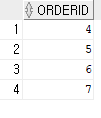
(5) 성이 김씨인 고객의 이름과 주소
SELECT NAME,ADDRESS
FROM CUSTOMER
WHERE NAME LIKE ('김%');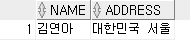
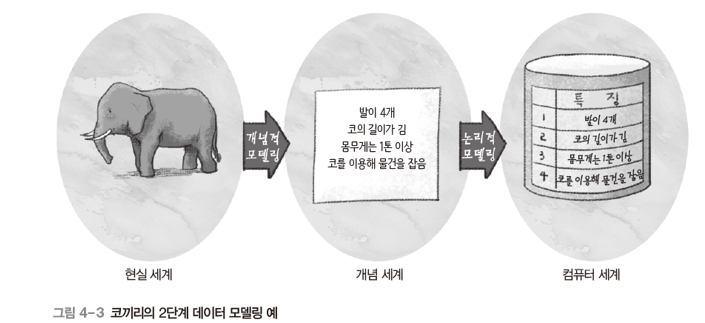
2단계 데이터 모델링
-
개념적 데이터 모델링(conceptual modeling)
: 현실 세계의 중요 데이터를 추출하여 개념 세계로 옮기는 작업, 데이터베이스 설계의 핵심 과정 -
논리적 데이터 모델링(logical modeling)
: 개념 세계의 데이터를 데이터베이스에 저장하는 구조로 표현하는 작업
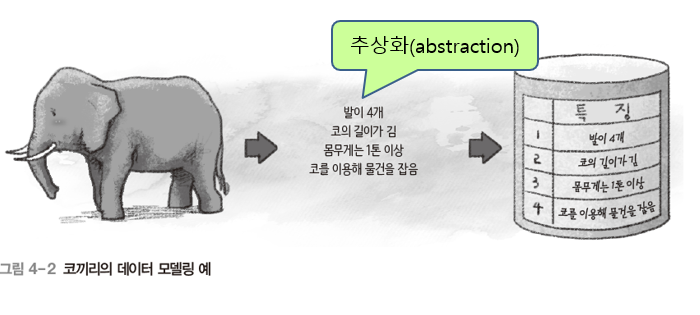
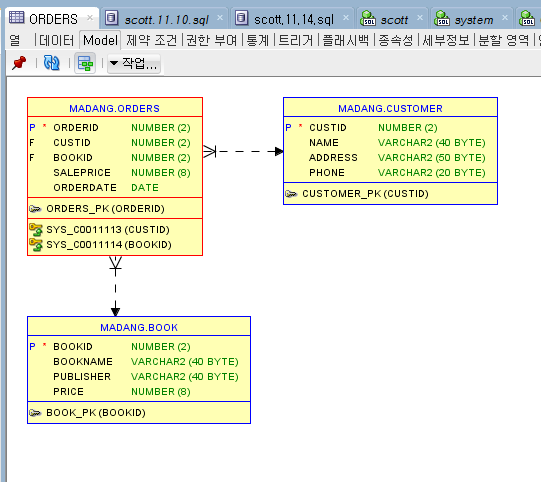
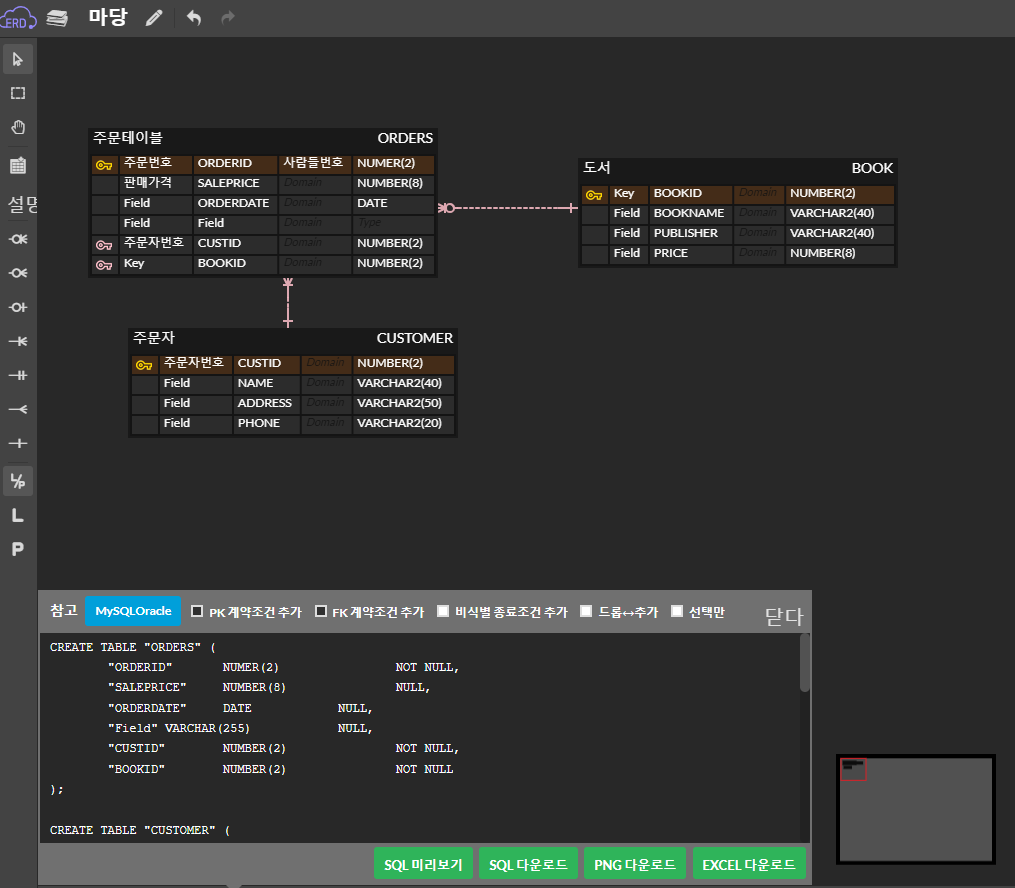
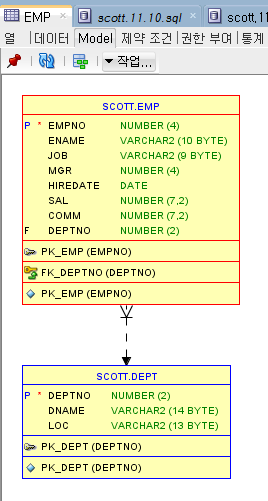
Oracle SQL Developer에서 ERD 만들기!-> ERDCLOUD
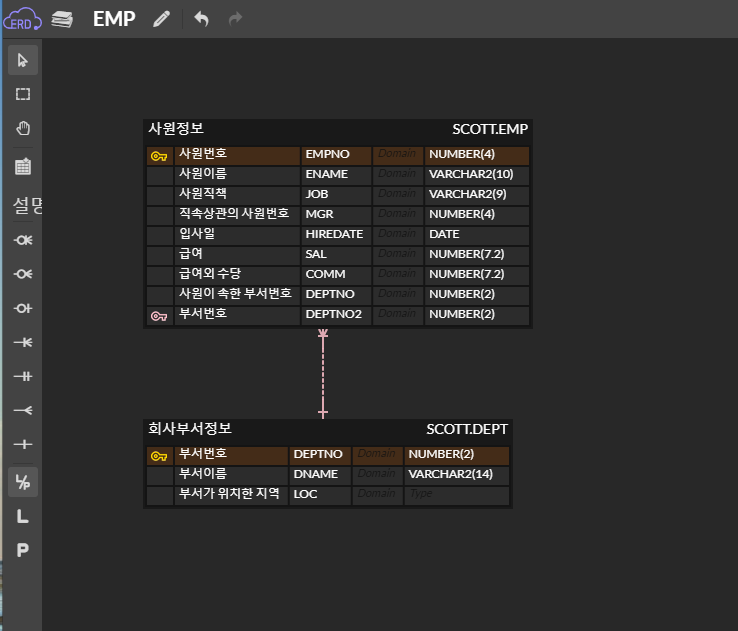

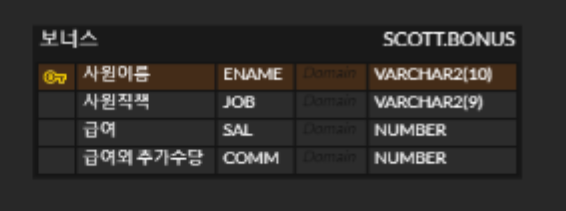

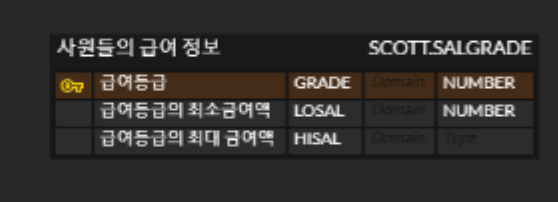
출처:
https://webstudynote.tistory.com/46
https://syj-computer.tistory.com/31
