연습문제
----- 11 / 23 ----------------------------------------------------------------------------
-- (1) emp 에서 전체열을 조회하세요
SELECT *
FROM EMP;
-- (2) 사원의 이름,연봉을 출력하기 (comm제외)
SELECT ENAME,SAL*12 AS ANNSAL
FROM EMP;
-- (3) 연봉을 내림 차순으로 정렬하시오.
SELECT ENAME, SAL*12 AS ANNSAL
FROM EMP
ORDER BY ANNSAL DESC;
-- (4) 사원이름,부서번호 내림,연봉 오름으로 정렬하기
SELECT ENAME, SAL*12 AS ANNSAL
FROM EMP
ORDER BY DEPTNO DESC, ANNSAL ASC;
-- (5) 직책이름을 출력해 봅시다. 중복제외
SELECT DISTINCT JOB
FROM EMP;
-- (6) 부서번호가 30인 사원 정보 모두
SELECT*
FROM EMP
WHERE DEPTNO = 30;
-- (7) 6번 이어서 직책이 CLERK인 사원 정보
SELECT *
FROM EMP
WHERE DEPTNO = 30
AND JOB = 'CLERK';
-- (8) SAL가 3000이상이고 직책은 ANALYST인 사원정보
SELECT *
FROM EMP
WHERE SAL >= 3000
AND JOB = 'ANALYST';
-- (9) 부서번호가 30이 아닌 사원 정보 모두
SELECT *
FROM EMP
WHERE DEPTNO<>30;
-- (10)JOB,CLERK,ANALYST,MANAGER인 사원
SELECT *
FROM EMP
WHERE JOB IN ('CLERK', 'ANALYST', 'MANAGER');
--(11)JOB,CLERK,ANALYST,MANAGER 아닌 사원
SELECT *
FROM EMP
WHERE JOB NOT IN ('CLERK', 'ANALYST', 'MANAGER');
-- (12) 급여가 2000-3000인 사원
SELECT *
FROM EMP
WHERE SAL BETWEEN 2000 AND 3000;
-- (13) ENAME 두번째 글자가 L인 사원
SELECT *
FROM EMP
WHERE ENAME LIKE '_L%';
-- (14) ENAME,SAL,COMM을 출력해 주세요.
-- (14) ENAME,SAL,COMM을 출력해 주세요.(COMM이 없는 사람들만 출력해주세요)
SELECT ENAME, SAL, COMM
FROM EMP
WHERE COMM IS NULL;
-- (14) ENAME,SAL,COMM을 출력해 주세요.(COMM이 있는 사람들만 출력해주세요)
SELECT ENAME, SAL, COMM
FROM EMP
WHERE COMM IS NOT NULL;
-- (15) 이름이 대소문자 구별없이 SCOTT인 사원
SELECT *
FROM EMP
WHERE LOWER(ENAME) = 'scott';
-- (16) 3*3은 얼마인가?
SELECT 3*3
FROM DUAL;
-- (17)오늘 날짜와 시간은?
SELECT SYSDATE
FROM DUAL;
-- (18) 부서별 SAL의 합계는?
SELECT DEPTNO, SUM(SAL)
FROM EMP
GROUP BY DEPTNO;
-- (19) 부서번호 30번인 인원 수?
SELECT COUNT(ENAME)
FROM EMP
WHERE DEPTNO = 30;
-- (20) 부서번호 30번인 ENAME, SAL는?
-- (21) 부서번호 30번인 최고급여인 사람의 ENAME, SAL는?
SELECT *
FROM EMP
WHERE SAL = (SELECT MAX(SAL) FROM EMP WHERE DEPTNO =30);
-- (22) 평균월급이 2000 이상인 사람들 이름과 평균월급,부서를 . 부서별로 출력,
select ename, avg(sal), deptno
from emp where sal >= 2000
group by deptno, ename
order by deptno;
-- (22) 평균월급이 2000 이상인 사람들 이름과 평균월급,부서를 . 부서별로 출력,
-- 부서별 평균월급은 2500이상인 부서
SELECT ENAME, AVG(SAL), DEPTNO
FROM EMP
WHERE SAL >= 2000
GROUP BY DEPTNO, ENAME
HAVING AVG(SAL) >= 2500
ORDER BY DEPTNO; - 클래스: 범주
- 레이블: 특정 샘플의 클래스 p61
- 손실함수와 같은말은?:
- 손실함수란: P63 머신러닝 혹은 딥러닝 모델의 출력값과 사용자가 원하는 출력값의 오차를 의미, 측정한 데이터를 토대로 산출한 모델의 예측값과 실제값의 차이를 표현하는 지표
손실함수는 정답(y)와 예측(^y)를 입력으로 받아 실숫값 점수를 만드는데, 이 점수가 높을수록 모델이 안좋은 것
손실함수의 함수값이 최소화 되도록 하는 가중치(weight)와 편향(bias)를 찾는 것이 목표
- 손실함수의 종류:
- binary_crossentropy(이항교차엔트로피) : 활성화 함수 : sigmoid 사용
- sparse_categorical_crossentropy : 클래스가 3개 이상이며 라벨이 0, 1, 2처럼 정수의 형태로 제공될 때 주로 사용된다.
- 평균 제곱 오차 손실 (means squared error, MSE): 실제 정답에 대한 정답률의 오차뿐만 아니라 다른 오답에 대한 정답률의 오차도 포함하여 계산해준다.-> 회귀에서 널리 사용
- 교차 엔트로피 오차(Cross Entropy Error, CEE)
- categorical_crossentropy (범주형 교차 엔트로피): 두 확률 분포의 거리 측정. 활성화 함수 : softmax
- 평균절대오차
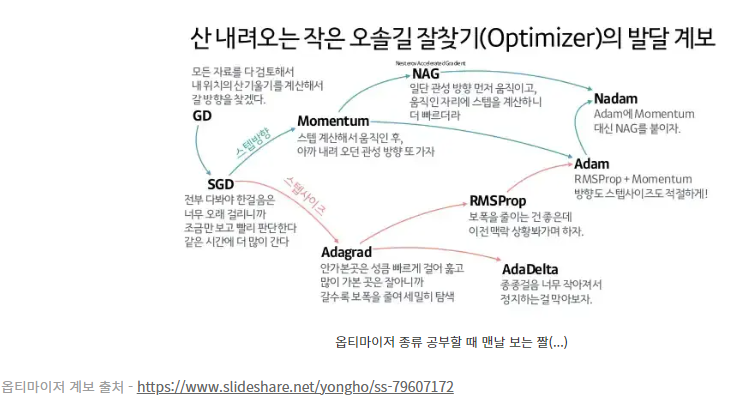
- 옵티마이저란? P63 : 업데이트하는 메커니즘

- 옵티마이저의 종류는?
Batch Gradient Descent
Stochastic Gradient Descent
Momentum
Nesterov Accelerated Gradient (NAG)
Adagrad
RMSprop
Adam
Adabelief
8.배열의 최댓값의 인덱스를 보려면.
- np.argmax()
- 변환해야 할 데이터타입은? .astype
- 과적합이란? 오버피팅
-
텐서란? p65 : 다차원의 넘파이의 배열
-
a = np.arange(12)
3행 4열의 2차원으로 바꾸어 주세요. - a.reshape(3,4) -
a.shape=3,4 ->3,4,1로 바꾸어 봅시다.
a[:, np.newaxis].shape
a.reshape((3, 4, 1))
np.expand_dims(a, axis = 1).shape
- 컬러 사진이 100장 (100, 28,28,3) p71
(sample, height,width,channels), channels = color_depth
14-1) 활성화 함수란? p153 입력된 데이터의 가중 합을 출력 신호로 변환하는 함수
14-2) 활성화 함수의 종류는? Relu/sigmoid/tanh/Leaky ReLU/ PReLU
-
Relu(rectified linear unit)의 그래픈는? p152
np.구현하는 식: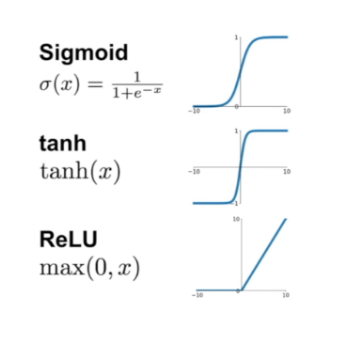
-
sigmoid의 그래프는?
구현하는 식은? 1/(1+np.e-x)
-
tanh의 그래프는?
식은? (ex+e-x)/2 -
변환의 종류는? p85 이동,확대,축소,아핀,회전,선형
가중치 초기화 (Weight Initialization)
초기 가중치 설정 (weight initialization)
딥러닝 학습에 있어 초기 가중치 설정은 매우 중요한 역활을 한다. 가중치를 잘못 설정할 경우 기울기 소실 문제나 표현력의 한계를 갖는 등 여러 문제를 야기하게 된다. 또한 딥러닝의 학습의 문제가 non-convex 이기 때문에 초기값을 잘못 설정할 경우 local minimum에 수렴할 가능성이 커지게 된다.
가중치를 초기화하는 여러 방법들에 대해서 알아보도록 한다.


2.4 신경망의 엔진: 그래디언트 기반 최적화 p87
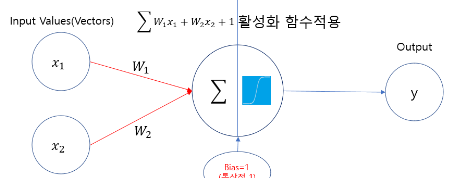
이전 절에서 보았듯이 첫 번째 신경망 예제에 있는 각 층은 입력 데이터를 다음과 같이 변환합니다.
output = relu(dot(W, input) * b)이 식에서 텐서 W와 b는 층의 속성처럼 볼 수 있습니다.
가중치(W)weight 또는 훈련되는파라미터trainable parameter 라고 부릅니다 (각각 커널kernel 25과편향bias 이라고 부르기도 합니다). 이런 가중치에는 훈련 데이터를 신경망에 노출시켜서 학습된 정보가 담겨 있습니다.
초기에는 가중치 행렬이 작은 난수로 채워져 있습니다 (무작위 초기화random initialization 단계라고 부릅니다). 물론 W와 b가 난수일 때 relu(dot(W, input) + b)가 유용한 어떤 표현을 만들 것이라고 기대할 수는 없습니다.
즉 의미 없는 표현이 만들어집니다. 하지만 이는 시작 단계일 뿐입니다. 그다음에는 피드백 신호에 기초하여 가중치가 점진적으로 조정될 것입니다. 이런 점진적인 조정 또는 훈련training이 머신 러닝 학습의 핵심입니다.
※ x는 값이 주어짐 w는 주어지지 않음.
※ w값에 아무거나 주면 안됨.
※ 예 0이 들어가면 학습이 되지 않는다. 랜덤하게 잘 줄 수 있을까? -> 그게 가중치의 초기화 -> 학습 잘하고 빠르게 결론에 도달하게 만든다.
훈련은 다음과 같은 훈련 반복 루프(training loop) 안에서 일어납니다. 필요한 만큼 반복 루프 안에서 이런 단계가 반복됩니다. (※중요하다!!!!!)
- 훈련 샘플 x와 이에 상응하는 타깃 y의 배치를 추출합니다.
- x를 사용하여 네트워크를 실행하고(정방향 패스forward pass 단계), 예측 y_pred를 구합니다.
- y_pred와 y의 차이를 측정하여 이 배치에 대한 네트워크의 손실을 계산합니다.
- 배치에 대한 손실이 조금 감소되도록 네트워크의 모든 가중치를 업데이트합니다.
결국 훈련 데이터에서 네트워크의 손실, 즉 예측 y_pred와 타깃 y의 오차가 매우 작아질 것입니다. 이 네트워크는 입력에 정확한 타깃을 매핑하는 것을 학습했습니다. 전체적으로 보면 마술처럼 보이지만 개별적인 단계로 쪼개어 보면 단순합니다.
1단계는 그냥 입출력 코드이므로 매우 쉽습니다.
2단계와 3단계는 몇 개의 텐서 연산을 적용한 것 뿐이므로 이전 절에서 배웠던 연산을 사용하여 이 단계를 구현할 수 있습니다.
어려운 부분은 네트워크의 가중치를 업데이트하는 4단계입니다.
개별적인 가중치 값이 있을 때 값이 증가해야 할지 감소해야 할지, 또 얼마큼 업데이트해야 할지 어떻게 알 수 있을까요?한 가지 간단한 방법은 네트워크 가중치 행렬의 원소를 모두 고정하고 관심 있는 하나만 다른 값을 적용해 보는 것입니다. 이 가중치의 초깃값이 0.3이라고 가정합시다.
배치 데이터를 정방향 패스에 통과시킨 후 네트워크의 손실이 0.5가 나왔습니다. 이 가중치 값을 0.35로 변경하고 다시 정방향 패스를 실행했더니 손실이 0.6으로 증가했습니다.반대로 0.25로 줄이면 손실이 0.4로 감소했습니다. 이 경우에 가중치를 –0.05만큼 업데이트한 것이 손실을 줄이는 데 기여한 것으로 보입니다. 이런 식으로 네트워크의 모든 가중치에 반복합니다.
이런 접근 방식은 모든 가중치 행렬의 원소마다 두 번의 (비용이 큰) 정방향 패스를 계산해야 하므로 엄청나게 비효율적입니다(보통 수천에서 경우에 따라 수백만 개의 많은 가중치가 있습니다).
신경망에 사용된 모든 연산이 미분 가능differentiable하다는 장점을 사용하여 네트워크 가중치에 대한 손실의 그래디언트gradient 26를 계산하는 것이 훨씬 더 좋은 방법입니다.
그래디언트의 반대방향으로 가중치를 이동하면 손실이 감소됩니다.미분 가능하다는 것과 그래디언트가 무엇인지 이미 알고 있다면 2.4.3절로 건너뛰어도 좋습니다. 그렇지 않으면 다음 두 절이 이해하는 데 도움이 될 것입니다.
https://reniew.github.io/13/-> 가중치 초기화 설명
https://heeya-stupidbutstudying.tistory.com/entry/ML-%EC%8B%A0%EA%B2%BD%EB%A7%9D%EC%97%90%EC%84%9C%EC%9D%98-Optimizer-%EC%97%AD%ED%95%A0%EA%B3%BC-%EC%A2%85%EB%A5%98-> 옵티마이저 설명
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339-> 활성화함수 설명
