
Code.presso Java 웹 개발 트랙 체험단 활동 5주차 첫번째 코스로 수강한 강의는 SQL 프로그래밍에 관한 내용이다.
4주차 코스였던 "처음 시작하는 SQL 프로그래밍" 강의를 수강한 후 학습하면 더 이해하기 쉽다!
강의 제목은 "SQL 프로그래밍 초급"으로, 자세한 정보는 👇🏻아래👇🏻 링크를 통해 확인할 수 있다.
✋🏻 포스팅 내 사용된 사진 파일들의 저작권은 모두 코드프레소에 있으며, 강의자료 공유 및 업로드는 불가능합니다.
🏷 SQL 명령어를 이용한 데이터의 조회
✔️ ORDER BY 명령어를 이용한 데이터의 정렬
특정 컬럼을 기준으로 내림차순(DESC) 혹은 오름차순(ASC)으로 정렬이 가능하다.(오름차순이 Default)

ORDER BY 명령어를 사용하며, 1개 이상의정렬 조건을 조합할 수 있다.
예제1
🤔 : 고객 데이터를 아이디 순으로 내림차순 정렬해봐!
SELECT *
FROM customers
ORDER BY cust_id DESC;예제2
🤔 : 주문아이템을 수량 순으로 오름차순 정렬해봐!
SELECT *
FROM orderItems ORDER BY quantity;예제3
🤔 : 주문아이템 데이터를 1차 주문 번호로 오름차순, 2차 수량으로 내림차순 정렬해봐!
SELECT *
FROM orderItems
ORDER BY order_num ASC, quantity DESC;
WHERE절과 결합하여 조건을 명시한 후 결과를 정렬할 수도 있다.
🤔 : 가격이 9 이하인 제품들만 가격 오름차순으로 정렬해봐!SELECT * FROM Products WHERE prod_price <= 9 ORDER BY prod_price;
✔️ LIMIT, OFFSET 명령어를 이용한 조회 데이터의 제한
LIMIT 은 조회 된 결과 값의 개수를 제한하는데 사용하고,
OFFSET 은 LIMIT 과 함께 사용되며 페이지 처리를 하는데 사용된다.

LIMIT 은 주로 ORDER BY 절과 같이 사용되며, 정렬 후 상위 N개의 결과만을 확인할 수 있다.
예제1
🤔 : 가격이 가장 비싼 제품 상위 3개 조회해봐!
SELECT *
FROM Products
ORDER BY prod_price DESC LIMIT 3;예제2
🤔 : 가격이 가장 비싼 제품 상위 4,5 번째 제품 조회해봐!
SELECT *
FROM Products
ORDER BY prod_price DESC LIMIT 3;예제3
🤔 : 가격이 가장 비싼 제품 상위 4,5 번째 제품 조회해봐!
SELECT *
FROM Customers
WHERE cust_name = 'Fun4All' LIMIT 1;✔️ IN 연산자를 이용한 데이터 필터링
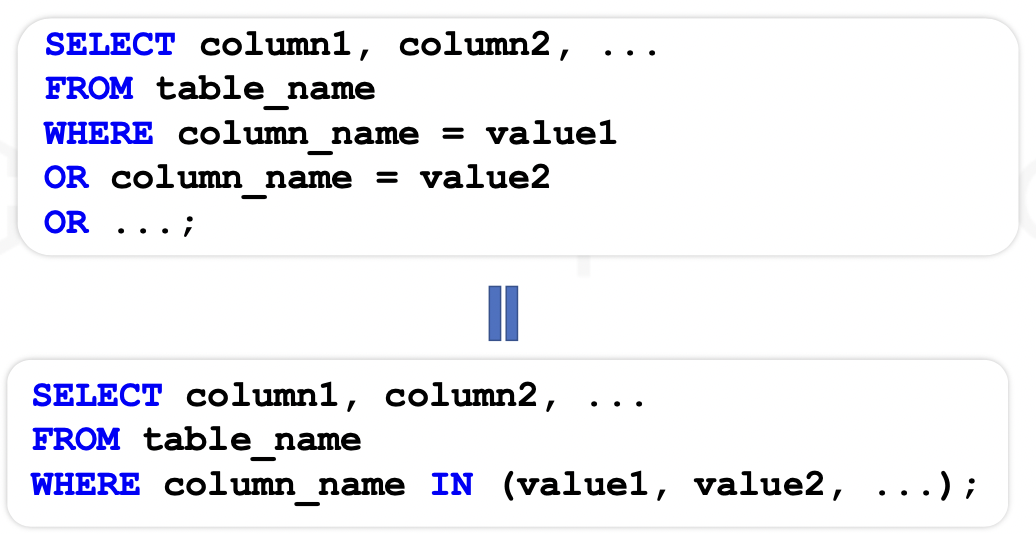
IN 연산자는 다중 OR 연산자의 축약 버전이다.
예제1
🤔 : 'MI' 주에 거주하거나 'OH' 주에 거주하는 고객을 조회해봐!
SELECT *
FROM Customers
WHERE cust_state IN ('MI', 'OH');예제2
🤔 : 'USA' 에 있거나 'France' 에 있는 벤더를 조회해봐!
SELECT *
FROM Vendors
WHERE vend_country IN ('USA', 'France');✔️ BETWEEN 연산자를 이용한 데이터의 필터링
BETWEEN 연산자는 주어진 범위에 대한 조건에 해당하는 데이터를 조회한다.
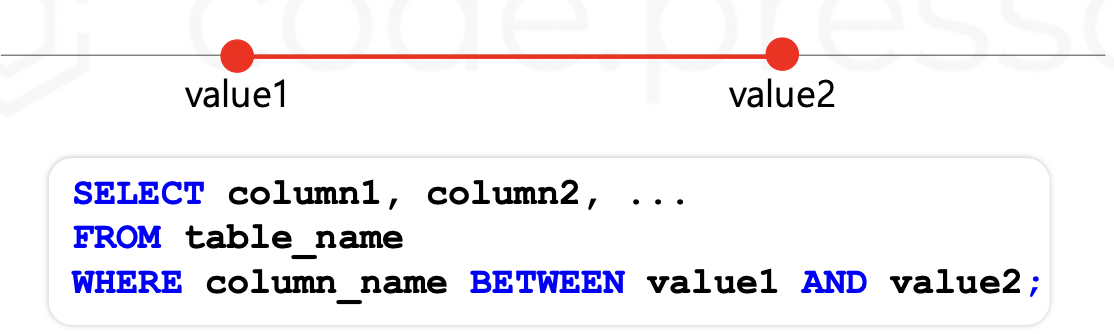 숫자, 날짜, 문자형 데이터에 모두 사용 가능하고, 주어진 범위까지 모두 포함한다.
숫자, 날짜, 문자형 데이터에 모두 사용 가능하고, 주어진 범위까지 모두 포함한다.
예제1
🤔 : 주문 번호가 20006 ~ 20008 인 주문 데이터를 조회해봐!
SELECT *
FROM Orders
WHERE order_num BETWEEN 20006 AND 20008;✔️ LIKE 연산자를 이용한 데이터의 필터링

LIKE 연산자는 문자열 안에서 특정 패턴을 검색하기 위해 사용한다.
= 연산자가 문자열이 완전히 일치하는 조건이라면, LIKE 연산자는 문자열이 부분적으로 일치하는 조건이다.
문자열의 검색 패턴을 위해 % 기호를 사용한다.
WHERE column_name LIKE 'a%'
"a"로 시작하는 문자열 검색WHERE column_name LIKE '%a'
"a"로 끝나는 문자열 검색WHERE column_name LIKE '%a%'
"a"가 들어있는 문자열 검색WHERE column_name LIKE 'a%o'
"a"로시작하고 "o"로 끝나는 문자열 검색
예제1
🤔 : 이름이 'B'로 시작하는 벤더를 조회해봐!
SELECT *
FROM Vendors
WHERE vend_name LIKE 'B%';✔️ DISTINCT 명령어를 이용한 중복 데이터 제거

SELECT DISTINCT 문은 특정 컬럼의 unique한 값 들을 조회한다.
다수의 컬럼을 명시할 수 있지만 자주 사용되지는 않는다.
예제1
🤔 : 벤더의 unique한 국가 목록을 조회해봐!
SELECT DISTINCT
vend_country FROM Vendors;✔️ 누락(Null Value) 데이터의 처리
Null Value 란 아무것도 값이 없는 상태를 의미한다.

IS NULL, IS NOT NULL 연산자로 null 인 또는 null 이 아닌 데이터만 조회할 수 있다.
예제1
🤔 : 고객 데이터 중 국가 정보가 Null인 고객을 조회해봐!
SELECT *
FROM Customers
WHERE cust_country IS NULL;예제2
🤔 : 고객 데이터 중 주소 정보는 Null이고 국가 정보는 Null이 아닌 고객을 조회해봐!
SELECT *
FROM Customers
WHERE cust_address IS NULL
AND cust_country IS NOT NULL;✔️ AS 명령어를 이용한 데이터의 별칭

AS 명령어는 Alias (별칭)을 의미한다.
컬럼 또는 테이블에 별칭을 부여하여 컬럼/테이블 명을 이해하기 쉽게 만들기 위해서 사용한다.
예제1
🤔 : 고객 테이블의 cust_name 컬럼에 customerName으로 별칭을 부여하여 고객 이름 정보를 조회
해봐!
SELECT cust_name AS customerName
FROM Customers;예제2
🤔 : 고객 테이블에 cst 로 별칭을 부여하여 고객의 이름이 'The Toy Store' 인 데이터를 조회해봐!
SELECT cst.*
FROM Customers AS cst
WHERE cst.cust_name = 'The Toy Store'; 🏷 SQL 명령어를 이용한 데이터의 변경
✔️ UPDATE 명령어를 이용한 데이터 수정
UPDATE 명령어는 기존의 데이터를 수정할 때 사용된다.

WHERE 절에 명시한 조건에 해당하는 데이터를 변경하기 때문에, 명시하지 않으면 모든 행의 값이 변경될 수 있으니 주의해야 한다!
예제1
🤔 : 사용자 데이터 중 ID가 '1000000002' 인 사용자의 이메일 주소를 변경해봐!
UPDATE customers
SET cust_email = 'support@kidsplace.com'
WHERE cust_id = '1000000002'; ✔️ DELETE 명령어를 이용한 데이터 삭제
DELETE 명령어는 기존 데이터를 삭제한다.
 이 명령어 또한
이 명령어 또한 WHERE 절에 명시한 조건에 해당하는 데이터를 삭제하기 때문에 명시하지 않으면 해당 테이블의 모든 데이터가 삭제될 수 있다.
지워진 데이터는 복구가 어렵기 때문에 신중히 사용하고, 삭제하기 전 데이터를 백업해 놓거나 동일한 where 조건으로 조회하여 삭제되는 데이터를 확인해야 한다!
예제1
🤔 : 주문 아이템 테이블에서 order_num 이 20005 이고 order_item 이 2인 데이터를 삭제해봐!
DELETE FROM Orderitems
WHERE order_num = 20005
AND order_item = 2;🏷 SQL 명령어를 이용한 데이터의 집계
✔️ COUNT 함수를 이용한 데이터 개수 집계
COUNT 함수는 조회된 데이터의 개수를 계산하는 함수이다.

WHERE 절을 통해 필터링된 데이터의 개수를 계산하는데 Null Value 는 카운트 되지 않는다.
예제1
🤔 : 제품의 총 개수를 조회해봐!
SELECT COUNT(*)
FROM Products;예제2
🤔 : 제품에서 제품 가격 컬럼의 총 데이터 개수를 조회해봐!
SELECT COUNT(prod_price)
FROM Products;✔️ SUM 함수를 이용한 데이터의 합 집계
SUM 함수는 조회된 데이터의 합을 계산하는 함수이다.

WHERE 절을 통해 필터링된 데이터의 합을 계산하는데, * 를 사용할 수 없고 꼭 특정 컬럼명을 명시해야 한다!
예제1
🤔 : 주문 아이템 데이터에서 전체 구매 수량을 계산해봐!
SELECT SUM(quantity)
FROM OrderItems; ✔️ MIN, MAX 함수를 이용한 최대값, 최소값 집계
MIN 함수는 조회된 데이터에서 특정 컬럼의 최소값을 계산하는 함수이고,
MAX 함수는 조회된 데이터에서 특정 컬럼의 최대 값을 계산하는 함수이다.

WHERE 절을 통해 필터링된 데이터의 최대값 최소값을 계산할 수 있다.
예제1
🤔 : 주문 아이템 수량의 최대값을 계산해봐!
SELECT MAX(quantity)
FROM OrderItems;예제2
🤔 : 주문 아이템 수량의 최소값을 계산해봐!
SELECT MIN(quantity)
FROM OrderItems;✔️ AVG 함수를 이용한 평균값 집계
AVG 함수는 조회된 데이터에서 특정 컬럼의 평균 값을 구하는 함수이다.

WHERE 절을 통해 필터링 된 데이터에서 특정 컬럼의 평균값을 계산할 수 있다.
예제1
🤔 : 주문 아이템 수량의 평균을 계산해봐!
SELECT AVG(quantity)
FROM OrderItems; ✔️ VARIANCE, STDDEV 함수를 분산, 표준편차 집계

VARIANCE 함수는 조회된 데이터에서 특정 컬럼의 분산을 계산하고,
STDDEV 함수는 조회된 데이터에서 특정 컬럼의 표준편차를 계산한다.
예제1
🤔 : 주문 아이템 수량의 분산을 계산해봐!
SELECT VARIANCE(quantity)
FROM OrderItems;예제2
🤔 : 주문 아이템 수량의 표준편차를 계산해봐!
SELECT STDDEV(quantity)
FROM OrderItems;✔️ GROUP BY 함수를 이용한 그룹별 데이터 집계
GROUP BY 는 특정 컬럼들을 기준으로 데이터를 그룹 지어 분석해주는 함수이다.
한 개 이상의 컬럼으로 그룹화가 가능하다.
 이와 같이 주로 집계함수들과 함께 자주 사용된다.
이와 같이 주로 집계함수들과 함께 자주 사용된다.
예제1
🤔 : 주문 아이템을 주문번호로 그룹화해봐!
SELECT order_num
FROM OrderItems
GROUP BY order_num;예제2
🤔 : 주문 아이템을 주문번호로 그룹화 하여 그룹 별 데이터의 개수를 계산해봐!
SELECT order_num, COUNT(order_num)
FROM OrderItems
GROUP BY order_num;예제3
🤔 : 주문 아이템을 주문번호로 그룹화하여 다양한 통계량을 알아보자!
SELECT
order_num,
COUNT(order_num) AS "총 카운트",
SUM(quantity) AS "수량 합계",
AVG(item_price) AS "가격 평균",
MAX(item_price) AS "가격 최대",
MIN(item_price) AS "가격 최소"
FROM OrderItems
GROUP BY order_num;✔️ HAVING 명령어를 이용한 집계 데이터 필터링
HAVING 명령어는 그룹화 한 결과를 필터링해주는 명령어이다.
 그룹화 전 필터링은
그룹화 전 필터링은 WHERE, 그룹화 후 필터링은 HAVING 을 사용한다!
예제1
🤔 : 주문 아이템을 주문번호로 그룹화하여 그룹별 카운트 계산 후, 카운트가 3 이상인 결과만 필터링해봐!
SELECT order_num,
COUNT(order_num)
FROM OrderItems
GROUP BY order_num
HAVING COUNT(order_num) >= 3; 🏷 SQL 명령어를 이용한 데이터의 결합
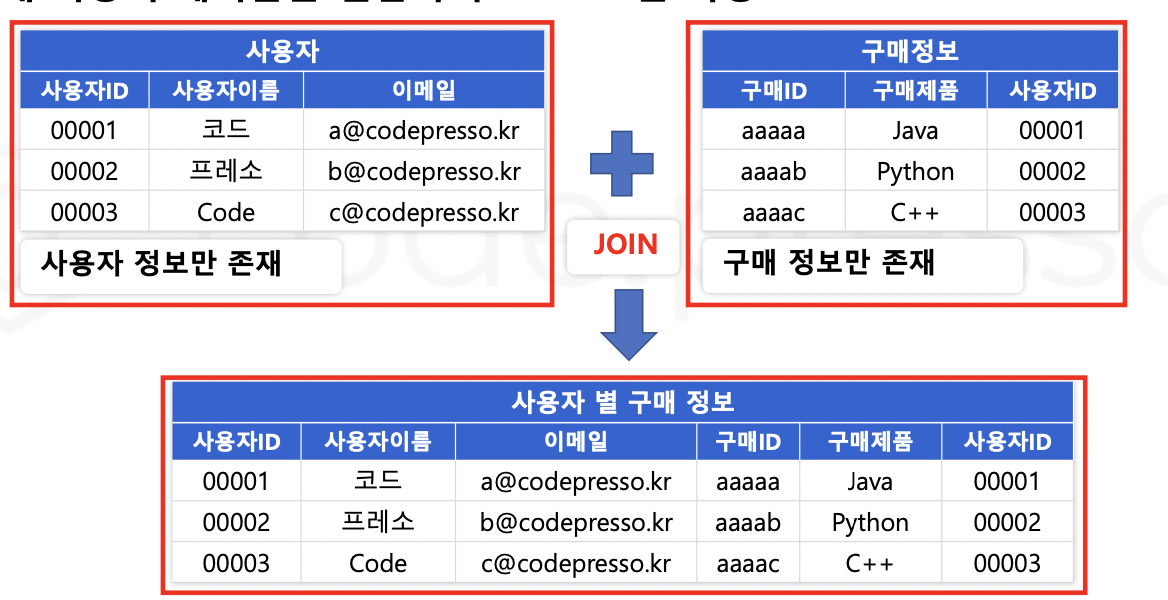
SQL JOIN 을 이용하여 두 개 이상의 테이블을 결합하여 Column을 확장할 수 있다.
SQL JOIN 에는,
INNER JOINLEFT(OUTER) JOINRIGHT(OUTER) JOINFULL OUTER JOINCROSS JOINSELF JOIN
이와 같이 다양한 종류가 있는데 이번 코스에서는INNER JOIN,OUTER JOIN에 대해서만 학습했다.
✔️ INNER JOIN 명령어를 이용한 데이터의 Column 결합
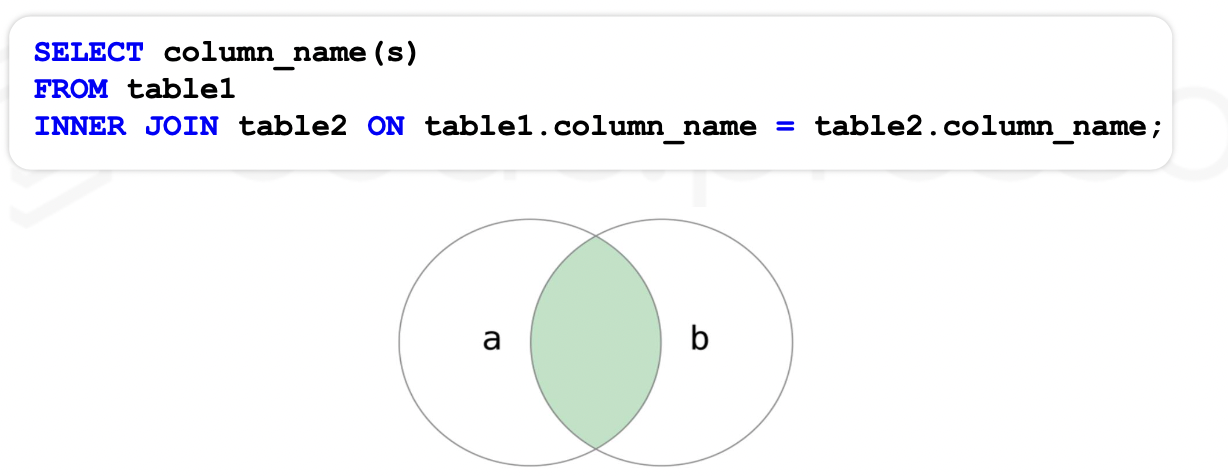
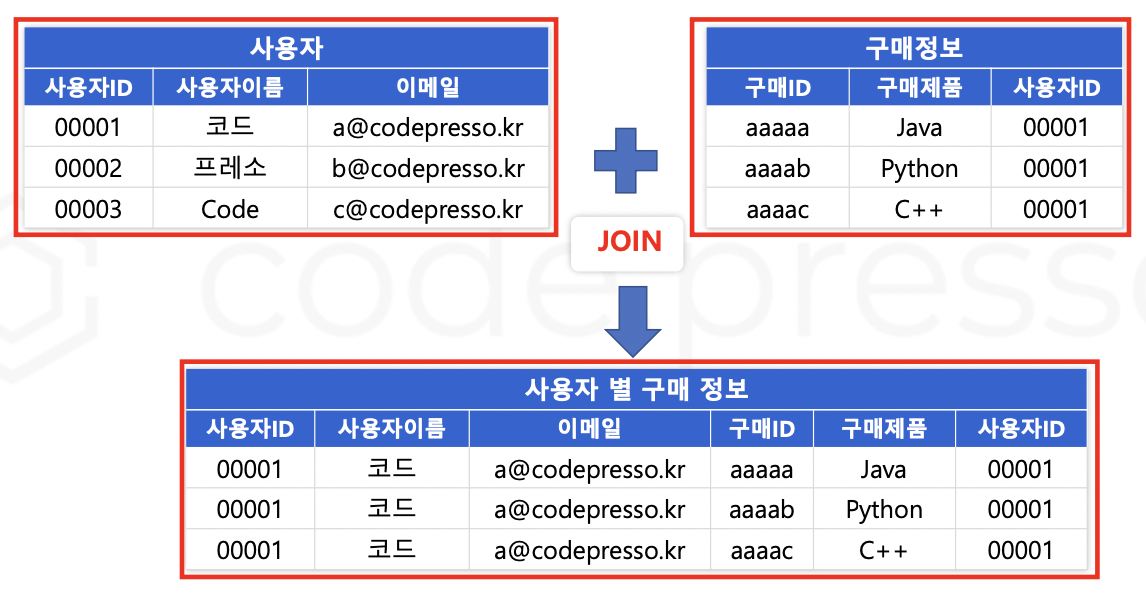
INNER JOIN 은 두 개의 테이블에 모두 존재하는 데이터만 결합하여 조회하는 명령어이다.
ON 명령어 뒤에 정의한 Column 정보를 기준으로 존재 여부를 체크한다.
예제1
🤔 : 고객 테이블과 주문 테이블을 cust_id 값으로 결합해봐!
SELECT *
FROM Customers AS cu
INNER JOIN Orders AS od ON od.cust_id = cu.cust_id예제2
🤔 : Orders 테이블의 order_num 이 20007보다 큰 데이터를 조회해봐!
✔️ OUTER JOIN 명령어를 이용한 데이터의 Column 결합
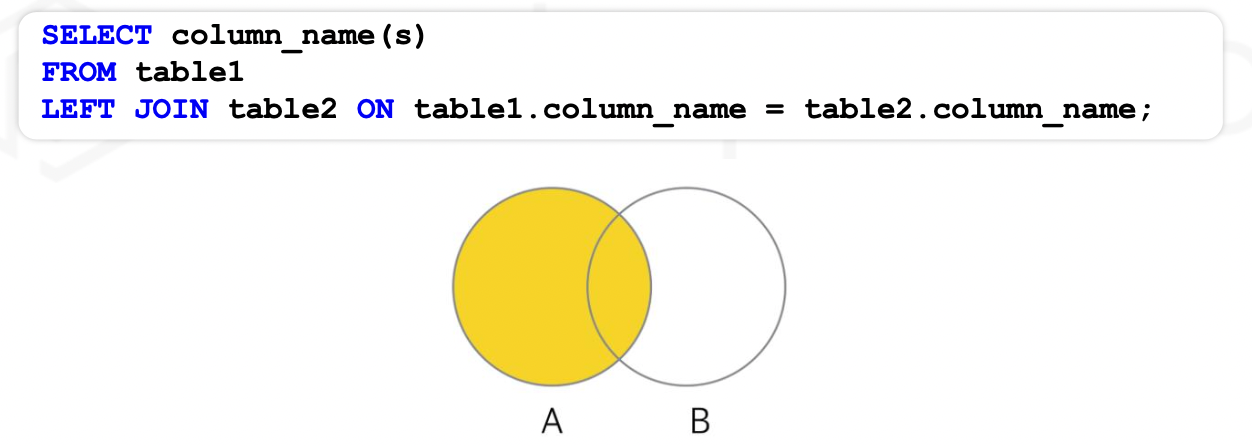
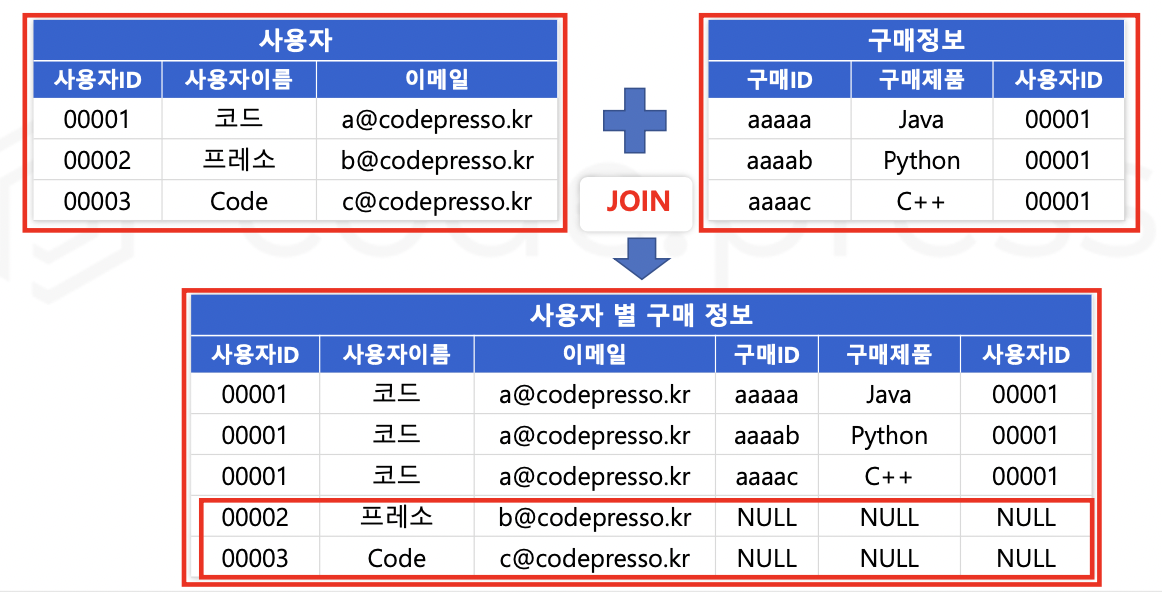
OUTER JOIN 중 LEFT (OUTER) JOIN 은 왼쪽에 위치한 테이블을 기준으로 오른쪽의 테이블의 데이터를 붙이는 명령어이다.
FROM 사용자
LEFT JOIN 구매정보 ON 사용자.사용자ID = 구매정보.사용자ID;왼쪽 테이블의 데이터는 모두 조회되고,
왼쪽 테이블에는 있지만 오른쪽 테이블에 없는 데이터는 Null 로 조회된다.
예제1
🤔 : 고객 테이블과 주문 테이블을 cust_id 값으로 JOIN, 단 주문 정보가 존재하지 않는 고객 정보도 조회해봐!
SELECT *
FROM Customers AS cu
LEFT JOIN Orders AS od ON od.cust_id = cu.cust_id이렇게 SQL 명령어를 이용한 데이터 조회/변경/집계/결합방법에 대해 학습해보았다!
코드프레소 홈페이지(https://www.codepresso.kr/)에는 오늘 포스팅한 SQL 프로그래밍 관련 강의뿐만 아니라 다양한 강의들이 개설되어 있으니 모두 한번 씩 살펴보고 수강해보면 좋을 것 같다😃
