
🏷 주문 조회 V4 : JPA에서 DTO 직접 조회
✔️ OrderApiController에 추가
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4() {
return orderQueryRepository.findOrderQueryDtos();
}✔️ OrderQueryRepository 생성
@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
private final EntityManager em;
/**
* 컬렉션은 별도로 조회
* Query: 루트 1번, 컬렉션 N 번 * 단건 조회에서 많이 사용하는 방식
*/
public List<OrderQueryDto> findOrderQueryDtos() {
// 루트 조회 (toOne 코드를 모두 한번에 조회)
List<OrderQueryDto> result = findOrders();
// 루프를 돌면서 컬렉션 추가 (추가 쿼리 실행)
result.forEach(o -> {
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId());
o.setOrderItems(orderItems);
});
return result;
}
/**
* 1:N 관계(컬렉션)를 제외한 나머지를 한번에 조회
*/
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o" +
" join o.member m" +
" join o.delivery d", OrderQueryDto.class)
.getResultList();
}
/**
* 1:N 관계인 orderItems 조회
*/
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id = : orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
}
✔️ OrderQueryDto 생성
@Data
@EqualsAndHashCode(of = "orderId")
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate,
OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}✔️ OrderItemQueryDto 생성
@Data
public class OrderItemQueryDto {
@JsonIgnore
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int
count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}
- 쿼리 : 루트 1번, 컬렉션 N번 실행
XToOne(N:1, 1:1)관계들을 먼저 조회하고,XToMany(1:N)관계는 각각 별도로 처리한다.
이런 방식을 선택한 이유는 다음과 같다.XToOne관계는 조인해도 데이터 row 수가 증가하지 않는다.XToMany(1:N)관계는 조인하면 row 수가 증가한다.- row 수가 증가하지 않는
XToOne관계는 조인으로 최적화 하기 쉬우므로 한번에 조회하고,XToMany관계는 최적화 하기 어려우므로findOrderItems()같은 별도의 메서드로 조회!
✔️ 실행 결과
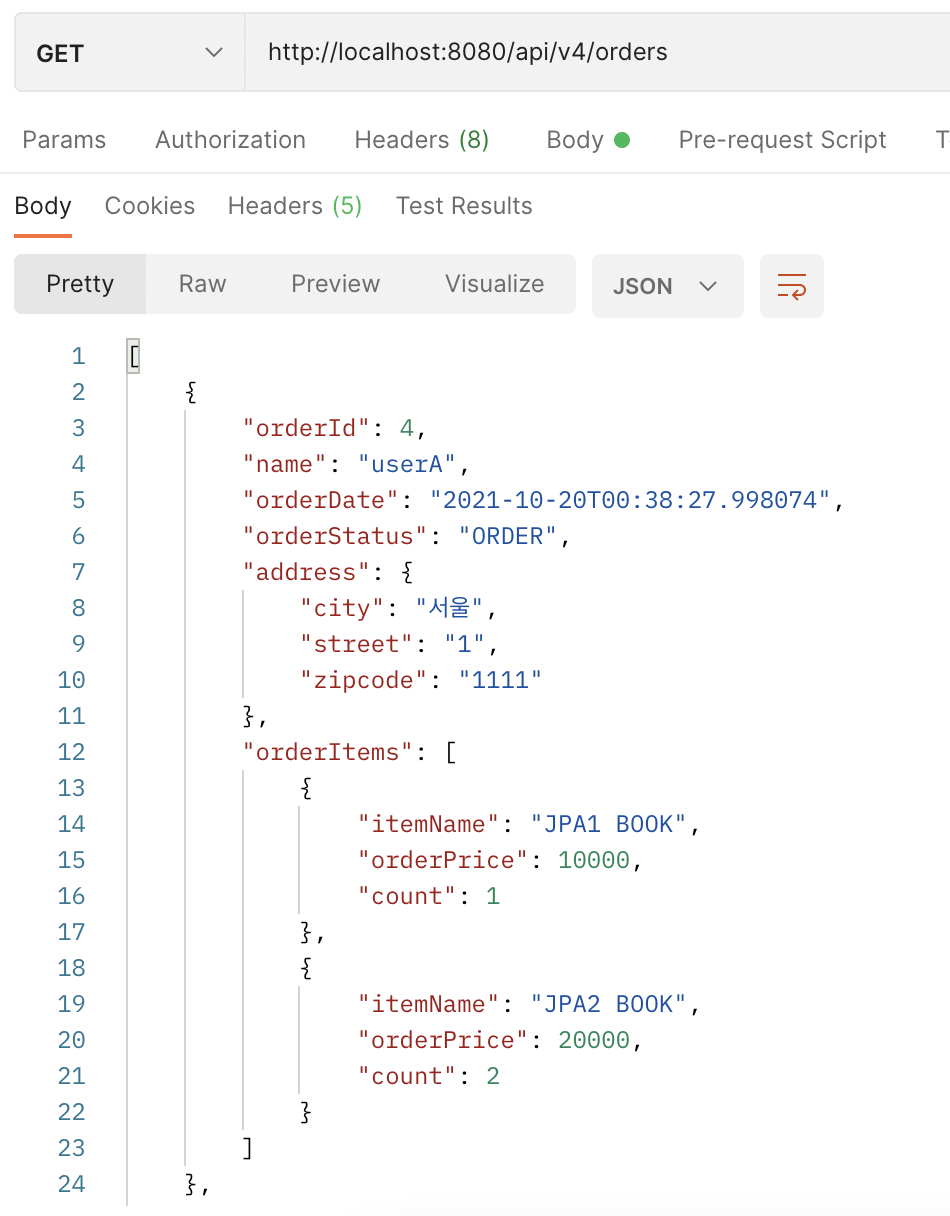 ➡️ 포스트맨 실행 결과 👍🏻
➡️ 포스트맨 실행 결과 👍🏻
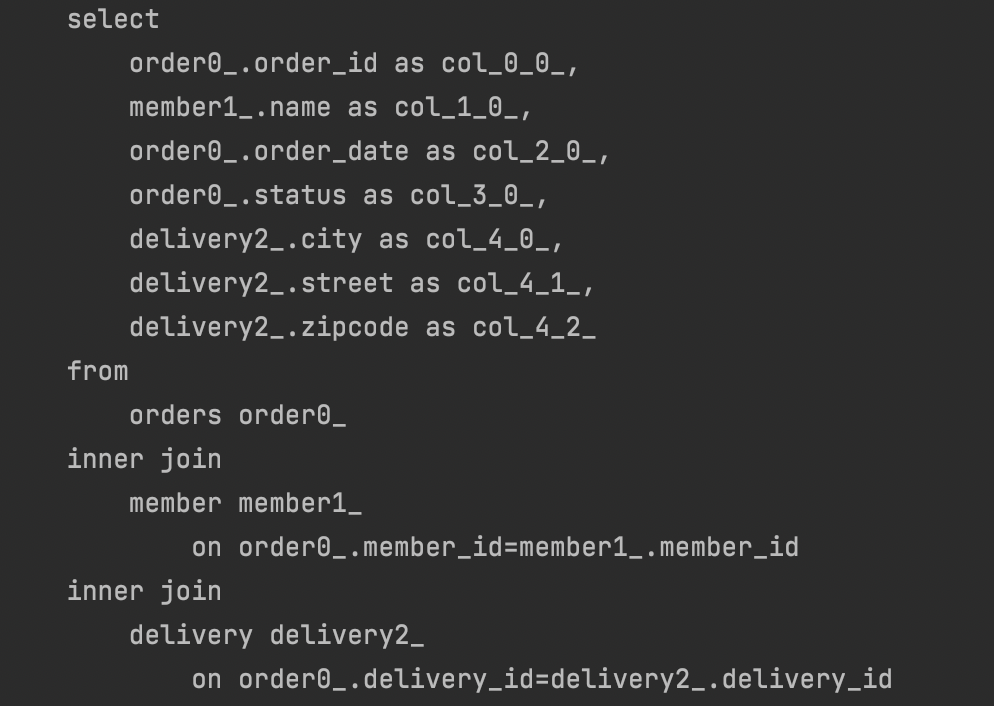 ➡️ 쿼리 : 루트 1번
➡️ 쿼리 : 루트 1번
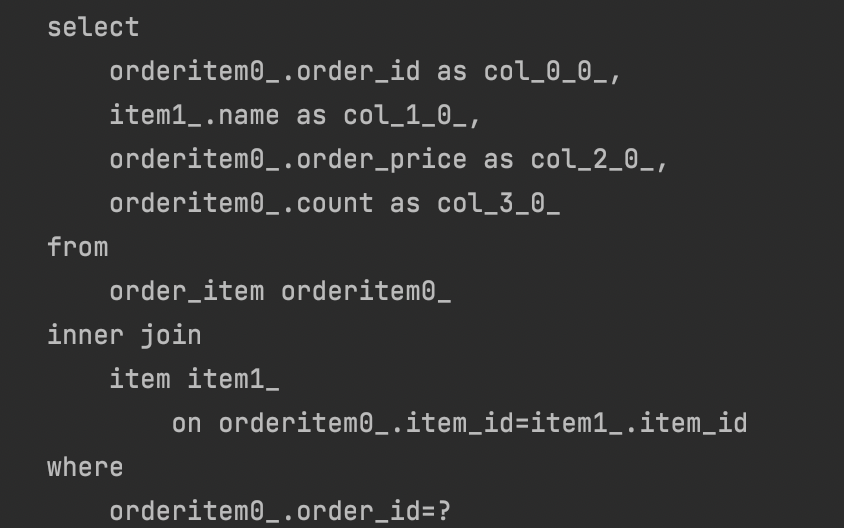 ➡️ 컬렉션 1번
➡️ 컬렉션 1번
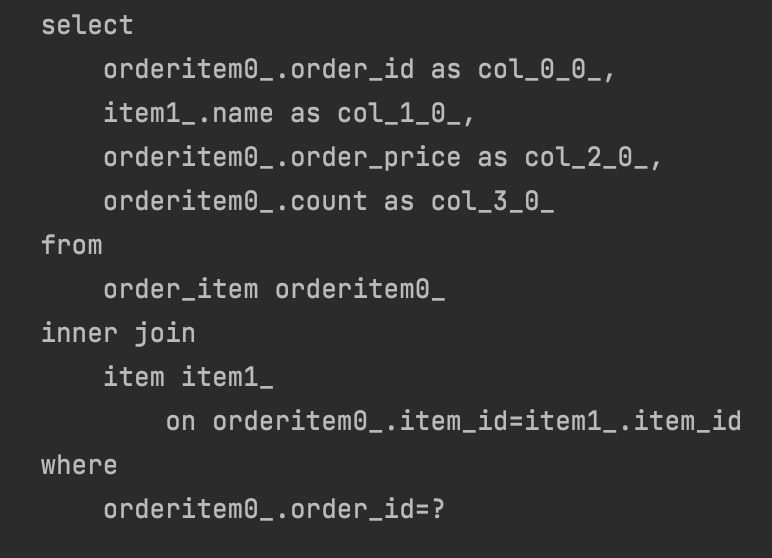 ➡️ 컬렉션 2번
➡️ 컬렉션 2번
🏷 주문 조회 V5 : JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
✔️ OrderApiController 에 추가
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5() {
return orderQueryRepository.findAllByDto_optimization();
}✔️ OrderQueryRepository 에 추가
/**
* 최적화
* Query: 루트 1번, 컬렉션 1번
* 데이터를 한꺼번에 처리할 때 많이 사용하는 방식 *
*/
public List<OrderQueryDto> findAllByDto_optimization() {
// 루트 조회(toOne 코드를 모두 한번에 조회)
List<OrderQueryDto> result = findOrders();
// orderItem 컬렉션을 MAP 한방에 조회
Map<Long, List<OrderItemQueryDto>> orderItemMap = findOrderItemMap(toOrderIds(result));
// 루프를 돌면서 컬렉션 추가(추가 쿼리 실행X)
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId())));
return result;
}
private List<Long> toOrderIds(List<OrderQueryDto> result) {
return result.stream()
.map(o -> o.getOrderId())
.collect(Collectors.toList());
}
private Map<Long, List<OrderItemQueryDto>> findOrderItemMap(List<Long>
orderIds) {
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
return orderItems.stream()
.collect(Collectors.groupingBy(OrderItemQueryDto::getOrderId));
}- 쿼리 : 루트 1번, 컬렉션 1번
XToOne관계들을 먼저 조회하고, 여기서 얻은 식별자orderId로XToMany관계인OrderItem을 한꺼번에 조회!- MAP을 사용해서 매칭 성능 향상👍🏻
✔️ 실행 결과
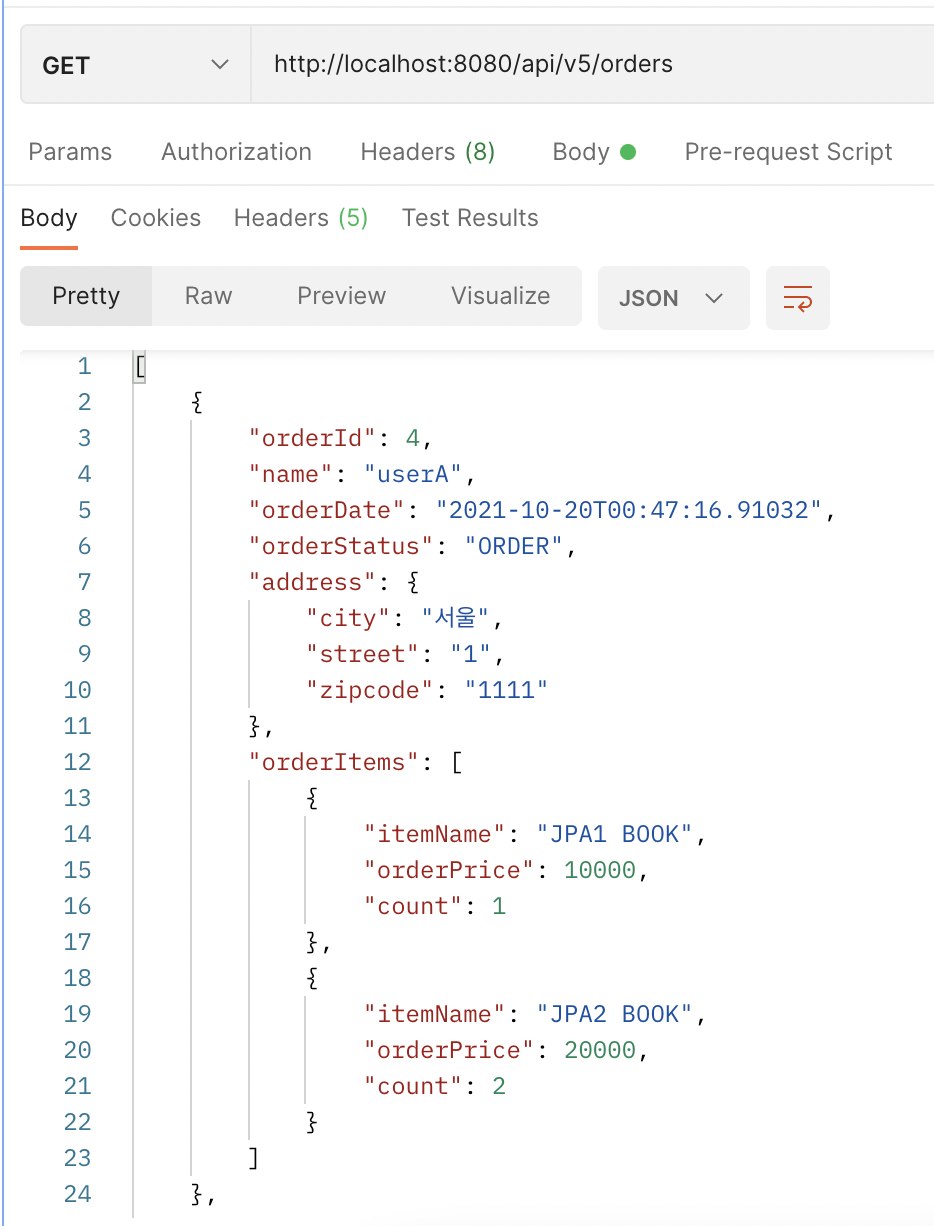 ➡️ 포스트맨 실행 결과는 이전과 동일!
➡️ 포스트맨 실행 결과는 이전과 동일!
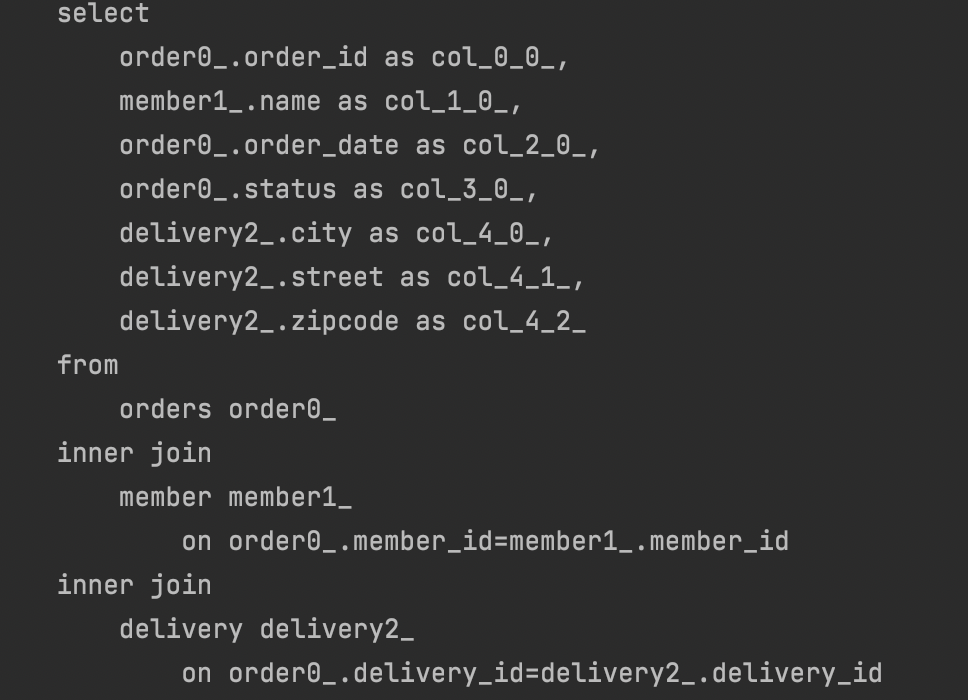 ➡️ 쿼리 : 루트 1번
➡️ 쿼리 : 루트 1번
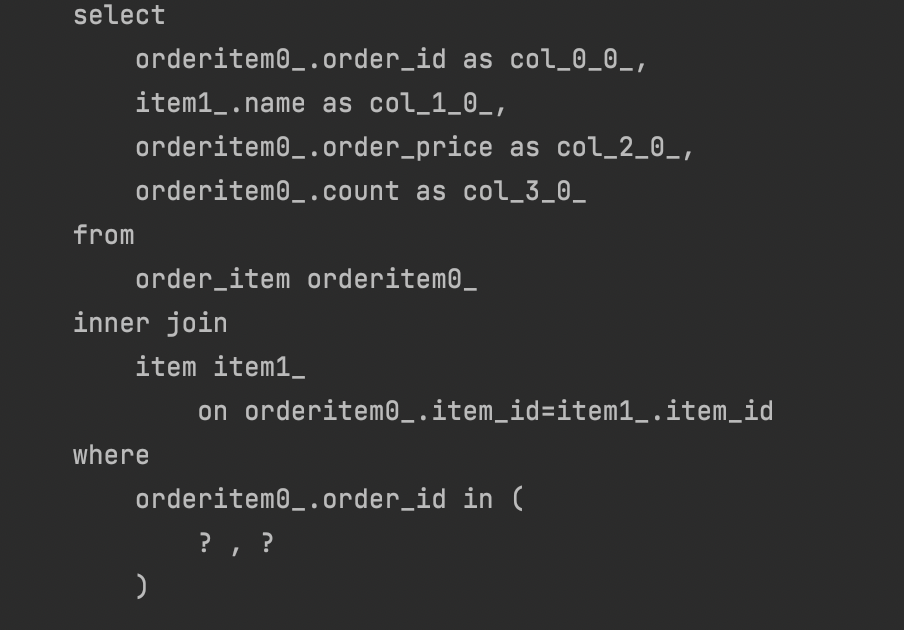 ➡️ 컬렉션 1번
➡️ 컬렉션 1번
🏷 주문 조회 V6 : JPA에서 DTO 직접 조회, 플랫 데이터 최적화
✔️ OrderApiController 에 추가
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6() {
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(),
o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(),
o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(),
e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(),
e.getKey().getAddress(), e.getValue()))
.collect(toList());
}✔️ OrderQueryDto 에 생성자 추가
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate,
OrderStatus orderStatus, Address address, List<OrderItemQueryDto> orderItems) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.orderItems = orderItems;
}✔️ OrderQueryRepository 에 추가
public List<OrderFlatDto> findAllByDto_flat() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count)" +
" from Order o" +
" join o.member m" +
" join o.delivery d" +
" join o.orderItems oi" +
" join oi.item i", OrderFlatDto.class)
.getResultList();
}✔️ OrderFlatDto 생성
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private Address address;
private OrderStatus orderStatus;
private String itemName;
private int orderPrice;
private int count;
public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate,
OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}- 쿼리가 단!!!!!한 번!!!!!!!!!!!!
- 그러나^^ 단점❓
- 쿼리는 한번이지만 조인으로 인해 DB에서 애플리케이션에 전달하는 데이터에 중복 데이터가 추가되므로 상황에 따라 V5보다 더 느릴 수도 있다ㅠ
- 애플리케이션에서 추가 작업이 큼
- 페이징 불가능
✔️ 실행 결과
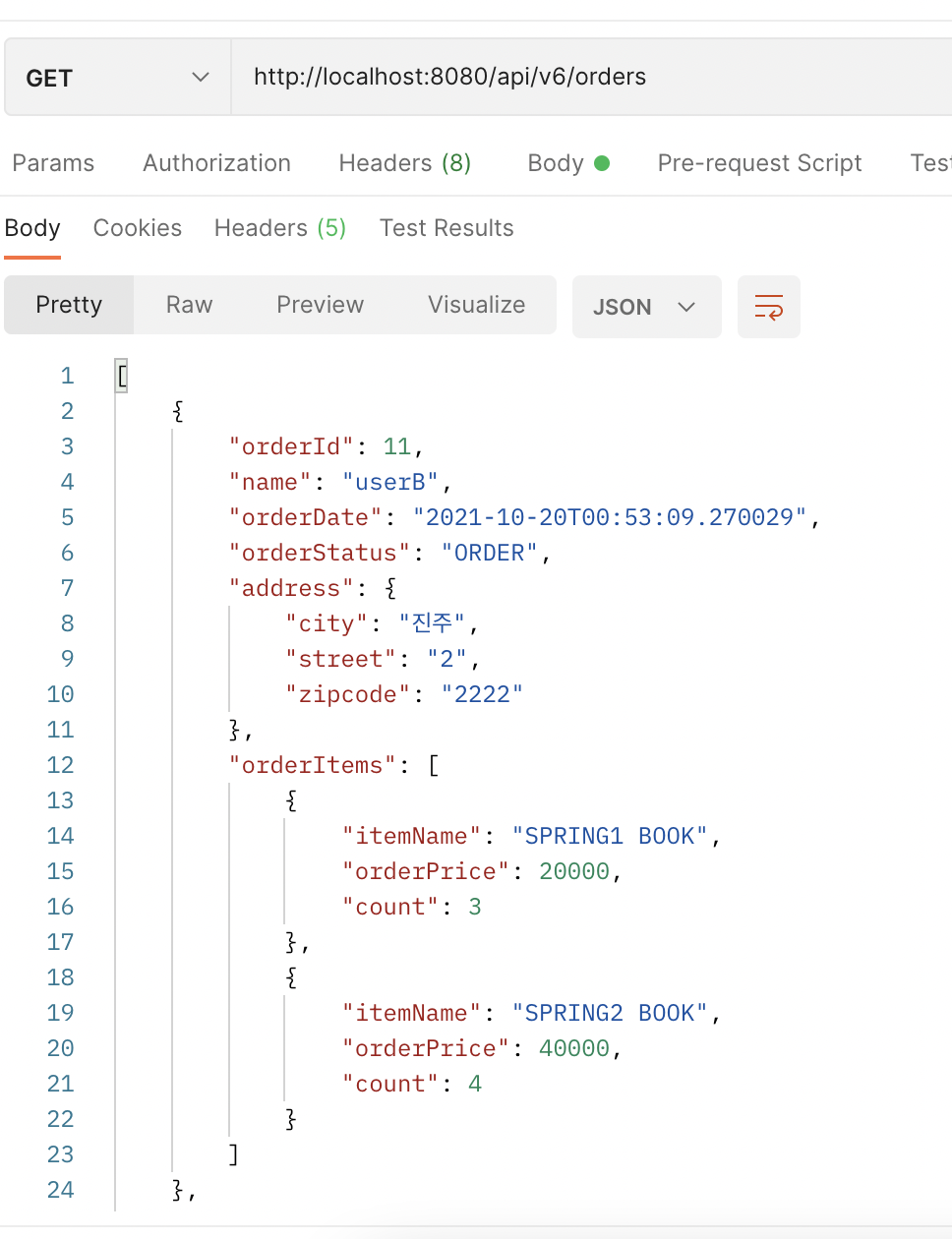 ➡️ 포스트맨 실행 결과는 이전과 동일!
➡️ 포스트맨 실행 결과는 이전과 동일!
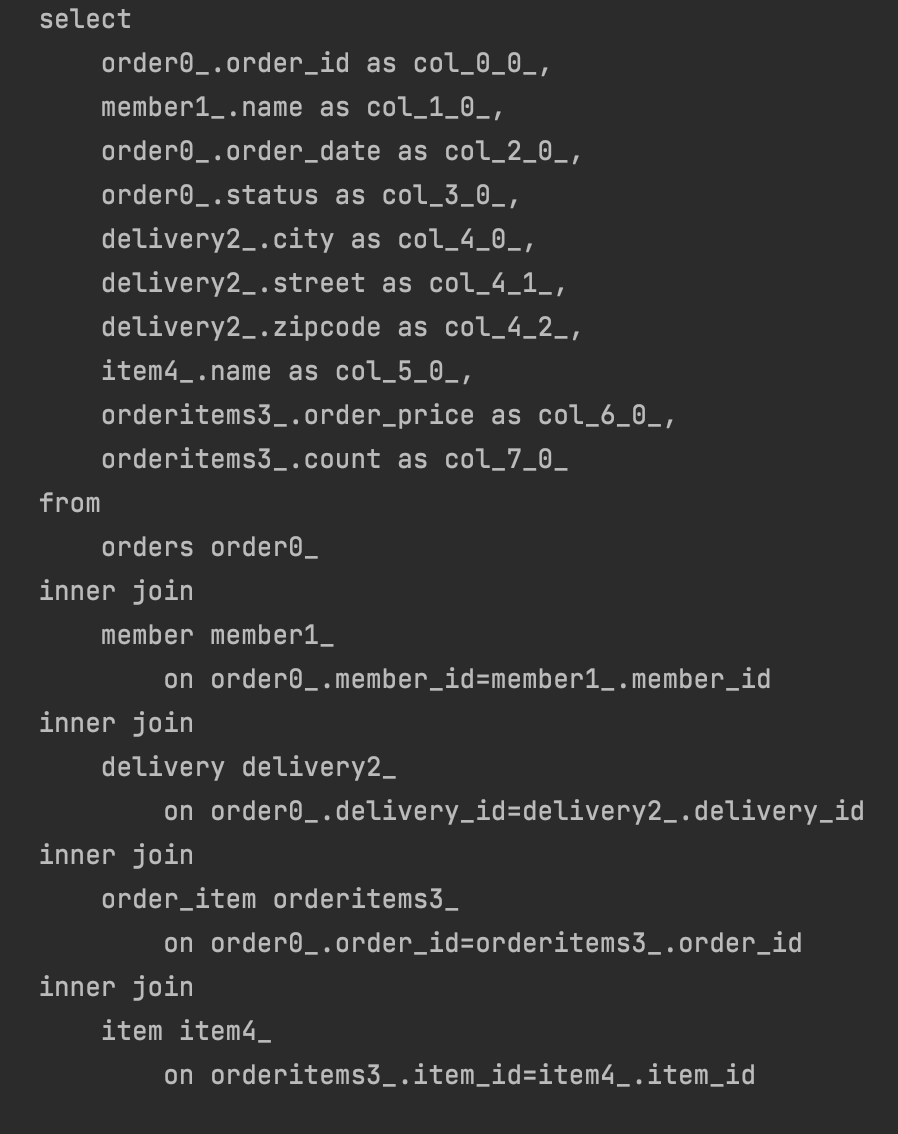 ➡️ 쿼리가 단 한 번!!!!
➡️ 쿼리가 단 한 번!!!!
🏷 API 개발 고급 정리
✔️ 정리
1️⃣ 엔티티 조회
- 엔티티를 조회해서 그대로 반환 :
V1 - 엔티티 조회 후 DTO로 변환 :
V2 - 페치 조인으로 쿼리 수 최적화 :
V3 - 컬렉션 페이징과 한계 돌파 :
V3.1- 컬렉션은 페치 조인시 페이징이 불가능
- XToOne 관계는 페치 조인으로 쿼리 수 최적화
- 컬렉션은 페치 조인 대신에 지연 로딩을 유지하고,
hibernate.default_batch_fetch_size,@BatchSize로 최적화
2️⃣ DTO 직접 조회
- JPA에서 DTO를 직접 조회 :
V4 - 컬렉션 조회 최적화 ➡️ 일대다 관계인 컬렉션은
IN절을 활용해서 메모리에 미리 조회해서 최적화 :V5 - 플랫 데이터 최적화 ➡️
JOIN결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환 :V6
✔️ 권장 순서
1️⃣ 엔티티 조회 방식으로 우선 접근
- 페치조인으로 쿼리 수를 최적화
- 컬렉션 최적화
- 페이징 필요
hibernate.default_batch_fetch_size,@BatchSize로 최적화 - 페이징 필요X ➡️ 페치 조인 사용
- 페이징 필요
2️⃣ 엔티티 조회 방식으로 해결이 안 되면 DTO 조회 방식 사용
3️⃣ DTO 조회 방식으로 해결이 안되면 NativeSQL or 스프링 JdbcTemplate
📌 참고
- 엔티티 조회 방식은 페치 조인이나,
hibernate.default_batch_fetch_size,@BatchSize같이 코드를 거의 수정하지 않고 옵션만 약간 변경해서, 다양한 성능 최적화를 시도할 수 있다!- 반면에 DTO를 직접 조회하는 방식은 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다는 번거로움이 이따


Backend Developer