시작하기에 앞서
이 글은 Office(Word, Power point, Excel), 한글(hwp) 문서로부터 텍스트와 이미지를 추출하는 프로그램을 python으로 구현해보는 과정을 다루고 있다.
가벼운 생각으로 시작했으나, 듣도 못한 ole 파일 구조, png, jpg 등 바이너리 파일 구조에 대해 공부해야 했으며, 결국에는 다소 애매한 결과로 마무리됐다.
결과물보다는 작성자가 프로그램을 만드는데 거치는 과정과, 사서 고생을 하는 모습을 즐겁게 봐주시면 감사하겠다.
"저 doc, xls, ppt 파일 파싱하는 프로그램 찾고있어요! 급해요!"
하시는 분들은 이 글을 보지말고, 'Apache Tika'를 검색해보자.
본인은 tika의 존재를 이 프로젝트 시작하고 한 달 뒤에서야 알았다.
역시 구글링도 능력인가보다...
Office 파일구조를 알아보자
그냥 압축해제하면 되는 거 아닌가?
처음에는 문서로부터 텍스트와 이미지를 추출하는 것이 그닥 어렵지 않을 것이라고 생각했다.
위 사진과 같이 docx 파일은 확장자를 zip으로 변경한 후, 압축을 해제하면 파일의 구조를 확인할 수 있다.
docx 파일의 경우
이미지는 [word > media] 폴더에
텍스트는 [word > document.xml] 파일에서 확인 가능하다.
이 때문인지 구글에 'python extract docx', 'python docx2text' 등을 검색하고 코드를 보면 대부분 파일을 압축해제하는 방식을 사용한다.
[SWHL /ExtractOfficeContent - github 홈페이지]
https://github.com/SWHL/ExtractOfficeContent
[ankushshah89 / python-docx2txt - github 홈페이지]
https://github.com/ankushshah89/python-docx2txt
와 쉽다. 다른 문서들도 다 압축해제하면 되겠네?
xlsx 파일? 압축해제 된다.
pptx 파일? 압축해제 된다.
뭐야. doc 파일은 왜 안돼.
OLE 파일에 대하여
[위키피디아 - 복합 파일 이진 형식]
https://ko.wikipedia.org/wiki/복합_파일_이진_형식
[nurilab - OLE 파일 구조 분석 (1)]
https://nurilab.github.io/2020/05/04/fileformat_ole_1/
복합 파일 이진 형식(Compound File Binary Format, CFBF, Compound File, Compound Document format, Composite Document File V2 Document)은 여러 파일과 디렉터리를 하나의 파일에 저장하는 마이크로소프트의 파일 형식이다.
OLE 파일 구조는 마치 하나의 작은 파일 시스템과 같은 구조를 가지고 있다. 스트림은 문서 내용을 담고 있는 파일, 스토리지는 파일을 담는 폴더와 같다. 스토리지와 스트림의 내용은 문서 종류(doc, hwp, xls 등)에 따라 다를 수 있다.

요약하자면 doc, xls, ppt, hwp 파일은 이진수 형태로 파일마다 각자의 구조를 가지고 있다는 것이다.
아니 그럼 나보고 저 16진수로 적힌 것들 중에 필요한 부분을 추출해 내라고? 어떻게 하는데?
[Youtube - 최원혁 대표님의 OLE 파일 구조 기초 강의 Part 1]
https://www.youtube.com/watch?v=-z9cFe1qK1Q
놀랍게도 유튜브에 OLE 파일구조 분석과 관련된 강의 영상이 존재는 했다.
그러나 두 시간이 넘는 영상길이..
최원혁 대표님 죄송합니다...
제가 대학교 1시간 강의 들으면서도 졸아요....
일단 Python을 써보자
olefile
[PyPI - olefile]
https://pypi.org/project/olefile/
다행히도 python으로 ole파일을 구조별로 분리해주는 패키지가 존재했다.
이 덕분에 ole 파일구조를 분리하는 코드를 내가 직접 짤 필요가 없어졌다.
class olefile_text_extractor:
def __init__(self, filepath):
self.open(filepath)
def open(self, filepath):
self.ole = olefile.OleFileIO(filepath)
self.fileName = os.path.splitext(filepath)[0]
self.fileType = os.path.splitext(filepath)[1]
self.streamList = self.getOLEStreamList()
대충 위와 같이 객체를 만들고
def getOLEStreamList(self):
sl = []
for stream in self.ole.listdir(streams=True, storages=False):
d = stream[0]
if len(stream) > 1:
d = ""
for s in stream: d += (s+"/")
d = d[:len(d)-1]
sl.append(d)
return slstream 형태로 존재하는 모든 binary 파일 경로를 self.streamList에 추가하고
for stream in self.streamList:
self.ole.openstream(stream).read()와 같이 streamList에 있는 모든 binary 파일을 열어보며 텍스트를 추출하는 방식을 사용하고자 했다.
'그런데 아까 텍스트가 존재하는 경로가 따로 존재한다하지 않았나? 왜 굳이 모든 binary 파일을 열어보지?'
이게... hwp, doc, ppt, xls 각 파일마다
본문에 작성한 텍스트가 존재하는 경로가 따로 존재하는데...
- 각 파일별로 존재하는 본문 텍스트의 경로를 내가 직접 찾아야 한다.
- 'external link'와 같이 외부 데이터를 참조한 경우 본문이 아닌 다른 경로에 텍스트가 존재한다.
위 두가지의 이유로 그냥 모든 경로의 파일을 검사하기로 했다.
그렇다. 귀찮은게 크다.
텍스트 추출과 디코딩
디코딩 오류
여기서 내 머리를 깨는 문제가 연달아 발생한다.
def binData_to_ascii(self, binData):
data = binData.decode('ansi')
data = re.sub(asciiRegularExpression, '', data)
return dataUnicodeDecodeError: 'mbcs' codec can't decode bytes in position 0--1: No mapping for the Unicode character exists in the target code page.binary 데이터를 ascii 문자열로 변경하려고 하면 위와 같이 오류가 떠버린다.
def binData_to_utf16(self, binData):
data = binData.decode('utf-16-le')
data = re.sub(utf16RegularExpression, '', data)
return dataUnicodeDecodeError: 'utf-16-le' codec can't decode byte 0x00 in position 480: truncated datautf16으로 변경해도 오류가 뜬다.
어쩌라고
[MS-DOC] 공식 자료
계속 고민해봤자 의미가 없다고 생각하고
ms 홈페이지에서 자료를 찾아보기로 했다.
[MS-DOC: Word (.doc) Binary File Format]
https://msopenspecs.azureedge.net/files/MS-DOC/%5bMS-DOC%5d.pdf

이.. 이게 뭐고....
일단 디코딩 문제가 왜 생겼는지부터 확인해보자.
5번과 6번을 보면
텍스트 본문이 있는 wordDocument stream에 Unicode 블록과, ANSI(ascii) 블록이 함께 쓰이고 있음을 알 수 있다.
나는 이를 동시에 ascii나, Unicode로 변경하려고 해서 오류가 발생한 것이다.
그럼 이 문서를 읽고 ascii로 작성된 블럭과 Unicode로 작성된 블럭을 찾아 각자 따로 디코딩을 해야하는데....
아... 너무 어려워 보인다...
'아 이거 설명으로만 적혀있어서 어려운 거임. 밑에 실제 예시 적혀있음!'
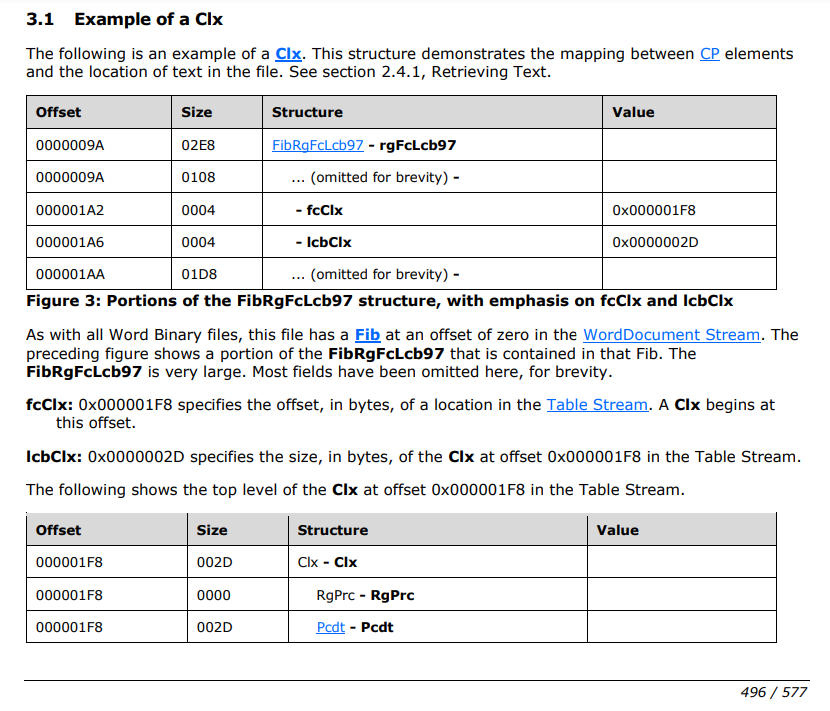
5페이지 분량의 텍스트 추출 예시가 적혀있다.
대략 6시간 정도 테스트해봤으나...
으아.. 중간에 막힌다.....
물어볼 사람도 없고....
아... 때려치자....
결국 찾은 야매(?) 방법
중간에 때려치고 일주일이 지났다.
편안하게 누워서 쉬어서 그런지 아이디어가 하나 생각났다.
'그냥 ascii는 1byte씩, utf16은 2byte씩 살펴보면서 디코딩되는 것만 하면 되지 않나?'
오 그럼 작업속도 엄청 느려지겠는데?
아 몰라 일단 해봐
def binData_to_utf16(self, binData):
data = b""
end = len(binData)
left = 0
right = 2
while right <= end:
if self.isFormat(binData[left:right], 'utf-16-le'):
data += binData[left:right]
left = right
right += 2
data = data.decode('utf-16-le')
return data
def isFormat(self, binText, format):
try:
binText.decode(format)
except:
return False
return Trueutf16의 경우 기본적으로 2byte 문자열이기 때문에
binary 데이터를 2byte씩 확인하는 방식을 사용했다.
자 그럼 어떻게 출력되나 보면

아 맞다.
모든 binary 파일을 디코딩했기 때문에,
텍스트가 아닌 쓰레기 값이 함께 출력된다.
asciiRegularExpression = r"[^a-zA-Z0-9 ~\.\-\[\]!@#$%^&*()_+|<>?:{}\r\n]+"
utf16RegularExpression = r"[^a-zA-Z0-9ㄱ-ㅎ가-힣 ~\.\-\[\]!@#$%^&*()_+|<>?:{}\r\n]+"한글, 영어, 숫자, 기호만을 남기기 위한 정규식을 작성하고
data = data.decode('utf-16-le')
data = re.sub(utf16RegularExpression, '', data)
return data정규식을 적용해주면....

?? 뭐여이게?
확인해보니 utf16으로 작성된 텍스트는 앞에 '\xFF\xFE'가 붙어 있어야한다.
아오 가지가지해요.
data = data.decode('utf-16-le')
data = re.sub(utf16RegularExpression, '', data)
return b'\xff\xfe'.decode('utf-16-le') + data
와! 아직은 쓰레기 글자들이 남아있지만, 아무튼 된다.
자 이제 ascii 문자열도 잘되나 보자
def binData_to_ascii(self, binData):
data = b""
end = len(binData)
left = 0
right = 1
while right <= end:
if self.isFormat(binData[left:right], 'ansi'):
data += binData[left:right]
left = right
right += 1
data = data.decode('ansi')
data = re.sub(asciiRegularExpression, '', data)
return dataascii 문자는 1byte 문자열이기 때문에
binary 데이터를 1byte씩 확인하였다.
1byte씩 확인하였기 때문에, utf16 보다 쓰레기 값이 많이 나온다.
그래도 일단 ascii로 작성된 영문이 잘 추출된다.
오케이 일단 텍스트 추출은 끝났다.
이미지 파일 추출
이미지 파일 시그니처
[SH1R0_HACKER - 헤더/푸터 시그니처 (JPEG, GIF, PNG, PDF, ZIP, ALZ, RAR)]
https://sh1r0hacker.tistory.com/90
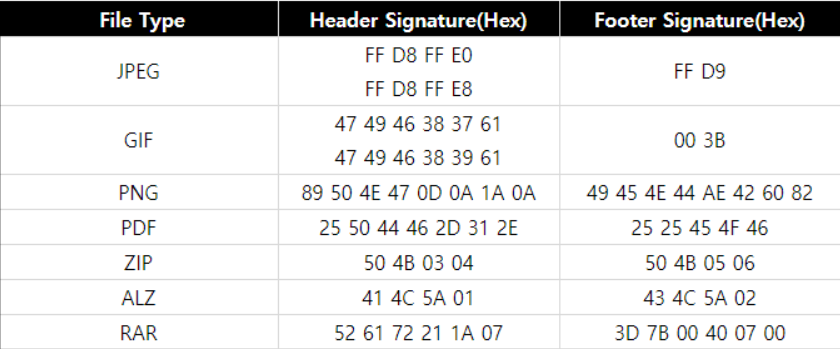
바이너리 구조의 파일들은 파일 타입을 나타내기 위해 시작지점에 고유의 헤드 시그니처를 가진다.
이중 PNG와 JPEG 헤더와 푸터를 사용해 이미지를 추출해 보았다.
코드 작성
imgType = ['.png', '.jpg']
imgHead = {
'.png': b'\x89\x50\x4E\x47\x0D\x0A\x1A\x0A',
'.jpg': b'\xff\xd8\xff',
}
imgTail = {
'.png': b'\x49\x45\x4E\x44\xAE\x42\x60\x82',
'.jpg': b'\xff\xd9',
}먼저 이미지 타입과 헤더, 푸터를 변수로 저장하고
def extract_img(self, binData, outFile):
for type in imgType:
head = [i.start() for i in re.finditer(imgHead[type], binData)]
print(len(head))
for start in head:
end = binData.find(imgTail[type], start)
fp = open(outFile + str(datetime.now().timestamp())+".png", 'wb')
fp.write(binData[start:end] + imgTail[type])
fp.close()바이너리 데이터 내부에 이미지 파일 헤더가 존재하는지 찾고,
존재한다면 해당 포인트부터 푸터가 존재하는 지점을 찾아
그 구역을 .png 파일로 저장하는 방식을 사용했다.
(실제 속성은 png가 아닌 jpg일 수도 있으나, 일단 이름은 png로 저장하게 함)
def get_images(self, outfilepath):
for stream in self.streamList:
self.extract_img(self.ole.openstream(stream).read(), outfilepath)이를 ole 파일을 분리하여 나온, 모든 스트림에 적용하는 방식을 사용했다.
실행결과
doc 파일을 테스트해보면 제법 잘된다.

문제는 xls나 ppt에서 추출할 때는 위와 같이 노이즈가 낀다는 것이다.
헤더와 푸터만으로 데이터를 긁어 왔다보니, 중간에 쓰레기 값이 끼거나,
실제로는 푸터가 아닌데 푸터로 인식하고 가져와 버렸을 가능성이 높다.
한글 문서 이미지 파일(BinData) 압축해제
한글(hwp, hwpx) 파일은 binData 경로에
'BIN0001.jpg'와 같은 이름으로 이미지 파일을 확인할 수 있다.
다만 이를 바로 열어보면, 위 사진처럼 내용을 확인할 수 없는데
[한글과컴퓨터 - 한글문서파일형식_5.0]
https://cdn.hancom.com/link/docs/%ED%95%9C%EA%B8%80%EB%AC%B8%EC%84%9C%ED%8C%8C%EC%9D%BC%ED%98%95%EC%8B%9D_5.0_revision1.2.pdf
한글은 문서 파일의 압축에 zlib.org의 zlib을 사용했다. zlib은 웹상에 소스가 공개되어 있는 공개 소프트웨어이다. zlib은 zlib License를 따르며, 이는 소스의 자유로운 사용이 가능하며 해당 소스를 사용한 2차 산출물에 대한 소스 공개 의무가 없다. 자세한 사항은 zlib에 포함되어 있는 라이센스 문서 파일을 참조하기 바란다
그래? 그럼 zlib으로 압축해제 하면 되겠네?
import zlib
f = open( 'BinData_BIN0001.jpg', 'rb' )
d = f.read()
f.close()
data = zlib.decompress(d)
fp = open("BinData_unzlib.png", 'wb')
fp.write(data)
fp.close()
뭔데 이건?
[Live Your IT - 한글 eps, zlib decompress 파이썬 코드]
https://liveyourit.tistory.com/257
구글에는 없는 게 없다고 하던가
다행히도 이를 해결할 방법을 이미 누군가가 정리해 두었다.
import zlib
f = open( 'BinData_BIN0001.jpg', 'rb' )
d = f.read()
f.close()
data = zlib.decompress( d , -15)
fp = open("BinData_unzlib.png", 'wb')
fp.write(data)
fp.close()
이미지도 예쁘게 잘 나온다.
자 코드도 다시 써보자
def hwp_img_zlib(self, binData, outFile):
data = zlib.decompress(binData, -15)
fp = open(outFile + str(datetime.now().timestamp())+".png", 'wb')
fp.write(data)
fp.close()zlib 압축해제를 함수로 만들어두고
def get_images(self, outfilepath):
for stream in self.streamList:
if('jpg' in stream):
print(stream)
self.hwp_img_zlib(self.ole.openstream(stream).read(), outfilepath)
else:
self.extract_img(self.ole.openstream(stream).read(), outfilepath)모든 스트림에서 이미지를 추출하는 get_images 함수에서
stream 이름 중 'jpg'가 포함됐을 때, zlib 함수를 실행하도록 수정했다.
이 글에서는 간단하게 설명했지만,
이 문제를 해결하려고 몇 시간을 구글을 뒤졌는지 모르겠다.
진짜 구글링도 능력인 걸 느낀다.
최종 결과
from datetime import datetime
import olefile
import zlib
import os
import re
asciiRegularExpression = r"[^a-zA-Z0-9 ~\.\-\[\]!@#$%^&*()_+|<>?:{}\r\n]+"
utf16RegularExpression = r"[^a-zA-Z0-9ㄱ-ㅎ가-힣 ~\.\-\[\]!@#$%^&*()_+|<>?:{}\r\n]+"
imgType = ['.png', '.jpg']
imgHead = {
'.png': b'\x89\x50\x4E\x47\x0D\x0A\x1A\x0A',
'.jpg': b'\xff\xd8\xff',
}
imgTail = {
'.png': b'\x49\x45\x4E\x44\xAE\x42\x60\x82',
'.jpg': b'\xff\xd9',
}
class olefile_text_extractor:
def __init__(self):
self.ole = None
self.fileName = None
self.fileType = None
self.streamList = []
def __init__(self, filepath):
self.open(filepath)
def open(self, filepath):
self.ole = olefile.OleFileIO(filepath)
self.fileName = os.path.splitext(filepath)[0]
self.fileType = os.path.splitext(filepath)[1]
self.streamList = self.getOLEStreamList()
def get_utf16_text(self):
utf16_text = ""
for stream in self.streamList:
utf16_text += self.binData_to_utf16(self.ole.openstream(stream).read())
return utf16_text
def get_ascii_text(self):
ascii_text = ""
for stream in self.streamList:
ascii_text += self.binData_to_ascii(self.ole.openstream(stream).read())
return ascii_text
def get_images(self, outfilepath):
for stream in self.streamList:
if('jpg' in stream):
print(stream)
self.hwp_img_zlib(self.ole.openstream(stream).read(), outfilepath)
else:
self.extract_img(self.ole.openstream(stream).read(), outfilepath)
def getOLEStreamList(self):
sl = []
for stream in self.ole.listdir(streams=True, storages=False):
d = stream[0]
if len(stream) > 1:
d = ""
for s in stream: d += (s+"/")
d = d[:len(d)-1]
sl.append(d)
return sl
def binData_to_ascii(self, binData):
data = b""
end = len(binData)
left = 0
right = 1
while right <= end:
if self.isFormat(binData[left:right], 'ansi'):
data += binData[left:right]
left = right
right += 1
data = data.decode('ansi')
data = re.sub(asciiRegularExpression, '', data)
return data
def binData_to_utf16(self, binData):
data = b""
end = len(binData)
left = 0
right = 2
while right <= end:
if self.isFormat(binData[left:right], 'utf-16-le'):
data += binData[left:right]
left = right
right += 2
data = data.decode('utf-16-le')
data = re.sub(utf16RegularExpression, '', data)
return b'\xff\xfe'.decode('utf-16-le') + data
def isFormat(self, binText, format):
try:
binText.decode(format)
except:
return False
return True
def extract_stream(self, outFile):
for stream in self.streamList:
print(stream)
fw = open(outFile + stream.replace('\x05', '_').replace('/', '_'), 'wb')
fw.write(self.ole.openstream(stream).read())
fw.close()
def extract_img(self, binData, outFile):
for type in imgType:
head = [i.start() for i in re.finditer(imgHead[type], binData)]
for start in head:
end = binData.find(imgTail[type], start)
fp = open(outFile + str(datetime.now().timestamp())+".png", 'wb')
fp.write(binData[start:end] + imgTail[type])
fp.close()
def hwp_img_zlib(self, binData, outFile):
data = zlib.decompress(binData, -15)
fp = open(outFile + str(datetime.now().timestamp())+".png", 'wb')
fp.write(data)
fp.close()결과적으로 코드는 위와 같이 작성되었다.
extractor = olefile_text_extractor('files/01.hwp')
fw = open('out_utf16.txt', 'w', encoding='utf-16-le')
fw.write(extractor.get_utf16_text())
fw.close()
fw = open('out_ascii.txt', 'w', encoding='ascii')
fw.write(extractor.get_ascii_text())
fw.close()
extractor.get_images('./')테스트를 해보면 hwp나 doc 파일에 대해서는
나름 만족할 만큼의 텍스트, 이미지 추출이 가능하다.
ppt, xls는...
텍스트도, 이미지도, 이게 추출이 된게 맞나 싶을 정도로 퀄리티가 낮다.
아 그리고 원래는 docx, pptx, xlsx도 다 추출하려 했는데, ole 파일 추출하는 것 구현하느라 잊고 있었다.
뭐, 어쩌겠나..
이 이상으로 파고들기에는 시간이 아까워 여기서 마무리하기로 했다.
나름 재미있었다.
뭔가 사서 고생하는 느낌이지만,
아무튼 내가 원하는 기능이 하나씩 된다는 뿌듯함? 그런 게 있었다.
다만 유익했는가는.. 글쎄다?
내가 정보 보안이나 리버싱쪽을 전공으로 할 생각이 없어 잘 모르겠다 ㅋㅋㅋㅋ
