
안녕하세요. 소리입니다 👋
이번 글에서는 최단 거리 및 경로 탐색에서 빼놓을 수 없는 다익스트라 알고리즘에 대해 알아볼게요.
🚀 다익스트라 알고리즘이란?
다익스트라는 그래프의 특정 위치에서 다른 정점까지의 최단 경로를 구하는 알고리즘이에요.
실생활에서 내비게이션 시스템이나 네트워크 흐름 제어, 물류 이동 최적화 등 많은 곳에서 쓰이고 있어요.
다익스트라 알고리즘의 기본 원리는 그리디(Greedy)예요.
어떤 최단 경로에 경유하는 정점 가 있다면, 시작 정점부터 까지의 경로도 최단 경로라는 사실을 이용하기 때문이에요.
따라서 시작 정점에서부터 최단 경로를 구하고, 이 경로에서 계속 뻗어가며 탐색하면 확정적으로 모든 정점의 최단 경로를 구할 수 있게 돼요.
⚠️ 주의!
그래프에 음수값을 가지는 간선이 있다면 다익스트라 알고리즘을 사용할 수 없어요.
그래프에 음수값이 있다면 음수 간선을 처리할 수 있도록 코드를 수정하거나, 벨먼-포드 알고리즘을 활용해야 해요.
🧐 다른 최단 경로 알고리즘도 있어요!
벨먼-포드 알고리즘
→ 음수 간선 처리가 가능해요. 다익스트라보다 느리지만, 더 유연하게 사용할 수 있어요.플로이드-워셜 알고리즘
→ 한번에 모든 정점에서 다른 정점까지의 최단 경로를 구해요.
과정
- 최단 거리 배열 초기화
- 시작 정점의 거리를 0으로 설정합니다.
- 나머지 모든 정점은 무한대()로 초기화합니다.
- 방문 가능한 모든 정점에 대해 반복
- 방문하지 않은 정점 중 시작 정점으로부터 거리가 가장 짧은 정점을 선택합니다.
- 선택된 정점을 거쳐갈 때 거리가 짧아지는 정점을 확인하고, 최단 거리를 갱신합니다.
- 선택된 정점의 상태를 방문 완료로 바꿉니다.
예시
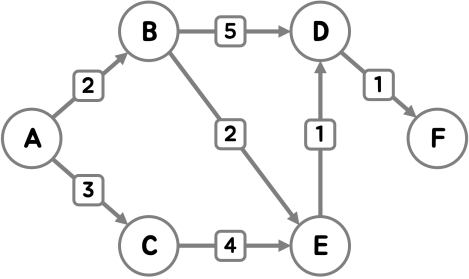
다음 그래프에서 A를 시작점으로 잡고 다른 정점들과의 최단 거리를 구해볼게요.
먼저 최단 거리 배열 와 정점의 방문 여부를 저장할 배열 를 초기화할게요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | ||||||
| false | false | false | false | false | false |
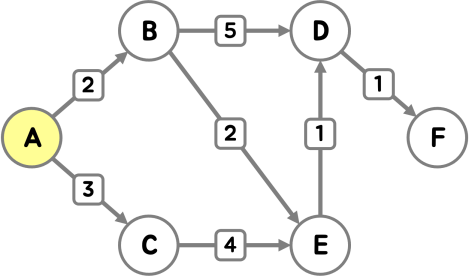
먼저 시작점인 정점 A에 방문합니다.
A를 통해 B, C의 경로를 단축할 수 있기 때문에, 최단 거리를 갱신했어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | ||||
| true | false | false | false | false | false |
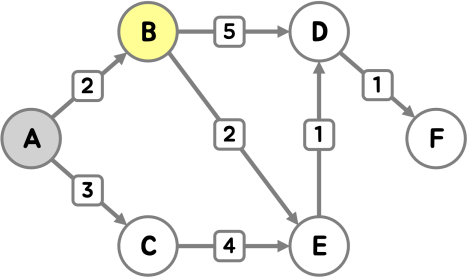
다음으로 가장 거리가 가까운 정점 B에 방문했어요.
마찬가지로, B를 통해 D, E의 경로를 단축할 수 있기 때문에, 최단 거리를 갱신했어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 7 | 4 | ||
| true | true | false | false | false | false |
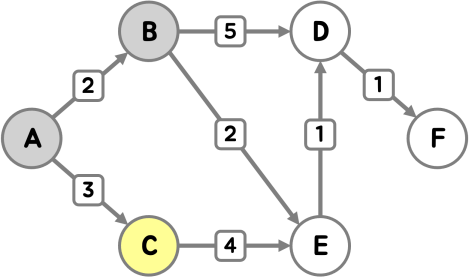
세 번째로 정점 C에 방문했어요.
C를 통해 E를 갈 수 있지만, C를 통하는 경로보다 기존 경로가 효율적이기 때문에 최단 거리 갱신이 이루어지지 않았어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 7 | 4 | ||
| true | true | true | false | false | false |
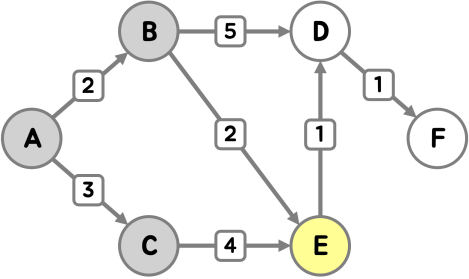
다음으로 정점 E에 방문했어요.
E를 통해 D로 가는 방법이 기존 경로보다 효율적이기 때문에 최단 거리 갱신이 이루어졌어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 5 | 4 | ||
| true | true | true | false | true | false |
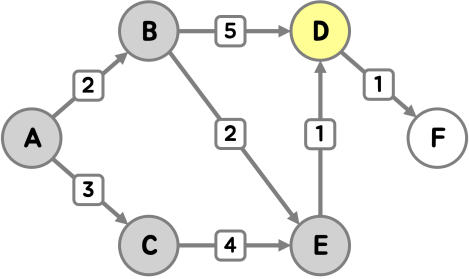
이번에는 정점 D 차례예요.
F의 최단 거리가 새롭게 갱신되었어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 5 | 4 | 6 | |
| true | true | true | true | true | false |
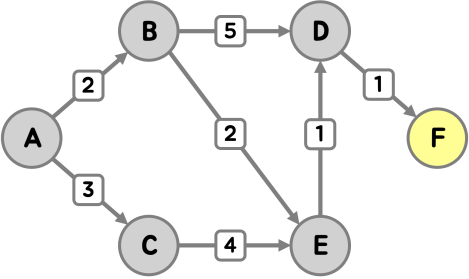
마지막으로, 정점 F를 방문했어요.
F에서 갈 수 있는 정점이 없기 때문에 최단 거리는 갱신되지 않았어요.
가능한 모든 정점 방문이 끝나, 알고리즘이 종료되었어요.
의 값에 각 정점 간 최단 거리가 담겨 있어요.
| 정점 A | 정점 B | 정점 C | 정점 D | 정점 E | 정점 F | |
|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 5 | 4 | 6 | |
| true | true | true | true | true | true |
🧑💻 다익스트라 구현하기
다익스트라 알고리즘의 구현은 방문할 정점 탐색을 어떻게 하느냐에 따라 두 종류로 나뉘어요.
구현한 모든 코드에 각 정점의 이전 정점을 저장하는
prev배열을 넣었어요.
거리가 아닌 경로가 필요한 경우 도착 정점에서부터 이전 정점 정보를 읽어나가며 구할 수 있어요.
선형 탐색 사용
첫 번째는 선형적으로 탐색하는 방법이에요.
구현은 매우 쉬워지지만, 매 차례마다 모든 정점을 확인해야 하다 보니 시간이 오래 소요되는 방법이에요.
- 시간 복잡도:
V: 정점 개수E: 간선의 수
Python
def dijkstra(graph, start):
# 최단 거리 배열 및 방문 여부 저장 배열 초기화
dist = [math.inf for _ in range(len(graph))]
prev = [None for _ in range(len(graph))]
visited = [False for _ in range(len(graph))]
dist[start] = 0
while True:
# 방문 가능한 노드 중 가장 가까운 노드 찾기
visit_idx = 0
visit_dist = math.inf
for i in range(len(graph)):
if not visited[i] and dist[i] < visit_dist:
visit_idx = i
visit_dist = dist[i]
# 방문할 수 있는 노드가 없다면 알고리즘 종료
if visit_dist == math.inf:
# 경로가 필요하다면 prev 반환
return dist
visited[visit_idx] = True
# 최단 거리 배열 갱신
for (i, v) in graph[visit_idx]:
if dist[i] > dist[visit_idx] + v:
dist[i] = dist[visit_idx] + v
prev[i] = visit_idxRust
fn dijkstra(graph: &Vec<Vec<(usize, u32)>>, start: usize) -> Vec<u32> {
// 최단 거리 배열 및 방문 여부 저장 배열 초기화
let mut dist = vec![u32::MAX; graph.len()];
let mut prev = vec![None; graph.len()];
let mut visited = vec![false; graph.len()];
dist[start] = 0;
loop {
// 방문 가능한 노드 중 가장 가까운 노드 찾기
let mut visit_idx = 0;
let mut visit_dist = u32::MAX;
for i in 0..graph.len() {
if !visited[i] && dist[i] < visit_dist {
visit_idx = i;
visit_dist = dist[i];
}
}
// 방문할 수 있는 노드가 없다면 알고리즘 종료
if visit_dist == u32::MAX {
// 최단 경로가 필요하다면 prev 반환
return dist;
}
visited[visit_idx] = true;
// 최단 거리 배열 갱신
for (i, v) in graph[visit_idx].iter() {
if dist[*i] > dist[visit_idx] + v {
dist[*i] = dist[visit_idx] + v;
prev[*i] = Some(visit_idx);
}
}
}
}우선순위 큐 사용
두 번째는 우선순위 큐를 이용하는 방법이에요.
이때 우선순위 큐 내부 값을 감소한 후 다시 힙 구성을 수행하는 decrease-key 연산에 대한 구현이 필요해 구현은 복잡해지지만, 탐색 시간을 으로 줄일 수 있어요.
보통 다익스트라를 구현할 때엔 우선순위 큐를 사용하는 방법을 사용해요.
- 시간 복잡도:
V: 정점 개수E: 간선의 수
Python
def dijkstra(graph, start):
# 최단 거리 배열 및 방문 여부 저장 배열 초기화
dist = [math.inf for _ in range(len(graph))]
prev = [None for _ in range(len(graph))]
visited = [False for _ in range(len(graph))]
dist[start] = 0
# 우선순위 큐에 시작점 삽입
pq = PriorityQueue()
pq.push(start, 0)
# 방문이 가능한 정점이 없을 때까지 탐색
while (pop := pq.pop()) is not None:
idx, d = pop
visited[idx] = True
# 최단 거리 배열 갱신
for next, cost in graph[idx]:
if not visited[next] and dist[next] > d + cost:
dist[next] = d + cost
prev[next] = idx
# 이미 큐에 담겨 있는 정점이라면 큐 내부 데이터를 갱신
if pq.contains_key(next):
pq.change_key(next, dist[next])
else:
pq.push(next, dist[next])
# 경로가 필요하다면 prev 반환
return dist
# queue 및 heapq 모듈에서 지원하지 않는 추가 연산을 사용하기 위해 우선순위 큐 직접 구현
class PriorityQueue:
def __init__(self):
self.heap = []
self.hash = {}
def push(self, key, value):
self.heap.append((key, value))
self.hash[key] = len(self.heap) - 1
self.sift_up(len(self.heap) - 1)
def pop(self):
if len(self.heap) == 0:
return None
ret = self.heap[0]
del self.hash[ret[0]]
if len(self.heap) > 1:
self.heap[0] = self.heap.pop()
self.hash[self.heap[0][0]] = 0
self.sift_down(0)
else:
self.heap.pop()
return ret
def contains_key(self, key):
return key in self.hash
def change_key(self, key, value):
if self.contains_key(key):
self.heap[self.hash[key]] = (key, value)
self.sift_down(self.hash[key])
self.sift_up(self.hash[key])
def sift_down(self, idx):
parent = idx
child = idx << 1 | 1
while child < len(self.heap):
if child + 1 != len(self.heap) and self.heap[child][1] > self.heap[child + 1][1]:
child += 1
if self.heap[parent][1] <= self.heap[child][1]:
break
self.heap[parent], self.heap[child] = self.heap[child], self.heap[parent]
self.hash[self.heap[parent][0]] = parent
self.hash[self.heap[child][0]] = child
parent = child
child = parent << 1 | 1
def sift_up(self, idx):
while idx > 0:
parent = (idx - 1) >> 1
if self.heap[parent][1] <= self.heap[idx][1]:
break
self.heap[parent], self.heap[idx] = self.heap[idx], self.heap[parent]
self.hash[self.heap[parent][0]] = parent
self.hash[self.heap[idx][0]] = idx
idx = parentRust
fn dijkstra(graph: &Vec<Vec<(usize, u32)>>, start: usize) -> Vec<u32> {
// 최단 거리 배열 및 방문 여부 저장 배열 초기화
let mut dist = vec![u32::MAX; graph.len()];
let mut prev = vec![None; graph.len()];
let mut visited = vec![false; graph.len()];
dist[start] = 0;
// 우선순위 큐에 시작점 삽입
let mut pq = PriorityQueue::new();
pq.push(start, 0);
// 방문이 가능한 정점이 없을 때까지 탐색
while let Some((idx, d)) = pq.pop() {
visited[idx] = true;
// 최단 거리 배열 갱신
for (next, cost) in graph[idx].iter() {
if !visited[*next] && dist[*next] > d + cost {
dist[*next] = d + cost;
prev[*next] = Some(idx);
// 이미 큐에 담겨 있는 정점이라면 큐 내부 데이터를 갱신
if pq.contains_key(*next) {
pq.change_key(*next, dist[*next]);
}
else {
pq.push(*next, dist[*next]);
}
}
}
}
// 경로가 필요하다면 prev 반환
dist
}
// 힙 구조로 우선순위 큐 구현, 해시를 덧붙여 추가 연산 수행할 수 있도록 구조체 정의
struct PriorityQueue {
heap: Vec<(usize, u32)>,
hash: HashMap<usize, usize>
}
// BinaryHeap에서 지원하지 않는 추가 연산을 사용하기 위해 우선순위 큐 직접 구현
impl PriorityQueue {
fn new() -> Self {
Self { heap: vec![], hash: HashMap::new() }
}
fn push(&mut self, key: usize, value: u32) {
self.heap.push((key, value));
self.hash.insert(key, self.heap.len() - 1);
self.sift_up(self.heap.len() - 1);
}
fn pop(&mut self) -> Option<(usize, u32)> {
if self.heap.is_empty() {
return None;
}
let ret = self.heap[0];
self.hash.remove(&ret.0);
if self.heap.len() > 1 {
self.heap[0] = self.heap.pop().unwrap();
self.hash.insert(self.heap[0].0, 0);
self.sift_down(0);
}
else {
self.heap.pop();
}
Some(ret)
}
fn contains_key(&self, key: usize) -> bool {
self.hash.contains_key(&key)
}
fn change_key(&mut self, key: usize, value: u32) {
if let Some(&idx) = self.hash.get(&key) {
self.heap[idx] = (key, value);
self.sift_down(idx);
self.sift_up(idx);
}
}
fn sift_down(&mut self, idx: usize) {
let len = self.heap.len();
let mut parent = idx;
let mut child = idx << 1 | 1;
while child < len {
if child + 1 != len && self.heap[child].1 > self.heap[child + 1].1 {
child += 1;
}
if self.heap[parent].1 <= self.heap[child].1 {
break;
}
self.heap.swap(parent, child);
self.hash.insert(self.heap[parent].0, parent);
self.hash.insert(self.heap[child].0, child);
parent = child;
child = parent << 1 | 1;
}
}
fn sift_up(&mut self, mut idx: usize) {
while idx > 0 {
let parent = (idx - 1) >> 1;
if self.heap[parent].1 <= self.heap[idx].1 {
break;
}
self.heap.swap(parent, idx);
self.hash.insert(self.heap[parent].0, parent);
self.hash.insert(self.heap[idx].0, idx);
idx = parent;
}
}
}지금까지 다익스트라의 개념과 두 가지 구현 방법을 살펴보았습니다.
다익스트라는 그 어떤 것보다 실생활에 가까운 알고리즘이에요.
따라서 다익스트라에 대해 배우면, 다양한 문제를 해결하는 데 큰 도움이 될 거에요.
다음에도 유익한 내용으로 찾아올게요! 😁
