UTF(Univercsal Coded Character Set Transformation Format - N - bit, Unicode Transformation format)로 뒤에 숫자는 해당 비트를 이용하는 전 세계 문자 표현 방법이라고 생각하면 좋을 것 같다
UTF-8과 UTF-16은 Unicode를 표현하는 Encoding 방식이다
UTF-8과 UTF-16의 기본 차이는 문자 하나를 표현할 때 사용할 최소 byte를 의미한다고 볼 수 있다
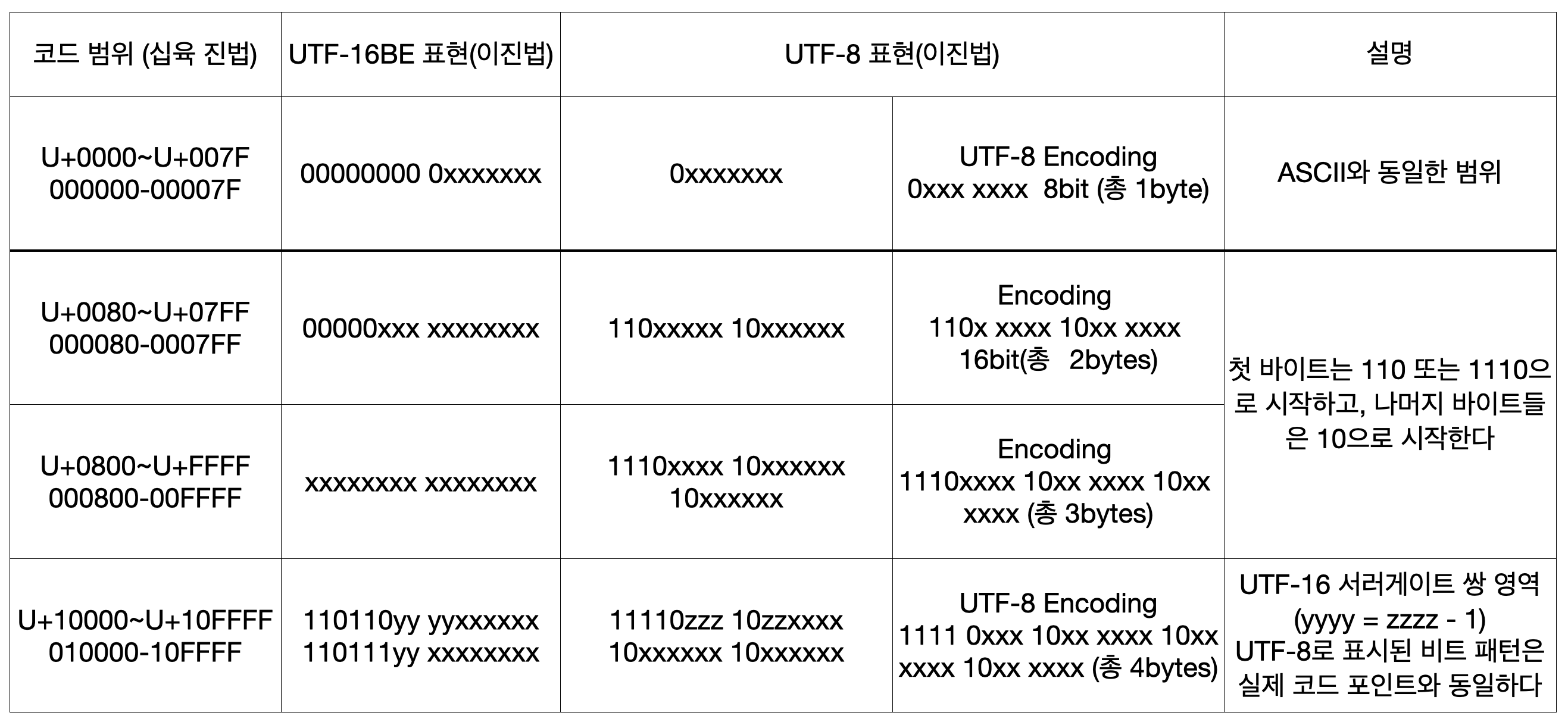
UTF-8의 규칙성
1. U+0000 ~ U+007F( 기존 ASCII의 0~127)은 8byte로 표현한다.
- 가장 첫 바이트의 처음 1이 나오는 갯수만큼 해당 문자의 표현 byte가 결정된다.
110 : 2bytes, 1110 : 3bytes, 11110 : 4bytes.
- 뒤에 따라오는 바이트에는 모두 10으로 시작하게 하였다.
UTF16도 표현방식이 표에 나타나 있는데 UTF16은 아스키와 동일한 범위를 표현할 때도 앞에 0으로 채워서 16비트가 최소로 이용되며 3바이트 이용 없이 2 or 4 바이트 사용만 있다
UTF8에서 3바이트가 필요한 표현을 2바이트로 표현해낸다
즉, 영문만 사용하는 경우 UTF8은 1바이트만 사용되고, UTF16은 기본 2바이트, 그리고 UTF8은 표현범위에 따라 각기 2,3,4바이트를 사용하는데 UTF16은 2바이트 혹은 4바이트를 사용한다
UTF8에서 3바이트로 표현되는 문자들은 모두 UTF16에서는 2바이트로 표현되므로 문서가 3바이트에 해당하는 경우 UTF16을 선택하면 더 효율적일 수 있다
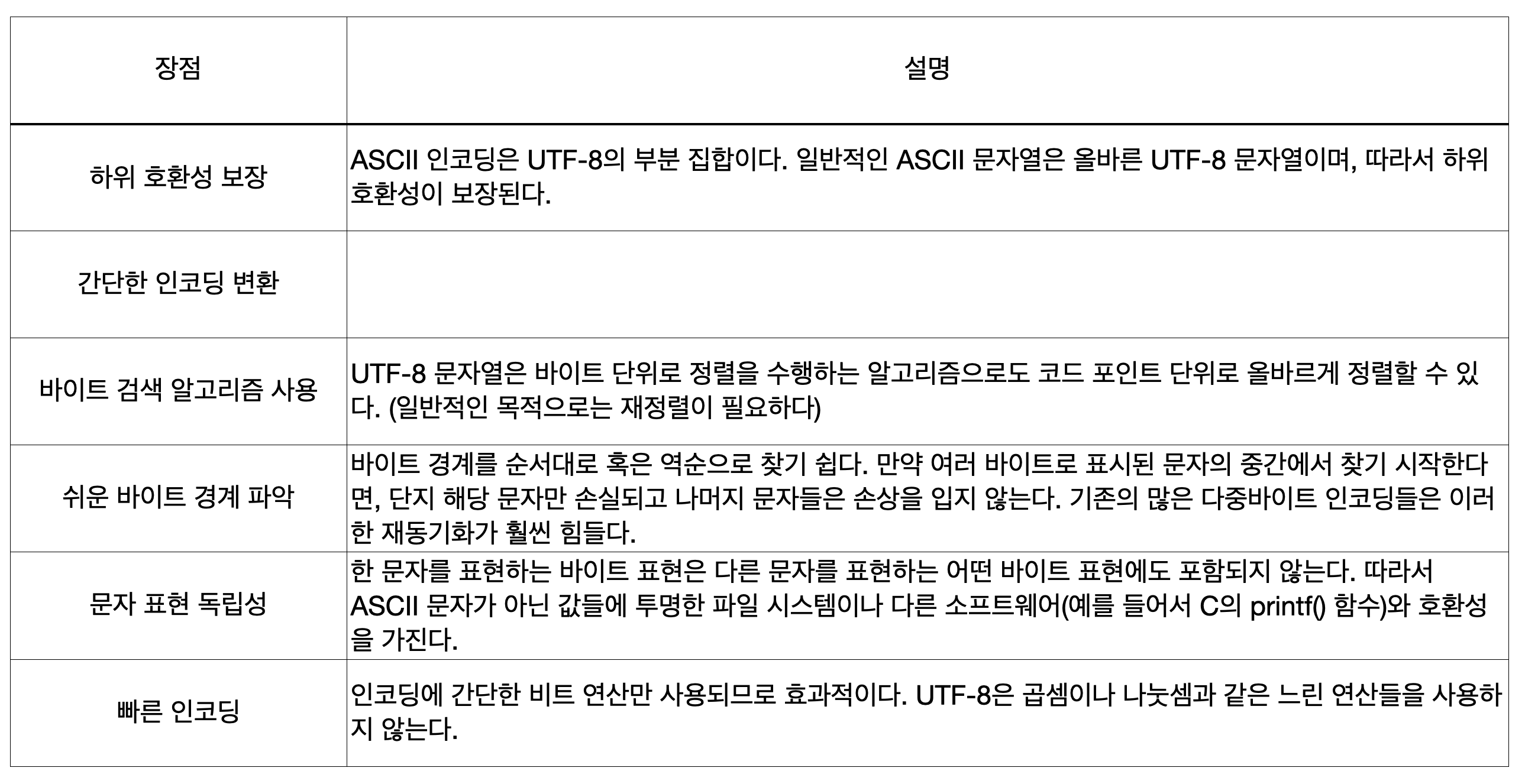
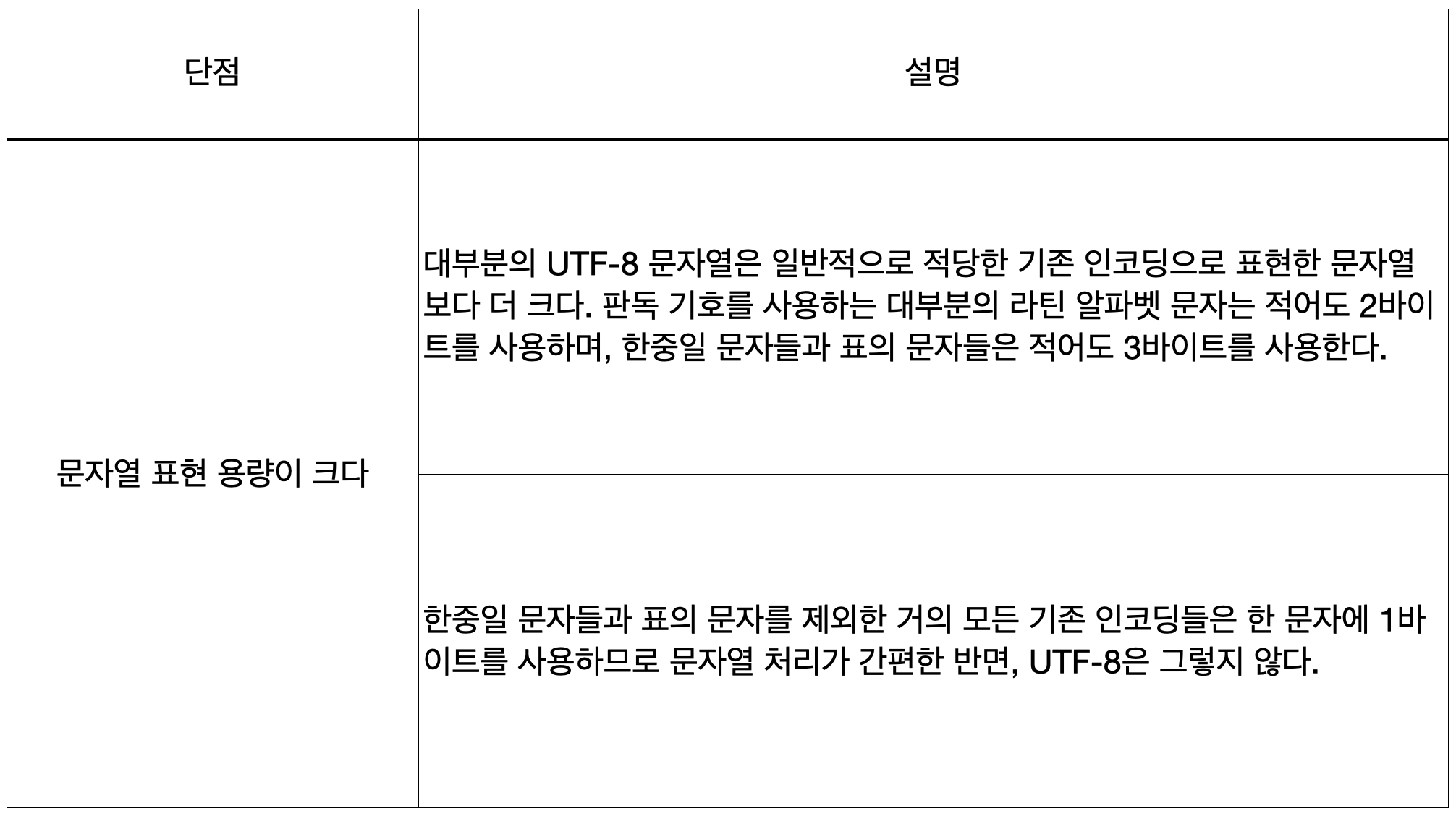
UTF-8 장점 / 단점
UTF-16
U+0000~U+FFFF : BMP(Basic Multilingual Plane), 가장 많이 쓰는 문자들이 이 영역에 있다
단, U+D800~U+DFFF 영역은 사용되지 않는다.
U+10000~U+10FFFF : Supplementary Planes 라 불린다, 계산을 거쳐 4bytes로 저장한다
1. Code Point - 0x10000 = ( 0x0 ~ 0xFFFFF) : 20bit 영역만 남김
2. 상위 10-bit(0~0x03FF) + 0xD800 을 high surrogate로 할당한다.
(0xD800~ 0xDBFF)
3. 하위 10-bit(0~0x03FF) + 0xDC00 을 low surrogate로 할당한다.
(0xDC00~0xDFFF)high surrogate / low surrogate로 활용하여 U+10000 이상 code points를 표현한다
대부분 UTF-8를 많이 사용한다
Web Encoding 의 대부분은 UTF-8이 차지하고 있다
7bit ASCII 영역은 UTF-8에서 동일하게 Encoding되어 있다
저장, 통신 용량을 고려하지 않는다면 UTF-8를 사용한다
하지만 용량이 민감하다면 UTF-8, UTF-16중에서 고민해야한다
문서에서 많이 사용된 CodePoint들이 몇 Byte로 표현될지 고민 후 결정하면 저장, 통신 용량을 아낄 수 있다
예를 들어 영문자들로 가득찬 문서의 경우 UTF-8로 표현하면 대부분 1byte로 표현되고 UTF-16으로 표현하면 2byte로 표현되니 UTF-8이 유리하고,
한글의 경우 UTF-8은 3byte, UTF-16은 2byte로 표현되니 UTF-16이 유리하다
