RDS란?
Relational Database Service의 약자
세상에 존재하는 DB service를 제공하며 DB중에서도 SQL에 속한다.
- RDS가 지원하는 엔진
: Microsoft SQL, Oracle, MySQL, Aurora, Maria DB 등
: Aurora는 AWS에서 직접 운영하는 DB이다(FreeTier제공 X)
-> Aurora는 읽기 복제본 구성이 간편, 기존 MySQL보다 더 좋은 성능
Managed DB Service, RDS
DB : 구조화되어 있고 여러 사람이 활용할 목적으로 통합 관리되는 정보
DBMS : DB 정보 이용이 더욱 쉽도록 효율적으로 관리해주는 시스템
RDBMS : 정보를 Table 구조로 사전 정의하여 처리하는 모델
DBMS는 분명 유용하지만, 이 DBMS를 유지하고 관리하는 업무가 만만치 않다
1) On-Premise 환경에서 DB 사용시 영역 전체를 관리해야 한다.
2) EC2 위에 DBMS 설치하여 사용하는 경우
: AWS에서 [물리 서버관리/OS설치] 영역만 관리, 나머지는 사용자 영역
3) RDS 기반에서 DB를 구성하는 경우
:[OS패치/DB설치 및 패치/DB백업/가용성관리]영역을 추가로 관리
Managed Service : 사용자의 관리 업무 일부를 떼어 대신 관리해주는 서비스
RDS : RDBMS를 대상으로 DB설치,패치,백업/이중화 영역을 관리해주는 Managed DB서비스
다만, 사용자는 RDS 인스턴스의 OS레벨 권한은 획득할 수 없다.
그렇기에 User가 기존 방식대로 RDS 인스턴스에 접근하여 DB Configuration이나 플러그인 설치와 같은 작업을 할 수 없다.
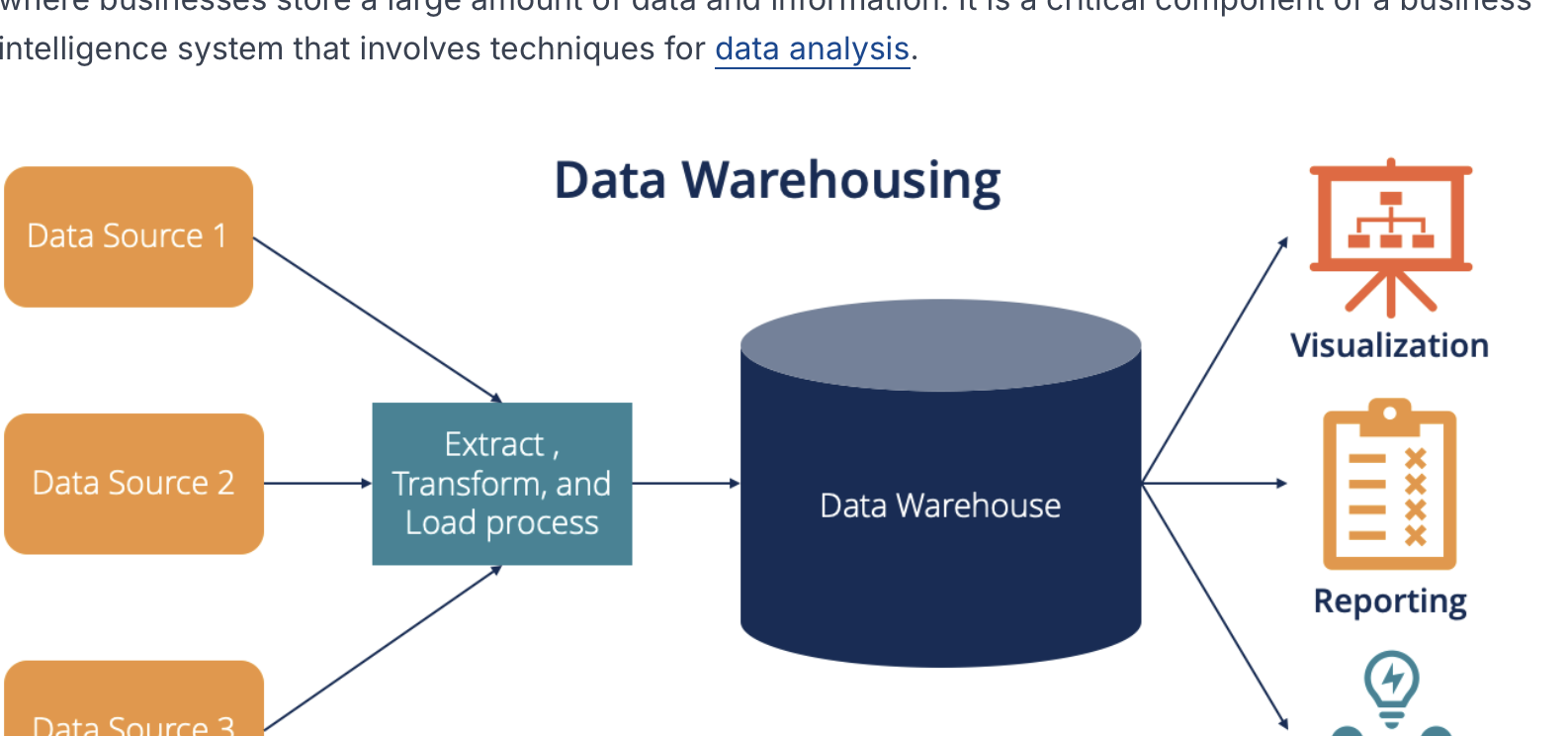
Data Warehousing
- Business Intelligence
: 엄청난 양의 빅데이터를 불러올 때 사용되는 시스템 - 리포트 작성, 데이터분석시 사용(Production Database -> Data Warehousing)
- 매우 방대한 분량의 데이터 로드시 사용
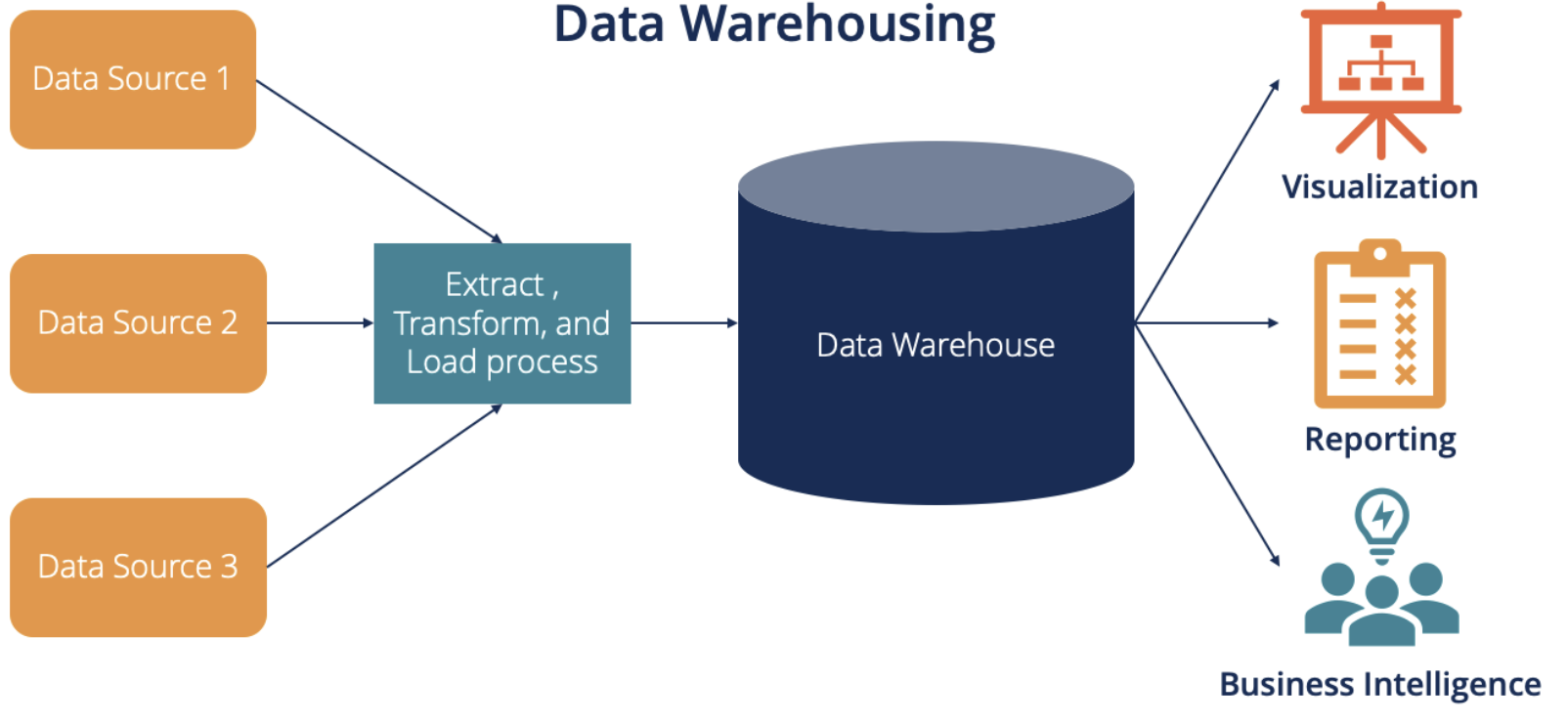
OLTP VS OLAP
- OLTP : Insert와 같이 종종 사용되어지는, 혹은 규모가 작은 데이터를 불러올 때 사용되는 SQL쿼리가 필요할 때 유용
ex) order #210에만 해당되는 customer정보 Insert
- OLAP : 매우 큰 데이터를 불러올 때 사용, 주로 덩치가 큰 SELECT 쿼리가 사용된다 (select 구문 join시 사용)
-> Transcation Processing이 사용되지 않는다
ex)특정 회사 부서의 Net Profit,Products
Database Backups
AWS RDS의 백업 :
1) Automated Backups (자동 백업)
2) DB Snapshots (데이터베이스 스냅샷)
Automated Backups(AB) - 자동백업
- Retention Period(1~35일) 안의 어떤 시간으로든 돌아가게 할 수 있다
- AB는 그날 생성된 스냅샷과 Transcation logs(TL)을 생성한다
-> 유저가 복구 희망하는 시간이 있다면 위를 참조해 백업 - 디폴트로 AB기능이 설정되어 있으며 백업정보는 S3에 저장한다
- AB동안 약간의 I/O suspenstion이 존재할 수 있음 -> Latency
- AB기능은 우리가 rds인스턴스를 만들 때 디폴트로 설정되어 있는 기능
- 백업 정보 = s3버켓에 저장된다 (특정 조건 도달시 s3는 무료 X)
Database Snapshots(데이터베이스 스냅샷)
- 주로 사용자에 의해 실행됨
- 원본 RDS Instance를 삭제해도 스냅샷은 존재한다 (vsAB)
: AB백업 기능은 인스턴스 삭제시 스냅샷이 모두 사라진다
데이터베이스 백업
원본 RDS 인스턴스를 가지고 새로운 데이터베이스를 복원 시 우리는 전혀 새로운 RDS인스턴스와 그에 해당하는 엔드포인트가 생성된다
-> 2개는 서로 다른 객체가 된다
RDS - Multi AZ, Read Replicas
백업과 겹치기는 하지만 완전히 백업 기능이라고 말할 수는 없다
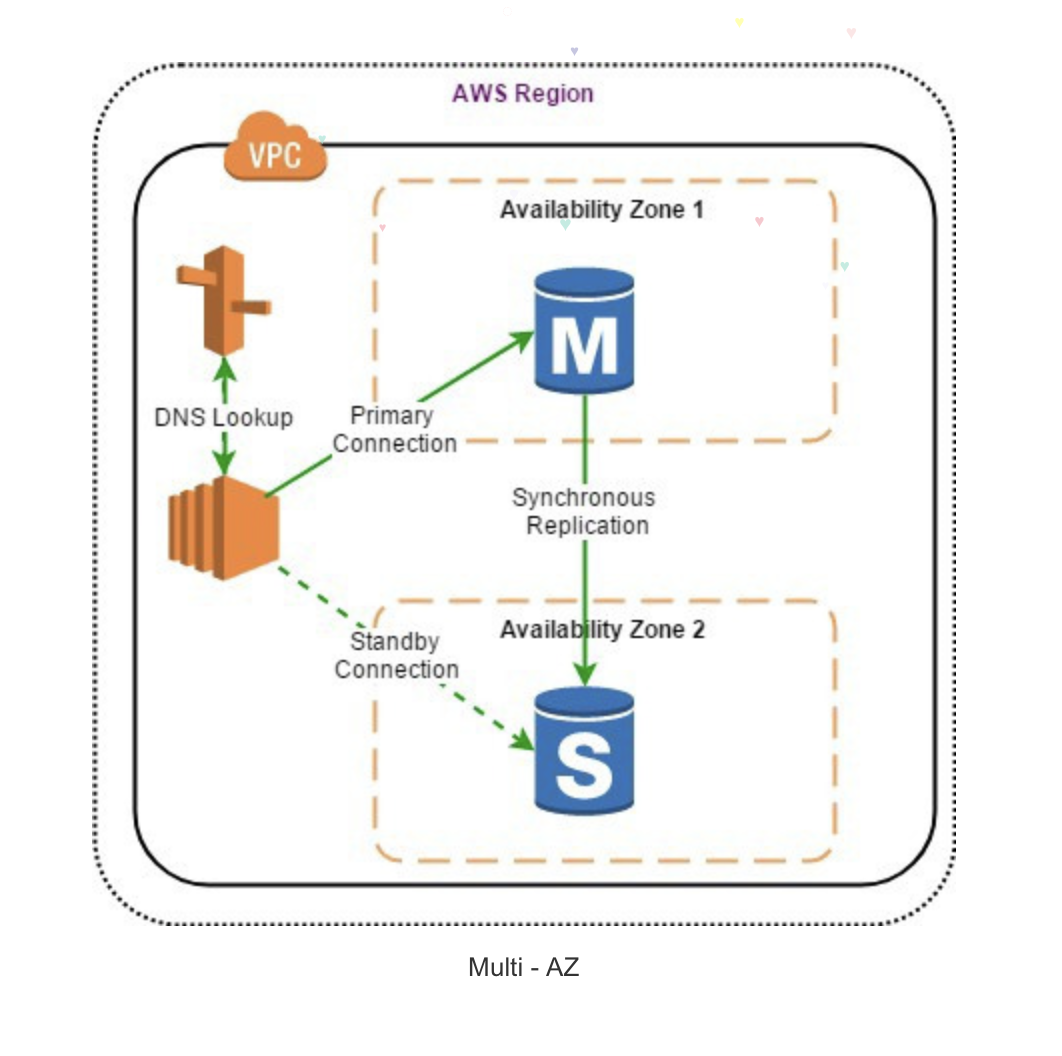
Multi AZ
: Multi Availability Zones (고가용성을 위한 이중화 기능)
- 원래 존재하는 RDS DB에 무언가 변화가 생길 때 다른 Availability Zone에 똑같은 복제본이 만들어진다(=Synchronize) -> 동시다발적
- Standby역할 하는 인스턴스에는 별도 접근하거나 사용 불가
- AWS에 의해 자동으로 관리가 이루어진다 (No admin intervention)
- 원본 RDS DB에 문제가 생길 시 자동으로 다른 AZ의 복제본이 사용된다
- RDS 인스턴스의 속성을 변경하는 과정도 MultiAZ 활용해 진행
- Disaster Recovery Only!
-> Multi AZ는 복제본을 만든다고 성능 개선은 없다
-> 성능 개선을 기대하기 위해서는 Read Replica가 사용되어야 한다
장애 대응 방식
: DNS를 이용해서 수행
: Master 서버에 장애가 발생 -> 기존 RDS Endpoint가 가리키던 Master 노드의 IP가 Slave 노드의 IP로 변경 -> Slave는 Master로 승격된다
Read Replica
- Production DB의 읽기 전용 복제본이 생성된다
- 주로 Read-Heavy DB작업시 효율성의 극대화를 위해 사용된다(Scaling)
- Disaster Recovery가 주목적이 아니다
- 최대 5개 Read Replica DB가 허용된다
- Read Replic의 Read Replica에서도 생성이 가능 (단 Latency 발생)
- 각각의 Read Replica는 자기만의 고유 Endpoint 존재
-> RDS DB는 IP주소가 아닌 엔드포인트로 그들의 정체를 가려낼 수 있다
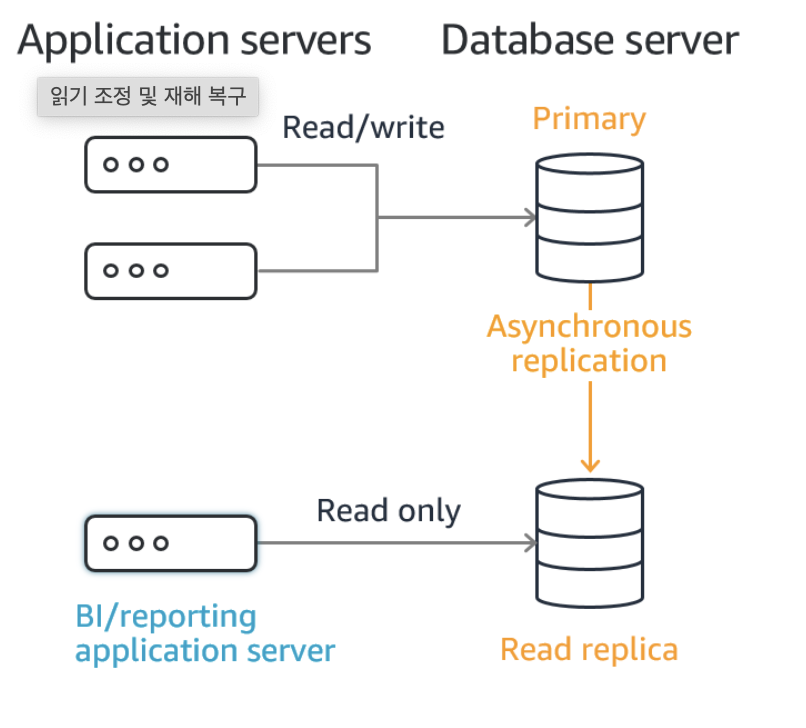
: 인스턴스에서 읽고 쓸 때 복제본이 생성
: 대부분의 Incoming Traffic이 Read Traffic일 때 Main Production DB로 모두 연결시키는 것이 아니라 하나의 EC2 인스턴스를 각각의 Read Replica로 연결시킬 수 있다 따라서 Main DB의 Work Load를 낮추고 성능 개선의 효과도 누릴 수 있다.
: Read Replica에서 Read Replica 생성 O (같은 AZ 혹은 다른 AZ에 생성 O)
????
그럼 Main DB에서 Multi AZ생성하고 Read Replica 생성한 다음 이 Read Replica에 대한 Multi az도 Read Replica 복제본도 생성 가능? -> 그럼 무한 자가 증식 가능?
가용능력을 갖추고 그 위에 replica가 존재할 수 있기에 그럼 무한증식은 안될 것
????
RDS, EC2 둘 중 어떤게 위로 올라갈까?
VPC위에 올라가는 둘 다 인스턴스 개념이라 굳이 우선순위의 개념으로 보기보다는 상호보완적인 느낌으로 볼 수 있다
