1197번 최소 스패닝 트리
https://www.acmicpc.net/problem/1197
문제 처음 봤을 때 무슨 말인지 하나도 모르겠어서 절망했던 문제.. 스패닝트리가 무엇인지 가중치는 또 무슨 말인지 하나하나 찾아보며 풀었다.
그런데 스패닝 트리에 대해 찾아보다 보니 이걸 크루스칼 알고리즘이라는 것으로 풀어야하고 그러려면 또 Union-find라는게 있어서 그걸 활용해야한다고.. 참 힘들었다..
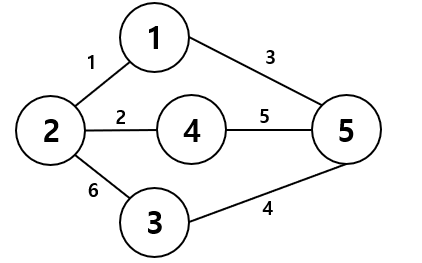
스패닝트리(신장트리)란?
- 모든 정점이 포함되어있는 그래프
- 정점이 연결되어있으며 사이클이 존재하지 않아야함
여기서 사이클이란 하나의 정점이 2개의 간선과 연결되어있는 것을 뜻한다. 12345가 서로 겹침 없이 연결되어야하는데 1-2-4-5-1처럼 서로 연결되어있는 것이다. 고로 스패닝 트리는 밑의 사진과 같다.
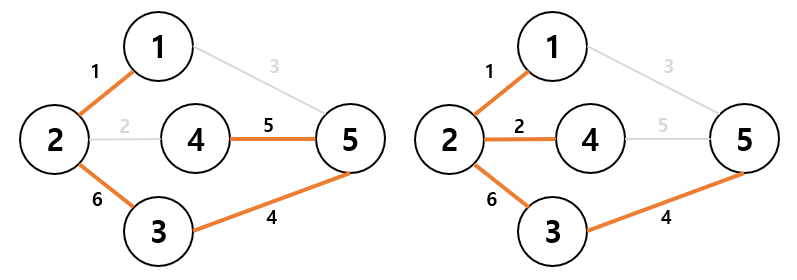
모든 정점을 연결하고 있지만 사이클이 형성되어있지 않다. 이 중에 가중치의 합이 최소인 트리를 최소 스패닝 트리라고 하는데, 여기서 가중치란 간선에 적혀있는 숫자를 뜻한다. 첫번째 트리는 1+6+5+4 = 16의 가중치를 가지고 있고, 두번째 트리는 1+2+6+4 = 13의 가중치를 가지고 있다. 고로 두번째 트리가 최소 스패닝 트리이다.
크루스칼 알고리즘이란?
최소 스패닝 트리를 구하기 위한 알고리즘이다. 대표적으로 크루스칼 알고리즘과 프림 알고리즘이 있으나 크루스칼로 풀었으니 이 방법만 설명하겠다.
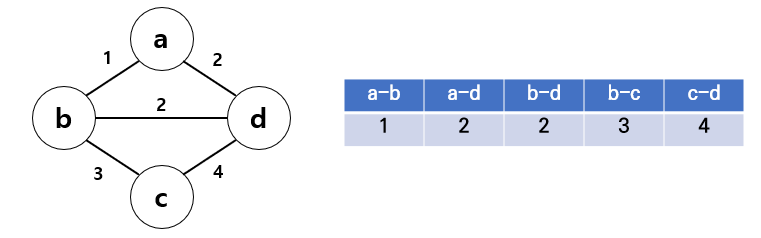
-
그래프를 가중치 기준 오름차순으로 정렬한다.
-
가중치가 가장 낮은 a-b부터 시작한다. 그리고 a-d, b-d 순으로 확장해 나가는데, a-d를 선택한 뒤 b-d를 선택하게 되면 사이클이 형성되므로 b-d는 선택하지 않고 다음 b-c를 선택한다.
-
최소 스패닝 트리의 간선 개수는 항상 정점의 개수 -1이다. 간선의 개수가 정점의 개수 -1에 도달했을 때 탐색이 종료된다.
Union-find
여기서 사이클인지 아닌지 판단하기 위해 Union-find 기법이 사용된다. Union-find란 합집합을 구할 때 사용하는 자료구조이다.
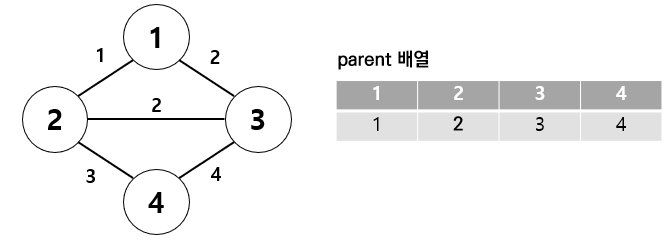
위의 그래프를 보자. 처음에는 테이블 안의 값이 자기 자신으로 설정된다. 가중치 기준 오름차순으로 정렬한 뒤 1-2가 연결된다.
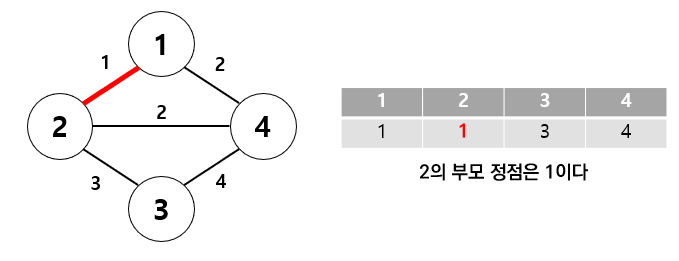
1-2 집합을 만들었다. 여기서 부모가 다른지 체크하고, 만약 다르다면 union 연산으로 합친다. 이 집합 내에서 가장 작은 수가 부모로 설정된다. 그래서 2의 부모를 1로 변경하는 것이다.
그 다음 1-4를 연결한다. 부모가 다르므로 집합을 만든다. 1,2,4 집합이 되는 것이다. 가장 작은 수가 부모로 설정되므로 4의 부모 또한 1이 된다.
그 다음 2-4를 연결하게 되는데, 연결하게 되면 사이클이 형성되고, 2와 4는 부모가 같으므로 연결하지 않는다.
마지막으로 2-3을 연결하면 최소 스패닝 트리의 구현이 완료된다.
아래는 작성한 코드이다.
#작은 쪽을 테이블에 넣게됨
# ex) 1과 2가 연결되었을 때 2번째 자리에 1이 들어가게끔 만드는것임
# 그리고 3이라는 다른 수가 들어왔을 때 2와 연결되면 3이 가르키고 있는 2를 찾음
# >> 결국 3번째 자리에도 1이 들어가게됨. 그래서 재귀가 사용됨
import sys
input = sys.stdin.readline
V, E = map(int, input().split())
c = [list(map(int, input().split())) for _ in range(E)]
#가중치 기준으로 오름차순 정렬
c.sort(key= lambda x: x[2])
#작은 노드를 저장해줄 테이블/ 처음에 모든 값은 자기 자신을 가리킴
table = [i for i in range(V+1)]
ans = 0
# find로 테이블[x] == x 같을 때까지 찾아줌
def find(x):
if x != table[x]:
return find(table[x])
return table[x]
# 연결된 정점끼리는 부모를 같게 만들어줌
def unit(a,b):
a= find(a)
b = find(b)
if a > b:
table[a] = b
else:
table[b] = a
#부모가 같지 않을때만 cost(가중치) ans에 추가해줌
for a, b, cost in c:
if find(a) != find(b):
unit(a,b)
ans += cost
print(ans)
1916번 최소비용 구하기
https://www.acmicpc.net/problem/1916
이 문제를 보자마자 최소 스패닝 트리를 풀었던 게 오버랩되면서 아 이거 테이블 만들어야겠는데? 라고 생각했다. 크루스칼로 푸는 건 아니었지만 테이블을 만들어야한다는 발상은 맞았다. 이 문제는 우선순위 큐를 이용한 다익스트라 알고리즘을 구현해 풀었다.
다익스트라(Dijkstra) 알고리즘이란?
간단히 말해 최단경로를 구하는 알고리즘이라고 할 수 있다. 노드를 탐색하면서 거리가 가장 짧은 노드를 발견하면 테이블을 갱신한다. 그 과정을 계속 반복하여 최단거리를 구하는 것이다.
여기서 우선순위 큐, 즉 힙을 사용하는 자료구조를 이용한다. 우리가 DFS에서 사용하던 스택은 FILO(first-in-last-out) 방식을, BFS에서 사용하던 큐는 FIFO(first-in-first-out) 방식을 사용한다. 하지만 우선순위 큐는 우선순위가 높은 것부터 차례로 삭제(OUT)한다. 따라서 우선순위 큐는 우선순위를 정해두고 높은 것부터 삭제하고 싶을 때 사용된다. 시간복잡도는 O(E log V)이다. (E = 간선의 개수, V = 정점의 개수)
우선순위 큐를 이용한 다익스트라 알고리즘의 구현법은 간단히 설명해보자면 다음과 같다.
- 출발 노드를 설정한다.
- 방문하지 않은 인접 노드를 체크하여 거리를 계산한 다음 기존 거리보다 짧다면 우선순위 큐에 추가한다. 만약 계산한 거리가 기존 거리보다 길다면 무시한다.
++ 추가예정
자세한 내용은 아래 코드 주석에 추가해두었으니 참고하길 바란다.
import sys
input = sys.stdin.readline
import heapq
n = int(input())
m = int(input())
INF = int(1e9)
table = [INF] * (n+1)
graph = [[] for _ in range(n + 1)]
for _ in range(m):
a,b,c = map(int, input().split())
graph[a].append((b,c))
start, end = map(int, input().split())
def dijkstra(start):
q = []
# 순서는 꼭 우선순위, 값 형태로 넣는다. 반대로 넣으면 원하는 대로 정렬되지 않기 때문
heapq.heappush(q, (0, start))
# 시작노드(ex. 1)에서 1로 가는 거리는 없으므로 0
table[start] = 0
while q:
# 탐색할 거리와 노드를 가져옴
dist, node = heapq.heappop(q)
# 기존 거리보다 길다면 체크하지 않음
if table[node] < dist:
continue
for i in graph[node]:
# cost = 인접노드까지의 거리 탐색
cost = table[node] + i[1]
# cost가 기존 거리보다 짧다면 테이블을 갱신한다
if cost < table[i[0]]:
table[i[0]] = cost
# 다음으로 인접한 거리를 계산하기 위해 큐에 삽입
heapq.heappush(q, (cost, i[0]))
dijkstra(start)
print(table[end])
참고자료: https://techblog-history-younghunjo1.tistory.com/248?category=1014800
사진출처 : https://chanhuiseok.github.io/posts/algo-33/