Attention 등장배경
Attention은 Transformer Model의 기반이자 LLM모델의 핵심이다.
Drink Water라는 문장을 번역한다고 가정해본다.
이 경우 문장을 번역할 때 사용되는 Encoder-Decoder모델을 사용할 수 있다.
Encoder-Decoder는 한 번에 한 단어를 가져와 각 시점에 이를 번역하는 방법으로 작동한다.
하지만 어순의 영향에 따라 Encoder에 입력되는 단어와 출력되는 단어가 맞지 않을 때가 있다.
첫번째 input 영어는 Drink이나, 출력은 Water의 의미인 '물'가 출력되어야 한다.
Input -> Output
Drink -> 물
Water -> 마셔
이러한 첫번째 시점에서 Drink라는 단어 대신 Water란 단어에 더 집중하도록 모델을 학습시키고 싶을때 바로 Attention 매커니즘을 사용한다.
Attention Mechanism
Attention Mechanism은 신경망이 입력 시퀀스의 특정 부분에 집중할 수 있도록 하는 기법이다.
이 기법에서는 중요한 부분에 가장 높은 가중치가 적용되도록 입력 시퀀스의 각기 다른 부분만다 가중치를 할당한다.
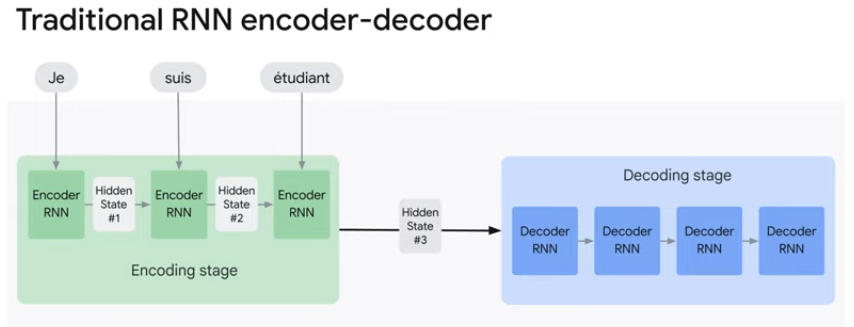
전통적인 RNN 기반 Encoder-Decoder는 모델이 한번에 한 단어를 입력으로 가져와 은닉 상태를 업데이트하고 다음 시점으로 전달한다. 최종 은닉상태(Hidden State #3)만 디코더로 전달되고, 디코더는 이 최종 은닉상태를 처리에 사용하고 번역한다.
Attention Model은 전통적인 Seq2Seq Model과 두가지 다른점이 있다.
1. 인코더가 훨씬 더 많은 데이터를 디코더로 전달한다.
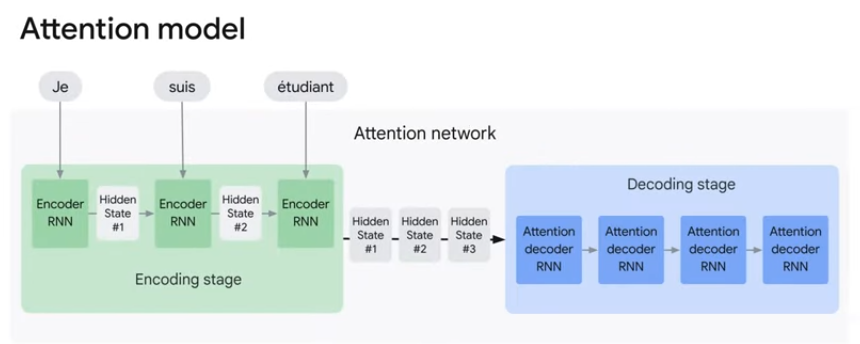
각 시점의 모든 은닉 상태(Hidden State #1~3)를 전달해 최종 은닉상태 이상의 컨텍스트가 디코더에 제공되고, 디코더는 모든 은닉 상태 정보를 사용해 문장을 번역한다.
2. 출력을 생성하기 전에 어텐션 디코더에 단계를 추가한다.
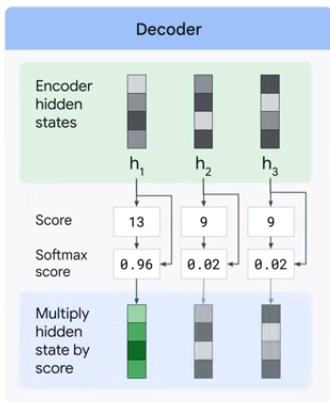
1) 수신된 인코더의 상태집합을 살펴본다.(각 인코더의 은닉 상태는 특정 단어와 연결됨)
2) 은닉 상태에 점수를 부여한다.(Score 계산)
3) 각 은닉 상태를 SoftMax Score와 곱한다.
이 과정은 점수가 가장 높은 은닉 상태를 증폭하고 점수가 낮은 은닉 상태는 축소한다.
Bahdanau Attention
바다나우 어텐션은 Attention Mechanism 중 범용적으로 사용되는 어텐션이다.
실제 Pytorch 코드에서 Attention 디코더는 바다나우 어텐션을 사용한다.
1) 수신된 인코더의 상태집합을 살펴본다.
인코더의 상태집합은 h, 디코더의 현재 시점을 t라고 가정한다.
2) 은닉 상태에 점수를 부여한다.(Score 계산)
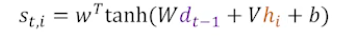
그림과 같이 t시점의 은닉상태가 아닌 t-1시점의 은닉상태를 사용한다.
인코더 정보와 이전타임 디코더 정보를 이용해 구한다. 가중치 행렬인 W들을 지난 후 하이퍼볼릭탄젠트함수를 지나도록 한다.
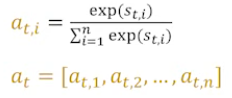
모든 어텐션 스코어를 더한 값이 1이 되도록 softmax 함수를 적용해 어텐션 분포를 구한다.
이는 각 encoder를 얼마나 할당할지에 대한 값, 즉 어텐션 가중치를 의미한다.
이후 context vector를 구할때 활용한다.
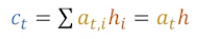
softmax score와 은닉상태를 가중합 해 context vector를 구한다.
이와 같은 바다나우 어텐션은 이전 게시물에서 설명한 Tacotron2에도 변형되어 적용된다. Local Sensitive Attention은 TTS의 특징에 맞게 시간정보를 추가한다. 이전 시점의 어텐션 정보를 이용해 어텐션 스코어를 구하는 점이 특징이다.
