11월 16일 - 수업 18일차

1. 콜렉션 프레임워크란?
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합
즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것으로, 인터페이스를 사용하여 구현된다.
💥주요 인터페이스💥
1. List 인터페이스
- 순서가 있는 데이터의 집합으로, 데이터의 중복을 허용함.
- ArrayList, LinkedList
2. Set 인터페이스
- 순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않음.
- HashSet, TreeSet
- Queue 인터페이스
- Map 인터페이스
2. ArrayList와 LinkedList의 장단점은?
✅ ArrayList: 데이터들이 순서대로 쭉 늘어선 배열의 형태를 취하고 있음.
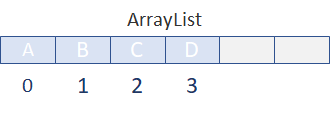
메모리에서 내부적으로 데이터를 배열로 만들어 관리하며, 데이터의 추가, 삭제를 위해 임시 배열을 생성해 데이터를 복사하는 방법을 사용한다.
add() 메소드로 엘레멘트를 추가할 수 있다.
일반 배열은 처음에 메모리를 할당할 때 크기를 지정해주어야 하지만, ArrayList는 크기를 지정하지 않고 동적으로 값을 삽입하고 삭제할 수 있다.
장점
- 배열의 형태로 데이터들이 저장해 있기 때문에 사용자가 원하는 인덱스의 데이터를 빠르게 꺼내올 수 있다.
즉, 참조에 유리하다.
단점
- 각 데이터 추가/삭제마다 배열을 새로 만들어 복사해주므로 시간이 오래 걸린다.
<삽입 과정>
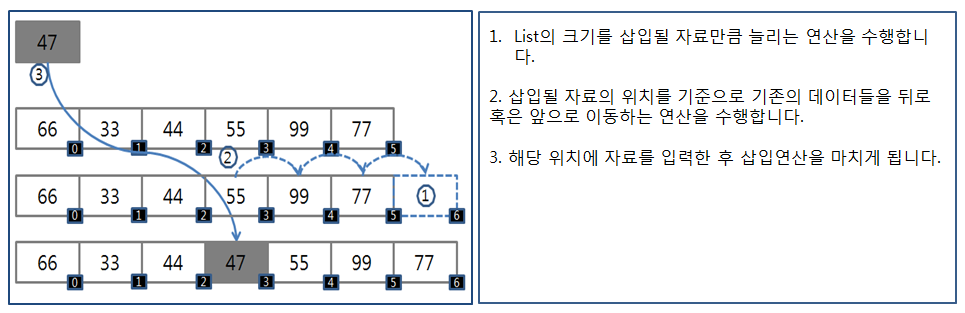
<삭제 과정>
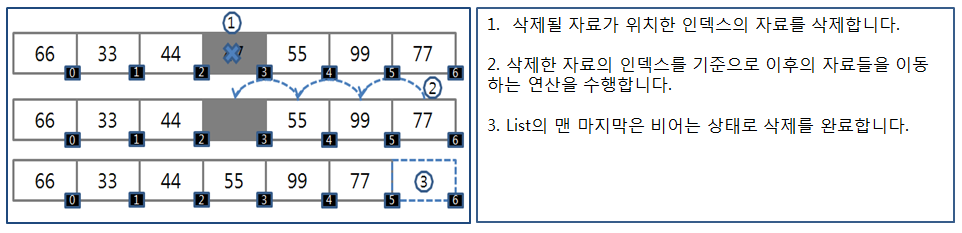
✅ LinkedList: 양방향 연결 리스트(Doubly Linked List)로 구현되어 있고, 각각의 데이터가 노드(Node)로 구성되어 연결이 되는 구조.

각각의 노드는 데이터와 함께 next(다음 노드)와 prev(이전 노드) 값을 내부적으로 가지고 있다.
add() 메소드로 엘레멘트를 추가
<삽입 과정>
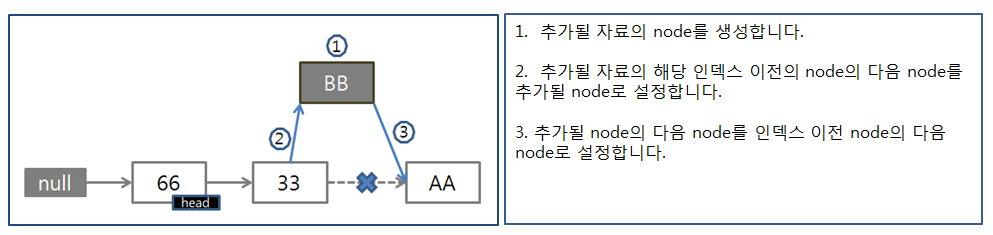
<삭제 과정>
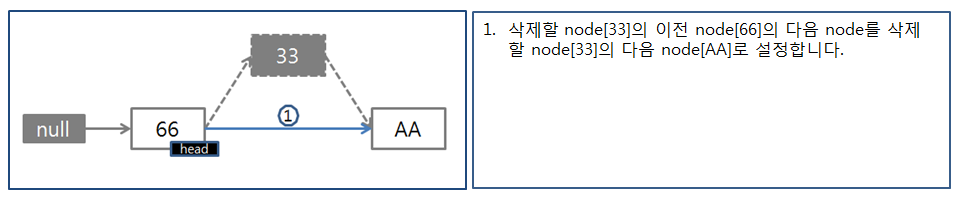
장점
- 데이터 입력시 주소가 순차적이지 않아 요소를 메모리의 어느곳에나 둘 수 있음 (크기가 동적임)
- 인덱스 대신 현재 위치의 이전 및 다음 위치를 기억하는 형태로, 요소 중간에 삽입, 삭제 시 논리적 주소만 바꿔주면 되기 때문에 요소(데이터) 삽입, 삭제가 용이
단점
- 요소에 바로 접근이 가능하지 않고 연결되어 있는 링크를 따라가야만 접근이 가능하여 접근 속도가 느림
소량의 데이터를 가지고 사용할 때는 사실 큰 차이가 없지만, 정적인 데이터를 활용하면서 조회가 빈번하다면 ArrayList를 사용하는 것이 좋고,
동적으로 추가/삭제 요구사항이 빈번하다면 LinkedList를 사용하는 것이 좋다.
순차적으로 추가/삭제하는 경우 ArrayList가 LinkedList보다 빠르다.
처음 또는 마지막 데이터부터 순차적으로 데이터를 쭉 삭제하면 각 요소들의 재배치가 필요하지 않기 때문에 ArrayList도 빠르다.
중간 데이터(비순차적)을 추가/삭제하는 경우 LinkedList가 ArrayList보다 빠르다.
중간 요소를 추가 또는 삭제하는 경우, LinkedList는 각 노드간 연결만 변경해주면 되기 때문에 처리속도가 빠르다. 반면에 ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 늦다.
3. Scanner 클래스로 -1이 입력될 때까지 양의 정수를 입력 받아 저장(List)하고 검색하여 가장 큰 수를 출력하는 프로그램을 작성하라.
package java_sua_instance_example;
import java.util.LinkedList;
import java.util.List;
import java.util.Scanner;
public class ListMaxNum {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("정수(-1이 입력될 때까지)>>");
List<Integer> list = new LinkedList<>();
int num = 0;
while(num != -1) {
num = sc.nextInt();
list.add(num);
}
sc.close();
int maxNum = 0;
for(int i=0; i<list.size(); i++) {
if(list.get(i) > maxNum) {
// get(): 파라미터로 전달받은 index에 있는 값을 리턴
maxNum = list.get(i);
}
}
System.out.println("가장 큰 수는 :" + maxNum);
}
}
4. 로또 프로그램을 작성하시오. (Set으로)
import java.util.HashSet;
import java.util.Set;
public class LottoSet {
public static void main(String[] args) {
Set<Integer> LSet = new HashSet<>();
while(LSet.size() != 6) {
int num = (int)(Math.random()*46 + 1);
LSet.add(num);
}
for (int num : LSet) {
System.out.print(num + " ");
}
}
}
5. Set 인터페이스에 대하여 설명하시오.
집합의 개념.
특정한 값들을 저장하는 추상자료형
-
저장 순서가 유지되지 않는다.
-
데이터의 중복 저장을 허용하지 않는다.
-
collection interface는 Iterable interface를 상속하고, Set은 collection을 상속하므로 iterator 반복자를 호출해서 사용할 수 있다.
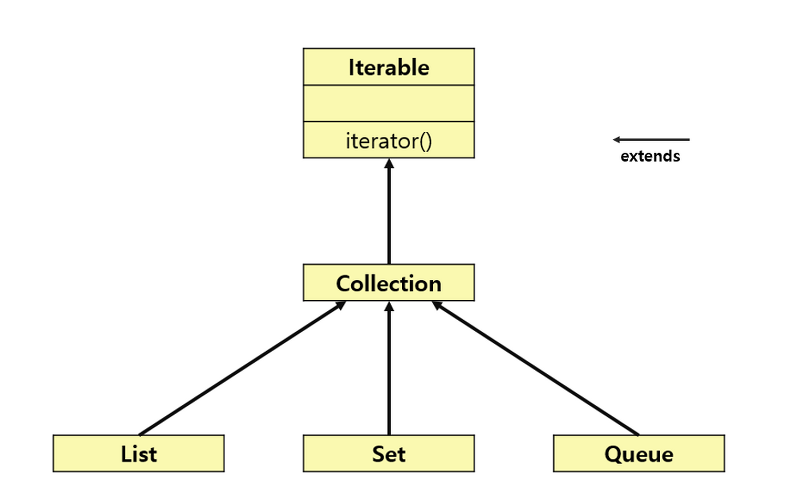
-
HashSet, Treeset이라는 클래스를 갖는다.
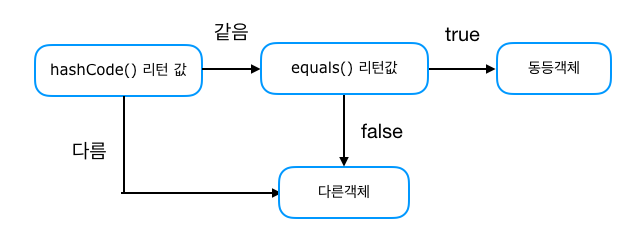
👹 cf. HashSet이 중복을 걸러내는 과정 👹
HashSet은 객체를 저장하기 전에 먼저 객체의 hashCode() 메소드를 호출하여 해시 코드를 얻어낸다. 저장되어 있는 객체들의 해시 코드와 비교한 뒤, 같은 해시 코드가 있다면 equals() 메소드로 두 객체를 비교한다. 이때 true가 나오면 동일한 객체로 판단하고 중복 저장을 하지 않는다.
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetEx {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Toy"); set.add("Box");
set.add("Robot"); set.add("Box");
System.out.println("인스턴스 수: " + set.size());
//반복자를 이용한 전체 출력
for(Iterator<String> itr= set.iterator(); itr.hasNext(); )
System.out.print(itr.next() + '\t');
System.out.println();
//for-each문을 이용한 전체 출력
for(String s : set)
System.out.print(s + '\t');
System.out.println();
}
}
6. 출력이 아래와 같이 나오도록 하시오 (필수) ⭐️
HashSet<Num> set = new HashSet<>();
set.add(new Num(7799));
set.add(new Num(9955));
set.add(new Num(7799));
System.out.println("인스턴스 수: " + set.size());
for(Num n : set)
System.out.print(n.toString() + '\t');
System.out.println();====출력====
인스턴스 수: 2
7799 9955답
import java.util.HashSet;
class Num1 {
private int num;
public Num1(int n) {
num = n;
}
@Override
public String toString() {
return String.valueOf(num);
}
@Override
public int hashCode() {
System.out.println("hashCode()");
return num % 13;
}
@Override
public boolean equals(Object obj) {
System.out.println("equals");
if(num == ((Num1)obj).num)
return true;
else
return false;
}
}
class HashSetEquality {
public static void main(String[] args) {
HashSet<Num1> set = new HashSet<>();
set.add(new Num1(7799));
set.add(new Num1(9955));
set.add(new Num1(7799));
System.out.println("인스턴스 수: " + set.size());
for(Num1 n : set)
System.out.print(n.toString() + '\t');
System.out.println();
}
}7. Set이 호출되는 원리와 순서를 설명하시오.
set을 호출하기 위해서는 아래의 두 메소드가 호출되어야 한다.
(set은 중복을 허용하지 않으므로)
1. hash code
두 개 객체 주소-hash code-가 같은지 비교
hashCode는 Object에 있다. 아래의 예시와 같이 오버라이드한 함수를 통과해 리턴되는 값으로 군집(집합, 캐비넷)을 만든다. 그 후 equals를 호출한다.
2. equals
문자열을 비교하여 걸러냄
hash code의 호출로 군집히 형성되면 그 군집 내의 요소들을 비교해 나간다.
이 두 메소드가 다 같아야 동일 인스턴스이다.
8. 아래와 같이 출력되도록 하시오.
HashSet<Person> hSet = new HashSet<Person>();
hSet.add(new Person("LEE", 10));
hSet.add(new Person("LEE", 10));
hSet.add(new Person("PARK", 35));
hSet.add(new Person("PARK", 35));
System.onut.println("저장된 데이터 수: " + hSet.size());
System.out.println(hSet);
======출력======
저장된 데이터 수: 2
[LEE(10세), PARK(35세)]
답
import java.util.HashSet;
class Hper{
private String name;
private int age;
public Hper(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return age;
}
@Override
public boolean equals(Object obj) {
if(name.equals(((Hper)obj).name) && age == ((Hper)obj).age)
return true;
else
return false;
}
@Override
public String toString() {
return name + "(" + age + ")";
}
}
public class HashSetPerson {
public static void main(String[] args) {
HashSet<Hper> hSet = new HashSet<Hper>();
hSet.add(new Hper("LEE", 10));
hSet.add(new Hper("LEE", 10));
hSet.add(new Hper("PARK", 35));
hSet.add(new Hper("PARK", 35));
System.out.println("저장된 데이터 수: " + hSet.size());
System.out.println(hSet);
}
}