
클러스러링(군집화) 란 ?
- X 에 대한 레이블이 지정 되어있지 않은 데이터를 그룹핑하는 분석 알고리즘
- 데이터들의 특성을 고려해 데이터 집단(클러스터)를 정의하고 데이터 집단의 대표할 수 있는 주심점을 찾는 것으로 데이터 마이닝의 한 방법
- 클러스터란 비슷한 특성을 가진 데이터들의 집단
K-means 알고리즘
가장 많이 알려진 클러스터링 알고리즘
클러스터링 알고리즘 중 가장 이해하기 쉽고, 구현하기 쉽다.
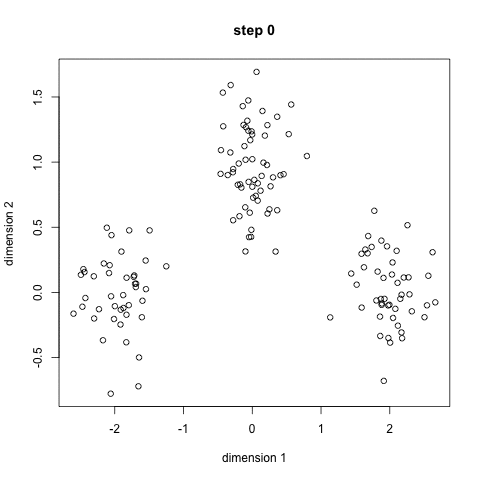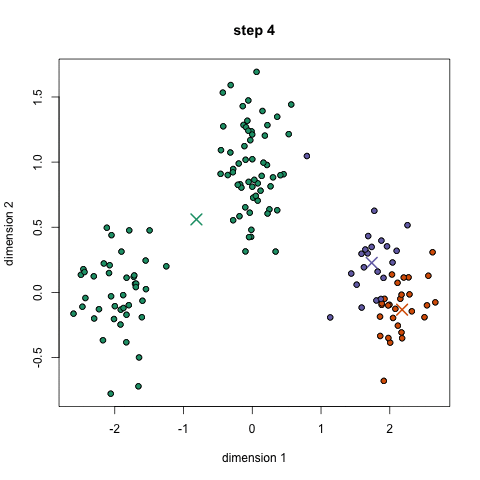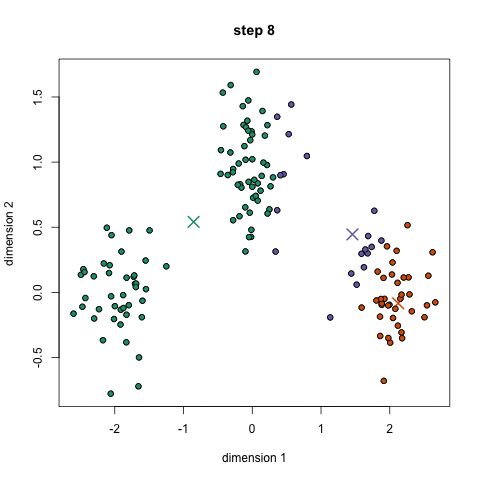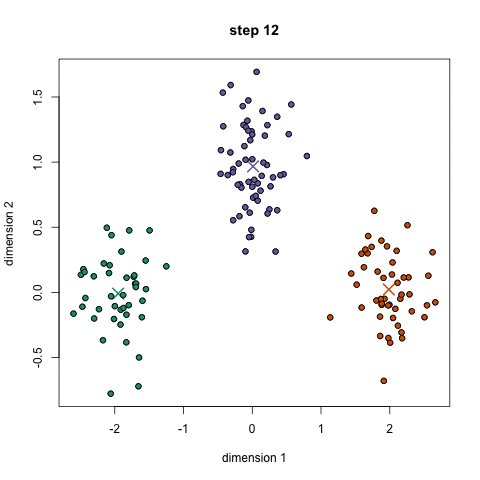
① 클래스 혹은 그룹의 수 (K) 를 정한다. 그러면 그 숫자에 따라 랜덤하게 center point 를 잡는다.
② 각 data point는 각 center point끼리의 거리를 측정해서 분류된다.
③ 분류된 data points에 기반해서 우리는 모든 그룹의 벡터의 평균(mean)을 구하는 것으로 그룹의 center를 recompute한다.
④ 이 과정을 설정된 반복 횟수 혹은 그룹 center가 그렇게까지 많이 바뀌지 않는 선에서 반복한다. 물론 그룹 center를 랜덤하게 여러번 초기화 시킬 수 있고 가장 좋은 결과가 나오도록 고를 수도 있다.
| 장점 | 단점 |
|---|---|
| 아주 빠름 계산량은 O(n) | 클래스/그룹수(K)를 내가 정해야 한다. 처음 point를 랜덤하게 고르기 때문에 돌릴 때마다 다른 결과가 나온다. |
Mean-Shift Clustering
데이터 포인트의 밀집 영역을 찾으려고 하는 sliding-window 기반 알고리즘
이는 즉 centroid-based 알고리즘이라고도 하는데 해당 알고리즘은 목표(goal) 가 각 그룹/클래스의 중심점을 찾는 것이며, 중심점 후보를 점의 평균으로 업데이트 하여 작동한다.
후보 창은 사후 처리 단계에서 필터링되어 거의 중복을 제거하여 최종 중심점 집합과 해당 그룹을 형성
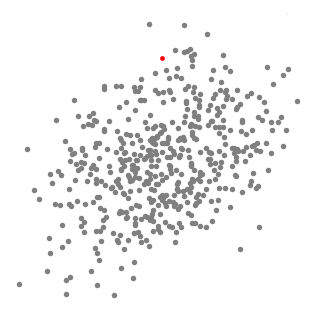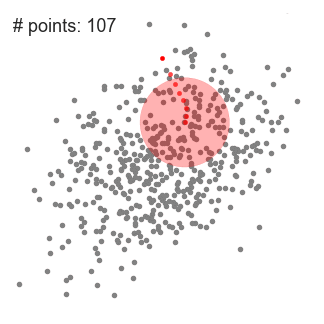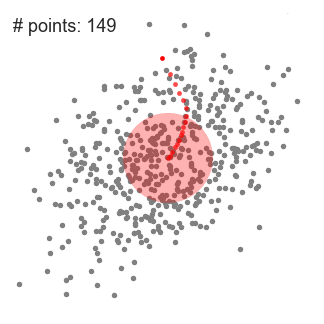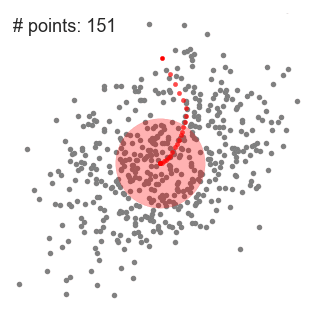
① 위 일러스트에서 볼 수 있는 것 처럼 point set을 2D 공간에 놔둬야 한다. 그리고 원 형태의 sliding window(kernel = 반지름(radius) r)를 랜덤하게 선택한 point C에 맞춘다. 때문에 이 알고리즘은 언덕을 오르는(hill climbing) 알고리즘이라고도 하며 높은 밀도를 보이는 지역을 각 단계에서 찾기 위해 kernel을 반복적으로 옮긴다.
② 반복할 때마다 sliding window는 더 높은 밀도를 갖는 지역으로 center point를 points(window 범위 내에 있는)의 평균값으로 옮겨간다.
③ 우리는 평균값에 따라 sliding window를 계속해서 옮기고 이 작업은 kernel 안에 더 많은 points를 수납할 수 있는 방향을 찾지 못할 때까지 계속된다.
④ 여러 개의 sliding window안에 모든 points가 수납될 때까지 1-3을 반복한다.
Mean-Shift Clustering의 전 과정

| 장점 | 단점 |
|---|---|
| K-Means와 대조적으로 이 알고리즘은 클래스 혹은 그룹의 개수를 정할 필요가 없다. Mean-Shift가 자동적으로 발견한다. | kernel = 반지름 r 사이즈를 선택해야 한다. |
잡음이 있는 응용 프로그램의 밀도 기반 공간 클러스터링(DBSCAN)
밀도에 따라 클러스터링 하는 알고리즘
① DBSCAN은 임의로 고른(가 본 적 없는) starting data point에서 시작한다. 이 point의 이웃은 거리 입실론 ε을 사용해 추출된다.
② 만약 '이웃' 안에 충분한 수의 points(minPoints에 따라)가 들어있다면 클러스터링을 시작한다. 새로운 클러스터에 있는(현재 시작점인) 첫 번째 point와 다르게 나머지 points는 noise로 라벨링된다. 나중에 noise도 클러스터의 부분이 된다. 그리고 두 경우 다 방문했다는 것을 기억한다.
③ 새로운 클러스터의 first point를 위해 입실론 거리에 있는 이웃에 속한 points도 같은 클러스터의 일부가 된다. 이러한 절차는 클러스터 그룹에 추가된 적이 있는 모든 새로운 points를 위해 반복된다.
④ 2, 3번은 모든 points가 정의될 때까지 계속된다. 즉, 모든 입실론 이웃인 points이 라벨링 될 때 까지 계속된다.
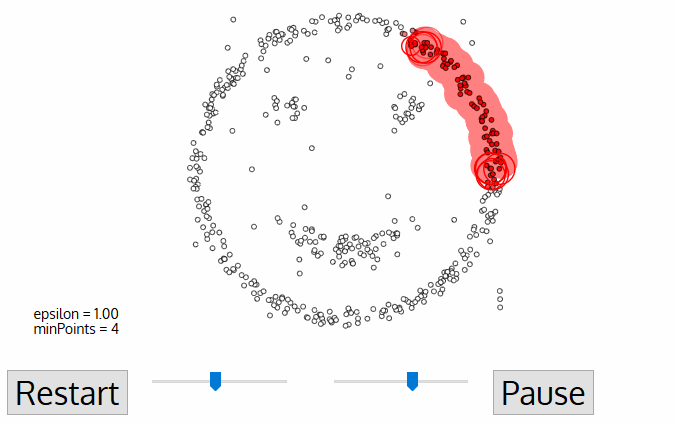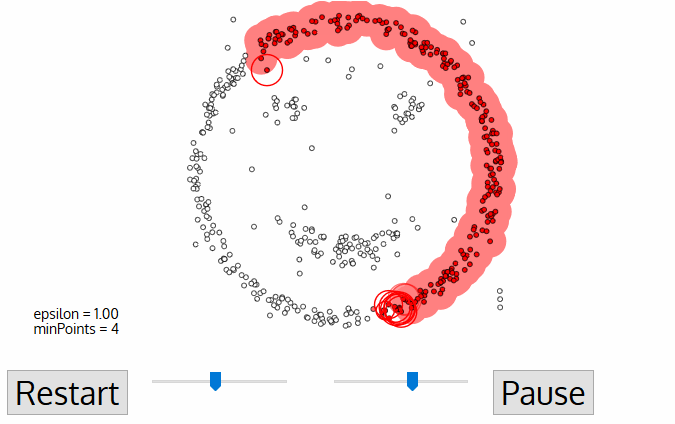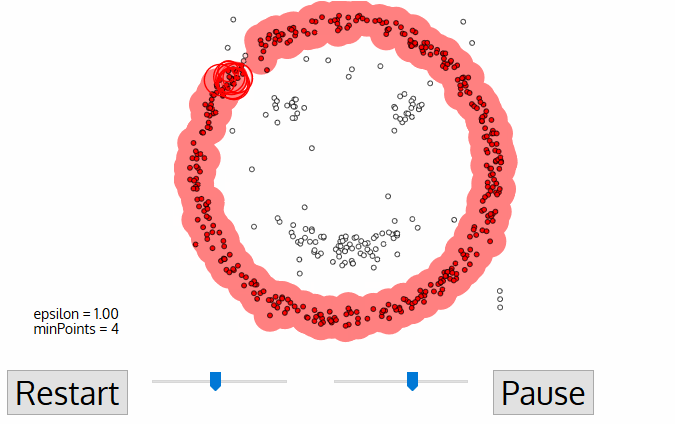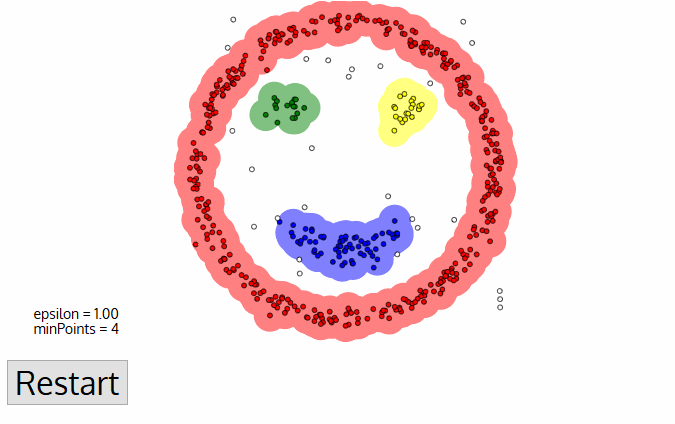
⑤ 현재 클러스터링이 끝나면 새로운 방문하지 않은 point가 나오고 다시 위 과정이 반복된다. 이는 더 먼 거리에 있는 cluster와 noise를 발견하기 위함이다. 이 과정도 모든 points를 방문할 때까지 계속된다.
| 장점 | 단점 |
|---|---|
| 1. 미리 클래스 혹은 그룹 수를 지정할 필요가 없다 2. 데이터 포인트가 매우 다른 경우에도 클러스터에 단순히 던지는 평균 이동과 달리 이상값을 노이즈로 식별한다. 3.임의의 크기와 임의의 모양의 클러스터를 아주 잘 찾을 수 있다. | 1. 클러스터의 밀도가 다양할 때 다른 것만큼 잘 수행되지 않는다. (밀도가 변할 때 이웃 점을 식별하기 위한 거리 임계값 ε 및 minPoints의 설정이 클러스터마다 다르기 때문) 2. 거리 임계값 ε이 추정하기 어려워지기 때문에 매우 고차원 데이터에서도 발생 |
가우스 혼합 모델(GMM)을 사용한 EM(기대값 최대화) 클러스터링
K-Means 의 단점은 군집 중심에 대한 평균 값을 제대로 사용하지 않는 다는 것이다.
아래 이미지를 보면 왜 이것이 최선의 방법이 아님을 알 수 있다.
첫번째 (왼쪽), 인간의 눈에는 같은 평균을 중심으로 서로 다른 반지름을 가진 두 개의 원형 성단이 있다는 것이 매우 명백해 보인다. K-평균은 군집의 평균 값이 서로 매우 가깝기 때문에 이를 처리할 수 없다.
두번째 (오른쪽), K-평균은 군집이 원형이 아닌 경우에도 군집 중심으로서 평균을 사용한 결과로 실패합니다.

GMM 은 K-Means 보다 더 많은 유연성을 제공한다.
우리는 data points가 가우시안 분포라고 가정하고 이는 즉 평균을 이용해 원이 되어야 한다는 것 보다 덜 제한적인 가정을 사용할 수 있게 된다. 따라서 우리는 클러스터의 모양을 묘사하기 위한 두 개의 파라메터를 갖는데: 평균과 분산이다!
2D로 예를 들면, 클러스터는 어떠한 종류의 타원형(x, y축 안에서 표준 분산을 갖기 때문에)도 가질 수 있다는 얘기이다. 따라서 각 가우시안 분포는 하나의 클러스터로 할당된다.
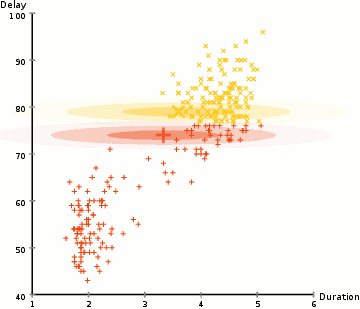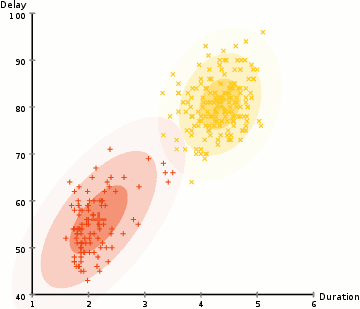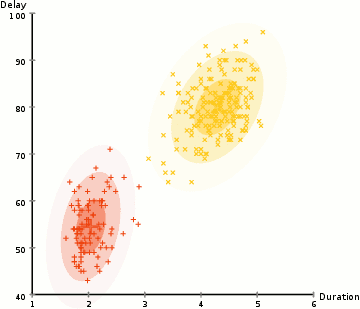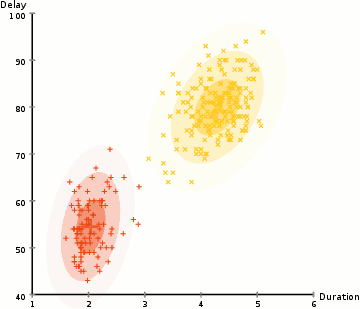
① 우리는 클러스터의 개수를 K-Means와 같이 정하고 랜덤하게 각 클러스터의 가우시안 분포 파라메터를 정해준다.
② 각 클러스터를 위해 주어진 이러한 가우시안 분포들의 각 data point가 특정 클러스터에 속할 확률을 계산한다. 가우시안의 중심부에 가까운 point는 해당 클러스터에 속할 가능성이 더 높다. 이는 대부분의 데이터가 클러스터의 중심부와 가깝게 나뉘어질 거라고 가정할 수 있게 한다.
③ 이러한 확률에 기초해 우리는 data points가 클러스터 안에 속할 확률을 최대화 하는 가우시안 분포들의 새로운 파라메터 집합을 계산한다. 계산은 data point 위치의 가중치를 적용한 합계를 이용해 이루어지며 가중치는 data point가 특정 클러스터에 속할 확률이다. 위 일러스트에서 노란색 클러스터를 예로 들면, 첫 번째 반복시에 해당 분산은 랜덤하게 정해지지만 대부분의 yellow points가 오른쪽으로 향해 가는 것을 볼 수 있다. 우리가 확률로 합 가중치를 적용한 합을 계산했을 때, 중심부에 가까운 몇 개의 points가 있다 하더라도 대부분은 오른쪽에 있는 것을 알 수 있다. 따라서 자연적으로 분산의 평균은 points 집합에 가까워지도록 옮겨진다. 이에 따라 분산은 확률로 가중치가 적용된 sum이 최대값이 되도록 이러한 points에 알맞는 타원형을 만들어간다.
④ 2, 3은 분산이 반복 시마다 많이 달라지지 않는 선에서 집합이 만들어질 때 까지 반복된다.
| 장점 |
|---|
| 1. K-Means보다 클러스터 집합이 flexible(분산 덕분에 덜 제한적이라서). 2. GMMs는 확률을 사용하기 때문에 각 data point마다 여러 클러스터를 가질 수 있고 만약 data point가 겹쳐진 두 개의 클러스터 사이에 있다 하더라도 우리는 간단하게 확률로 나눠서 판단할 수 있다. 즉, GMMs는 mixed membership2을 지원한다. |
Agglomerative Hierarchical Clustering (통합 계층적 클러스터링)
통합 계층적 클러스터링 알고리즘은 top-down, bottom-up 으로 총 2가지로 나뉜다.
Bottom-up 알고리즘은 시작 부분(outset)에서 각 data point를 하나의 클러스터로 다루며 연속적으로 한 쌍의 클러스터를 모든 클러스터가 하나로 합쳐질 때까지 병합(merge 혹은 agglomerate; 뭉치다)한다. 그러므로 계층으로 뭉쳐진(hierarchical agglomerative) 클러스터링 혹은 HAC라 불린다.
클러스터의 계층은 나무(혹은 dendrogram)로 표현된다. 나무의 뿌리는 모든 샘플을 모아 놓은 unique한 클러스터이고 잎은 하나의 샘플을 갖는 클러스터가 된다.
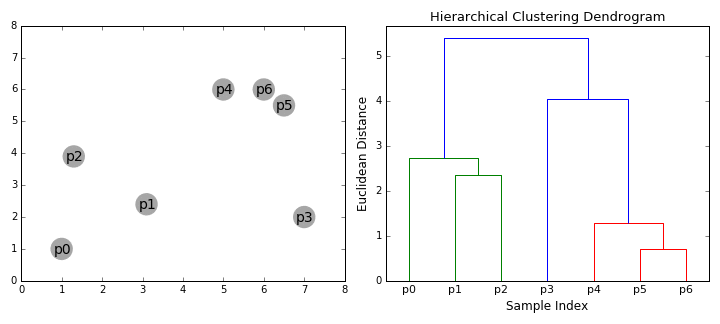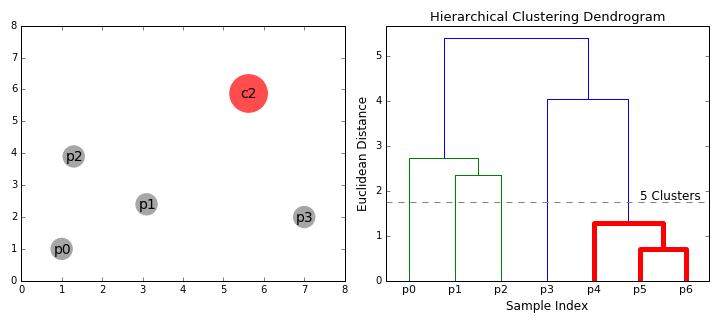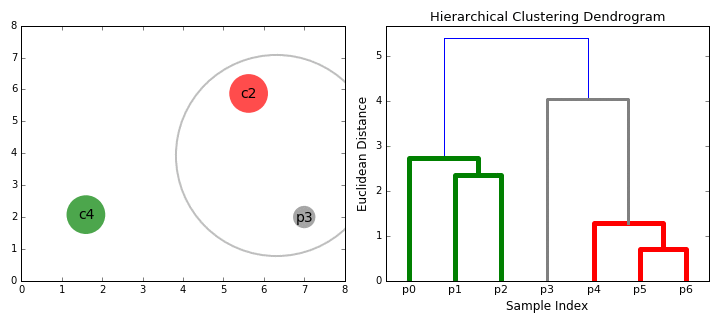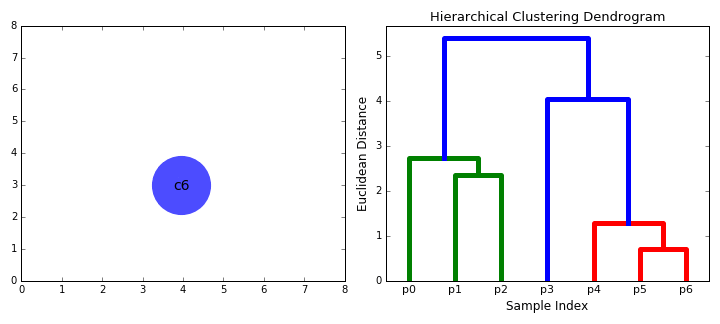
① 우리는 각 data point를 하나의 클러스터로 다루면서 시작한다. 즉, 만약 X개의 data points가 우리의 데이터셋에 있다면 우리는 X개의 클러스터를 갖는다.
② 각 반복시에 우리는 두 클러스터를 하나로 합친다. 결합할 두 군집은 평균 연결이 가장 작은 군집으로 선택된다. 즉, 선택된 거리에 따라 두 클러스터는 서로를 잇는 가장 짧은 거리를 가지며 이는 가장 비슷하다는 뜻이고 합쳐져야 한다는 말이 된다.
③ 2 단계는 루트에 도달할 때 까지 계속된다. 즉, 우리는 모든 data points를 갖는 하나의 클러스터가 생길 때까지 계속하는 것이다. 여기서 우리는 우리가 원하는 클래스 개수가 될 때 멈추는 것으로 클래스 개수를 마음대로 고를 수 있다.
| 장점 | 단점 |
|---|---|
| 1. 우리에게 클래스 혹은 그룹의 개수를 정하게 하지 않는다. 2. 오히려 우리가 원하는 개수의 클러스터를 언제든지 얻을 수 있다. 3. 거리에 민감하지 않다. 4. 특히 좋은 점은 갖고 있는 데이터가 계층적인 구조를 갖고 있을 때이다. 다른 알고리즘은 이런 상황에서는 별 소용이 없다. | 1. K-Means나 GMM과 다르게 높은 계산량을 갖는다. O(n^3) |
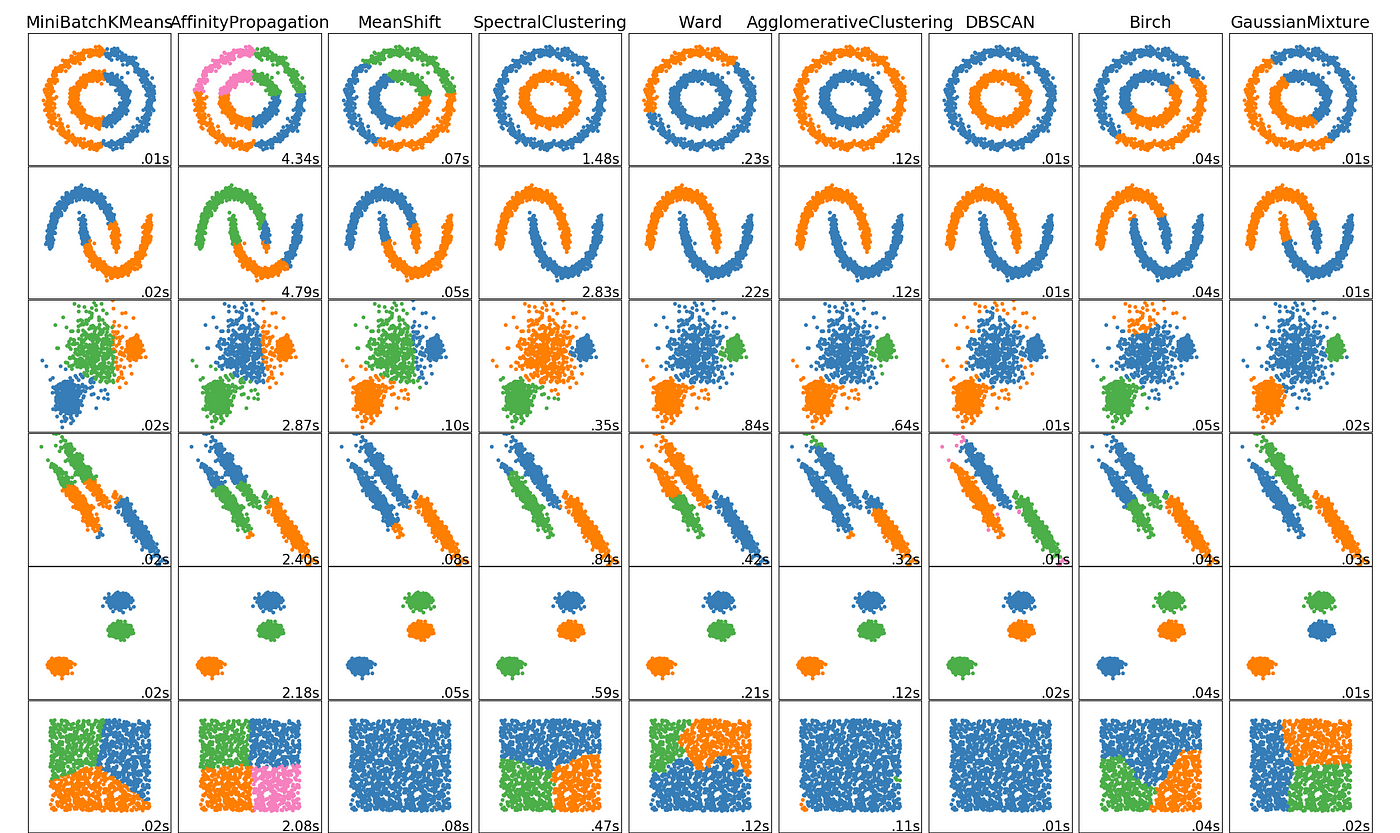
알고리즘 비교
🙇🏼♀️ 레퍼런스
[AI] Clustering (군집화) 개념과 알고리즘 종류
The 5 Clustering Algorithms Data Scientists Need to Know
