
주류데이터 탐색적 분석해보기 (결측값 처리 및 파이차트 그리기)
(1) 결측값 처리
결측값은 탐색적 데이터 분석에서도, 그 후 더 나아가 머신 러닝 알고리즘을 통해 분석을 할 때에도 성능에 영향을 줄 수 있는 값입니다. 결측값은 아예 제거를 해주거나, 특정 값으로 채워주거나 크게 두 가지 선택을 해줄 수 있습니다.
제거할 때는 주로 dropna()를 쓰는 반면, 채워줄 때는 주로 fillna()를 사용합니다.
처음 분석시 아래와 같이 continent에만 결측값이 있었으므로, 그 값을 ETC로 채워줍니다.
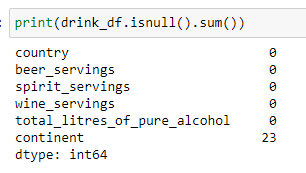
drink_df['continent'] = drink_df['continent'].fillna('ETC')
drink_df.sample(10)
drink_df.isnull().sum()

(2) 파이차트 그리기
파이 차트를 그리려면 아래의 두가지가 필요합니다.
- 파이 차트로 사용할 데이터의 이름이 담긴 리스트,
- 그리고 해당 이름에 해당하는 데이터의 값이 담긴 리스트
drink_df['continent'].value_counts()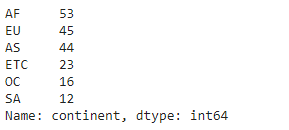
인덱스는 index로 접근하고 값에 대해서는 values로 접근하므로 각각 접근 후에 리스트로 값을 변환하는 tolist()를 사용해줍니다
pie_labels = drink_df['continent'].value_counts().index.tolist()
pie_values = drink_df['continent'].value_counts().values.tolist()
print(pie_labels)
print(pie_values)
plt.pie(데이터의 실질적인 값, labels=데이터의 레이블 리스트, autopct=소수점개수설정) 포맷을 사용하여 파이차트를 그려봅니다
plt.pie(pie_values, labels=pie_labels, autopct='%.02f%%')
plt.title('Percentage of each continent')
plt.show()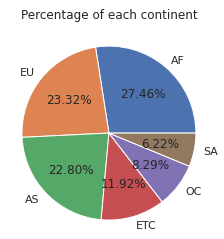

코딩 0살