
PySpark 공식 org 를 읽어보며 (약간의 번역?) 실전에도 능숙하게 적용해보고자 한다.
https://spark.apache.org/docs/latest/api/python/
1. PySpark
Python 에서 사용되는 Apache Spark interface 로, Spark applications 를 Python APIs 로 쓸 수 있을 뿐 아니라, 분산환경에서 interactive 하게 데이터를 분석할 수 있는 Pyspark shell 을 제공한다.
PySpark 는 Spark SQL, DataFrame, Streaming, MLlib (Machine Learning) and Spark Core 와 같은 대부분의 Spark 기능을 제공한다.
Spark SQL and DataFrame
Spark SQL 은 structured data processing 을 위한 Spark module 이다. 이는 programming abstraction 이라 불리는 DataFrame 을 제공하고, distributed SQL query engine 에 작동된다.
< What is a Distributed SQL Query Engine? : 발췌>
A distributed SQL query engine 은 cluster computing (MPP) 를 사용하는 architecture의 software tool 이다. 이는 사용자가 다양한 종류의 data sources 또는 single query 내에서 multiple data sources 의 데이터를 쿼리할 수 있게 한다.
Distributed SQL queries 는 사용자들이 다양한 frameworks 와 technologies 의 복잡성을 효과적으로 처리할 수 있게 해 매우 중요하다. 이는 data analysts 들이 여러개의 독립된 engines의 데이터를 결합하여 복잡한 분석 쿼리를 수행할 수 있게 한다.
pandas API on Spark
pandas API on Spark 는 pandas worload(작업량) 을 확장시켜 준다. 이 패키지를 사용하면, 아래와 같은 것들을 할 수 있다.
- pandas 에 익숙하다면 즉시 Spark 로 생산 할 수 있음
- pandas(tests, smaller datasets) 와 Spark(distributed datasets) 모두에 작용하는 single codebase 를 사용
- 어떠한 overhead 없이, pandas API 와 PySpark API contexts 를 전환
Streaming
Spark 위에서 실행되는, Apache Spark 의 streaming 기능은 streaming 과 historical data 모두에 걸쳐 강력한 interactive 및 분석 applications 을 가능하게 하며, Spark 의 사용편의성과 Fault tolerance(장애 허용 시스템) 특성을 계승한다.
MLlib
Spark 위에 built 된, MLlib 는 high-level APIs 의 uniform set 을 제공하는 scalable machine learning library 이다.
Spark Core
Spark Core 는 모든 기능이 탑재된 Spark platform 을 위한 underlying general execution engine 이다. 이는 RDD(
Resilient Distributed Dataset) 과 in-memory computing capabilities 를 제공한다.
2. DataFrame
PySpark DataFrames 는 RDDs 위에 구현되었다. Spark 가 데이터를 transform 할때, 이는 즉시 그 transformation 을 계산하지 않고, 어떻게 계산할지 계획을 먼저 한다. collect() 와 같은 actions 가 호출되었을 때, 계산이 시작된다.
RDD : Resilient Distrivuted Datasets 발췌
Spark 의 기본 데이터 구조로, 분산 변경 불가능한 객체 모음이며 스파크의 모든 작업은 새로운 RDD를 만들거나 존재하는 RDD를 변형하거나 결과 계산을 위해 RDD 에서 연산한다.
Spark 는 빠른 map-reduce 작업을 RDD 개념을 이용해 사용한다.
PySpark applications 는 PySpark 의 entry point인 `SparkSession` 초기화와 함께 시작한다. In case of running it in PySpark shell via pyspark executable, the shell automatically creates the session in the variable spark for users.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
엔트리 포인트(entry point)는 제어가 운영 체제에서 컴퓨터 프로그램으로 이동하는 것을 말하며, 프로세서는 프로그램이나 코드에 진입해서 실행을 시작한다. 어떤 운영체제나 프로그래밍 언어에서, 초기 엔트리는 프로그램의 한 부분이 아니라 런타임 라이브러리의 한 부분이다. 즉 런타임 라이브러리가 프로그램을 초기화하고 프로그램에 진입한다. 다른 경우에는 프로그램이 진입 직후에 바로 런타임 라이브러리를 호출하고, 이것이 반환된 후에 실제 실행을 시작한다. 이것은 로드 타임에서 런타임으로의 전환이다.간단한 레이아웃(흔히 스크립트 언어, 간단한 바이너리 실행 파일 포맷 그리고 부트 로더)에서는 시작점에서 실행을 시작한다. 또는 상대 주소나 절대 주소가 아니라 고정된 위치에 존재한다.
: 출처
2.1 DataFrame Creation
PySpark DataFrame 은 일반적으로 lists, tuple, dictionaries and pyspark.sql.Rows, a pandas DataFrame 그리고 an RDD list를 pyspark.sql.SparkSession.createDataFrame 을 통해 passing 해 생성된다.
pyspark.sql.SparkSession.createDataFrame 은 DataFrame schema 를 특정지을 shcema argument 를 가진다. 이것이 제출될 때, PySpark 는 데이터의 sample 을 참조해 schemma 를 생성한다.
Create a DataFrame from a list of rows
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=3, b=4., c='string3', d=date(2000, 3, 1), e = datetime(2000, 1, 1, 12, 0))
])Create a DF from explicit schema
df = spark.createDataFrame([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'stirng2', date(2000, 2, 1), datetime(2000, 1, 1, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
], schema='a long, b double, c string, d date, e timestamp')Creat a DF from a pandas DataFrame
pandas_df = pd.DataFrame({
'a' : [1, 2, 3],
'b' : [2., 3., 4.],
'c' : ['string1', 'string2', 'string3'],
'd' : [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e' : [date(2000, 1, 1, 12, 0), date(2000, 1, 2, 12, 0), date(2000, 1, 3, 12, 0)]
})
df = spark.creatDataFrame(pandas_df)Create a PySpark DF from an RDD consisting of a list of tuples
rdd = spark.sparkContext.paralleize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd'. 'e'])위의 모든 결과는 아래와 같이 동일함을 확인할 수 있다.
# All DataFrames above result same.
df.show()
df.printSchema()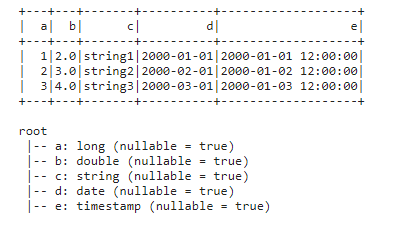
2.2 Viewing Data
-
DataFrame 상단의 row는
DataFrame.show()로 확인 할 수 있다.df.show(1) -
spark.sql.repl.eagerEval.enabled로 PySpark DataFrame의 eager evaluation 을 실행 (Jupyter 와 같은 노트북 내에서만 사용 가능)spark.conf.set('spark.sql.repl.eagerEval.enabled', True) df
- rows 를 수직으로 볼 수 있다 (rows 가 너무 길어 수평으로 보기 어려운 경우)
df.show(1, vertical=True)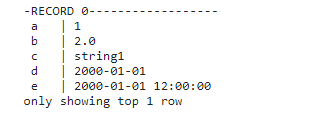
-
schema 와 columns 이름 보기
df.columns df.printSchema()- schema 출력

- schema 출력
-
summary of the DataFrame
df.select("a", "b", "c").describe().show()
-
DataFrame.collect()는 드라이버 내 분산된 데이터를 파이썬 로컬데이터로 모아줌.- 드라이버 executors 로 부터 모든 데이터를 수집하기 때문에 데이터셋이 상당히 클 경우 out-of-memory error가 발생할 수 있음
df.collect()
- 드라이버 executors 로 부터 모든 데이터를 수집하기 때문에 데이터셋이 상당히 클 경우 out-of-memory error가 발생할 수 있음
-
out-of-memory 오류를 피하기 위해서는
DataFrame.take()또는DataFrame.tail()을 활용
-
conversion back to a pandas DataFrame 를 pandas API 로 제공
df.toPandas()
2.3 Selecting and Accessing Data
PySpark DataFrame 은 lazily evaluated 이며 계산에 trigger 을 일으키지 않는 열을 심플하게 선택
df.a # output : Column<b'a'>, a Column instance
# In fact, most of column-wise operations return Colmns.
from pyspark.sql import Column
from pyspark.sql.functions import upper
type(df.c) == type(upper(df.c)) == type(df.c.isNull()) # output : TrueDataFrame.select() 는 Column 인스턴스를 받아 또 다른 DataFrame 을 반환 가능
df.select(df.c).show()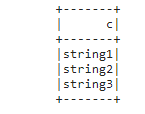
Assign new Column 인스턴스
df.withColumn('upper_c', uppper(df.c)).show()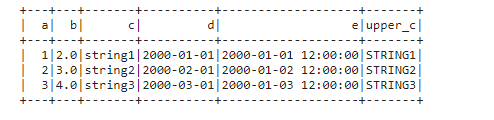
To select a subset of rows, use DataFrame.filter()
df.filter(df.a == 1).show()2.4 Applying a Function
PySpark 는 user 들이 Python native functions 를 실행할 수 있도록 다양한 UDFs 와 APIs 를 지원한다.
아래 예시를 통해 사용자들이 pandas Series APIs 를 직접적으로 사용할 수 있음을 알 수 있음.
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf('long')
def pandas_plus_one(series: pd.Series) -> pd.Series:
# Simply plus one by using pandas Series.
return series + 1
df.select(pandas_plus_one(df.a)).show()
DataFrame.mapInPandas 는 result length 와 같은 다른 제약 없이 직접적으로 pandas DataFrame APIs 를 사용할 수 있게 한다.
def pandas_filter_func(iterator):
for pandas_df in iterator:
yield pandas_df[pandas_df.a == 1]
df.mapInPandas(pandas_filter_func, schema=df.schema).show()2.5 Grouping Data
PySpark DataFrame 은 grouped data 를 핸들링하는 방법을 일반적인 접근법인 split-apply-combine strategy 를 활용해 제공한다. 이는 일반적인 조건을 함수를 각각의 group 에 적용하고 다시 DataFrame 에 결합하는 방법으로 데이터를 그룹화한다.
df = spark.createDataFrame([
['red', 'banna', 1, 10], ['blue', 'banna', 2, 20], ['red', 'carrot', 3, 30],
['blue', 'grape', 4, 40], ['red', 'carrot', 5, 50], ['black', 'carrot', 6, 60], ['red', 'banna', 7, 70], ['red', 'grape', 8, 80], schema=['color', 'fruit', 'v1', 'v2'])
df.show()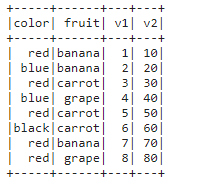
Grouping and then applying the avg() function to the resulting groups.
df.gorupby('color').avg().show()
You can also apply a Python native function against each group by using pandas API,
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.gorupby('color').applyInPandas(plus_mean, schema=df.schema).show()
Co-grouping and applying a function
df1 = spark.creatDataFrame(
[(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0), ('time', 'id', 'v1'))
df2 = spark.createDataFrame(
[(20000101, 1, 'x'), (20000101, 2, 'y')],
('time', 'id', 'v2'))
def asof_join(l, r):
return pd.merge_asof(l, r, on='time', by='id')
# This is similar to a left-join except that we match on nearest key
df1.gorupby('id').cogroup(df2.gorupby('id')).applyInPandas( asof_join, schema='time int, id int, v1 double, v2 string').show()
2.6 Getting Data in/out
CSV 는 직관적이고 사용하기 쉽다. Parquet, ORC 는 효율적이고 작은 파일 포맷으로 빠르게 읽고 쓴다.
PySpark 에는 JdBC, text, binaryFile, Avro 등의 다른 다양한 데이터 소스들도 사용가능하다.
csv
df.write.csv('foo.csv', header=True)
spark.read.sv('foo.csv', header=True).show()Parquet
df.write.parquet('bar.parquet')
df.read.parguet('bar.parquet').show()ORC
df.write.orc('zoo.ort')
spark.read.orc('zoo.orc').show()2.7 Working with SQL
DataFrame and Spark SQL share the same execution engine so they can be interchangebly used seamlessly. For example, you can register the DataFrame as a table and run a SQL easily as below:
df.createOrReplaceTempView("tableA")
spark.sql("SELECT count(*) form tableA").show()In addition, UDFs can be registered and invoked in SQL out of the box:
@pandas_udf("integer")
def add_one(s: pd.Series) -> pd.Series:
return s + 1
spark.udf.register("add_one", add_one)
spark.sql("SELECT add_one(v1) FROM tableA").show()SQL 식은 PySpark colums 와 직접적으로 섞이거나 사용될 수 있다
from.pysaprl.sql.fuction import expr
df.selectExpr('add_one(v1)').show()
df.select(expr('count(*)') > 0).show()
