- 하나의 노드에 엘리먼트 하나씩 저장
- 순서O (인덱싱)
- ArrayList, Vector, LinkedList
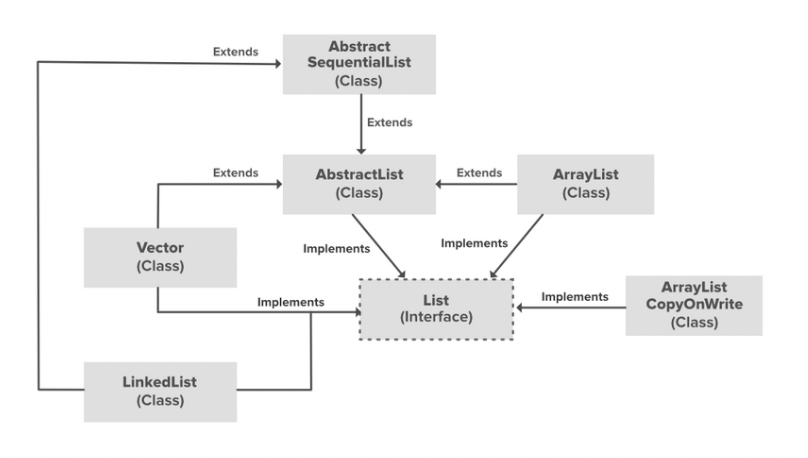
ArrayList
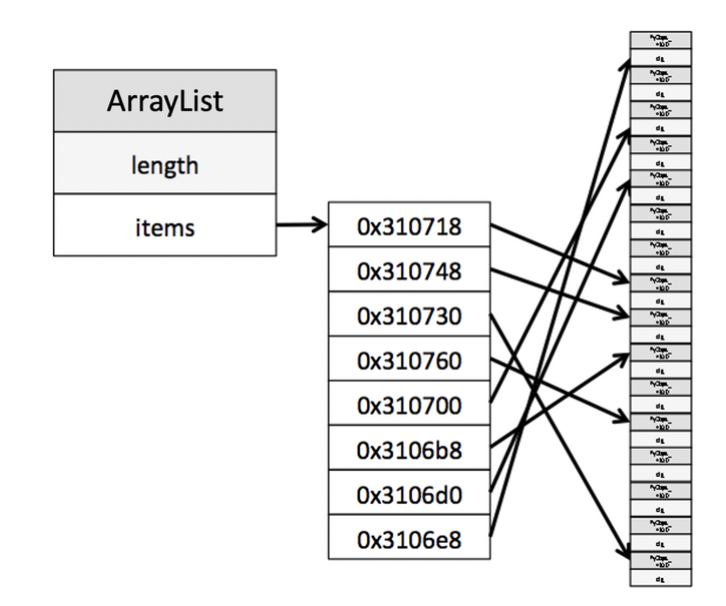
- 객체 배열을 동적으로 계산 (doubling, remove, .. 내부 구현)
- 배열 크기 부족해지면 50%로 늘림
- 연속적 주소 할당 (인덱싱), 주소가 가르키는 실제 객체들(JVM이 관리)은 순서 뒤죽박죽 일수도 있다. 주소만 알면 실제 데이터 접근 가능
- 검색 성능에 좋다
- 첫번째 주소 + (인덱스 * 8byte)
- 주소 배열에서 한개 삭제 =>
- 화살표 자동 삭제
- 실제 데이터는 참조되지 않으므로 Heap에 남아있다가 JVM GC가 수거
- 주소 배열을 한개 앞으로 땡겨주는건 직접 해야함 (주소의 빈칸 불가)
- 주소 배열에서 0번째 주소 삭제/추가 -> n-1개 다 땡겨/밀어줘야함 (대이동)
- 추가/삭제 성능에 안좋다
- not synchronized
Vector
- 하나의 스레드가 종료되어야 다음 스레드 실행
- JDK1.0
- 요즘 사용 안함
- 데이터를 순서대로 저장하는 동적인 배열
ArrayList+Synchronization- 하나의 객체에 두가지 역할을 주는 것은 좋지 않다
- =>
ArrayList/LinkedList에 저장하고 멀티 스레드가 접근해야 하는 경우에Collections.synchronizedList()/ConcurrentQueue사용하는 것이 좋다- 모든 메소드를 동기화 할 필요 없다 (시간, 성능 절약)
CUD: 필요
R: 불필요
- 모든 메소드를 동기화 할 필요 없다 (시간, 성능 절약)
LinkedList
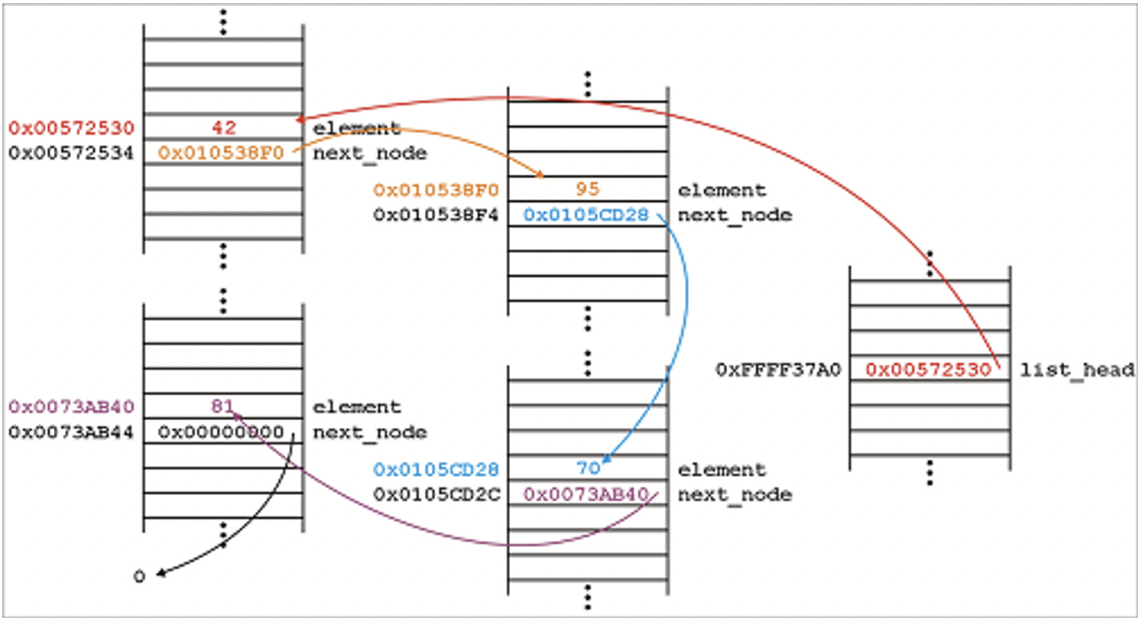
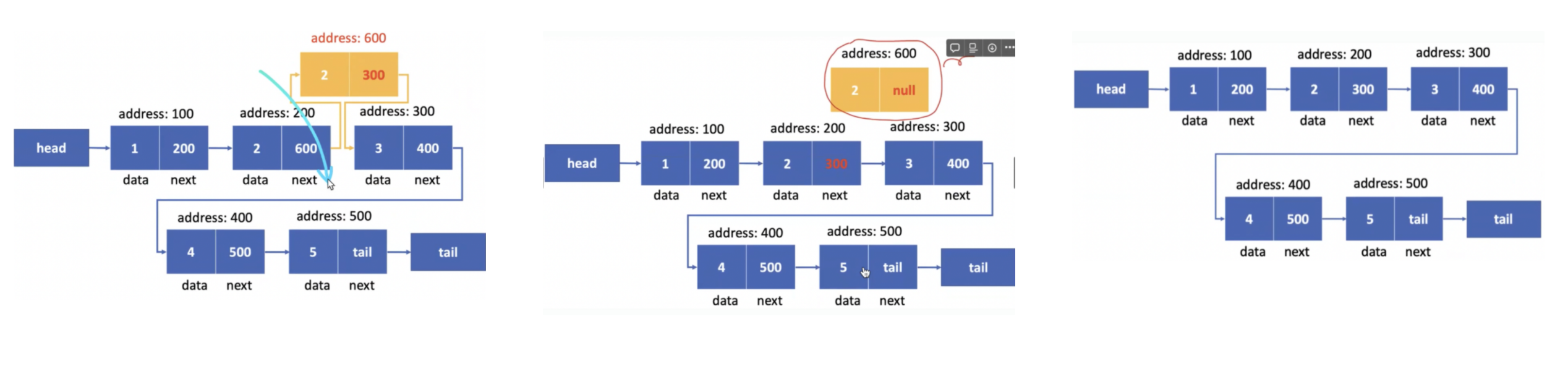
- 비연속적 주소 할당
- 하나의 노드에 다음 데이터의 주소와 데이터를 같이 저장
- 추가, 삭제 👍 : 대입 연산 (밀고 당기는 작업 필요 없음)
- 검색 👎 : for문 (곱하기, 더하기 불가)
- 원소의 추가, 삭제 동안 인덱스가 물리적인 주소의 순서와 달라질 수 있기 때문에 다시 앞의 노드부터 돌면서 인덱스 부여
doubly linked list
- 양방향 연결 리스트
next_node주소 뿐만 아니라prev_node주소도 가지고 있음 (하나의 노드에 3개 저장)single linked list보다 검색 성능이 향상
(배열의 사이즈(필드)를 알고 있으면 접근하려는 인덱스가 앞쪽이면 앞부터 검색. palindrome)- 자바에서 기본으로 제공하는 LinkedList는 양방향 연결 리스트
메서드
- ArrayList, LinkedList, Vector 모두 동일
- Vector는 + synchronized
- List
- api 사용 불가 -> ArrayList에 담아줘야 함 (업캐스팅)
- 초기화 :
of()-> stream
- Array
toString(),toArray(),asList()List<int>->List<String>->String[]->List<String>- 동적(수정O) <-> 정적(수정X)
- Array는 직접 만들어 사용해야함
toString()vs.valueOf()
ArrayList vs. LinkedList
List
업캐스팅 (인터페이스로 초기화)
- 인스턴스와 api의 타입을 인터페이스로 맞추면, 인스턴스의 타입을 상위 인터페이스(List)를 구현한 클래스(Stack, ArrayList, LinkedList, ..)로만 바꾼다면 api의 파라미터 타입을 수정하지 않아도 된다.
- 즉, 객체 간의 결합도를 낮추고 의존성을 분리하여 재사용성을 높인다. (한 코드의 변화가 다른 코드의 변화를 만들어내지 않을수록 생산성이 높다.)
- 구현 클래스의 api 사용
- 인터페이스는 api 구현부 없으므로 api 사용 불가
public class ListExample {
public static void main(String[] args) {
// 1. ArrayList를 Stack 으로 변경 해야 한다면
// List<Object> list = new ArrayList<Object>();
List<Object> list = new Stack<Object>();
// 2. 기존의 sizeOf() 사용 할때
int size = Counter.sizeOf(list);
}class Counter {
static int sizeOf(List<?> items) { // 3. 파라미터 수정하지 않아도 됨
return items.size();
}
}