데이터베이스는 개인적으로 학교에서 가장 재미있게 수업을 듣고 조금 더 심도 있게 들어가고 싶은 수업 중 하나이다. 처음에는 재밌게 하지만 뒤로 갈수록 어려워져서 잘 생각하면서 쿼리를 작성해야한다.
✅ 데이터베이스도 프로그램이 여러 종류가 있다. 학교에서는 오라클을 위주로 수업을 했으나, 학원에서는 Mysql을 바탕으로 이루어지고 있다. 프로그램 별로 사용하는 언어가 조금씩 다를 수 있으니 참고 바란다.
데이터베이스 관리 시스템(DataBase Management System)
-
데이터 베이스를 관리해주는 소프트웨어
데이터베이스 관리 시스템을 사용하는 이유?
- 중복된 데이터를 제거
- 자료를 구조화시킬 수 있음
- 다양한 프로그램을 사용하는 사용자들과 데이터를 공유
SQL(Structured Query Language)
- 데이터베이스에서 데이터를 정의, 조작, 제어하기 위해 사용하는 언어
- 대소문자 구별하지 않음
- 문자열을 저장할때 "(싱글 따옴표)만 사용
String sql = "select * from TB_Member where userid = 'apple'";데이터 베이스(Database)
- 통합하여 관리되는 데이터의 집합체를 의미한다.
- 중복된 데이터를 없애고, 자료를 구조화하여, 효율적인 처리를 할 수 있도록 관리된다.
데이터베이스 확인
show databases;데이터베이스 생성
create database 데이터베이스명;데이터베이스 사용(필수!)
use 데이터베이스명;데이터베이스 삭제
drop databases 데이터베이스명;- 데이터베이스를 삭제하면 해당 데이터베이스의 모든 테이블과 데이터도 전부 삭제된다.
테이블(Table)
- 데이터를 행과 열로 스키마에 따라 저장할 수 있는 구조
CREATE TABLE 테이블명 (
필드명1 필드타입 제약조건,
필드명2 필드타입 제약조건,
...
필드명n 필드타입 제약조건
)스키마란?
- 데이터베이스의 구조와 제약 조건에 관한 명세를 기술한 집합을 의미
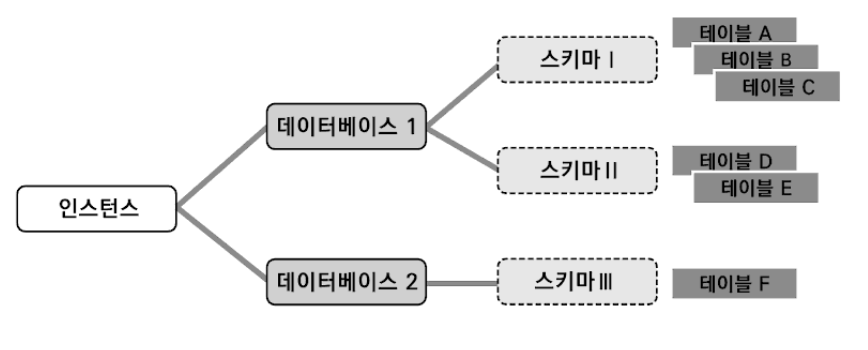
데이터타입
- 숫자 타입
- 정수 : tinyint, smallint, meduimint, int, bigint..
- 소수 : float, double
- 문자열 타입
- 텍스트 : char, varchar, text
ex) char(20) → 1byte만 저장하더라도 총 20byte를 소모
varchar(20) → 1byte를 저장하면 총 1byte를 소모
⇒ 저장공간을 생각하면 varchar를 사용하는 것이 좋다. - 바이너리 : binary, varbinary
- 열거 : enum
ex) enum('남', '여')
- 텍스트 : char, varchar, text
- 날짜와 시간 타입
- 날짜 : date
- 날짜와 시간 타입 : datetime, timestamp
제약 조건
- 데이터의 무결성을 지키기 위해 데이터를 입력 받을 때 실행하는 검사 규칙
무결성이란?
- 데이터베이스에 값이 정확하다는 것을의미
- 정확한 데이터를 유지하고 있다.
- NOT NULL : 필드에 NULL을 저장할 수 없다.
- UNIQUE
- 서로 다른 값을 가져야 한다.
- 중복된 값을 저장할 수 없다.
- null 값은 허용한다.
- DEFAULT : 기본값을 설정
- AUTO_INCREMENT
- 자동으로 숫자가 증가되어 추가
- 중복값이 저장되지 않음
- 직접 데이터를 추가할 수 없다.
- PRIMARY KEY
- UNIQUE 제약과 NOT NULL 제약을 동시에 가진다.
- 테이블에 오직 하나의 필드에만 적용된다.
- 데이터를 쉽고 빠르게 찾을 수 있게 적용한다.(색인)
- 외래키가 참조할수 있도록 설정
- FOREIGN KEY
- 다른 테이블과 연결해주는 역할
- 기준이 되는 테이블의 내용을 참조해서 레코드가 입력
- PRIMARY KEY를 참조
테이블 만들기
CREATE TABLE tb_member(
mem_idx bigint auto_increment primary key,
mem_userid varchar(20) unique not null,
mem_userpw varchar(20) not null,
mem_name varchar(20) not null,
mem_hp varchar(20) not null,
mem_email varchar(50) not null,
mem_hobby varchar(100),
mem_ssn1 char(6) not null, -- 주민번호 앞자리
mem_ssn2 char(7) not null, -- 주민번호 뒷자리
mem_zipcode char(5), -- 우편번호
mem_address1 varchar(100),
mem_address2 varchar(100), -- 상세주소
mem_address3 varchar(100), -- 특이 사항
mem_regdate datetime default now() -- 자동으로 시간을 저장할 수 있도록
);테이블 구조 확인
DESC 테이블명;테이블 삭제
DROP TABLE 테이블명;테이블에 필드 추가
ALTER TABLE 테이블명 ADD 컬럼명 컬럼타입 제약조건;테이블 필드 수정
ALTER TABLE 테이블명 MODIFY COLUMN 컬럼명 컬럼타입 제약조건;테이블 필드 삭제
ALTER TABLE 테이블명 DROP 컬럼명;데이터 삽입(INSERT)
-- 방법1) 모든 테이블의 모든 값을 fix에서 넣을때만
INSERT INTO 테이블명 VALUES(값1, 값2, 값3...);
-- 방법2)
INSERT INTO 테이블명(필드명1, 필드명2,..) VALUES (값1, 값2...);데이터 수정(UPDATE)
방법1) 전체 데이터 수정
UPDATE 테이블명 SET 필드 1 = 값1, 필드2 = 값2..
ex) UPDATE tb_member set mem_hobby = '운동';
방법2) 특정 행만 수정
UPDATE 테이블명 SET 필드 1 = 값1, 필드2 = 값2.. WHERE 조건절;
ex) UPDATE tb_member set mem_hobby = '운동' WHERE mem_userid = 'apple';
방법3) where절 이용
update tb_member set mem_point = mem_point + 500 where mem_userid = 'lemon';데이터 삭제(DELETE)
방법1) 전부 삭제
DELETE FROM 테이블명;
ex) DELETE FROM tb_member;
방법2) 조건절을 사용하여 삭제
DELETE FROM 테이블명 WHERE 조건절;
ex) DELETE FROM tb_member WHERE mem_userid = 'apple';SQL 연산자
- 산술 연산자
- +, -, *, /
- div : 왼쪽 피연산자를 오른쪽피연산자로 나눈 후 소수 부분을 버림
- mod : 나머지 연산
- 대입 연산자
- =
- =
- 비교 연산자
- =(같다), <>(다르다), <(작다), >(크다), <=(작거나 같다), >=(크거나 같다)
- is : 왼쪽 피연산자와 오른쪽 피연산자가 같으면 참
- is not : 왼쪽 피연산자와 오른쪽 피연산자가 다르면 참
- between A and B : 값이 A보다는 크거나 같고, B보다는 작거나 같으면 참을 반환
- in() : 연산자의 값이 인수로 전달받은 리스트에 존재하면 참을 반환
- 논리연산자
- AND, OR, XOR, NOT
검색(SELECT)
(👉🏻가장 많이 사용되므로 잘알고 있기!👈🏻)
기본문법)
Select 필드명1, 필드명2... From 테이블명;
where절 이용)
Select 필드명1, 필드명2... From 테이블명;
정렬)
SELECT 필드명1, 필드명2, FROM 테이블명 ORDER BY 정렬할 필드(ASC, DESC);
group by 이용)
SELECT 그룹을 맺은 필드 또는 집계함수 FROM 테이블명 GROUP BY 필드;집계함수
- count() : 데이터의 개수
- sum() : 합계
- max() : 최대값
- min() : 최소값
- avg() : 평균
별명을 주는 방법(필드명 만들기)
기본 문법) 필드 as 별명
예시)
select mem_gender, count(mem_idx) as count, sum(mem_point) as sum, max(mem_point) as max , min(mem_point) as min
from tb_member
group by mem_gender;테이블 병합(JOIN)
- 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
기본 문법
select 컬럼명1, 컬럼명2... from 테이블 1(Inner, left, right) join 테이블2 on 테이블1.필드명 = 테이블2.필드명INNER JOIN(교집합)
- INNER JOIN은 키 값이 있는 테이블의 컬럼 값을 비교 후 조건에 맞는 값을 가져오는 것
⇒ 서로 연관된 내용만 검색하는 조인 방법
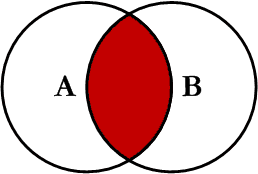
-- 기본 문법
select 테이블별칭.조회할 칼럼, 테이블별칭.조회할칼럼
from 기준 테이블 별칭 Inner join 조인테이블 별칭 on 기준테이블별칭.기준키 = 조인테이블별칭.기준키..
-- 예시
select mem_idx, mem_userid, mem_name, pro_gender, pro_height, pro_weight
from tb_member
inner join tb_profile on tb_member.mem_idx = tb_profile.pro_useridx;LEFT JOIN(왼쪽 테이블 중심)
- 기준테이블의 값 + 테이블과 기준테이블의 중복된 값을 보여준다.
- 왼쪽 테이블을 기준으로 JOIN을 하겠다고 생각하면 된다.
- 오른쪽에 일치하는 레코드가 없으면 오른쪽 결과는 null
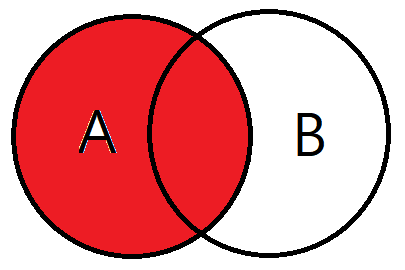
-- 기본 문법
select 테이블별칭.조회할 칼럼, 테이블별칭.조회할 칼럼
from 기준테이블 별칭
left join 조인테이블 별칭 on 기준테이블명.기준키 = 조인테이블별칭.기준키..
-- 예제
select mem_idx, mem_userid, mem_name, pro_gender, pro_height, pro_weight
from tb_member
left join tb_profile on tb_member.mem_idx = tb_profile.pro_useridx;RIGHT JOIN
- LEFT JOIN의 반대
- 오른쪽 테이블을 기준으로 JOIN을 하겠다고 생각하면 된다.
- 결과값은 오른쪽 테이블의 모든 데이터와 왼쪽 테이블과 오른쪽 테이블의 중복값이 나오게 된다.
- 만약 왼쪽에 일치하는 레코드가 없으면 오른쪽에서는 결과가 Null
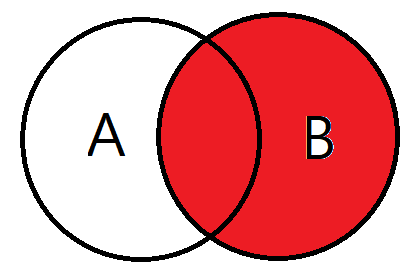
-- 기본 문법
select 테이블별칭.조회할칼럼, 테이블별칭.조회할칼럼
from 기준테이블 별칭
right join 조인테이블 별칭 on 기준테이블별칭.기준키 = 조인테이블별칭.기준키..
-- 예시
select mem_idx, mem_userid, mem_name, pro_gender, pro_height, pro_weight
from tb_member
right join tb_profile on tb_member.mem_idx = tb_profile.pro_useridx;