데이터 파이프라인(Data pipeline)은 차례대로 전달해 나가는 데이터로 구성된 시스템입니다. 데이터의 원천부터 시작하여 필요한 데이터를 추출하고, 그 데이터를 정제하고, 변환하고, 분석하고, 저장하고, 전달하는 과정을 포함합니다. 또한 어디에서 데이터를 수집하고 무엇을 달성하고 싶은지에 따라 그 구성이 변화합니다.
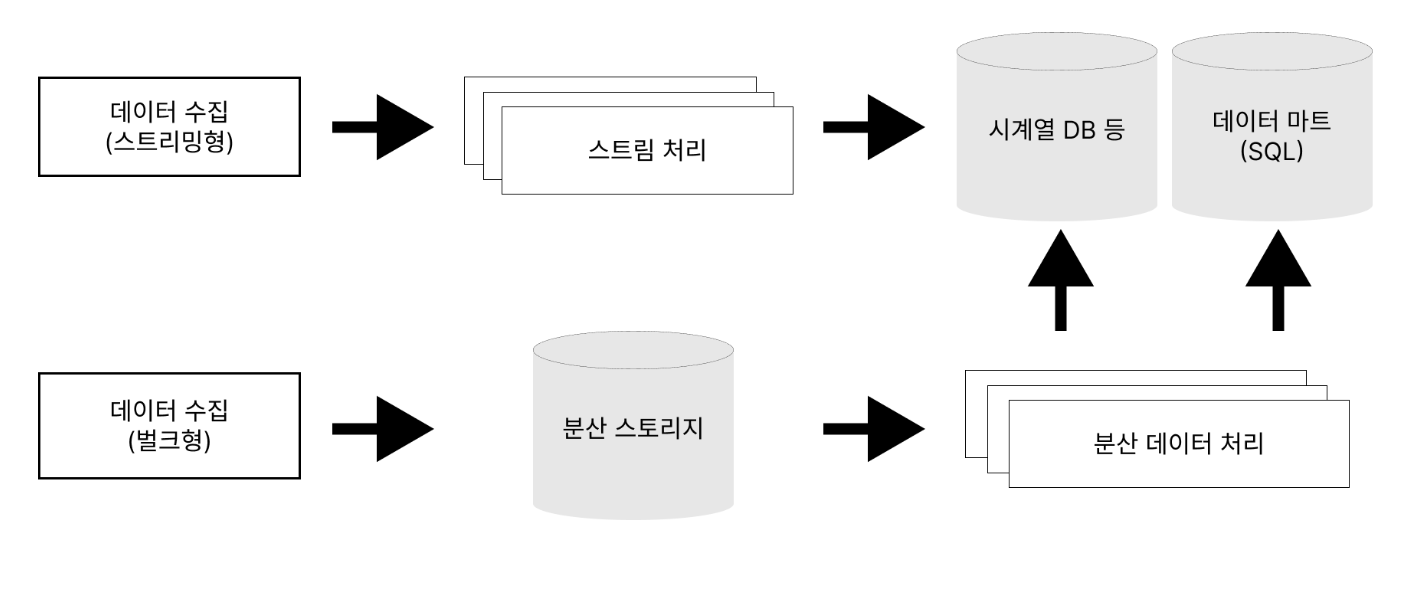
데이터 수집 방식 - 벌크형 / 스트리밍형
벌크형(bulk)은 이미 존재하는 데이터를 정리해 추출하는 방법입니다. 데이터베이스와 파일 서버 등에서 정기적으로 데이터를 수집할 때 사용합니다. 스트리밍형(streaming)은 차례대로 생성되는 데이터를 끊임없이 연속적으로 보내는 방법인데요. 모바일 앱이나 임베디드 장비 등에서 데이터를 수집하는 데에 사용합니다.
데이터 처리 방식 - 스트림 처리 / 배치 처리
스트림 처리는 스트리밍형으로 수집된 데이터를 처리하는 방식입니다. 실시간 데이터 분석에 적합해요. 배치 처리는 대량의 데이터를 저장하고 처리하는 방식이며, 장기적 데이터 분석에 적합합니다.
저장소 - 분산 스토리지와 객체 스토리지
분산 스토리지는 여러 컴퓨터와 디스크로 구성된 스토리지 시스템으로, 데이터가 수집되면 분산 스토리지에 저장합니다. 분산 스토리지의 대표적인 예시가 객체 스토리지인데, 폴더와 같이 한 덩어리로 모인 데이터에 이름을 부여해 파일을 저장하는 방식입니다. 아마존의 S3가 이 방식을 따른다고 하네요. 그 밖에도 NoSQL 데이터 베이스를 분산 스토리지로 사용하기도 합니다.
분산 데이터 처리
여러 곳에서 데이터를 가져와서 클러스터에서 분산 데이터 처리를 합니다. 이때 클러스터는 한 대의 컴퓨터처럼 운영되는 다수의 컴퓨터 집단이에요. 분산 데이터 처리를 통해서 외부 DB(시계열 DB나 데이터 마트)에 저장해 두면 그때그때 필요한 데이터를 빠르게 찾아서 분석에 쓸 수 있습니다.
워크플로 관리
빅데이터 처리에는 크고 작은 시스템 장애가 생기기도 합니다. 데이터 파이프라인이 복잡해지면서 각 과정에서의 정상 동작 여부를 확인하기가 까다로워지고요. 데이터 파이프라인의 전체 동작을 관리하려면 정해진 시각에 정확하게 실행되는지, 혹시 오류가 생기진 않았는지 알려주는 도구가 필요합니다. 이때 쓰이는 것이 워크플로 관리 기술이에요. 매일 정해진 시각에 배치 처리를 실행하고, 오류가 발생하면 관리자에게 알람을 보내주는 방식이지요. 자동화와도 관련이 높습니다.
