우리는 목표로 하는 함수를 모사하기 위해, 학습용 데이터들을 Linear layer에 넣어 출력값들을 구하고, 그 출력 값(yhat)들과 목표 값(y)들의 차이의 합 (Loss)를 최소화 해야한다. 결국 Linear layer 파라미터를 바꾸면서 Loss를 최소화할 방안을 찾아야 한다.
다르게 말하자면, 손실함수는 파라미터에 따른 함수 동작의 오류의 크기를 반환하기 때문에, 손실함수를 최소화하는 파라미터를 찾으면 된다.
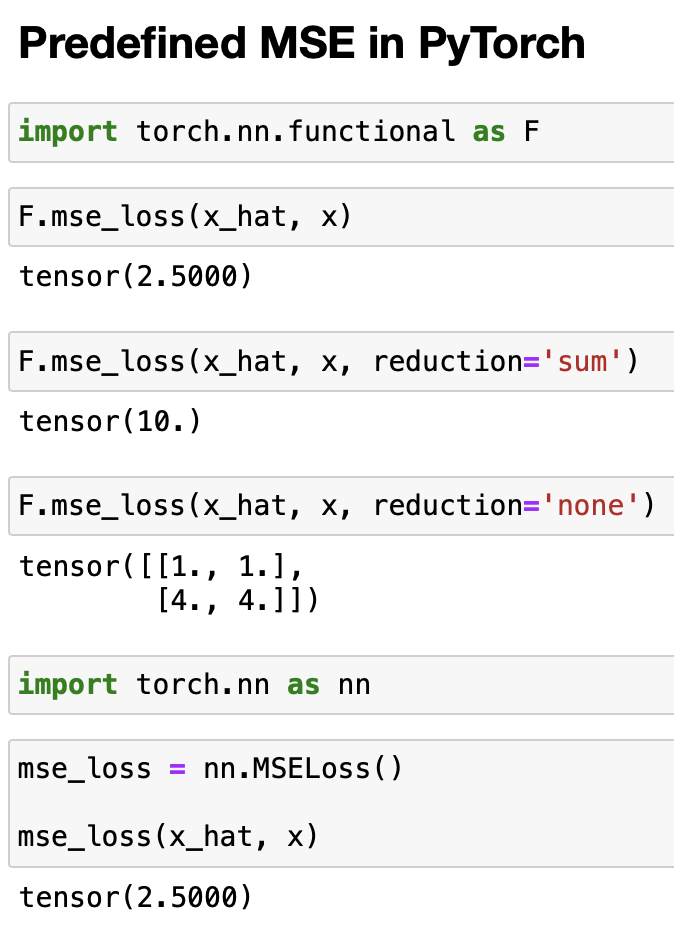
Regression : MSE
Classification (softmax) : Cross-Entropy
Binary Classification : Binary-Cross-Entropy
LogSoftmax : NLLLoss
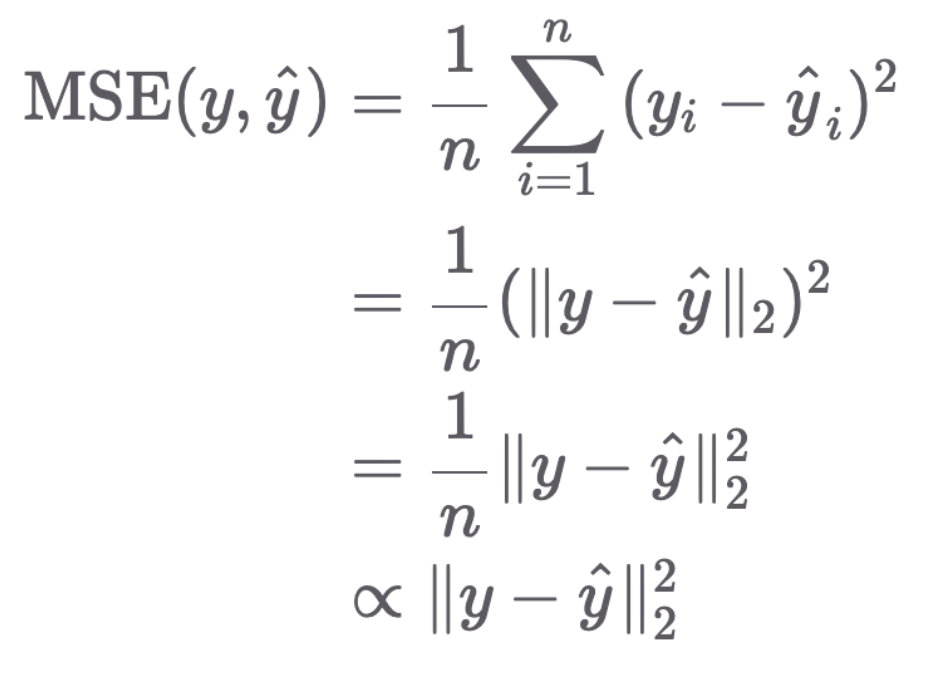

Frontend & Artificial Intelligence