Gradient Descent(경사하강법) 기법들
1. ★ SGD ★
원래의 경사하강법은 전체 데이터셋을 바탕으로 진행하기에 학습 수렴속도가 느리다는 단점이 있었다. 이에 등장한 것이 확률적 경사하강법(Stochastic Gradient Descent, SGD)이다.
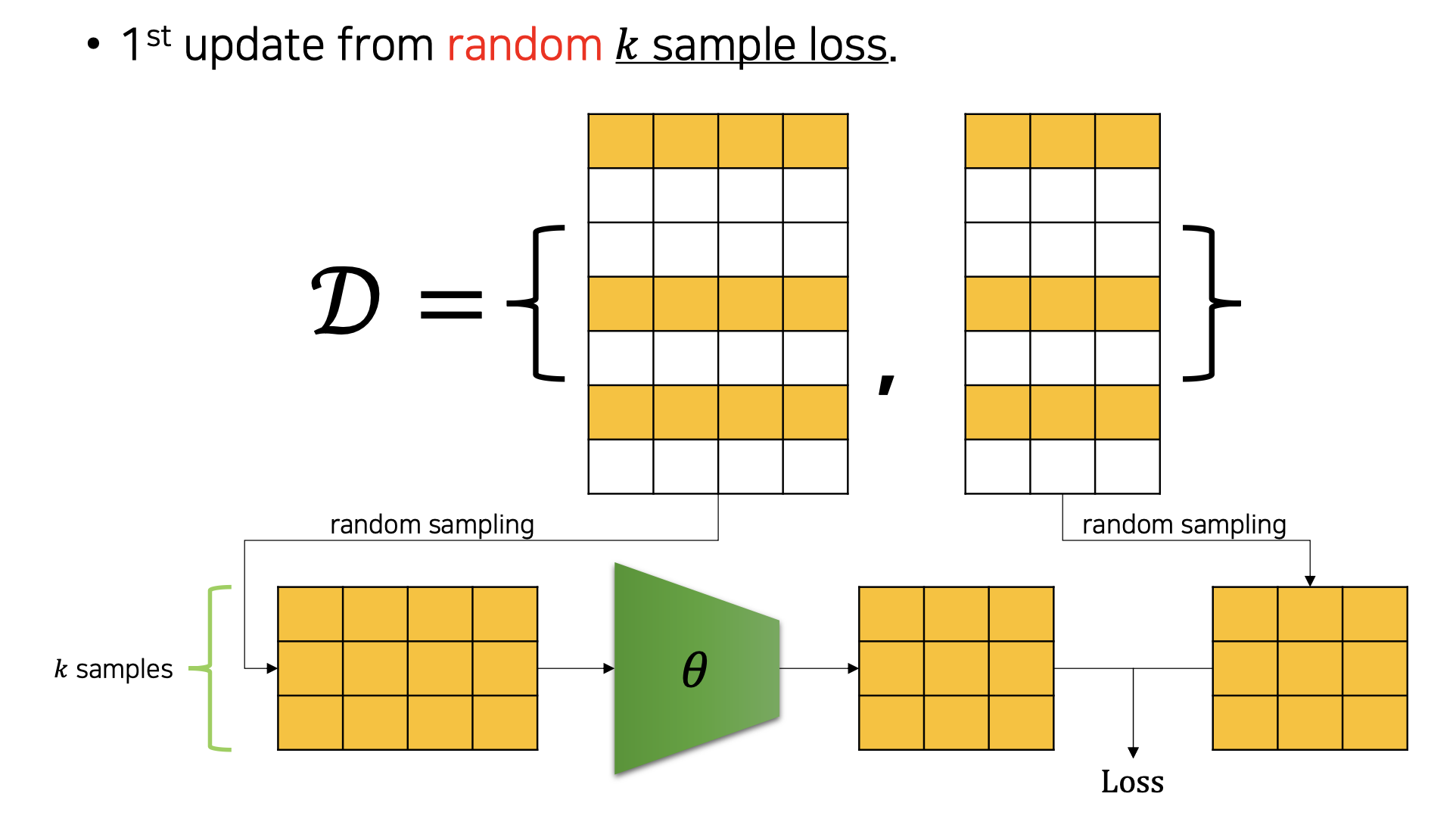
원래 SGD는 전체 데이터 중 단 하나의 데이터를 이용하여 경사 하강법을 1회 진행(배치 크기가 1)하는 방법을 말하는 것이었으나, 최근에는 전체 데이터를 batch_size개씩 나눠 배치로 학습(배치 크기를 사용자가 지정)하는 것을 말한다.(MSGD : Mini batch SGD)
-
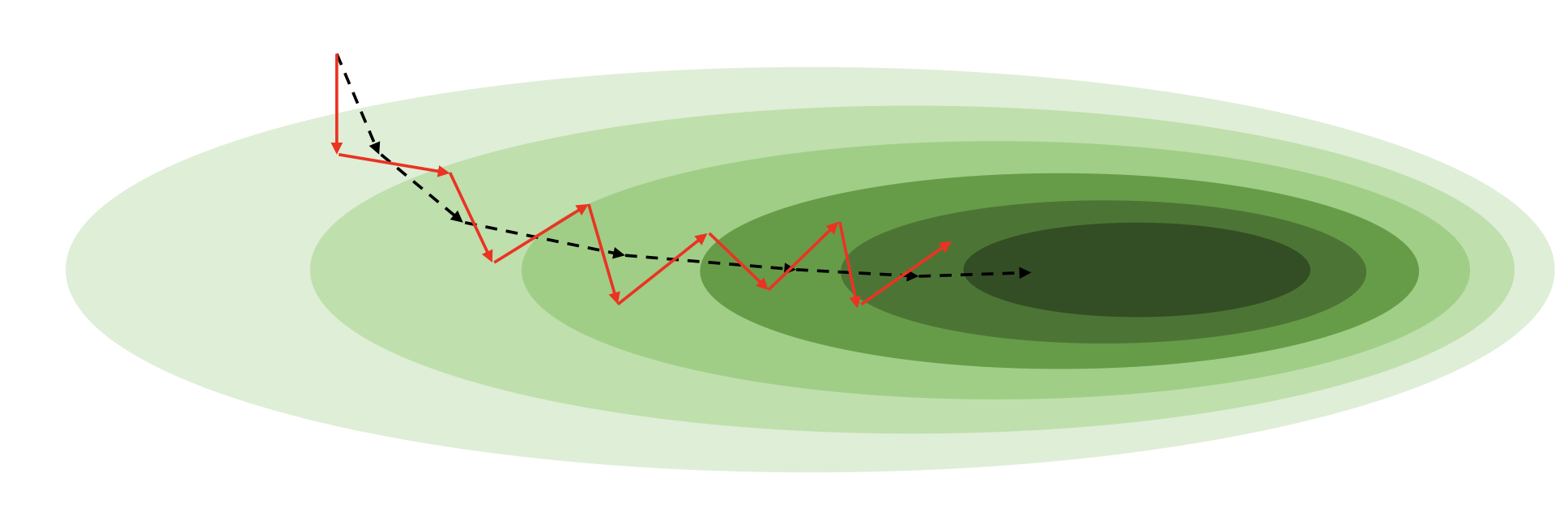
각 미니배치의 gradient는 전체 데이터의 gradient와 다를 것 (훨씬 noisy할 것)
• 하지만 미니배치 gradient의 평균(기대값)은 전체 데이터의 gradient와 같을 것 -
Batch size가 작을 수록 variance는 더욱 커질 것 (수렴이 어려워짐)
• 어쩌면 이로 인해 local minima를 탈출할수도 있음
• 하지만 실용적인 관점에서 local minima는 큰 문제가 아닐 수 있음. 애초에 global minima의 근처일 것이기 때문 -
따라서 적절한 batch_size를 가져가는 것이 좋다.
• 주로 64, 128, 256... ( 꼴) -
요즘 학계의 추세는 큰 batch_size를 가져가려함
• batch size가 클 수록 전체 데이터 셋의 gradient 방향과 비슷해질 것
• GPU를 사용하면 병렬 연산으로 인해, 큰 배치사이즈로 인한 비용이 줄어들게 되었음
• 매우 큰 배치사이즈의 경우에는 오히려 성능을 악화시킬 수도 있음 (파라미터 업데이트가 상대적으로 덜 진행됨)
• 하지만 상대적으로 빠르게 수렴 가능
실습



2. Momentum
Momentum은 이름 그대로 기울기에 관성 효과를 이용하여 더 빠르게 최적값에 도달할 수 있도록 하는 방법론이다. 이는 Gradient Descent에 가속도항을 추가하여 기존 가중치가 감소하던 (혹은 증가하던) 방향으로 더 많이 변화하여 Local Minimum 등의 문제를 해결한다.
3. Adagrad
Adagrad는 각 가중치마다 학습률을 Adaptive 하게, 다르게 조절하여 각 가중치별 특성을 고려하여 학습을 효율적으로 돕는 방법론이다. 이는 각 Gradient마다 이전 기울기의 누적 제곱합에 반비례하도록 학습률을 조정하여 업데이트를 진행한다. 이를 통해 이전에 큰 기울기로 업데이트가 진행된 가중치는 작게 업데이트하고, 이전에 작은 기울기로 업데이트가 진행된 가중치는 큰 비율로 업데이트를 진행하게 된다.
4. RMSProp
RMSProp은 Adagrad를 더 발전시킨 방법론으로 단순 누적 제곱합을 활용하는 것이 아니라 지수이동평균(Exponential Moving Average, EMA)을 활용하여 기울기 업데이트를 진행한다. 즉, 가장 최근 time step의 기울기를 많이 반영하고, 과거의 기울기는 조금만 반영하게 된다.
5. ★ Adam ★
Momentum과 Ada 계열 중 하나인 RMSProp의 장점만을 결합한 알고리즘이다.
learning rate에 대한 고민을 없앨 수 있다.
결론
요즘의 추세는 Adam과 SGD를 선호
• Adaptive LR Scheme에서는 Adam이 가장 인기
• 일각에서는 SGD가 최종 성능이 뛰어나단 주장
• Adam + SGD를 섞어쓰기도
