0. 데이터 처리 과정
데이터 수집 > 저장 > 처리 > 분석 > 표현
출처
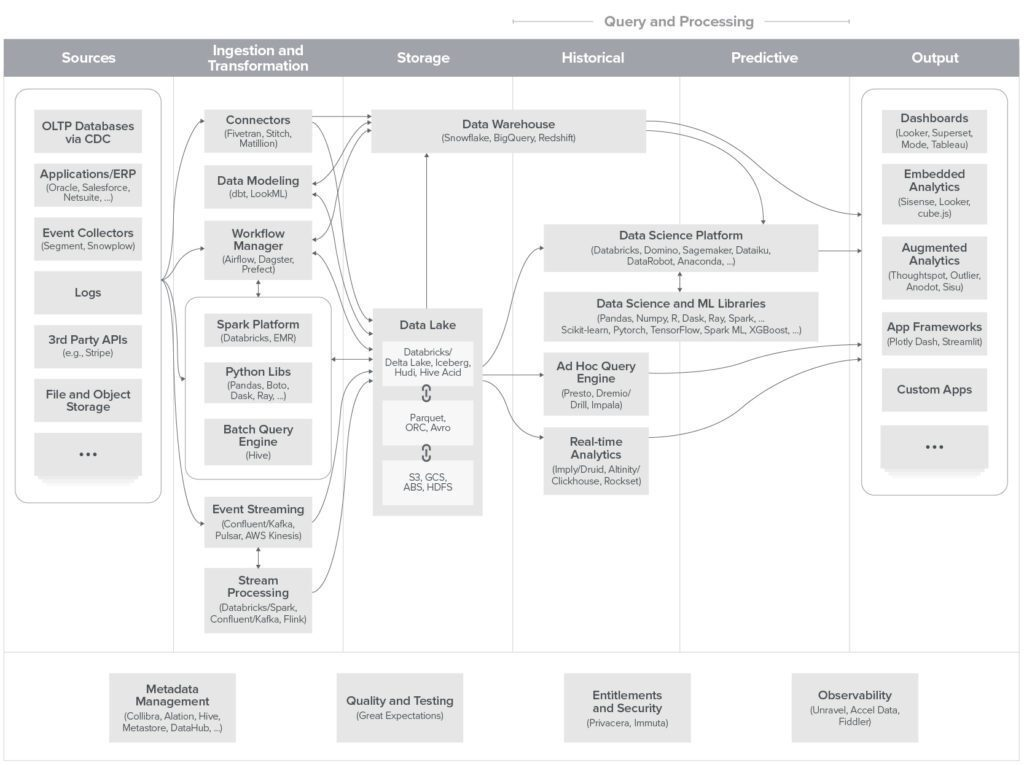
1. 데이터 수집
0) 데이터의 분류
- 데이터는 3가지 형태로 분류됨
| 데이터 | 특징 | 예시 |
|---|---|---|
| 비정형 데이터 | 정해진 규칙이 없고, 값의 의미를 쉽게 파악하기 힘듦 | 음악, 음성 데이터, 동영상 |
| 반정형 데이터 | 어느 정도 규칙이 있지만, 그 규칙이 상황에 따라 너무 다르게 나타나는 것 | HTML, XML, JSON |
| 정형 데이터 | 값의 의미 파악이 쉽고, 규칙적인 값으로 데이터가 들어간 경우 | CSV, RDBMS, 엑셀 파일 |
1) 내부 데이터 수집
- 수집하려는 데이터가 내부시스템에 있다는 것을 의미함 원천데이터와 수집한 데이터가 동일 시스템계에 저장돼 있으므로 원천데이터가 외부에 있는 경우와 비교했을 때 상대적으로 기술적 제약도 적은 편임
| 데이터 | 종류 | 수집 방법 |
|---|---|---|
| 비정형 데이터 | DBMS, 이진파일 | - ftp 프로토콜을 사용해 파일을 수집 시스템에 다운로드 하고 해당 파일을 API를 통해 데이터 처리 |
| 반정형 데이터 | 스크립트 파일, 이진 파일 | - http 프로토콜을 사용해 파일의 텍스트를 스크랩하고 데이터에 저장된 메타정보를 읽어 파일을 파싱해 데이터 처리 - 스트리밍을 사용해 파일의 텍스트를 스크랩하고 데이터에 저장된 메타정보를 읽어 파일을 파싱해 데이터 처리 |
| 정형 데이터 | 스크립트 파일 | - DBMS 벤더가 제공하는 API를 통해 정형 데이터에 접근해 데이터를 수집하고 시스템에 저장 - ftp 프로토콜을 사용해 파일을 수집 시스템에 다운로드 하고 해당 파일의 API를 통해 데이터 처리 |
2) 외부 데이터 수집
- 수집하려는 데이터가 외부 시스템에 있는 경우를 의미함 데이터 제공자와 협약된 관계가 아니면 상호 의사소통이 불가능하며 데이터 수집을 위해 수집주기 및 방법에 관한 분석이 필요함
| 데이터 | 종류 | 수집 방법 |
|---|---|---|
| 비정형 데이터 | DBMS, 이진파일 | - ftp 프로토콜을 사용해 파일을 수집 시스템에 다운로드하고 해당 파일을 API를 통해 데이터 처리 - http 프로토콜을 사용해 파일의 텍스트를 스크랩하고 내부 처리에서 텍스트를 파싱해 데이터 처리 |
| 반정형 데이터 | 스크립트 파일, 이진 파일 | - http 프로토콜을 사용해 파일의 텍스트를 스크랩하고 데이터에 저장된 메타정보를 읽어 파일을 파싱해 데이터 처리 - 스트리밍을 사용해 파일의 텍스트를 스크랩하고 데이터에 저장된 메타정보를 읽어 파일을 파싱해 데이터 처리 |
| 정형 데이터 | 스크립트 파일 | - DBMS 벤더가 제공하는 API를 통해 정형 데이터에 접근해 데이터를 수집하고 시스템에 저장 - ftp 프로토콜을 사용해 파일을 수집 시스템에 다운로드하고 해당 파일의 API를 통해 데이터 처리 |
3) Hadoop
- Hadoop은 주로 대량의 로그를 수집해 저장, 처리까지 한다.
| 데이터 | 종류 | 수집 방법 |
|---|---|---|
| 비정형 데이터 | DBMS | 척와(Chukwa), 스크라이브(Scribe) |
| 반정형 데이터 | 스크립트 파일 | 플룸(Flume) |
| 정형 데이터 | 파일 | 스쿠프(Sqoop), hiho |
2. 데이터 저장 및 처리
1) 데이터 저장
(1) NoSQL
SQL에서 주로 다루던 관계형 데이터베이스가 복잡하게 관계형 구조를 짜야하고 스키마도 있고하니 편하게 문서형 데이터를 저장할 수 있는 방법이 없을까? 하고 나온기술이면서도 RDBMS 한계를 극복 할 수 있는 기술
- RDBMS의 한계
1) 스키마에 준수하지 않는 레코드는 추가할 수 없음 즉, 비정형 데이터 처리 불가
2) 대량의 데이터를 입력할 경우나 조회할 경우 성능이 저하
3) 수평적 확장이 어렵고, 대체로 수직적 확장만 가능 즉, 처리의 한계가 명확함
NoSQL의 기술적 특징
- 무(無) 스키마 : RDBMS는 데이터의 관계를 Foreign Key 등으로 정의하고 join 등 관계형 연산을 하지만 그러한 SQL의 RDBMS와는 달리 데이터를 모델링하는 고정된 데이터 스키마 없이 Key값을 이용하여 다양한 형태의 데이터를 저장하고 접근 즉, 관계를 정의하지 않아도 됨
- 분산형 구조 : NoSQL은 분산형 구조를 통해 여러대의 서버에 분산하여 저장하고 상호복제하여 데이터 유실이나 서비스 중지에 대비가 가능함
- : CAP이론 준수 : 분산형 구조는 일관성(Consistency), 가용성(Availability), 분산허용(Partitioning Tolerance)의 3가지 특징을 가지고 있고 CAP이론은 이 중 2가지만 만족할 수 있다는 이론
(2) 분산 파일 시스템
HDFS(Hadoop Distributed File System) : 대용량 파일을 분산된 서버에 저장하고, 많은 클라이언트가 저장된 데이터를 빠르게 처리할 수 있게 설계된 파일 시스템
2) 데이터 처리
(1) 배치 처리(Batch Processing)
- 일괄처리라고도 불림
- 데이터를 바로바로 처리하는 것이 아닌 일괄적으로 모아서 한 번에 처리하는 작업
- Ex) 은행 정산작업
(2) 실시간 처리(Real-Time Processing)
- 데이터가 발생과 동시에 즉시 처리하는 방식
- 주로 log처럼 스트리밍 데이터를 처리할 때 쓰임
- Ex) Instagram, Twitter 등 글
(3) 대화형 처리(Interactive Processing)
- 사용자의 입력에 대하여 컴퓨터에서 바로 결과를 출력
- Ex) Python, Scala
3. 데이터 분석
1) 텍스트 마이닝 (Text mining)
- 자연어 처리(NLP)하여 비정형 데이터에서 정보(단어)를 추출하여 의미있는 정보를 발견하는 분석 방법
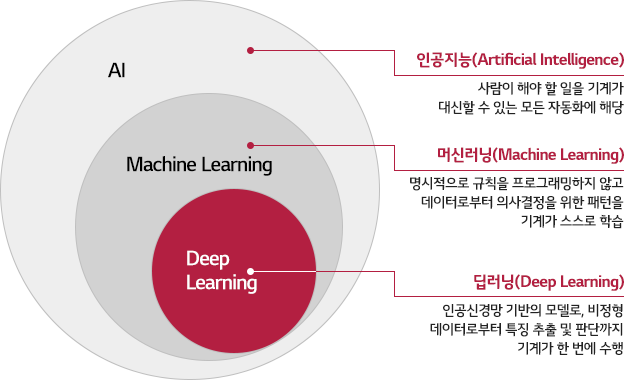
2) 기계학습 (Machine Learning)
- 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 딥러닝 또한 기계학습에 포함됨
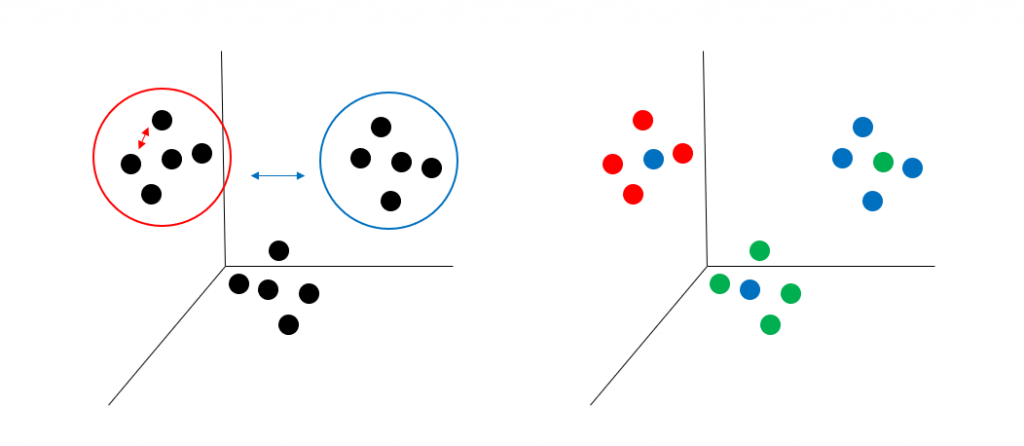
3) 군집화 (Clustering)
- 비슷한 데이터끼리 모아 군(집합)으로 분류하는 학습 방법
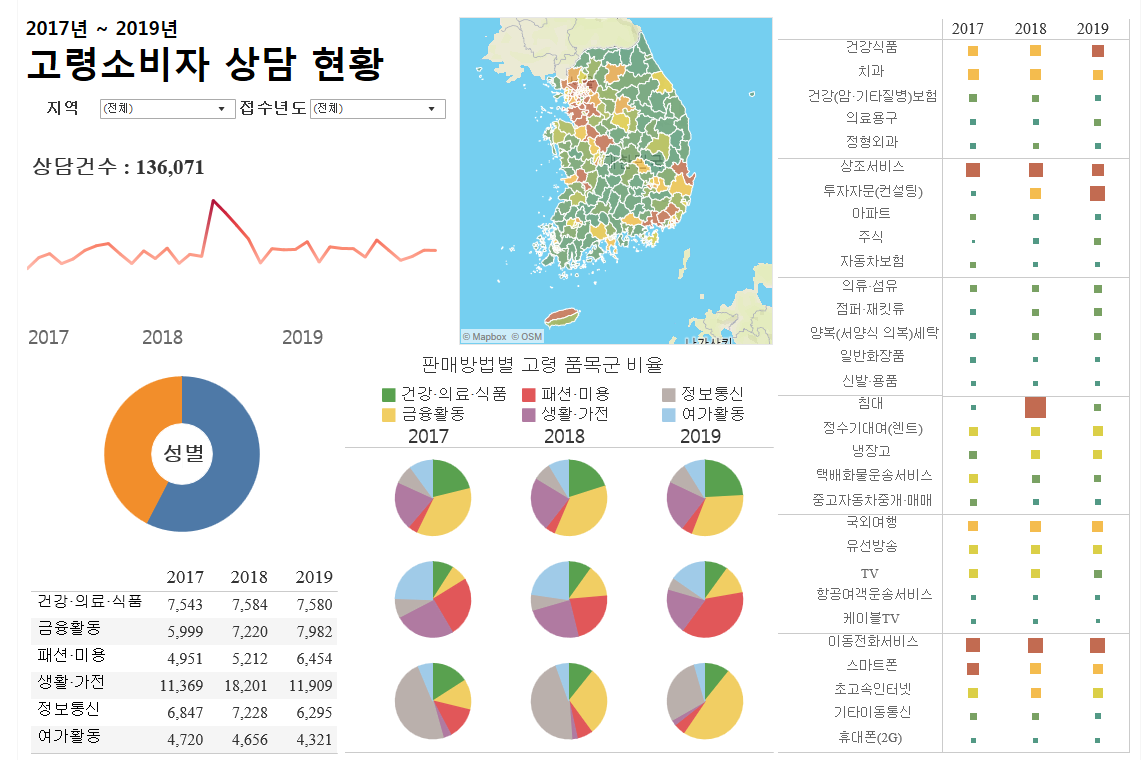
4. 데이터 표현
1) 시각화
- 데이터 시각화(data visualization)는 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정
- Kibana, R 등이 있음

사진은 남아 추억이 메모는 남아 스펙이 된다