1. 데이터타입
자바스크립트 데이터 타입은 두가지로 분류
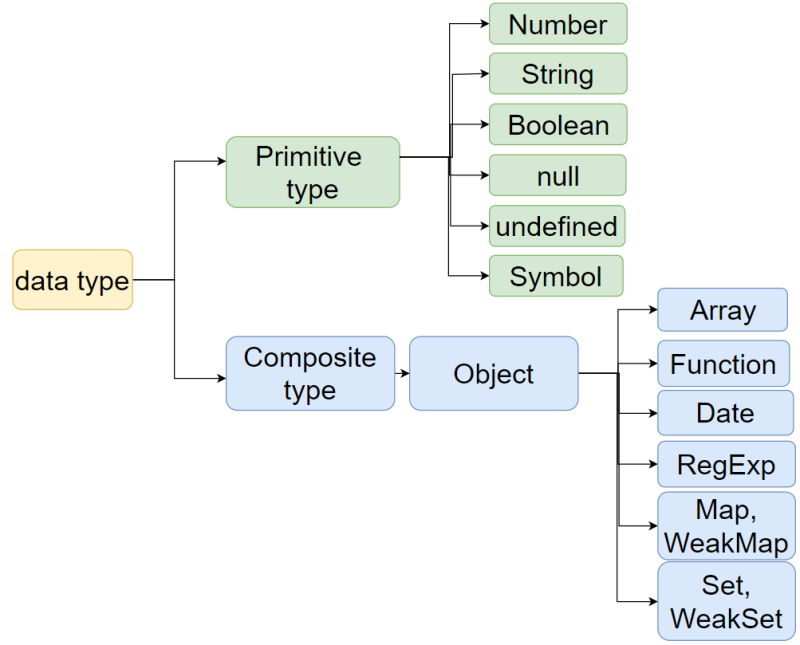
메모리상에서 저장되는 형태가 다르다.
→ 컴퓨터는 하는 일은 우선 메모리 안에서 데이터가 담길 공간을 확보한다.
→ 컴퓨터가 이해하기에는 선언 다음 할당이 이루어진다.
→ 메모리구조 공간 하나에는 값이 하나씩 밖에 못들어간다 - 실제 자바스크립트 메모리구조
- 스택 메모리(변수, 기본형 데이터, 정적 할당)
- 힙 메모리(참조형 데이터, 동적 할당)
기본형 데이터
var a;
a = 'abc';
a = 'abcdef';| 주소 | ... | 1002 | 1003 | 1004 | 1005 | ... |
|---|---|---|---|---|---|---|
| 데이터 | 이름 : a 값 : @5005 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | ... |
|---|---|---|---|---|---|---|
| 데이터 | 'abc' | 'abcdef' |
처음에는 @5004를 할당하였다가 나중에는 @5005를 할당한다.
참조형 데이터
기본형에 비해서 참조형이 메모리 할당 과정이 한단계를 더 거친다.
기본형은 바로 값이 변하는 반면에 참조형은 값이 변하지 않는다.
ex1)
var obj = {
a : 1,
b : 'bbb'
}| 주소 | ... | 1002 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : obj 값 : @5002 |
| 주소 | 5002 | 5003 | 5004 | 5005 | 5006 |
|---|---|---|---|---|---|
| 데이터 | @7103 ~ ? | 1 | 'bbb' |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : a 값 : @5003 |
이름 : b 값 : @5004 |
ex2)
var obj = {
a : 1,
b : 'bbb'
}
obj.a = 2;| 주소 | ... | 1002 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : obj 값 : @5002 |
| 주소 | 5002 | 5003 | 5004 | 5005 | 5006 |
|---|---|---|---|---|---|
| 데이터 | @7103 ~ ? | 1 | 'bbb' | 2 |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : a 값 : @5005 |
이름 : b 값 : @5004 |
ex3)
var obj = {
x : 3,
arr : [3, 4]
};
obj.arr = 'str';| 주소 | ... | 1002 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : obj 값 : @5002 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | 5006 | ... |
|---|---|---|---|---|---|---|---|
| 데이터 | ... | @7103 ~ ? | 3 | @8104 ~ ? | 4 | 'str' | ... |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : x 값 : @5003 |
이름 : arr 값 : @5006 |
| 주소 | ... | 8104 | 8105 | 8106 | 8107 | 8108 | ... |
|---|---|---|---|---|---|---|---|
| 데이터 | ... | 이름 : 0 값 : @5003 |
이름 : 1 값 : @5005 |
... |
참조되지 않는 대상은 0이다.
즉, 참조카운트가 0이면 Garbage Collecting의 대상이 된다.
@5004번과 @8104~주소는 Garbage Collecting 대상이 되어 없어진다.
ex4)
3을 직접 할당한다면
var obj = {
x : 3,
arr : [3, 4]
};| 주소 | ... | 1002 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : obj 값 : @5002 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | 5006 | ... |
|---|---|---|---|---|---|---|---|
| 데이터 | ... | @7103 ~ ? | 3 | @8104 ~ ? | 4 | ... |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
|---|---|---|---|---|---|
| 데이터 |
이름 : x 값 : 3 @5003 |
이름 : arr 값 : @5004 |
| 주소 | ... | 8104 | 8105 | 8106 | 8107 | 8108 | ... |
|---|---|---|---|---|---|---|---|
| 데이터 | ... | 이름 : 0 값 : 3 @5003 |
이름 : 1 값 : @5005 |
... |
아래 예시를 살펴보자.
var obj = {
x : '매우 큰 용량을 차지하는 문자열!',
arr : ['매우 큰 용량을 차지하는 문자열!', 4]
};
obj.x === obj.arr[0];| 주소 | ... | 7103 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : x 값 : 10111110000000111010101010111000110010101010011... |
| 주소 | ... | 8104 | 8105 | 8106 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : 0 값 : 10111110000000111010101010111000110010101010011... |
눈으로 보기에는 똑같지만 컴퓨터는 문자열에 대해서 이진법 숫자로 전환한 다음에야 메모리에 저장한다.
비교를 하게 된다면 이진법인 상태에서 하나하나 비교를 하기 때문에 상당한 성능저하를 일으킨다.
요거는 2개지만 100개 1000개라면 엄청난 성능 저하를 일으킬것이다.
처음에 한 번 저장할때 비어있는 다른 메모리에다가 저장해놓고 그 메모리를 저장하는 방식)
| 주소 | ... | 7103 | 1003 | 1004 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : x 값 : @1003 |
10111110000000111010101010111000110010101010011... |
| 주소 | ... | 8104 | 8105 | 8106 | ... |
|---|---|---|---|---|---|
| 데이터 | 이름 : 0 값 : @1003 |
반면에 처음에 한 번 저장할때 비어있는 다른 메모리에다가 저장해놓고 그 메모리를 계속 저장하는 방식을 따르게 된다면 문자열 리터럴을 새로 만들어서 입력할 때마다 기존에 저장된 데이터가 있는지 그 데이터들이랑 하나하나 비교를 해봐야 되는 단점이 있다. 처음에 저장할 때는 당연히 없을 테니까 새로 저장을 했는데 두번째로 다시 리터럴을 만들어서 저장을 하려고 할때 기존에 있는 1003번에 이 값이 같은 값이 있느지를 찾고 걔랑 비교해서 완전히 같으면 그거를 재활용하고 없으면 새로 만들고 할 텐데 그래서 할당하는데 있어서는 시간이 좀더 걸릴 수 밖에 없다. 하지만 한 번 동일성을 판단이 되면 이후에는 비교 과정을 몇번을 수행하든 전혀 비용이 발생하지 않는다. 의외로 메모리도 들차지한다.
결론
값을 직접 저장하는 방식
- 데이터 할당시에는 빠름
- 비교에 비용이 많이 듬
- 메모리 낭비가 심함
값의 주소를 저장하는 방식
- 데이터 할당시에는느림
- 비교에 비용이 들지 않음
- 메모리 낭비 최소화
중요❗️
값의 주소를 저장함으로써 비교에 비용이 들지않음
→ 즉, 같은 값이 오직 하나만 존재 - 불변값
기본형 데이터 복사 & 참조형 데이터 복사


