Proportional Share Scheduler
- Fair-share scheduler
각 job에 가중치를 부여하고 가중치에 비례하여 CPU-time을 분배한다.
turnaround time이나 response time에 최적화된 scheduler는 아니다.
Tickets
가중치를 나타내는 방법이다.
각 process가 갖고 있는 tickets수의 비율을 통해 system resource를 분배한다.
- Example:
전체 tickets이 100개인데 A가 75개, B가 25개 가지고 있으면
resource의 75%를 A가, 25%를 B가 가지게 된다.
Lottery scheduling
- The scheduler picks a winning ticket
ticket 번호를 random하게 하나 뽑고 그 번호의 ticket을 갖고 있는 process가 실행된다.
- Example:
100개의 ticket이 있고 A가 75개 0~74, B가 25개 75~99의 ticket을 소유하고 있을 때

winning ticket이 위와 같이 뽑혔다고 가정하면 실행되는 job의 순서는 위와 같다.
Job의 길이가 길면 길수록 fair 해진다.
-> winning ticket은 random 함수를 통해 결정되는데, random 함수는 실행 횟수가 증가할수록 각 티켓이 뽑히는 비율이 비슷해지기 때문이다.
Implementation
Ready Queue에 다음과 같이 3개의 Job이 있다고 해보자

1 // counter: used to track if we’ve found the winner yet
2 int counter = 0;
3
4 // winner: use some call to a random number generator to
5 // get a value, between 0 and the total # of tickets
6 int winner = getrandom(0, totaltickets);
7
8 // current: use this to walk through the list of jobs
9 node_t *current = head;
10
11 // loop until the sum of ticket values is > the winner
12 while (current) {
13 counter = counter + current->tickets;
14 if (counter > winner)
15 break; // found the winner
16 current = current->next;
17 }
18 // ’current’ is the winner: schedule it...예를 들어, winning ticket이 80번이라고 해보자.
while문에서 counter 값에 A의 티켓 수를 더하면 counter가 100이다.
winning ticket의 번호가 100보다 작으면, 즉 0~99 사이에 있으면 A가 소유하고 있는 티켓이므로 A가 실행된다.
-
U : Unfairness metric : CPU resource 할당이 fair한가?를 보여주는 지표
first job이 완료된 시간 / second job이 완료된 시간
U가 1에 가까울수록 fair한 scheduler 방식이라고 할 수 있다. -
Example:
A와 B process가 있을 때 둘의 run time은 10ms이다.
A와 B가 FIFO 방식으로 실행되면 U = 0.5이다
반면 A와 B가 RR 방식(time slice=1ms)으로 실행되면 U = 0.95이다.
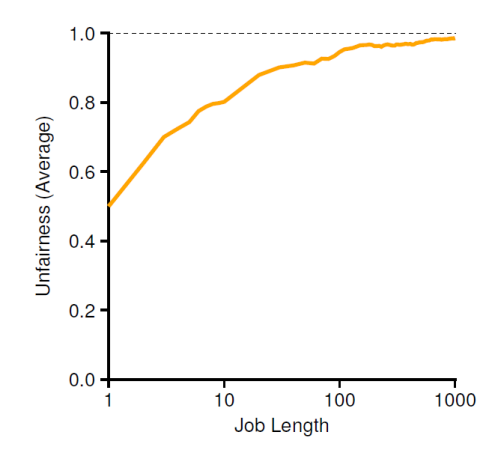
Job length가 클수록 ticket들이 고르게 뽑히기 때문에 unfairness가 1에 가까워진다.
Stride Scheduling
Lottery Scheduling의 Job length에 따른 unfairness를 해결하기 위해 Stride를 사용한다.
Stride = A Large number / process의 ticket 수
Process가 한 번 실행되면 pass value에 stride 값을 더해준다.
pass value가 가장 작은 job을 선택해 실행한다.
pass value는 그동안 얼마나 실행되었는지를 나타내는 지표이다.
current = remove_min(queue); // pick client with minimum pass
schedule(current); // use resource for quantum
current->pass += current->stride; // compute next pass using stride
insert(queue, current); // put back into the queue- Example : Larger number = 10000
A 100 tickets -> stride = 100
B 50 tickets -> stride = 200
C 250 tickets -> stride = 40
Stride Scheduling Example
pass value값이 동일하면 A->B->C 순서로 먼저 실행된다고 가정한다.
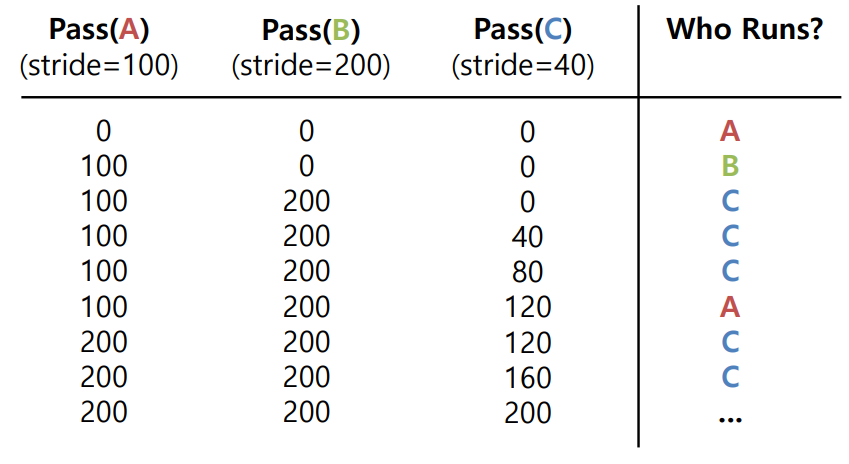
pass value 값이 200으로 동일할 때 각 job이 실행된 횟수는 2:1:5이며 이는 각 job의 가중치 비율과 같다.
위의 상황에서 새로운 Job인 D (stride = 10)가 중간에 추가된다고 생각해보자.
그럼 D의 pass value값은 0에서 시작하기 때문에 한동안 D가 CPU를 독점하는 문제가 생긴다.
따라서 중간에 추가되는 Job의 pass value는 그 상황에서의 pass value의 최솟값으로 초기화 시켜준다.