분기예측, R1CS
배경
현장실습에서 암호학 스터디를 진행하고 있습니다. 스터디를 준비하면서 공부한 내용입니다.
비탈릭 부테린(Vitalik Buterin)의 Quadratic Arithmetic Programs: from Zero to Hero 글을 참고하였습니다.
zk-SNARKs는 영지식 증명의 한 가지 방법입니다. 먼저, zk-SNARKs가 등장하게 된 배경을 살펴보겠습니다.
일반적으로 인터넷에는 증명자(prover)와 검증자(verifier)가 존재합니다. 일반적으로 시스템은 검증자는 신뢰하는 경향이 있습니다. 하지만, 이러한 허점을 이용해 검증자가 악한 행동을 할 수 있습니다. 이런 경우에 대비하여 ZKP(Zero-Knowledge Proof)가 고안되었습니다.
여기서 ZKP는 3가지 조건을 만족해야합니다. 그것은 Completeness, Soundness, Zero-Knowledge의 3가지 성질입니다.
- Completeness: positive true
- Soundness: positive false
- Zero-Knowledge: 조건이 참일 때, 검증자는 조건을 알 수 없다
‘알리바바의 동굴’ 예시와 같은 경우를 반복하면 증명자가 모든 경우에서 올바른 답을 내놓을 확률은 극히 작아지는 원리를 이용합니다. 초기 영지식 증명은 증명자와 검증자 사이의 네트워크 연결, 많은 컴퓨팅 자원이 필요한 해싱 함수 등이 필요했습니다. 하지만, 사람들은 검증의 시작부터 종료까지의 네트워크 연결, 많은 컴퓨팅 자원 소모 등에 불편함을 느꼈습니다.
zk-SNARKs는 이러한 불편함을 해결하여 증명자와 검증자가 네트워크로 연결되어 있을 필요가 없고, 추가로 컴퓨팅 자원 소모도 작은 방법입니다. 이를 위하여 이용자는 옳은(right)한 input을 생성하여 넘겨주어야 합니다. 여기서 옳은 input은 QAP form을 말하고, 자명하지 않은(미지수가 존재하는) 방정식 형태입니다. QAP를 만들기 위해 다음 과정을 거칩니다.
‘Flattening - Gates to R1CS - R1CS to QAP – Checking the QAP’
이번 글에서는 Flattening과 Gates to R1CS 과정을 살펴보겠습니다.
Flattening
복잡한 표현을 포함할 수 있는 Original code를 로직 게이트(logic gate)라고 하는 특정 형식의 문장의 나열로 변환하는 과정입니다.
원래 코드는 두 가지 방정식의 형태 중 하나로 바꿉니다.
1. x =y (y는 변수 혹은 숫자 입니다.)
2. x = y (op) z (op는 사칙연산(+, -, *, /), y&z는 변수, 숫자, 혹은 또다른 expression)
예시)
def qeval(x): y = x**3 x + y + 5↓ flattening
sym_1 = x * x y = sym_1 * x sym_2 = y + x ~out = sym2 + 5
Gates to R1CS
R1CS는 “Rank 1 Constraint System”을 의미합니다. 여기서 Rank 1은 생성되는 행렬(matrix)의 rank가 1임을 말합니다. 그리고 constraint는 로직 게이트를 의미합니다.
우리는 flattening을 통해 얻은 식들을 c = (a) * b의 꼴로 변경해야 합니다.
R1CS는 이렇게 얻은 group of 3 vectors (a, b, c)입니다. 해당 R1CS에 대한 solution은 (s⋅a*s⋅b-s⋅c=0)을 만족하는 s(solution vector) 입니다.
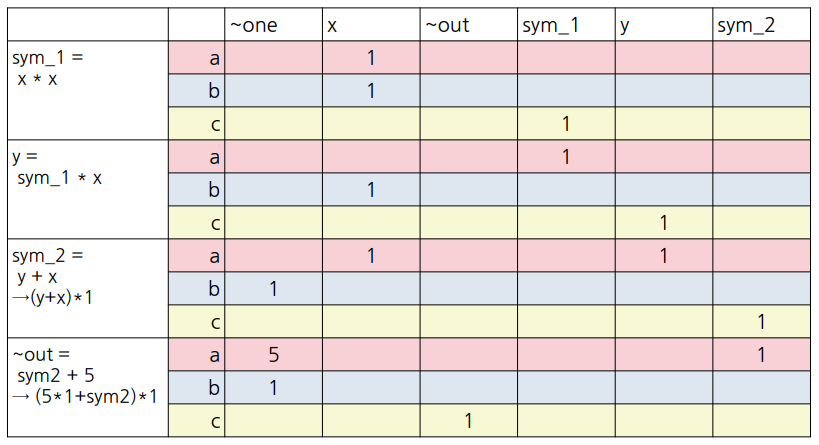
아래 표를 살펴보겠습니다.
두번째 행에서 '~one'은 숫자 '1'을 의미합니다. 표에서 각 변수들이 로직 게이트에 포함된다면 해당 칸에 그 수를 표시합니다. 주의해야할 점으로 네번째 행, 세번째 열을 보시면 sym_2=y+x→(y+x)*1이라는 식을 적어두었습니다. 이것의 의미는 c = (a) * b의 꼴로 변경해야하니, y+x를 (y+x)*1로 본다는 의미입니다. 다섯번째 행, 네번째 열의 ~out=sym2+5→(5*1+sym2)*1도 동일한 방법입니다.
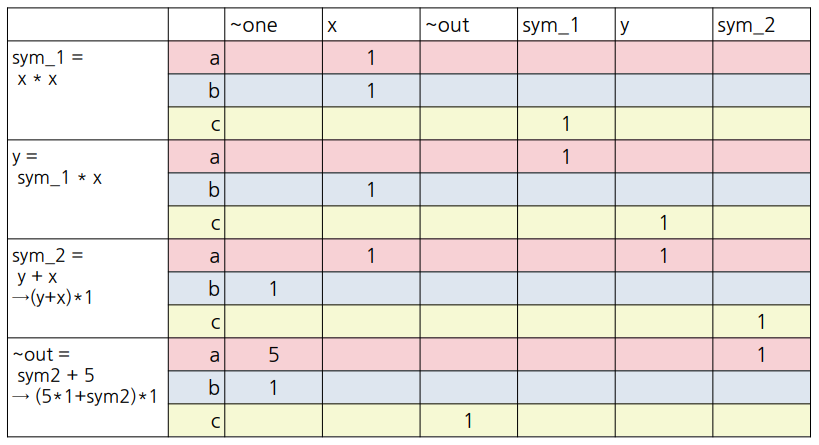
위의 표에서 a 벡터는 빨갛게, b 벡터는 파랗게, c 벡터는 노랗게 색칠해두었습니다. 이를 모으면 아래와 같은 행렬을 만들 수 있습니다.
A =
[0, 1, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0]
[0, 1, 0, 0, 1, 0]
[5, 0, 0, 0, 0, 1]
B =
[0, 1, 0, 0, 0, 0]
[0, 1, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
C =
[0, 0, 0, 1, 0, 0]
[0, 0, 0, 0, 1, 0]
[0, 0, 0, 0, 0, 1]
[0, 0, 1, 0, 0, 0]
우리가 찾는 solution vector는 [~one, x, ~out, sym_1, y, sym_2]에 대응하는 값들로 이루어진
s = [1, 3, 35, 9, 27, 30]
입니다.
따라서 우리가 찾는 R1CS를 이루는 a,b,c 벡터들의 group(A, B, C matrix)와 solution vecotr인 s를 구했습니다. 다음 글에서는 'R1CS to QAP – Checking the QAP'를 살펴보도록 하겠습니다.
번외

비탈리 부테린의 블로그에서 if문 등 조건문이 큰 오버헤드를 발생시킬 수 있다고 적혀있습니다. 이 이유에 대해 적어볼까 합니다. 현대 cpu는 고성능을 위해 연산이 pipeline화하여 실행합니다. 비록 다양한 분기예측 기술들이 있지만, 위와 같은 조건문은 반복의 경우도 아니기 때문에 예측 성공률이 높지 않을 것입니다. 예측에 실패하면 진행중인 pipeline execution들을(IF, ID, EX, MEM, WB) 초기화해야하고, 추가로 pipeline stall이 발생합니다. 따라서 조건문은 성능에 큰 장애물이 될 수 있습니다.
