네트워크 계층에서 매우 중요한 파트는 바로 패킷을 어느 경로로 보낼지를 결정하는 라우팅 알고리즘이다. 라우팅 알고리즘은 목적지까지 비용이 가장 적은 경로를 구하는 것이 목적이며, 이를 위해 라우터들과 링크들을 그래프 형태로 생각하면 편하다. 다음 그림처럼 그래프 G=(N,E)는 N개의 노드와 E개의 엣지의 집합으로 정의할 때, 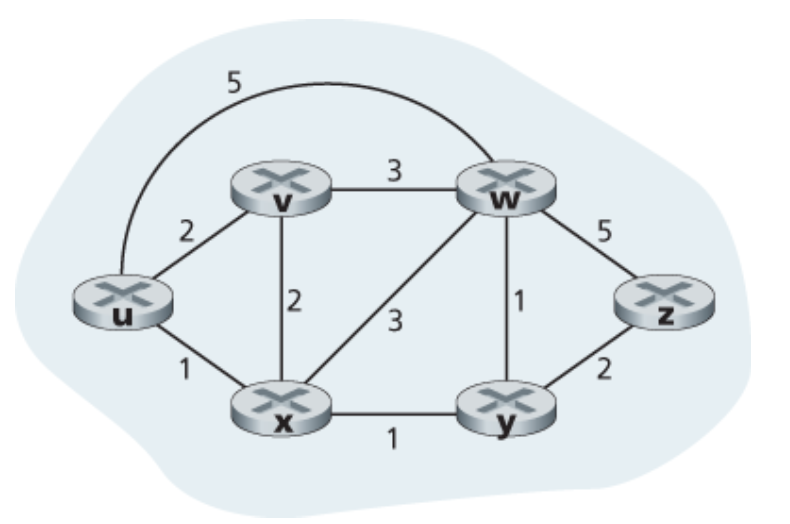
- 노드 = 라우터 (패킷을 어디로 forwarding할지 결정하는 포인트)
- 엣지 = 라우터를 연결하는 물리적 링크
로 생각할 수 있다. 이때, 엣지마다 비용이 있는데, 이 비용은 링크의 물리적 길이, 속도, 비용과 관련되어있다. 결국 라우팅 알고리즘은 출발지부터 목적지까지 연결된 간선 경로 중 비용의 합이 최소인 경로를 찾고자 하는 것이다. Least-cost 경로를 구하는 데 있어 두 가지 접근법이 있다.
1.centralized routing algorithm:
- 네트워크에 있는 모든 라우터들에 대한 topology를 알고 있는 경우
- 흔히 link state algorithm라고도 부름
- link state이라 하는 이유는 모든 라우터들이 연결된 링크들을 서로에게 broadcast해야 하기 때문
- 현실적으로 전세계 모든 노드들에게 Broadcast하는 것은 불가능하기 때문에, 이 알고리즘은 한 네트워크 내로 한정되었을 경우에만 사용됨
- decentralized routing algorithm:
- 물리적으로 연결된 이웃 라우터들에 대해서만 아는 겅우
- 대표적인 예시로 distance vector algorithm이 있다.
5.2.1 The Link-State (LS) Routing Algorithm
이 알고리즘은 위에서 언급한 것과 같이 모든 노드가 네트워크 topology와 모든 링크의 비용을 모두 알고 있다는 것을 전제로 한다. 모든 노드가 이런 정보를 다 알 수 있는 이유는 link-sate broadcast algorithm을 통해 노드들이 서로에게 정보를 broadcast하기 떄문이다. 정보를 모두 받은 각 노드는 개별적으로 LS algorithm을 돌려 동일한 least-cost 경로를 계산할 수 있게 된다. LS algorithm의 예시로는 다익스트라 알고리즘, 프림 알고리즘 등이 있다. 알고리즘으로 least-cost 경로를 구했다면, 라우터는 그것을 바탕으로 forwarding table 생성한다. Forwading table은 목적지와 링크가 매핑되어 있는 테이블로, 라우터는 도착한 패킷의 헤더를 통해 목적지를 파악하고, 해당 목적지로 효율적으로 가기 위해 forwarding 되야하는 링크로 패킷을 보내게 된다.
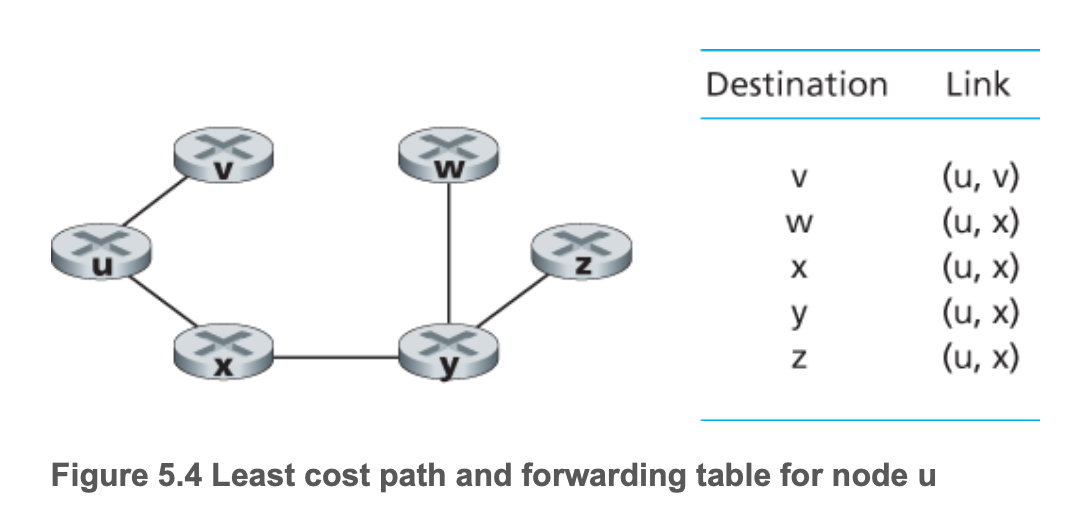
가령, 라우터 u는 위와 같은 forwarding table을 가지게 된다. 목적지 y를 예시로 들면, u -> x -> y가 least-cost path이기 때문에 목적지 y는 (u, x) 링크와 매핑되어 있는 것이다.
5.2.2 The Distance-Vector (DV) Routing Algorithm
이 알고리즘은 LS 알고리즘과 달리 반복적이고 비동기적이며 분산되어 있다. 각 노드는 직접 연결된 이웃 노드 중 하나 이상으로부터 일부 정보를 받아 계산을 수행한 다음 계산 결과를 다시 이웃 노드에게 전달한다. 이 과정은 더 이상 이웃 간에 정보가 교환되지 않을 때까지 계속되다가 자체 종료한다. 이 알고리즘은 모든 노드가 서로 동기화하여 작동할 필요가 없으므로 비동기적이다.
DV 알고리즘은 벨만포드 알고리즘으로 구현된다.

이 알고리즘 또한 least-cost path를 구해 forwarding table을 생성하게 된다. 아래 예시는 위 알고리즘의 loop을 시각적으로 보여주고 있다.
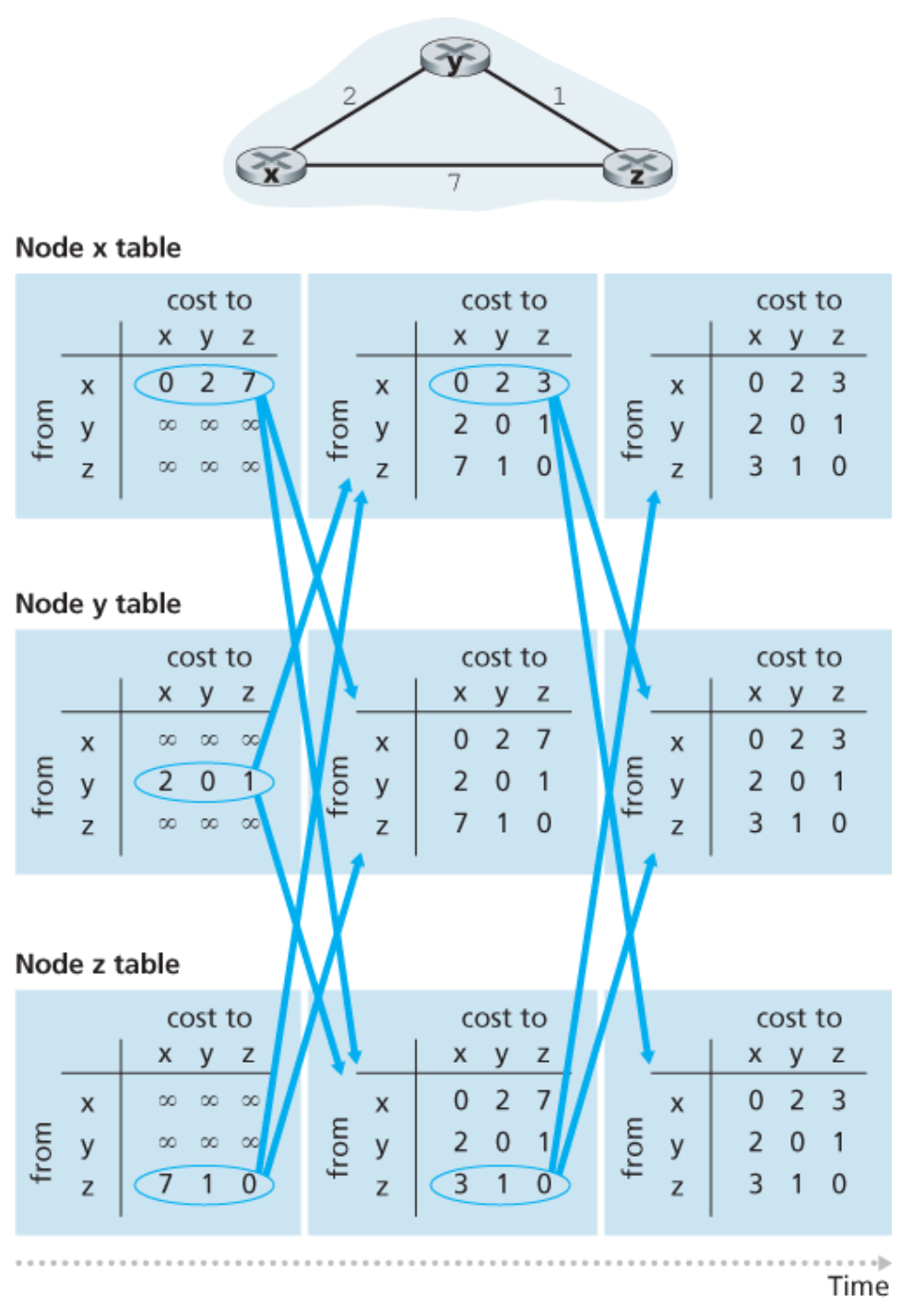
문제) Count-to-infinity problem
이 알고리즘은 변화가 없으면 정지 상태에 놓이고, 다음 변화가 발생할 때까지 기다리게 된다. 즉, least-cost path를 구한 이후, 링크 비용이 변화한다면 다시 알고리즘이 작동하기 시작한다는 것이다. 그러나 링크 비용이 변화하여 forwarding table을 업데이트할 때, 잘못 업데이트될 수 있다. 변화한 내용과 이웃 정보만 알고 있는 라우터는 제한된 정보로 인해 네트워크 전체를 알아야만 알 수 있는 정보를 알 수 없는 경우가 발생한다. 이로 인해 routing loop이 발생할 수 있다. 이는 패킷이 두 개의 라우터를 여러 번 왔다갔다하는 상황을 일컫는다. 링크 비용이 크게 증가할수록 왔다갔다하는 횟수가 기하급수적으로 늘며, 그렇기에 이런 문제상황을 count-to-infinity problem으로도 부른다.
