RDS (Relational Database Service)는 AWS가 관리해주며 SQL을 사용하는 클라우드 DB이다. 이는 AWS가 관리해주는 DB라는 측면에서 다양한 장점이 있어 EC2에서 직접 DB를 배포하는 것보다 선호되는 방식이다.
특징 및 장점 *
- automated provisioning, OS patching
- provisioned RDS instance size and ebs volume type & size
- continous backups and restore to specific timestamp (point in time restore)(up to 35 days)
- monitoring dashboards
- read replicas for improved read performance
- multi AZ setup for DR (disaster recovery)
- maintenance windows for upgrades
- scaling capability (vertical and horizontal)
- storage backed by DBS (gp2 or io1)
- security through IAM, Security groups, KMS(key management service), SSL in transit
- Manual DB snapshot for longer-term recovery
- managed and scheduled maintenance(with downtime)
- support for IAM Authentication, integration with Secrets manager
- RDS Custom for access to and customize the underlying instance (Oracle & SQL server)
단점
- RDS는 SSH로 접근할 수 없다는 단점을 가지고 있다.
Storage Auto Scaling
RDS는 스토리지를 동적으로 늘릴 수 있는 storage auto scaling 기능을 가지고 있다. 이는 RDS가 스토리지가 점점 부족하다는 것을 인지하면 스토리지 양을 자동적으로 늘리는 기능이다.
- 이 기능을 통해 데이터베이스 스토리지를 수동으로 조절할 필요가 없다는 장점이 있다.
- Maximum Storage Threshold (maximum limit for DB storage)을 설정할 수 있다.
- 다음 조건을 만족할 시 자동적으로 스토리지를 조정한다
- free storage is less than 10% of allocated storage
- low-storage lasts at least 5 minutes
- 6 hours have passed since last modification
- Unpredictable workload를 가지는 어플리케이션에 적합한 기능
- 모든 RDS 데이터베이스를 지원한다
RDS Read Replicas vs Multi AZ
RDS Read Replicas (for read scalability)
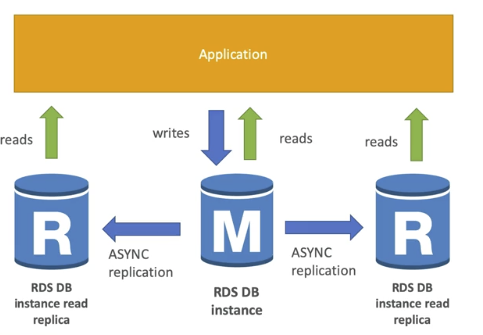
RDS Read Replica는 read를 더욱 많이 할 수 있도록 데이터베이스를 복제하는 기능이다. 기존 데이터베이스 read 요청이 너무 많으면, 이를 해결하기 위해 데이터베이스 복제를 생성하여 read 요청을 분배할 수 있다. 이때, 데이버베이스 복제인 RDS Read Replica에 write를 할 수 없다.
특징
- 최대 15 Read Replica 생성 가능
- within AZ, cross AZ, cross region 모두 가능
- 복제는 비동기적으로 이루어지기 때문에 결과적으로 read 결과는 모두 일관성있다.
- replica는 자기 자신만의 데이터베이스로 변경 가능
- read replica를 관리하기 위해선 어플리케이션들이 connection string을 업데이트해야한다.
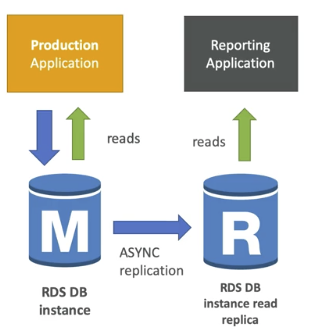
Use case
: 분석을 위한 reporting application을 기존 어플리케이션에 적용하고자 할 경우
- 만약 reporting application을 production database를 사용한다면, 그 데이터베이스는 너무 많은 read 요청으로 인해 성능이 떨어질 수 있다
- 그래서 read replica를 생성하고, reporting application은 그 복제 데이터베이스만을 활용한다면 해결할 수 있다
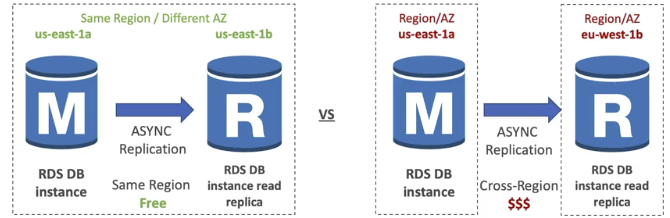
Network Cost
원래는 데이터를 다른 AZ로 전송할 시 비용이 발생한다. 그러나 RDS Read Replica에 있어선 같은 region이면 비용이 발생하지 않는다. 단, region이 데이터가 다른 곳으로 보내질 시 비용이 발생한다.
RDS Multi AZ (for Disaster Recovery)
이 기능은 master DB에 문제가 생겼을 때를 대비하기 위한 기능으로, 만약 DB에 문제 생기면 standby DB를 사용할 수 있도록 한다. 이는 scaling을 위해 사용하는 기능이 아니고 disaster recovery를 위한 것이다. 이때, Read replica는 multi AZ로 설정될 수 있다.
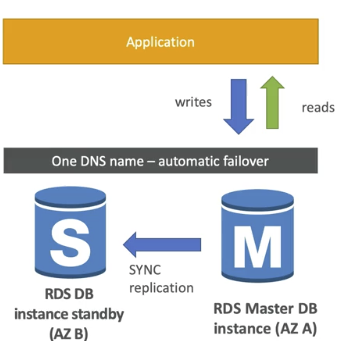
작동 방식
- Primary 인스턴스: 주 데이터베이스 인스턴스가 운영된다. (read & write)
- Standby 인스턴스: 다른 가용 영역(AZ)에 복제본이 자동으로 생성되고 동기화된다. 이때, Standby instance는 동기적으로 업데이트된다. (read only, write X)
- 자동 장애 조치: 주 인스턴스에 장애가 발생하면 자동으로 대기 인스턴스로 장애 조치된다. 즉, RDS Multi-AZ 배포에서 장애 조치(Failover)가 발생하면 Standby Instance가 Primary Instance로 승격됩니다. 이 경우, 승격된 인스턴스는 이제 새로운 주 인스턴스가 되어 쓰기 작업을 포함한 모든 데이터베이스 작업을 처리할 수 있습니다.
장점
- increase availability: 데이터베이스의 가용성을 높여 장애 발생 시에도 빠르게 복구됩니다.
- 자동 백업: 백업이 자동으로 수행되며, 유지 관리가 간편하다.
single-AZ RDS를 multi-AZ로 바꾸는 방법
- 이 작업은 zero downtime operation이다. 즉, DB를 멈출 필요가 없는 작업이라는 것이다
- 그저 데이터베이스의 'modify' 버튼을 누르기만 하면 실행된다
- 내부적으로 이루어지는 작업:
- DB에 대한 snapshot을 찍음
- 그 snapshot을 이용해 새로운 DB가 새로운 AZ에 생성된다
- 이 이후, 두 데이터베이스 간에 동기화 작업이 시작된다
비교
| 특징 | Multi-AZ | Read Replicas |
|---|---|---|
| 목적 | disaster recovery | 성능 향상 및 read scalability |
| 복제 방식 | 동기식 | 비동기식 |
| 장애 조치 | 자동 장애 조치 | 장애 조치 없음 |
| 쓰기 작업 | 주 인스턴스에서만 수행 | 주 인스턴스에서만 수행 |
| 읽기 작업 | 주 인스턴스 또는 대기 인스턴스에서 수행 | 각 리드 레플리카에서 독립적으로 수행 |
| 사용 사례 | 프로덕션 워크로드, 중요한 데이터베이스 | 읽기 집중 애플리케이션, 리포팅 및 분석 |
RDS Custom
RDS는 AWS가 관리해주는 클라우드 데이터베이스이기 때문에 원래는 해당 데이터베이스를 배포한 EC2 instance와 해당 OS에 접근을 못한다. 그러나 RDS Custom을 이용해 instance와 OS에 접근할 수 있으며, 둘에 대한 접근을 이용해
- configure settings
- install patches
- enable native features
- access the underlying EC2 instance using SSH or SSM Session Manager
와 같은 기능을 수행할 수 있다. 단, RDS Custom은 Oracle과 Microsoft SQL server database에만 적용가능하며, 만약 사용한다면 automation mode를 끄고 DB snapshot을 찍은 이후에 customization을 수행하는 것이 권장된다.
RDS vs RDS Custom
- RDS: entire database and the OS to be managed by AWS
- RDS Custom: full admin access to the underlying OS and the database
Amazon Aurora
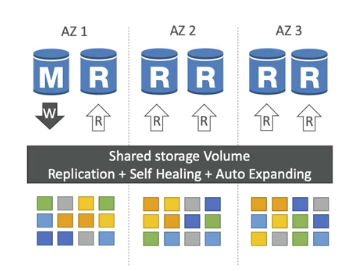
Amazon Aurora는 AWS에서 제공하는 고성능 관계형 데이터베이스 서비스이다. Aurora는 MySQL과 PostgreSQL과 호환되며(=해당 데이터베이스로 활용가능함), 이들 데이터베이스의 성능과 가용성을 크게 향상시킨다. 특징은 다음과 같다
- 고성능
- Amazon Aurora는 표준 MySQL 데이터베이스보다 최대 5배, 표준 PostgreSQL 데이터베이스보다 최대 3배 빠른 성능을 제공한다
- 확장성
- 최대 15개의 read replica를 추가할 수 있으며, 복제 작업이 MySQL보다 빠르다
- cross region replication 지원 (cluster of DB instances across multiple AZ)
- 자동 스케일링(auto scaling): 필요에 따라 스토리지 용량을 자동으로 확장할 수 있다. 스토리지는 10GB ~ 128TB씩 자동적으로 늘릴 수 있다
- high availability
- 자동 장애 조치: 장애가 발생하면 복구가 거의 바로 이루어진다 (30초 이내)
- 복제: Aurora는 기본적으로 6개의 복제본을 3개의 AZ에 분산시켜 데이터를 저장한다. 이러한 복제 구조는 고가용성과 데이터 손실 방지 기능을 제공한다
- 4 copies out of 6 needed for writes
- 3 copies out of 6 need for reads
- self healing with peer-to-peer replication
- storage is striped across 100s of volumes
- 자체 치유 스토리지(Recovery): 손상된 블록은 자동으로 감지되고 복구됩니다.
- Isolation and security
- 네트워크 격리: Amazon VPC(Virtual Private Cloud)를 사용하여 데이터베이스를 격리하고 보안 그룹으로 접근을 제어할 수 있다
- 암호화: 저장 중인 데이터와 전송 중인 데이터를 암호화할 수 있다
- industry compliance
- automated patching with zero downtime
- advanced monitoring
- routing maintenance
- push-button scaling
- backtrack
- restore data at any point of time without using backups
- 비쌈
- RDS보다 20% 더 비싸다
- 한 aurora instnace만 write할 수 있다 (master instance)
Aurora Serverless
- for unpredictable/intermittent workloads
- no capacity planning
Aurora Global *
- up to 16DB read instances in each region
- less than 1 sec storage replication
- if there's a problem in primary region, can promote secondary region to become new primary
Aurora Machine Learning
- perform machine learning using SageMaker & Comprehend on Aurora
Aurora Database Cloning
- new cluster from existing one
- faster than restoring a snapshot
- use case: want to use testing/staging database out of your production database
Reader Endpoint
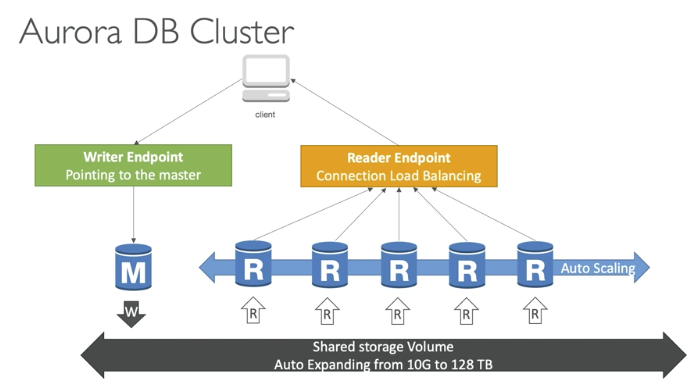
Reader Endpoint는 여러 개의 read replica를 가진 DB 클러스터에서 읽기 요청을 자동으로 분산시키기 위해 사용되는 엔드포인트이다. 이를 통해 애플리케이션이 직접 개별 읽기 복제본을 관리할 필요 없이, 읽기 성능을 확장하고 로드를 분산시킬 수 있다.
장점
- 읽기 성능 확장
- Aurora 클러스터는 여러 read replica를 가질 수 있다. Reader Endpoint는 이들 복제본에 대한 읽기 요청을 자동으로 분산하여 읽기 처리 성능을 확장한다.
- 간소화된 연결 관리
- 애플리케이션은 Reader Endpoint에만 연결하면 되므로, 각 읽기 복제본의 변경이나 추가에 대해 신경 쓸 필요가 없다.
- 새로운 읽기 복제본이 추가되거나 제거될 때도 애플리케이션 코드 변경 없이 자동으로 적용된다.
- 높은 가용성
- 특정 읽기 복제본에 문제가 발생해도 Reader Endpoint는 자동으로 다른 가용한 복제본으로 요청을 분산시킨다.
