사담
Heterogeneous system에서의 DAG task scheduling 알고리즘을 찾다가 Shinpei Kato의 HLBS로부터 찾아가며 알게된 알고리즘들이다. Reference에 보면 그 외에 더 많은 알고리즘이 있지만 어쨌든 HLBS가 해당 알고리즘보다 좋다는게 입증되었기에 마지막에 나온 것이 아닐까 싶어서 모두 보지는 않았다. 근데 최근 RTSS 2020에서 HLBS를 Reference한 논문이 등재되어 이는 시간이 날 때 리뷰할 예정이다. RTSS 2020의 논문을 포함한 소개할 알고리즘들은 각 task을 한 번만 실행한다고 가정하고 time table을 더 효율적으로 만드는 법에 대해 소개하는데, periodic한 모델에 대해서는 직관적으로 optimal하다고 보기가 어려울 것 같다. periodic DAG task에 대해서 스케줄링하는 알고리즘 논문을 찾고 싶은데 아직은 못 찾은 상태다.
Intro
세상에 많은 스케줄링 알고리즘이 있지만 Real-time System에 대해서는 단순히 CPU의 idle한 시간을 줄이는 것 뿐만 아니라 각 task에 대해 deadline miss가 일어나지 않도록 하는 constraint가 지켜져야 한다. single-core (uni-processor) 상황에서는 EDF(Earliest Deadline First), RM (Rate Monotonic), LST (Least Slack Time) 알고리즘 등이 알려져 있으나, Multi-core 상황에서는 얘기가 더 복잡해진다. 이 글에서 소개할 세 개의 알고리즘은 그 중에서도 각 core마다 execution time 등이 다른 heterogeneous한 상황에서의 스케줄링 알고리즘에 대한 내용이다. DAG task가 주어졌을 때 각 task들을 돌리는 time table을 output으로 만든다. 이 table을 반복하여 스케줄링하겠다는 Offline Scheduling의 일종인 Clock-driven scheduling을 사용할 수 있다. Multi-core 상황에서의 optimal한 스케줄링 방법을 구하는 것은 NP-Complete라고 알려져 있기 때문에 수학적으로 어떤 알고리즘이 optimal이라고는 말할 수 없다. 따라서 세 알고리즘은 각자의 heuristic을 이용하여 이전의 알고리즘보다는 성능 개선을 보였다고 주장한다.
Contribution
1. HEFT (Heterogeneous Earliest Finish Time)
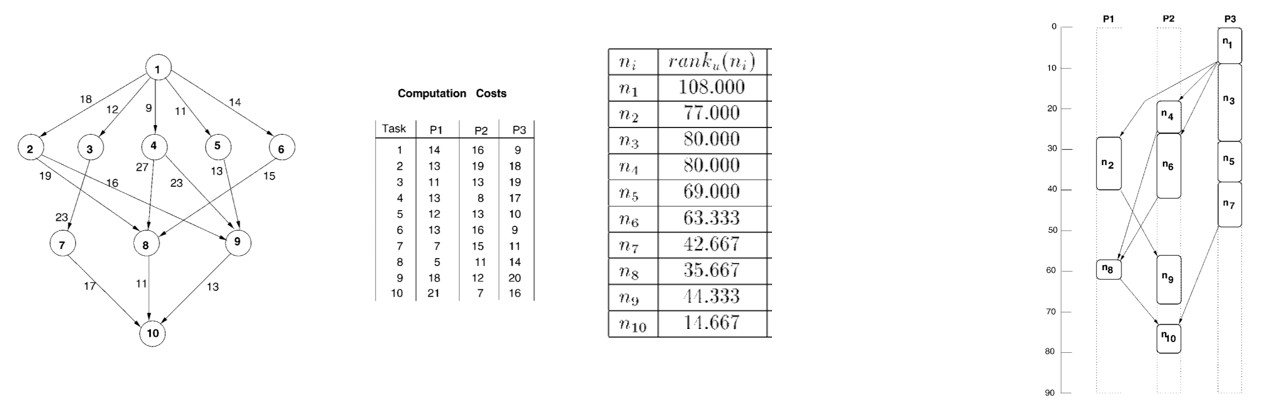
DAG task에 대해 time table을 만드는 task 스케줄링 알고리즘을 시간 복잡도 으로 수행하는 알고리즘을 구현하였다.
2. CPOP (Critical Path On a Processor)
마찬가지로 시간 복잡도 으로 스케줄링한다. CPOP은 HEFT와 다르게 Critical Path를 중요시한다.
3. HLBS (Heterogeneous Laxity-Based Scheduling)
HEFT, CPOP 알고리즘과 같은 시간복잡도로 deadline miss를 줄이는 알고리즘을 구현하였다.
System Model
Heteregeneous System이라고 하더라도 system model을 어떻게 구상하느냐에 따라 알고리즘도, 성능도 확연히 달라진다. 특히 DAG를 다루는 System Model의 경우에는 communication cost를 어떻게 처리할 지도 중요한 문제다. Real-time System을 위한 논문들은 주로 task의 소단위인 job이 periodic하게 반복되는 경우에 대해 다루지만, 이 논문들은 task가 한번 실행되고 끝난다. 그 외의 System Model의 특징은 다음과 같다.
- Non-preemptive
- No intra-processor communication cost
- Same arrival time (synchronized system)
- No duplication
각 task가 한 번 실행되고 끝나고 arrival time이 모두 0초라고 가정하기 때문에 preemption이 의미가 없다. 또한 DAG 상에서 부모자식 관계인 두 task에 대해 자식 노드가 부모 노드와 같은 processor에서 실행되는 경우에는 communication cost가 없다고 가정한다. 이는 다른 프로세서에서 실행하기 위해 부모 노드에서 도출된 결과값을 다른 프로세서에서 load하는 과정에서 생긴다고 추측은 하지만, 논문에서 자세히 언급한 바는 없다. 여담으로 HLBS를 차용한 Shinpei Kato의 논문인 ROSCH에서는 HLBS에 duplication을 고려한 exHLBS에 대해서도 그림으로 소개는 한다.
Basic Structure
세 알고리즘이 이름은 다르지만 아래 두 개의 Phase를 가진다는 점에서 모두 같은 구조를 취한다. (그래서 논문을 이어서 읽기가 쉬웠다.) 또한 static priority 방식으로 Task Prioritize Phase에서 정한 우선도는 이후에 바뀌지 않는다.
- Task Prioritize Phase : 나름의 metric을 통해 task 간의 우선순위를 정한다.
- Processor Selection Phase : Insertion-Based Policy를 바탕으로 우선순위가 높은 task부터 적절한 프로세서에 할당한다.
Metric for Prioritize

HEFT와 CPOP은 위 식에 있는 , 를 이용해서 우선도를 계산하는데 직관적으로는 는 critical path의 entry task를, 는 critical path의 end node를 의미한다.

HLBS의 경우에는 위 식과 같은 laxity를 이용한다. laxity의 직관적인 의미는 해당 task가 적어도 laxity 전에는 release(task의 시작 시간이 laxity보다 짧아야 함)되어야 한다는 의미다.
laxity는 일반적으로 Real-time task에서 통용되는 slack과 유사한 개념이나 현재 시간에 따라 그 값이 달라지는 slack과 다르게 처음에 계산된 값으로 고정된다는 특징을 가진다. 일반적으로 laxity를 위의 의미로 사용하지는 않는다고 한다는 점에 유념하자.
세 metric 모두 평균 execution time을 사용하는데, 이는 시간복잡도를 줄이기 위함으로 생각된다. 스케줄링은 OS의 핵심 기능이자 항상 실행되는 코드이기 때문에 일반적으로 스케줄링 알고리즘에 소요되는 시간은 짧을 수록 좋다. 이런 점에 의거하여 알고리즘을 더 복잡하게 짜지는 않은 듯 하지만, 반대로 이 때문에 optimal한 time table과 편차가 생기게 된다. 간단한 예시로 DAG가 복잡해졌을 때 entry task의 laxity가 음수가 나오기도 하는데 그럼에도 불구하고 deadline miss가 발생하지 않기도 한다.
Insertion Based Policy

세 알고리즘 모두 기본적인 프로세서 할당 정책은 Insertion Based Policy다. Insertion Based Policy라는 말은 단순히 이미 배정된 두 job 사이에 idle한 time slot이 있어 해당 slot에 새로운 task를 배정할 수 있다면 배정하여 넣겠다는 의미다.
하지만 이는 단순히 idle time을 줄이기 위한 하나의 정책일 뿐이고 실제 할당은 EFT (Early Finish Time)이 가장 짧게 되는 processor에 할당한다. 물론 precedence가 존재하는 DAG task이기 때문에 당연히 부모 task가 끝난 이후에 실행되어야 한다는 constraint가 존재한다. 또한 System Model에서 언급했듯이 자식 task가 부모 task와 다른 프로세서에서 실행될 때에만 communication cost가 발생한다. 위 그림에서 T3이 할당된 P2에 T4를 할당하는 것이 가장 EFT가 짧을 것 같으나 실제로는 communication cost가 존재하기 때문에 부모 task인 T1이 실행된 P3에 연속하여 할당하는 것이 더 EFT를 짧게 할 수 있다.
Algorithm Description
HEFT (Heterogeneous Earliest Finish Time)
가 높은 순으로 task를 뽑아서 EFT가 가장 작게 되는 프로세서에 할당한다.
CPOP (Critical Path On a Processor)
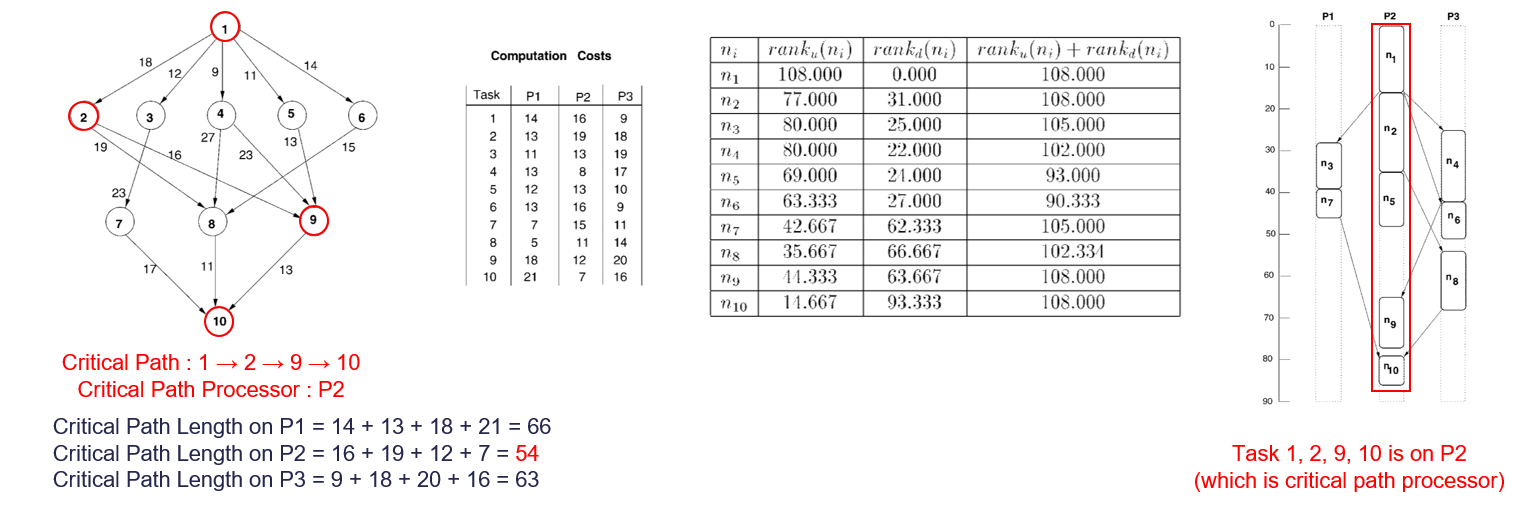
CPOP의 경우 Critical Path를 구하는 과정이 추가된다. Critical Path를 구하는 과정은 다음과 같다.
1. entry task를 critical path에 추가하고 selected task로 정한다.
2. selected task의 자식 task 중 + 가 가장 큰 task를 critical path에 추가하고 selected task로 정한다.
3. end task가 critical path에 추가될 때까지 2를 반복한다.
이후 critical path에 있는 노드들이 serial하게 실행된다고 했을 때 가장 시간이 짧게 걸리는 processor를 Critical Path Processor로 선택한다.
CPOP은 프로세서 할당이 HEFT와 약간 다른데, 가 큰 순으로 task를 뽑되, 해당 task가 critical path 상에 있는 경우 무조건 Critical Path Processor에 할당한다.
critical path 상에 있지 않은 경우는 HEFT와 동일하게 EFT가 짧게 되는 프로세서에 할당한다.
HLBS (Heterogeneous Laxity-Based Scheduling)
laxity가 작은 순으로 뽑아서 EFT가 가장 작게 되는 프로세서에 할당한다.
HEFT와 매우 유사하나 task의 우선도만 laxity로 정하는 것 뿐이다.
random task에 의한 실험 결과를 보면 deadline miss는 확실히 줄어드는데, 대신 스케줄의 길이인 makespan (일반적으로는 workspan이라는 용어를 사용한다고 한다.)에서는 손해를 본다.
HLBS는 random task를 만들기 위해 TGFF (Task Graph For Free)라는 오픈 소스 프로그램을 사용하였다. 여담으로 나도 이 프로그램을 사용해서 실험하려 했으나 너무 옛날 프로그램이라 parameter 설정이 자유롭게 되지 않는 듯 하여 내가 DAG Generator를 직접 만들었는데 이는 추후에 소개하겠다.
Example
아래 그림들은 세 알고리즘을 실제로 적용하여 나오는 time table이다.
HEFT Example
CPOP Example
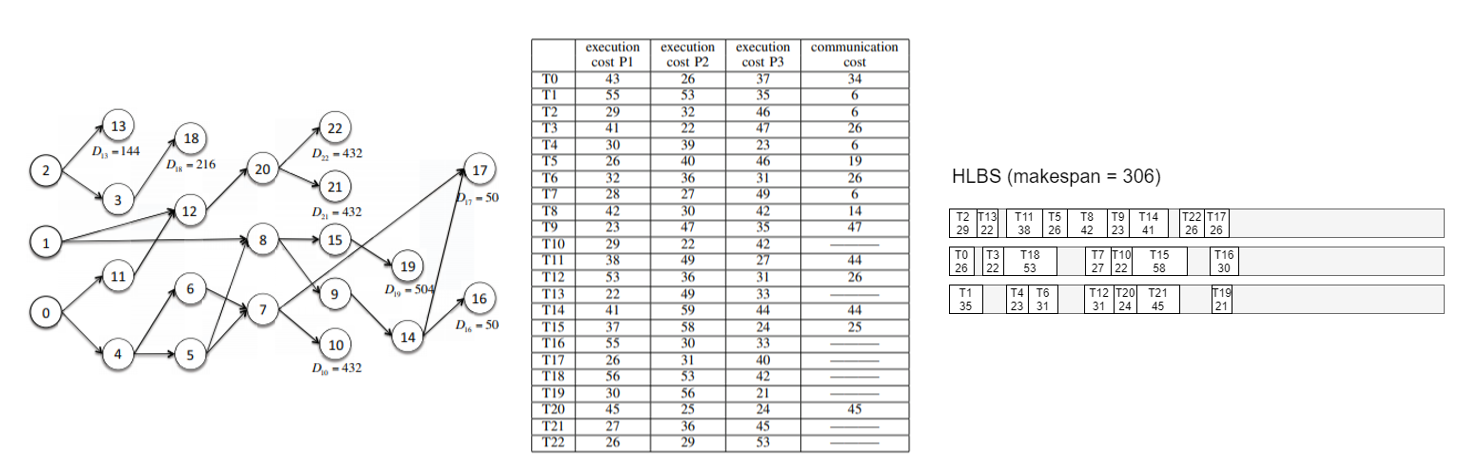
HLBS Example
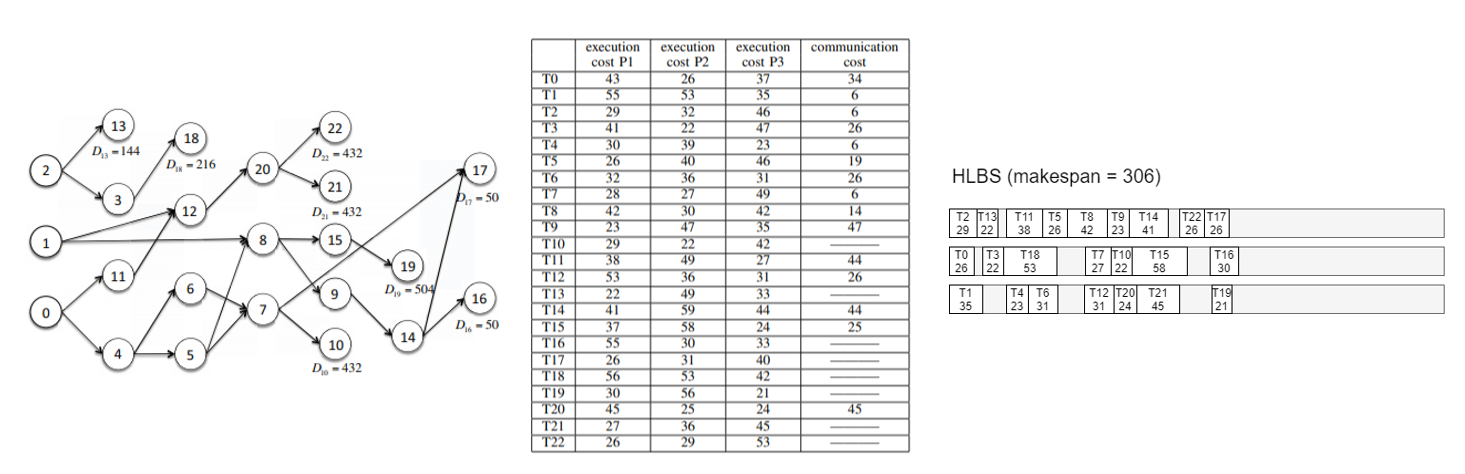
HLBS는 논문에서 제시한 예시가 계산해보니 틀린 것 같아 내가 다시 계산했다..
Ref
-
Y. Suzuki, T. Azumi, N. Nishio, and S. Kato, “HLBS: Heterogeneous laxity-based scheduling algorithm for DAG-Based real-time computing,” in Proc. of 2016 IEEE 4th International Conference on Cyber-Physical Systems, Networks, and Applications (CPSNA), pp. 83–88, 2016.
-
H. Topcuoglu, S. Hariri and Min-You Wu, "Performance-effective and low-complexity task scheduling for heterogeneous computing," in IEEE Transactions on Parallel and Distributed Systems, vol. 13, no. 3, pp. 260-274, 2002.
