Scheduling Approach의 분류
Task와 resource model을 정의했다면 이제 남은 것은 해당 자원을 task에 어떻게 배분할 것인가, 즉 task를 어떻게 스케줄링할 것인가를 결정해야 한다.
스케줄링하는 방법을 분류하자면 먼저 어느 phase에서 하는지에 따라 아래처럼 분류할 수 있다. 지난 글에서도 간단히 언급한 바 있다.
- Off-line Scheduling : design phase에서 스케줄을 정하고 runtime에서는 정해진 스케줄표대로 task에 자원을 할당하는 것을 단순 반복한다. task가 dynamic하게 생기거나 없어지는 것을 고려하지 않는다.
- On-line Scheduling : runtime에 기준에 따라 스케줄할 task를 결정한다. task가 dynamic하게 생기거나 없어져도 스케줄 가능하다.
- Clairvoyant Scheduling : job들이 언제 release되는지를 알고 스케줄링한다. 미리 스케줄링하는 셈이기는 하니 off-line scheduling과도 유사한 것 같지만, off-line scheduling은 어떤 job이 있는지만 알고 release time이나 execution time 등은 모른다는 점이 다른 것이 아닐까 싶다.
스케줄링 방법을 분류하자면 preemption 여부 등에 따라 나눌 수도 있다.
On-line scheduling은 성능이 좋은가?
연구에 따르면 online scheduler로는 clairvoyant 알고리즘으로 feasible한 스케줄의 25%만 스케줄 가능하다고 하다. 따라서 성능이 썩 좋지만은 않다.
하지만 대부분의 hard real-time system에서는 periodic task를 사용하기 때문에 clairvoyant하다고 생각할 수 있다.
Clock Driven Approach, RR(Round Robin)
아주 단순한 스케줄링 방법으로는 clock driven approach가 있다. off-line scheduling 방법으로 시간표를 짜놓고 정해진 task를 실행하게 하는 것이다. 초등학교 때 짰던 방학 계획표를 생각해보면 이해가 빠르다. 하지만 다른 점은 사람은 계획표를 지키지 않지만, 기계는 정해진대로 한다는 것이다.
주기적으로 실행하는 것은 유사하지만 on-line scheduling인 것이 RR(Round Robin) 기법이다. 실행될 수 있는 task는 기본적으로 ready queue에 있는데, ready queue에 있는 job들에게 돌아가면서 token (일정 시간)을 할당하는 것이다. clock driven approach와 다른 것은 새로운 job이 ready queue에 들어오거나 수행을 마친 job에 대해서도 처리할 수 있다는 것이다. 이 때 모든 job들에게 동일한 시간을 부여하는 것을 RR이라 하고, 가중치를 두고 부여하는 것을 WRR(Weighted Round Robin) 방법이라고 한다.
WRR의 예시는 아래와 같다.
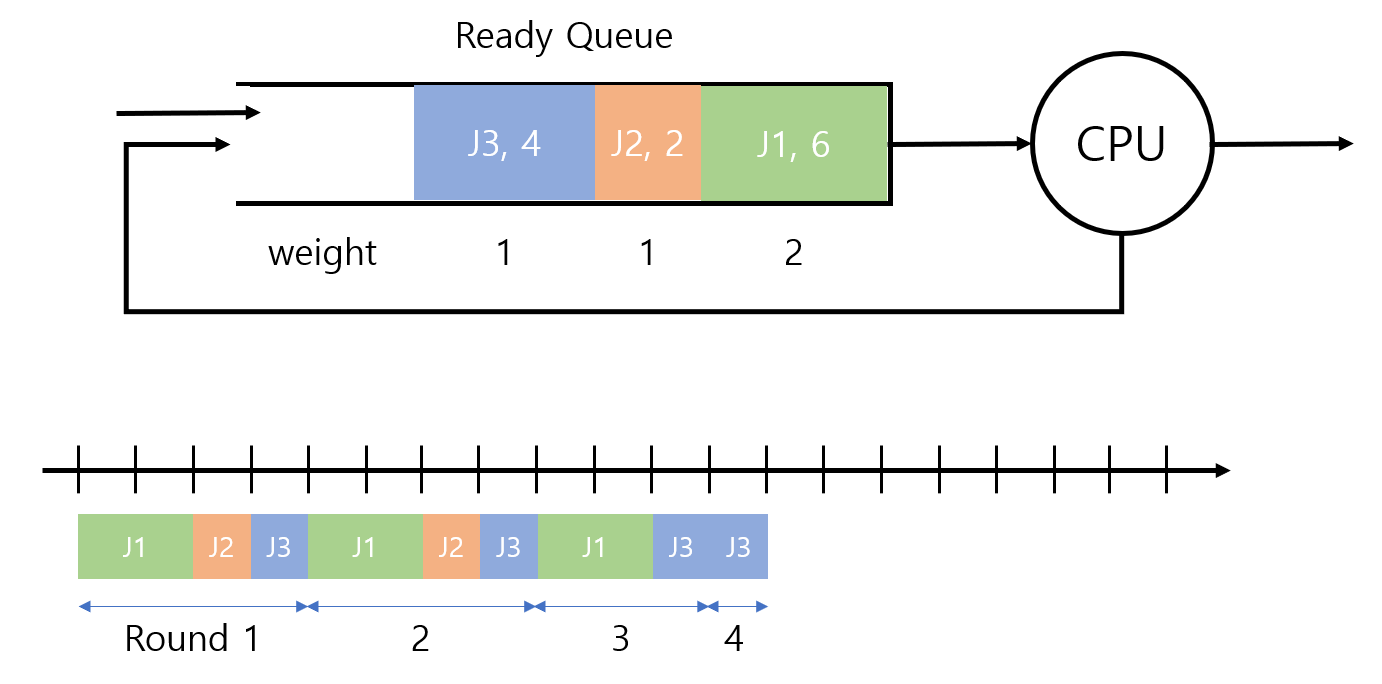
세 개의 job J1, J2, J3에 대해, 실행 시간은 각각 6, 2, 4이고 weight는 2, 1, 1이라고 하자. (한 번에 받는 token의 크기) 각 job은 받은 token만큼 실행하고 아직 작업이 더 남은 경우에는 다시 ready queue에 들어오고 실행을 마친 경우에는 사라진다.
처음 round에서 CPU는 J1에 대해 2, J2에 대해 1, J3에 대해 1만큼 token을 준다. 따라서 해당 시간만큼 돌아가면서 실행한다. 일반적으로 queue는 FIFO이기 때문에 J1부터 실행한다.
다음 round에서도 마찬가지로 2, 1, 1씩 실행한다. 이 때 J2는 실행을 마쳤기 때문에 ready queue에 들어오지 않는다.
따라서 Round 3에서는 J1, J3에 대해서만 2, 1만큼의 token을 할당한다. J1 역시 실행을 마쳤으므로 ready queue에 들어오지 않는다.
Round 4에서는 ready queue에 남은 J3에 대해서만 1만큼 실행한다.
이처럼 round를 시작할 때의 ready queue의 상태를 보고 token을 할당하기 때문에 새로운 job이 들어오거나 기존의 job이 사라질 수 있는 on-line scheduling이라고 할 수 있다.
Priority Driven Approach
각 job에 부여된 priority에 따라 priority가 높은 task부터 실행한다. preemption이 가능한 경우에는 스케줄링되는 period마다 ready queue에 있는 job 중 가장 높은 priority의 job을 실행하며, preemption이 불가능한 경우에는 한 job이 끝났을 때 ready queue를 검사한다.
여담으로 preemption이 불가능할 때 높은 priority의 job이 먼저 실행된 낮은 priority의 job 떄문에 실행되지 못하는 것을 block당했다고 말한다.
이제 중요한 것은 기준이 되는 priority를 어떻게 할당할 것인지를 결정하는 것이다. priority 결정 방법은 크게 3가지로 분류할 수 있다.
- Task 단위로 할당: Fixed priority 혹은 Static priority로도 부른다. 같은 task의 모든 job은 같은 priority를 가지게 된다. (ex : RM, DM)
- Job 단위로 할당: Dynamic priority로도 부른다. job 단위로 priority를 할당한다. 같은 task의 job이라도 priority가 다를 수 있다. (ex : EDF)
- Tick마다 priority를 할당: 위의 두 case는 한번 priority가 결정되면 바뀌지 않지만, 다음 실행할 job을 결정하는 tick마다 priority가 바뀐다. (ex : LST)
LST (Least Slack Time)
Slack
deadline과 job completion time 사이의 간격을 말한다. 이 때 job completion time은 현재 시간 기준으로 해당 job이 계속하여 실행된다고 했을 때의 끝나는 시각을 의미한다. 따라서 job이 실행되고 있으면 slack이 그대로이며, ready queue에만 있고 실행되지 않는 상태이면 감소한다.
LST 알고리즘은 slack이 작은 job부터 실행하는 알고리즘이다. slack은 tick마다 바뀌므로 tick마다 priority를 할당하는 알고리즘이라 할 수 있다.
ex)
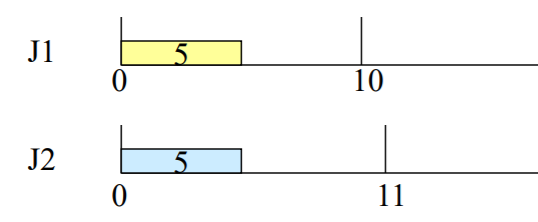
J1, J2의 release time이 0이고 execution time이 5이며 Job 1의 deadline이 10, Job 2의 deadline이 11이라고 하자. LST를 이용해 스케줄링하며 slack이 같으면 J1을 먼저 실행한다고 하자.
그럼 첫 tick에서는 J1의 slack은 5, J2의 slack은 6이므로 J1이 실행된다. 다음 tick에서는 두 slack이 모두 5가 된다. 따라서 J1이 실행되고, 3번째 tick에서는 J2의 slack이 4가 되므로 J2가 실행된다.
따라서 J1-J1-J2-J1-J2- ... 의 순서로 실행된다.
이와 같이 LST는 preemption이 계속해서 일어나서 context switch에 의한 overhead가 크다는 단점이 있다.
Fixed Priority Scheduling과 Dynamic Priority Scheduling에 대해서는 이후 글에서 이어서 소개하겠다.

On-line scheduling은 성능이 좋은가? 문단에 오타 있내요
사진은 피피티로 직접 만드신건가요? 대단해요