
개요
인공위성과의 통신에서 데이터가 올바르게 전달되고 있는지 확인하기 위해, 데이터를 헥스 덤프(Hex dump) 형식으로 시각화하는 작업을 진행했습니다. 헥스 덤프는 데이터를 16진수와 ASCII 코드로 표현해 데이터를 쉽게 분석할 수 있도록 합니다.
이번 글에서는 헥스 덤프의 개념과 구조를 설명하고, Uint8Array 데이터를 헥스 덤프 형식으로 변환하는 방법, 16진수 문자열을 헥스 덤프로 변환하는 방법을 설명하겠습니다. 먼저 16진수와 ASCII 코드, Uint8Array에 대해 간략하게 알아보겠습니다.
용어
16진수
16진법은 16을 기수로 하는 번호 체계를 뜻하며, 16진수는 16진법으로 표기된 숫자 자체를 의미합니다.
16진수는 0부터 9까지는 10진수와 동일하게 표기하고 10부터 15까지는 A~F 문자를 사용하여 아래와 같이 표현합니다.
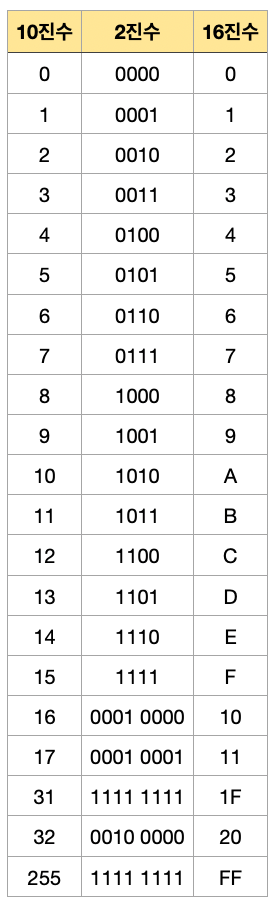
2진수의 네 자리 숫자(1010)와 16진수 한 자리 숫자(A)가 일대일 대응하여, 16진수는 2진수보다 읽기 쉽고 간결하며, 메모리 주소, 색상 코드(#FFFFFF), 파일 헤더 분석 등에 사용됩니다.
ASCII 코드
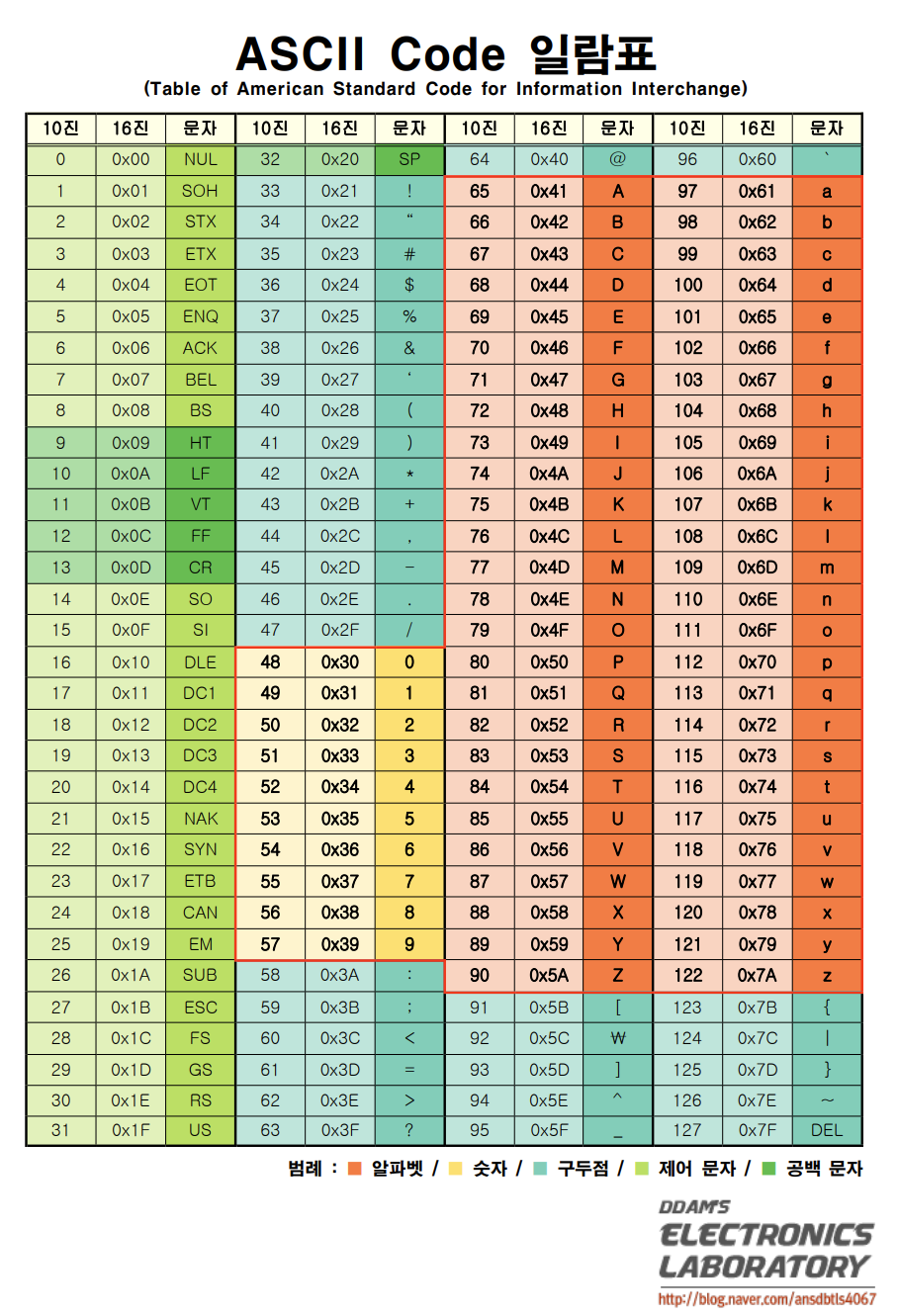
ASCII(American Standard Code for Information Interchange)는 문자(알파벳, 숫자, 기호)를 숫자로 표현하는 표준 부호 체계입니다.
컴퓨터는 이진 데이터만 이해할 수 있기 때문에, ASCII 코드는 문자를 숫자로 변환하여 처리할 수 있도록 도와줍니다.
ASCII 코드는 0부터 127까지의 범위를 가지며, 그 중 32부터 126까지가 출력 가능한 문자입니다.
예를 들어, A는 65, a는 97, 0은 48에 해당합니다. 출력 불가능한 문자(예: 제어 문자)는 헥스 덤프에서 점(.)으로 표시됩니다.
Uint8Array
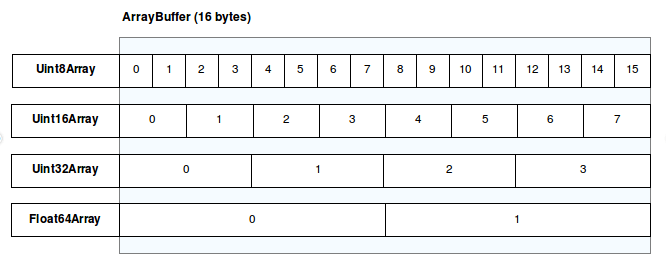
Uint8Array는 JavaScript에서 사용되는 형식화 배열(Typed Array) 중 하나로, 8비트 부호 없는 정수(unsigned 8-bit integer)의 배열을 나타냅니다.
- 형식화 배열(Typed Array): JavaScript에서 바이너리 데이터를 효율적으로 처리하기 위해 도입된 객체입니다.
Uint8Array는 이 중 하나로, 각 요소가 8비트(1바이트)의 부호 없는 정수(unsigned integer)로 구성됩니다. - 부호 없는 정수(unsigned integer): 0부터 255까지의 값을 가질 수 있습니다. 이는 1바이트(8비트)로 표현 가능한 범위입니다.
- 바이너리 데이터: 컴퓨터에서 데이터는 바이트 단위로 저장되며,
Uint8Array는 이러한 바이트 단위의 데이터를 직접 다룰 수 있게 해줍니다.
헥스 덤프(Hex dump)
헥스 덤프의 구조
00000000: 48 65 6c 6c 6f 20 57 6f 72 6c 64 21 00 00 00 00 |Hello World!...|헥스 덤프는 바이너리 데이터를 16진수와 ASCII 코드 형태로 시각적으로 표현하여 데이터를 더 쉽게 분석할 수 있도록 도와줍니다.
헥스 덤프의 형식은 상황에 따라 다를 수 있으며, 일반적인 헥스 덤프는 보통 세 가지 부분으로 구성됩니다.
주소(Offset)
- 각 줄의 왼쪽에 표시된 값(예:
00000000,00000010)은 바이트 오프셋(주소)입니다. - 이 값은 데이터의 시작 위치를 16진수로 나타내며, 일반적으로 16바이트 단위로 증가합니다.
- 예를 들어,
00000000은 첫 번째 바이트를,00000010은 17번째 바이트를 가리킵니다.
헥스 데이터(Hexadecimal Data)
- 중간 부분에 있는
48 65 6c ...는 해당 메모리 영역이나 파일 부분의 실제 데이터 값을 16진수로 나타낸 것입니다. - 각 값은 1바이트(2자리 16진수)를 나타내며, 한 줄에 16바이트가 표시됩니다.
ASCII 표현(ASCII Representation)
- 가장 오른쪽 부분 (
|Hello World!...|)은 해당 16바이트 데이터를 ASCII 문자로 변환한 결과입니다. - 출력 가능한 문자는 그대로 표시되고, 출력 불가능한 문자는 .(점)으로 표시됩니다.
헥스 덤프 변환
Uint8Array 데이터를 헥스 덤프 형식으로 변환
/**
* Uint8Array 데이터를 헥스 덤프 형식으로 변환하는 함수
* @param data 변환할 Uint8Array 데이터
* @param bytesPerLine 한 줄에 출력할 바이트 수 (기본값: 16)
* @returns 헥스 덤프 형식의 문자열
*/
function generateHexDump(data: Uint8Array, bytesPerLine = 16): string {
const result: string[] = []
for (let i = 0; i < data.length; i += bytesPerLine) {
// 지정된 크기만큼 데이터를 슬라이스
const chunk = data.slice(i, i + bytesPerLine)
// 현재 오프셋(주소)을 16진수로 변환하여 8자리로 맞춤
const address = i.toString(16).padStart(8, '0')
// 바이트 데이터를 16진수 문자열로 변환하여 공백으로 구분
const hex = Array.from(chunk, (byte) => {
return byte.toString(16).padStart(2, '0')
})
.join(' ')
.padEnd(bytesPerLine * 3 - 1) // 공백 포함 길이 정렬
// ASCII 표현 (출력 가능한 문자만 그대로, 나머지는 '.')
const ascii = Array.from(chunk, (byte) => {
return byte >= 32 && byte <= 126 ? String.fromCharCode(byte) : '.'
})
.join('')
.padEnd(bytesPerLine)
// 최종 출력 형식: [주소]: [16진수 값] |[ASCII 값]|
result.push(`${address}: ${hex} |${ascii}|`)
}
return result.join('\n') // 변환된 문자열 반환
}위 함수는 Uint8Array를 받아서 각 바이트를 16진수로 변환하고, 각 값에 대응하는 ASCII 코드도 출력합니다.
한 줄에 표시할 바이트 수는 bytesPerLine 매개변수로 조정할 수 있습니다.
위 코드와 같이 bytesPerLine을 16으로 설정하면 한 줄에 16바이트가 출력됩니다.
data.slice(i, i + bytesPerLine): 데이터를 지정된 크기(bytesPerLine)로 자릅니다.address: 현재 오프셋을 16진수로 변환하고, 8자리로 맞춥니다.hex: 각 바이트를 16진수 문자열로 변환하고, 공백으로 구분합니다.ascii: 각 바이트를 ASCII 문자로 변환합니다. 출력 불가능한 문자는 점(.)으로 대체합니다.
실행 예시
const exampleData = new Uint8Array([
0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x2C, 0x20, 0x57,
0x6F, 0x72, 0x6C, 0x64, 0x21, 0x20, 0x54, 0x68,
0x69, 0x73, 0x20, 0x69, 0x73, 0x20, 0x61, 0x20,
0x74, 0x65, 0x73, 0x74, 0x20, 0x64, 0x61, 0x74,
0x61, 0x2E, 0x20, 0x4C, 0x65, 0x74, 0x27, 0x73,
0x20, 0x73, 0x65, 0x65, 0x20, 0x68, 0x6F, 0x77,
0x20, 0x69, 0x74, 0x20, 0x6C, 0x6F, 0x6F, 0x6B,
0x73, 0x20, 0x69, 0x6E, 0x20, 0x61, 0x20, 0x68,
0x65, 0x78, 0x20, 0x64, 0x75, 0x6D, 0x70, 0x2E
])
generateHexDump(exampleData)00000000: 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 21 20 54 68 |Hello, World! Th|
00000010: 69 73 20 69 73 20 61 20 74 65 73 74 20 64 61 74 |is is a test dat|
00000020: 61 2e 20 4c 65 74 27 73 20 73 65 65 20 68 6f 77 |a. Let's see how|
00000030: 20 69 74 20 6c 6f 6f 6b 73 20 69 6e 20 61 20 68 | it looks in a h|
00000040: 65 78 20 64 75 6d 70 2e |ex dump. |16진수 문자열을 헥스 덤프 형식으로 변환
/**
* 16진수 문자열을 헥스 덤프 형식으로 변환하는 함수
* @param hexString 변환할 16진수 문자열 (공백 없이 연속된 문자열)
* @param bytesPerLine 한 줄에 출력할 바이트 수 (기본값: 16)
* @returns 헥스 덤프 형식의 문자열
*/
function generateHexDump(hexString: string, bytesPerLine = 16): string {
const result: string[] = []
for (let i = 0; i < hexString.length; i += bytesPerLine * 2) {
// 지정된 크기만큼 데이터를 슬라이스
const chunk = hexString.slice(i, i + bytesPerLine * 2)
// 현재 오프셋(주소)을 16진수로 변환하여 8자리로 맞춤 (문자열이므로 바이트 단위로 변환 필요)
const address = (i / 2).toString(16).padStart(8, '0')
// 16진수 문자열을 2자리씩 나누고 공백으로 구분하여 출력 형태로 변환
const hex =
chunk
.match(/.{1,2}/g) // 2자리씩 분리
?.join(' ') // 공백으로 구분
.padEnd(bytesPerLine * 3 - 1, ' ') || '' // 출력 형식 정렬
// ASCII 코드: 16진수를 문자로 변환 (출력 가능한 문자만 표시)
const ascii =
chunk
.match(/.{1,2}/g) // 2자리씩 분리
?.map((byte) => {
const charCode = parseInt(byte, 16) // 16진수를 숫자로 변환
return charCode >= 32 && charCode <= 126
? String.fromCharCode(charCode) // ASCII 문자로 변환
: '.' // 출력 불가능한 문자 대체
})
.join('')
.padEnd(bytesPerLine, ' ') || '' // 출력 형식 맞춤
// 최종 출력 형식: [주소]: [16진수 값] |[ASCII 값]|
result.push(`${address}: ${hex} |${ascii}|`)
}
return result.join('\n') // 변환된 문자열 반환
}위 함수는 헥스 문자열을 입력받아 헥스 덤프 형식으로 변환합니다. 16진수 문자열 값을 두 글자씩 잘라서 출력하며, 각 값에 대응하는 ASCII 코드도 출력합니다. 대부분의 코드는 동일하므로 Uint8Array 데이터 변환과 다른 점만 설명하겠습니다.
hexString.slice(i, i + bytesPerLine * 2): 16진수 문자열에서 각 바이트는 2개의 문자로 표현되기 때문에Uint8Array데이터와 다르게*2를 하여 자릅니다. (Uint8Array데이터는 각 요소가 한 바이트)(i / 2).toString(16).padStart(8, '0'): 16진수 문자열은 2자리가 1바이트를 나타내므로, 오프셋 계산 시i / 2를 사용하여 바이트 단위로 변환합니다.chunk.match(/.{1,2}/g): 16진수 문자열을 2자리씩 분리하여 각 바이트를 나타냅니다.
실행 예시
const exampleHexString = '48656c6c6f2c20576f726c642120546869732069732061207465737420646174612e204c657427732073656520686f77206974206c6f6f6b7320696e2061206865782064756d702e'
generateHexDumpFromString(exampleHexString)00000000: 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 21 20 54 68 |Hello, World! Th|
00000010: 69 73 20 69 73 20 61 20 74 65 73 74 20 64 61 74 |is is a test dat|
00000020: 61 2e 20 4c 65 74 27 73 20 73 65 65 20 68 6f 77 |a. Let's see how|
00000030: 20 69 74 20 6c 6f 6f 6b 73 20 69 6e 20 61 20 68 | it looks in a h|
00000040: 65 78 20 64 75 6d 70 2e |ex dump. |마무리
이번 글에서는 헥스 덤프의 개념과 구조를 알아보고, Uint8Array 데이터와 16진수 문자열을 헥스 덤프 형식으로 변환하는 방법을 알아봤습니다.
헥스 덤프에 대해 잘 알지 못했기 때문에 처음에는 어떻게 변환하여 출력 해야할지 감이 잡히지 않았는데 자료를 찾아보며 많은 것을 배운 것 같습니다. 부족한 부분이 있다면 의견 부탁드립니다😄

네????222