자율화 앱은 입력되는 트래픽을 처리하기 위해 자체적으로 확장 및 축소되며 간헐적인 오류가 발생하면 스스로 복구합니다. 컨테이너 플랫폼은 상태 확인으로 이미지를 빌드하는 경우 많은 작업을 수행할 수 있지만 상황이 심각하게 잘못되었을 때 사람이 개입하도록 지속적인 모니터링 및 경고가 필요합니다.
모니터링은 앱이 수행하는 작업과 성능을 알려주고 문제의 원인을 정확히 찾아내는 데 도움이 됩니다. 이 장에서는 모니터링에 대한 잘 정립된 방법을 배웁니다. 이러한 도구는 앱과 함께 컨테이너에서 실행됩니다. 개발에서 프로덕션에 이르기까지 모든 환경에서 앱 성능에 대해 통찰력을 얻을 수 있습니다.
9.1 컨테이너 앱을 위한 모니터링 스택
앱이 컨테이너에서 실행되는 경우 모니터링이 다릅니다. 기존 환경에서는 서버 목록과 현재 사용률(디스크 공간, 메모리, CPU)을 표시하는 모니터링 대시보드와 과로되어 응답을 중지할 가능성이 있는 서버가 있는지 알려주는 경고가 있을 수 있습니다. 컨테이너화된 앱은 수명이 짧고 컨테이너 플랫폼에 의해 생성되거나 제거되는 수십 또는 수백 개의 컨테이너에서 실행될 수 있습니다.
검색을 위해 컨테이너 플랫폼에 연결할 수 있고 컨테이너 IP 주소의 정적 목록 없이 실행 중인 모든 앱을 찾을 수 있는 도구를 사용하여 컨테이너를 인식하는 모니터링 접근 방식이 필요합니다. Prometheus는 CNCF(Kubernetes 및 컨테이너식 컨테이너 런타임의 동일한 기반)에서 감독하는 성숙한 제품입니다. 컨테이너에서 실행되므로 앱에 모니터링 스택을 쉽게 추가할 수 있습니다. 그림 9.1은 스택이 어떻게 생겼는지 보여줍니다.
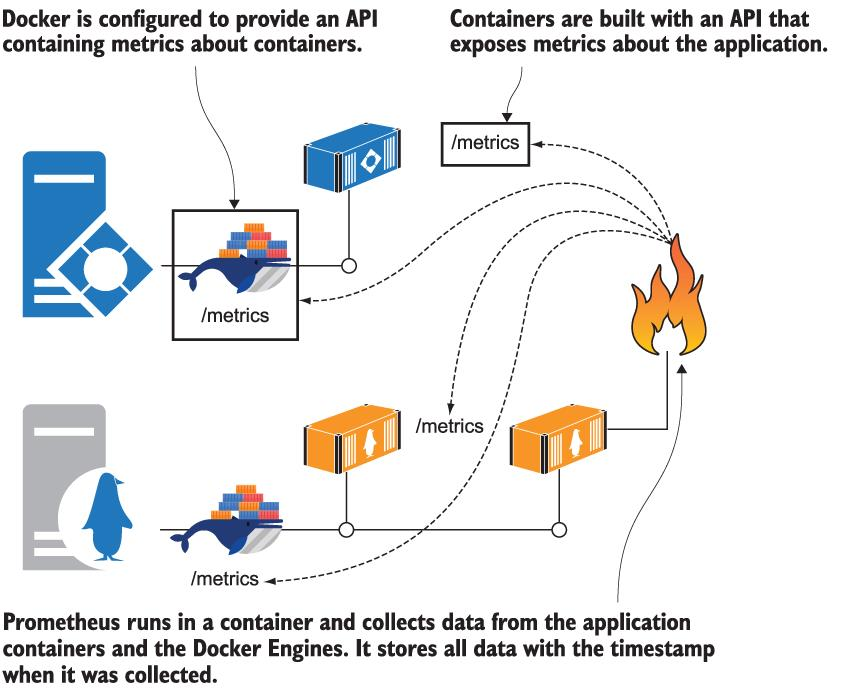
그림 9.1 컨테이너에서 Prometheus를 실행하여 다른 컨테이너와 도커 자체 모니터링
Prometheus는 모니터링에서 모든 앱에 대해 동일한 유형의 메트릭을 내보낼 수 있으므로 모니터링하는 표준 방법이 있습니다. 학습할 쿼리 언어는 하나뿐이며 전체 앱 스택에 적용할 수 있습니다.
또한 도커 엔진이 해당 형식으로 메트릭을 내보낼 수도 있기 때문에 컨테이너 플랫폼에서 일어나는 일에 대한 이해도 얻을 수 있습니다. 도커 엔진 구성에서 Prometheus 메트릭을 명시적으로 활성화해야 합니다. 구성을 업데이트하는 방법은 5장에서 확인했습니다. daemon.json 파일은 /etc/에서 직접 편집할 수 있습니다. 도커 Desktop에서 고래 아이콘을 마우스 오른쪽 버튼으로 클릭하고 설정을 선택한 다음 데몬 섹션에서 구성을 편집할 수 있습니다.
TRY 구성 설정을 열고 두 개의 새 값을 추가하십시오.
"metrics-addr" : "0.0.0.0:9323",
"experimental": true이는 모니터링을 활성화하고 포트를 노출합니다.
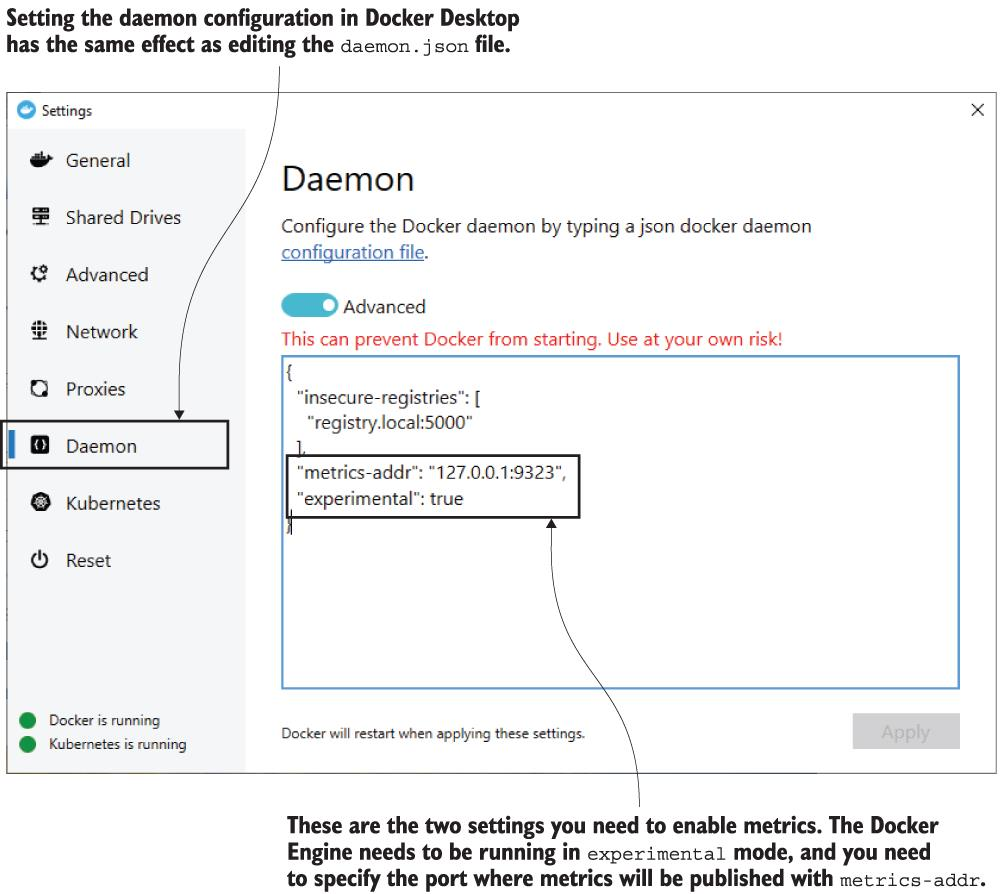
그림 9.2 Prometheus 형식으로 메트릭을 내보내도록 도커 엔진 구성
도커 Engine 메트릭은 현재 실험적인 기능이므로 제공하는 세부 정보가 변경될 수 있습니다. 하지만 오랫동안 실험적인 기능이었고 안정적이었습니다. 시스템의 전반적인 상태에 또 다른 세부 사항을 추가하기 때문에 대시보드에 포함할 가치가 있습니다. 이제 메트릭을 활성화했으므로 http:// /localhost:9323/metrics로 이동하여 Docker가 제공하는 모든 정보를 볼 수 있습니다. 그림 9.3은 Docker가 실행 중인 머신과 Docker가 관리하는 컨테이너에 대한 정보를 포함하는 지표를 보여줍니다.
이 출력은 Prometheus 형식입니다. 각 메트릭이 이름과 값과 함께 표시되는 간단한 텍스트 기반 표현이며, 메트릭이 무엇인지와 데이터 유형을 설명하는 도움말 텍스트가 메트릭 앞에 옵니다. 이러한 기본 텍스트 줄은 컨테이너 모니터링 솔루션의 핵심입니다. 각 구성 요소는 현재 메트릭을 제공하는 이와 같은 끝점을 노출합니다. Prometheus는 데이터를 수집할 때 데이터에 타임스탬프를 추가하고 모든 이전 컬렉션과 함께 저장하므로 집계로 데이터를 쿼리하거나 시간 경과에 따른 변경 사항을 추적할 수 있습니다.
TRY 컨테이너에서 Prometheus를 실행하여 도커 시스템에서 메트릭을 읽을 수 있지만 먼저 시스템의 IP 주소를 가져와야 합니다. 컨테이너는 실행 중인 서버의 IP 주소를 모르기 때문에 먼저 찾아서 컨테이너에 환경 변수로 전달해야 합니다.
# load your machine's IP address into a variable - Linux
hostIP=$(ip route get 1 | awk '{print $NF;exit}')
# and on Mac:
hostIP=$(ifconfig en0 | grep -e 'inet\s' | awk '{print $2}')
# pass your IP address as an environment variable for the container:
docker container run -e DOCKER_HOST=$hostIP -d -p 9090:9090 diamol/prometheus:2.13.1diamol/prometheus Prometheus 이미지의 구성은 DOCKER_ HOST IP 주소를 사용하여 호스트 시스템과 통신하고 도커 엔진에서 구성한 메트릭을 수집합니다. 컨테이너 내부에서 호스트의 서비스에 액세스해야 하는 경우는 드뭅니다. 그렇게 하는 경우 일반적으로 서버 이름을 사용하고 Docker는 IP 주소를 찾습니다. 작동하지 않을 수 있는 개발 환경에서는 IP 주소 접근 방식이 적합해야 합니다.
현재 Prometheus가 실행 중입니다. 도커 호스트에서 메트릭을 가져오기 위해 예약된 작업을 실행하고, 자체 데이터베이스의 타임스탬프와 함께 해당 메트릭 값을 저장하고, 메트릭을 탐색하는 데 사용할 수 있는 기본 웹 UI가 있습니다. Prometheus UI는 Docker의 /metrics 엔드포인트의 모든 정보를 표시하며, 메트릭을 필터링하여 테이블이나 그래프에 표시할 수 있습니다.
TRY http:// /localhost:9090으로 이동하면 Prometheus 웹 인터페이스가 표시됩니다. 상태 > 대상 메뉴 옵션으로 이동하여 Prometheus가 메트릭에 액세스할 수 있는지 확인할 수 있습니다. DOCKER_HOST 상태는 녹색이어야 합니다. 이는 Prometheus가 이를 찾았음을 의미합니다.
그런 다음 그래프 메뉴로 전환하면 Prometheus가 Docker에서 수집한 사용 가능한 모든 메트릭을 보여주는 드롭다운 목록이 표시됩니다. 그 중 하나는 서로 다른 컨테이너 작업에 소요된 시간에 대한 기록인 engine_daemon_container_actions_seconds_sum입니다. 해당 메트릭을 선택하고 Execute를 클릭하면 출력이 그림 9.4의 내 것과 유사하여 컨테이너를 생성, 삭제 및 시작하는 데 걸린 시간을 보여줍니다.
Prometheus UI는 무엇을 수집하고 있는지 확인하고 일부 쿼리를 실행하는 간단한 방법입니다. 메트릭을 살펴보면 Docker가 많은 정보 포인트를 기록한다는 것을 알 수 있습니다. 일부는 각 상태의 컨테이너 수 및 실패한 상태 확인 수와 같은 상위 수준 판독값입니다. 나머지는 도커 엔진이 할당한 메모리 양과 같은 낮은 수준의 세부 정보를 제공합니다. 일부는 Docker에서 사용할 수 있는 CPU 수와 같은 정적 정보입니다. 이는 인프라 수준 메트릭으로 상태 대시보드에 포함할 수 있는 모든 유용한 항목입니다.
앱은 자체 메트릭을 노출하고 다른 수준의 세부 정보도 기록합니다. 목표는 각 컨테이너에 메트릭 엔드포인트를 갖고 Prometheus가 정기적인 일정에 따라 모든 컨테이너에서 메트릭을 수집하도록 하는 것입니다. Prometheus는 전체 시스템의 전반적인 상태를 보여주는 대시보드를 구축하기에 충분한 정보를 저장합니다.
9.2 앱에서 메트릭 노출
도커 엔진이 노출하는 메트릭이 아니라 각 앱 컨테이너에서 필요한 메트릭 세트를 노출하려면 메트릭을 캡처하고 Prometheus가 호출할 HTTP 엔드포인트를 제공하는 코드가 필요합니다. 주요 프로그래밍 언어를 위한 Prometheus 클라이언트 라이브러리가 있기 때문에 생각보다 많은 작업이 필요하지 않습니다.
이 장의 코드에서 NASA의 image-gallery 앱을 다시 방문하여 각 구성 요소에 Prometheus 메트릭을 추가했습니다. Java 및 Go용 공식 Prometheus 클라이언트와 Node.js용 커뮤니티 클라이언트 라이브러리를 사용하고 있습니다. 그림 9.5는 각 앱 컨테이너가 메트릭을 수집하고 노출하는 Prometheus 클라이언트와 함께 패키징되는 방법을 보여줍니다.
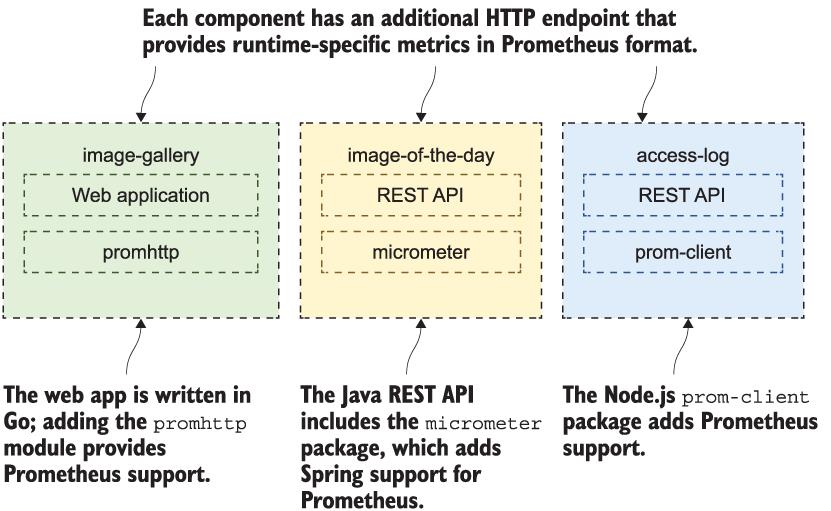
그림 9.5 앱의 Prometheus 클라이언트 라이브러리는 측정용 엔드포인트를 컨테이너에서 사용할 수 있도록 합니다.
Prometheus 클라이언트 라이브러리에서 수집된 정보 포인트는 런타임 수준 메트릭입니다. 앱 런타임과 관련하여 컨테이너가 수행하는 작업과 작업 강도에 대한 주요 정보를 제공합니다. Go 앱의 메트릭에는 활성 goroutine 수가 포함됩니다. Java 앱에 대한 메트릭에는 JVM에서 사용되는 메모리가 포함됩니다. 각 런타임에는 고유한 메트릭이 있으며 클라이언트 라이브러리는 이를 수집하고 내보내는 작업을 훌륭하게 수행합니다.
TRY 이 장의 연습에는 각 컨테이너에 메트릭이 있는 새 버전의 이미지 갤러리 앱을 실행하는 Compose 파일이 있습니다. 앱을 사용한 다음 메트릭 엔드포인트 중 하나로 이동합니다.
cd ./ch09/exercises
# clear down existing containers:
docker container rm -f $(docker container ls -aq)
# create the nat network - if you've already created it
# you'll get a warning which you can ignore:
docker network create nat
# start the project
docker-compose up -dbrowse to http://localhost:8010 to use the app then browse to http://localhost:8010/metrics
결과는 아래와 같은 Go 프론트엔드 앱으로부터의 메트릭입니다. 이 데이터를 만드는데 필요한 커스텀 코드는 없습니다.
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 2.9167e-05
go_gc_duration_seconds{quantile="0.25"} 2.9167e-05
go_gc_duration_seconds{quantile="0.5"} 2.9167e-05
go_gc_duration_seconds{quantile="0.75"} 2.9167e-05
go_gc_duration_seconds{quantile="1"} 2.9167e-05
go_gc_duration_seconds_sum 2.9167e-05
go_gc_duration_seconds_count 1
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 10http://localhost:8011/actuator/prometheus에서 Java REST API에 대한 메트릭을 확인할 수 있습니다. 메트릭 엔드포인트는 엄청난 텍스트지만 주요 데이터 포인트는 컨테이너가 CPU 시간, 메모리, 프로세서 쓰레드와 같은 리소스를 많이 사용하는 경우 "hot" 실행 중인지 여부를 보여주는 대시보드를 구축하기 위해 있습니다.
이들 런타임 메트릭은 도커의 인프라 메트릭 다음으로 원하는 세부 수준이지만 이 두 수준이 전체 내용을 말해주지는 않습니다. 최종 데이터 포인트는 앱에 대한 주요 정보를 기록하기 위해 명시적으로 캡처하는 앱 메트릭입니다. 이러한 메트릭은 구성 요소가 처리한 이벤트 수 또는 응답을 처리하는 평균 시간을 보여주는 작업 중심이거나 현재 활성 사용자 수 또는 새 서비스에 가입하는 사람들의 수를 보여주는 비즈니스 중심일 수 있습니다.
Prometheus 클라이언트 라이브러리를 사용하면 이러한 종류의 메트릭도 기록할 수 있지만 앱에서 정보를 캡처하려면 코드를 명시적으로 작성해야 합니다. 목록 9.1은 image-gallery 앱의 액세스 로그 구성 요소에 대한 코드에 있는 Node.js 라이브러리를 사용하는 예를 보여줍니다. server.js 파일의 이 스니펫은 몇 가지 핵심 사항을 보여줍니다.
목록 9.1 Node.js에서 사용자 정의 Prometheus 메트릭 값 선언 및 사용
//declare custom metrics:
const accessCounter = new prom.Counter({
name: "access_log_total",
help: "Access Log - total log requests"
});
const clientIpGauge = new prom.Gauge({
name: "access_client_ip_current",
help: "Access Log - current unique IP addresses"
});
//and later, update the metrics values:
accessCounter.inc();
clientIpGauge.set(countOfIpAddresses);소스 코드에서 Go로 작성된 image-gallery 앱과 Java로 작성된 image-of-the-day REST API에 메트릭을 추가한 방법을 볼 수 있습니다. 각 Prometheus 라이브러리는 다른 방식으로 작동합니다. main.go 소스 파일에서 Node.js 앱과 유사한 방식으로 카운터와 게이지를 초기화하지만 메트릭은 클라이언트 라이브러리의 계측 처리기를 사용합니다. Java 앱은 ImageController.java에서 @Timed 속성을 사용하고 소스에서 registry.counter 객체를 증가시킵니다. 각 클라이언트 라이브러리는 언어에 대해 가장 논리적인 방식으로 작동합니다.
Prometheus에는 다양한 유형의 메트릭이 있습니다. 앱에서는 가장 간단한 메트릭인 카운터와 게이지를 사용했습니다. 카운터는 증가하거나 동일하게 유지되는 값을 보유하고 게이지는 증가하거나 감소할 수 있는 값을 보유합니다. 메트릭 유형을 선택하고 정확한 시간에 값을 설정하는 것은 앱 개발자에게 달려 있습니다. 나머지는 Prometheus와 라이브러리에서 처리합니다.
TRY 마지막 연습에서 실행 중인 image-gallery 앱이 있으므로 이러한 메트릭이 이미 수집되고 있습니다. 앱에 로드를 실행한 다음 Node.js 앱의 메트릭 엔드포인트로 이동합니다.
# loop to make 5 HTTP GET request on Linux:
for i in {1..5}; do curl http://localhost:8010 > /dev/null; done브라우저에서 http://localhost:8012/metrics
트래픽을 보내기 위해 몇 가지 루프를 더 실행했습니다. 처음 두 레코드는 수신된 액세스 요청 수와 서비스를 사용하는 총 IP 주소 수를 기록하는 내 사용자 지정 메트릭을 보여줍니다. 이들은 단순한 데이터 포인트(그리고 IP 수는 실제로 가짜임)이지만 메트릭을 수집하고 표시하는 목적으로 사용됩니다. Prometheus를 사용하면 더 복잡한 유형의 메트릭을 기록할 수 있지만 간단한 카운터와 게이지로도 앱에서 자세한 계측을 캡처할 수 있습니다.
동일한 메트릭 엔드포인트는 커스텀 값과 표준 node.js 데이터를 제공합니다.
# HELP access_log_total Access Log - total log requests
# TYPE access_log_total counter
access_log_total{hostname="44b8b3ed68e5"} 11
# HELP access_client_ip_current Access Log - current unique IP addresses
# TYPE access_client_ip_current gauge
access_client_ip_current{hostname="44b8b3ed68e5"} 8클라이언트 라이브러리가 nodejs 런타임 메트릭을 제공됩니다. CPU 사용량을 보여줍니다.
# HELP process_cpu_system_seconds_total Total system CPU time spent in seconds.
# TYPE process_cpu_system_seconds_total counter
process_cpu_system_seconds_total{hostname="44b8b3ed68e5"} 3.4223400000000006 1647332972141캡처하는 항목에 대해 몇 가지 유용한 지침을 제공합니다.
-
외부 시스템과 대화할 때 호출에 걸린 시간과 응답 성공 여부를 기록하세요. 다른 시스템이 속도를 늦추거나 방해하는지 빠르게 확인할 수 있습니다.
-
로깅할 가치가 있는 것은 잠재적으로 메트릭으로 기록할 가치가 있습니다. 로그 항목을 작성하는 것보다 카운터를 증가시키는 것이 메모리, 디스크 및 CPU에서 더 저렴할 수 있으며 일이 얼마나 자주 발생하는지 시각화하는 것이 좋습니다.
-
비즈니스 팀이 보고하려는 앱이나 사용자 액션 정보는 메트릭으로 기록되어야 합니다. 이렇게 하면 기록 보고서를 보내는 대신 실시간 대시보드를 구축할 수 있습니다.
9.3 Prometheus 컨테이너를 실행하여 메트릭 수집
Prometheus는 풀 모델을 사용하여 메트릭을 수집합니다. 다른 시스템에서 데이터를 보내도록 하는 대신 해당 시스템에서 데이터를 가져옵니다. 이를 스크래핑이라고 하며 Prometheus를 배포할 때 스크래핑할 엔드포인트를 구성합니다. 프로덕션 컨테이너 플랫폼에서 클러스터에서 모든 컨테이너를 자동으로 찾도록 Prometheus를 구성할 수 있습니다. 단일 서버의 Compose에서는 간단한 서비스 이름 목록을 사용하고 Prometheus는 도커의 DNS를 통해 컨테이너를 찾습니다.
Listing 9.2는 Prometheus가 image-gallery 앱에서 두 개의 구성 요소를 스크래핑하는데 사용한 구성을 보여줍니다. 스크랩 사이에 기본 10초 간격을 사용하는 전역 설정이 있으며 각 구성 요소에 대한 작업이 있습니다. 작업에는 이름이 있고 구성은 메트릭 끝점에 대한 URL 경로와 Prometheus가 쿼리할 대상 목록을 지정합니다. 여기서는 두 가지 유형을 사용합니다. 먼저 static_configs는 단일 컨테이너에 적합한 대상 호스트 이름을 지정합니다. 또한 dns_sd_configs를 사용합니다. 즉, Prometheus가 DNS 서비스 검색을 사용합니다. 즉, 서비스에 대해 여러 컨테이너를 찾고 대규모 실행을 지원합니다.
Listing 9.2 앱 메트릭을 수집하기 위한 구성
global:
scrape_interval: 10s
scrape_configs:
- job_name: "image-gallery"
metrics_path: /metrics
static_configs:
- targets: ["image-gallery"]
- job_name: "iotd-api"
metrics_path: /actuator/prometheus
static_configs:
- targets: ["iotd"]
- job_name: "access-log"
metrics_path: /metrics
scrape_interval: 3s
dns_sd_configs:
- names:
- accesslog
type: A
port: 80
- job_name: "docker"
metrics_path: /metrics
static_configs:
- targets: ["DOCKER_HOST:9323"]10초마다 모든 컨테이너를 폴링하도록 설정합니다. DNS를 사용하여 컨테이너 IP 주소를 가져오지만 image-gallery의 경우 단일 컨테이너만 찾을 것으로 예상하므로 해당 구성 요소를 확장하면 예기치 않은 동작이 발생합니다. Prometheus는 DNS 응답에 여러 개의 IP 주소가 포함된 경우 항상 목록의 첫 번째 IP 주소를 사용하므로 도커가 메트릭 엔드포인트에 대한 요청을 로드 밸런싱할 때 다른 컨테이너에서 메트릭을 가져옵니다. accesslog 구성 요소는 여러 IP 주소를 지원하도록 구성되어 있으므로 Prometheus는 모든 컨테이너 IP 주소 목록을 작성하고 동일한 일정에 모두 폴링합니다. 그림 9.8은 스크래핑 프로세스가 실행되는 방법을 보여줍니다.
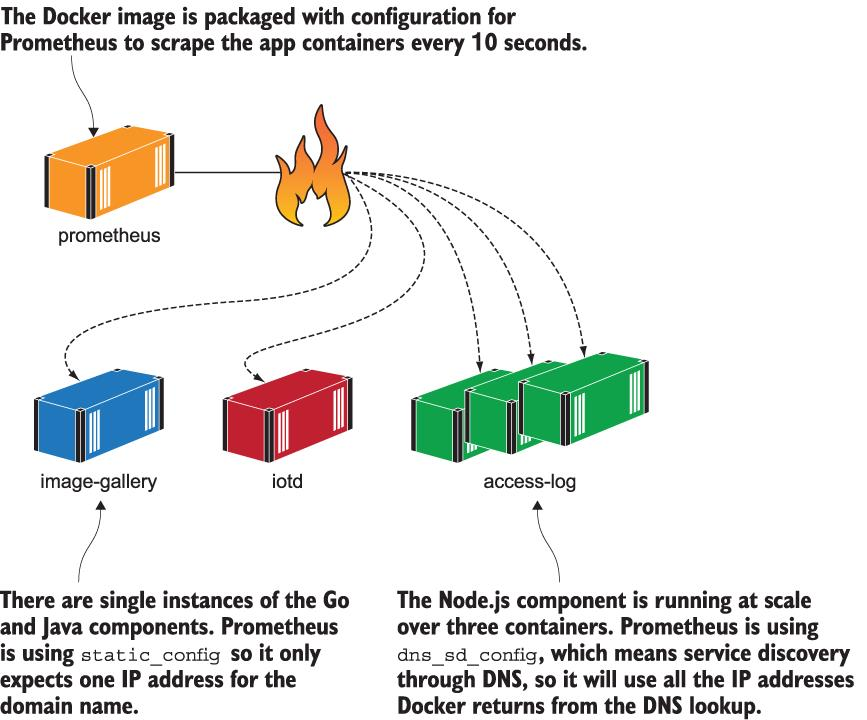
그림 9.8 앱 컨테이너에서 메트릭을 스크랩하도록 구성되어 컨테이너에서 실행 중인 Prometheus
이미지 갤러리 앱을 위한 사용자 지정 Prometheus 도커 이미지를 구축했습니다. Prometheus 팀이 도커 Hub에 게시한 공식 이미지를 기반으로 하며 내 구성 파일에 복사합니다(이 장의 소스 코드에서 Dockerfile을 찾을 수 있음). 이 접근 방식은 추가 구성 없이 실행할 수 있는 사전 구성된 Prometheus 이미지를 제공하지만 필요한 경우 다른 환경에서 구성 파일을 항상 재정의할 수 있습니다.
메트릭은 많은 컨테이너가 실행 중일 때 더 흥미롭습니다. 이미지 갤러리 앱의 Node.js 구성 요소를 확장하여 여러 컨테이너에서 실행할 수 있으며 Prometheus는 모든 컨테이너에서 메트릭을 수집하고 수집합니다.
Try exercise 폴더에 acess-log 서비스에 대한 임의의 포트를 게시하는 또 다른 docker-compose.yml 파일이 있으므로 해당 서비스를 대규모로 실행할 수 있습니다. 3개의 인스턴스로 실행하고 웹사이트에 부하를 더 보냅니다.
docker-compose -f docker-compose-scale.yml up -d --scale accesslog=3
# loop to make 10 HTTP GET request - on Linux:
for i in {1..10}; do curl http://localhost:8010 > /dev/null; done웹 사이트는 요청을 처리할 때마다 access-log 서비스를 호출합니다. 해당 서비스를 실행하는 컨테이너가 3개 있으므로 호출은 모두에서 로드 밸런싱되어야 합니다. 로드 밸런싱이 효과적으로 작동하는지 어떻게 확인할 수 있습니까? 해당 구성 요소의 메트릭에는 메트릭을 보내는 시스템의 호스트 이름을 캡처하는 레이블이 포함됩니다. 이 경우에는 컨테이너 ID입니다. Prometheus UI를 열고 access-log 메트릭을 확인하십시오. 세 가지 데이터 세트가 표시되어야 합니다.
TRY http://localhost:9090/graph로 이동합니다. 메트릭 드롭다운에서 access_log_total을 선택하고 실행을 클릭합니다.
그림 9.9에서 내 출력과 유사한 것을 볼 수 있습니다. 각 컨테이너에 대해 하나의 메트릭 값이 있고 레이블에는 호스트 이름이 포함됩니다. 각 컨테이너의 실제 값은 로드 밸런싱이 얼마나 고르게 분산되어 있는지 보여줍니다. 이상적인 시나리오에서는 수치가 같을 것이지만 많은 네트워크 요소(DNS 캐싱 및 HTTP 연결 유지 연결)가 작동하고 있습니다.
access_log_total{hostname="a",instance="172.31.0.7:80",job="access-log"} 4
access_log_total{hostname="b",instance="172.31.0.2:80",job="access-log"} 2
access_log_total{hostname="c",instance="172.31.0.6:80",job="access-log"} 3레이블로 추가 정보를 기록하는 것은 Prometheus의 가장 강력한 기능 중 하나입니다. 다양한 세부 수준에서 단일 메트릭으로 작업할 수 있습니다. 지금 당신은 가장 최근의 메트릭 값을 보여주는 각 컨테이너에 대한 테이블의 한 행과 함께 메트릭에 대한 원시 데이터를 보고 있습니다. sum() 쿼리를 사용하여 모든 컨테이너에 걸쳐 집계하여 개별 레이블을 무시하고 결합된 합계를 표시할 수 있으며 이를 그래프에 표시하여 시간이 지남에 따라 증가하는 사용량을 볼 수 있습니다.
TRY Prometheus UI에서 그래프 추가 버튼을 클릭하여 새 쿼리를 추가하십시오. 표현식 텍스트 상자에 다음 쿼리를 붙여넣습니다.
sum(access_log_total) without(hostname, instance)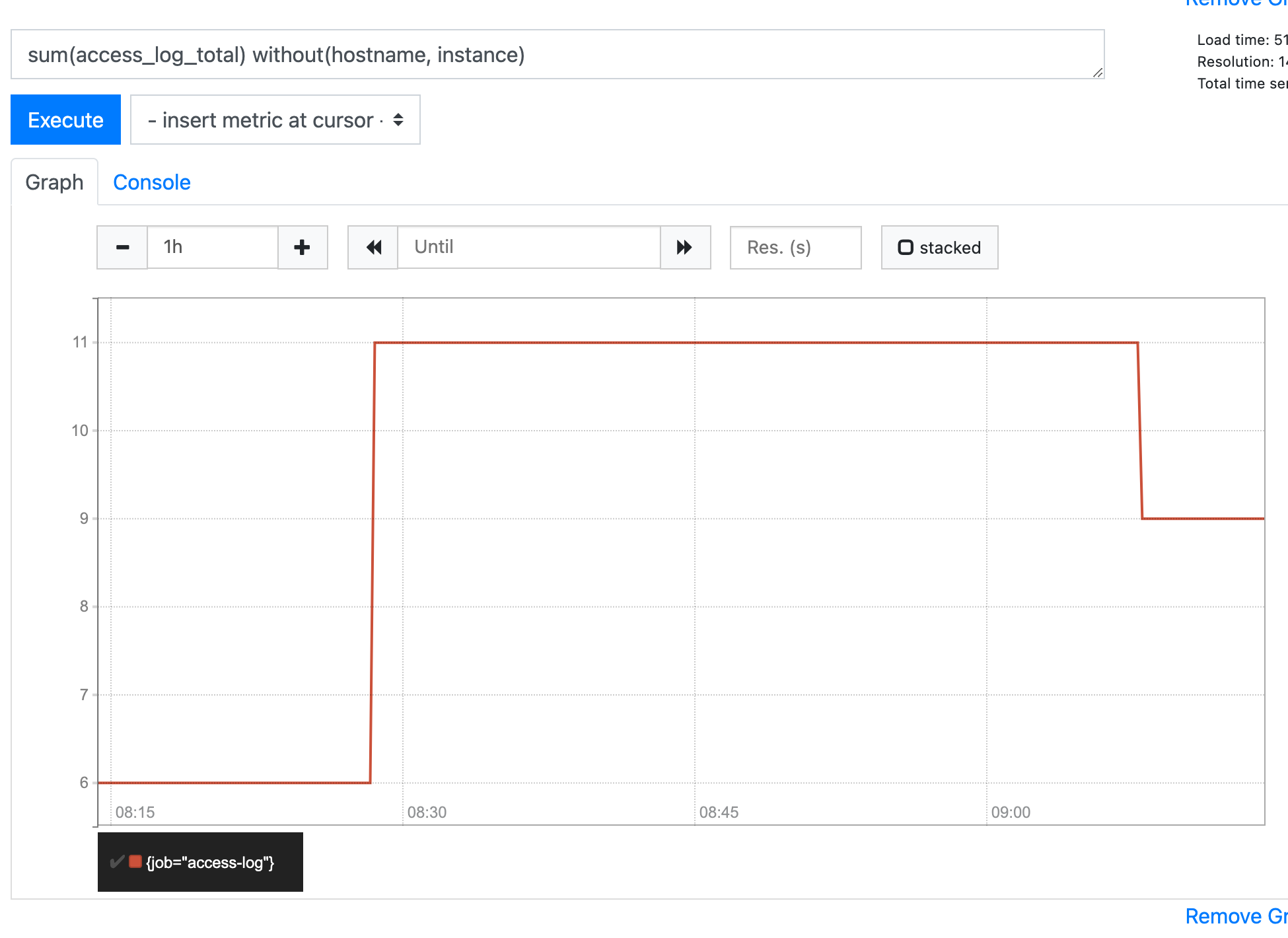
그림 9.10 모든 컨테이너의 값을 합산하기 위한 메트릭 집계 및 결과 그래프 표시
sum() 쿼리는 PromQL이라는 Prometheus의 자체 쿼리 언어로 작성되었습니다. 시간과 변화율에 따른 변경 사항을 쿼리할 수 있는 통계 기능이 있으며 하위 쿼리를 추가하여 다양한 메트릭을 연관시킬 수 있습니다. Prometheus 형식은 간단한 쿼리로 주요 메트릭을 시각화할 수 있을 정도로 잘 구성되어 있습니다. 레이블을 사용하여 값을 필터링하고 결과를 합산하여 집계할 수 있으며 이러한 기능만으로도 유용한 대시보드를 제공할 수 있습니다.
Prometheus UI는 구성을 확인하고 모든 스크래핑 대상에 도달할 수 있는지 확인하고 쿼리를 처리하는 데 적합합니다.
9.4 grafana 컨테이너를 실행하여 메트릭 시각화
모니터링은 컨테이너의 핵심 주제이기 때문에 이 장에서 많은 내용을 다루지만 더 자세한 세부 사항은 모두 앱에 매우 의존하기 때문에 빠르게 진행합니다. 캡처해야 하는 메트릭은 비즈니스 및 운영 요구 사항에 따라 다르며 캡처 방법은 사용 중인 앱 런타임과 해당 런타임에 대한 Prometheus 라이브러리의 메커니즘에 따라 다릅니다.
Prometheus에 데이터가 있으면 일이 더 간단해집니다. Prometheus UI를 사용하여 기록 중인 메트릭을 탐색하고 보고 싶은 데이터를 얻기 위한 쿼리 작업을 수행합니다. 그런 다음 Grafana를 실행하고 해당 쿼리를 대시보드에 연결합니다. 각 데이터 포인트는 사용자에게 친숙한 시각화로 표시되며 대시보드는 전체적으로 앱에서 어떤 일이 일어나고 있는지 보여줍니다.
이 챕터 내내 image-gallery 앱을 위한 grafana 대시보드를 만들기 위해 노력했으며 그림 9.12는 최종 결과를 보여줍니다. 모든 앱 구성 요소와 도커 런타임의 핵심 정보를 표시하는 매우 깔끔한 방법입니다. 이러한 쿼리는 규모를 지원하도록 구축되어 있으므로 프로덕션 클러스터에서 동일한 대시보드를 사용할 수 있습니다.
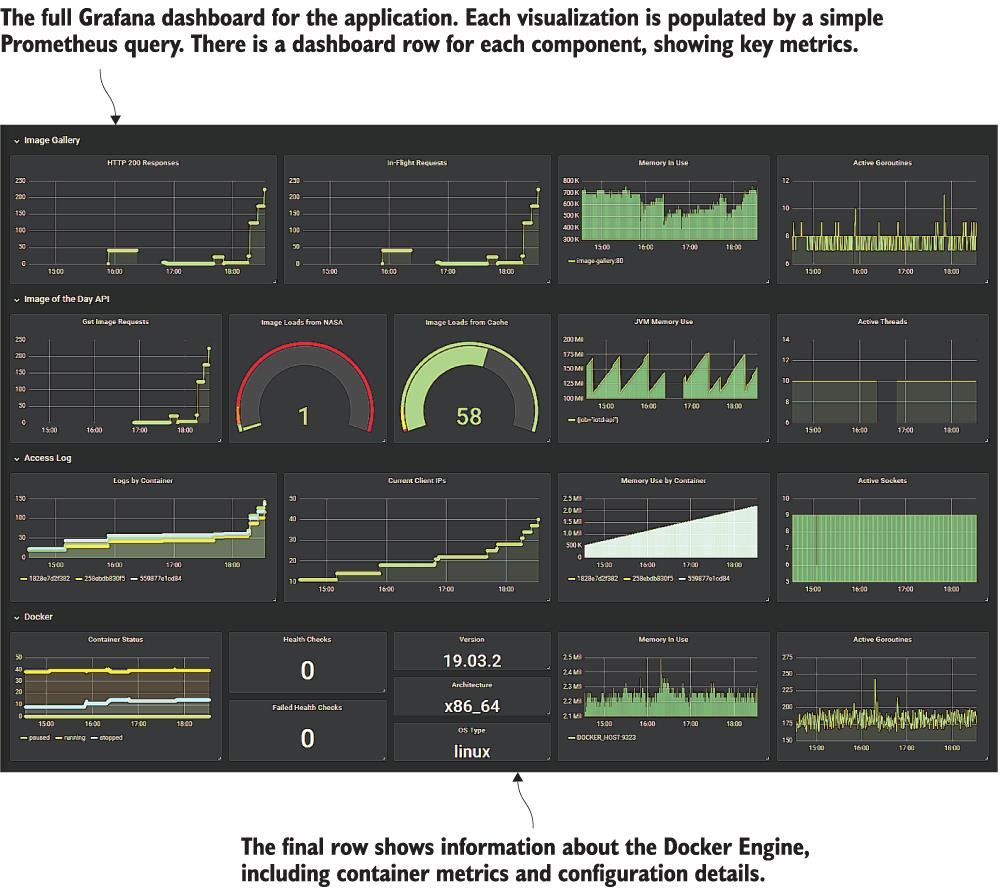
그림 9.12 Grafana 대시보드
grafana 대시보드는 다양한 수준으로 정보를 전달합니다. 각 시각화는 PromQL 쿼리로 구동되며 어떤 쿼리도 필터링 및 집계보다 더 복잡한 작업을 수행하지 않습니다. 그림 9.12의 축소된 보기는 전체 그림을 제공하지 않지만 컨테이너에서 직접 실행하고 탐색할 수 있도록 대시보드를 사용자 지정 Grafana 이미지로 패키징했습니다.
TRY 이번에는 docker-compose 파일이 찾아서 Prometheus 컨테이너에 주입하는 환경 변수로 컴퓨터의 IP 주소를 다시 캡처해야 합니다. 그런 다음 docker-compose로 앱을 실행하고 약간의 부하를 생성합니다.
# load your machine's IP address into an environment variable - on Linux:
export HOST_IP=$(ip route get 1 | awk '{print $NF;exit}')
# or on Mac:
hostIP=$(ifconfig en0 | grep -e 'inet\s' | awk '{print $2}')
# run the app with a Compose file
docker-compose -f ./docker-compose-with-grafana.yml up -d --scale accesslog=3
# now send in some load to prime the metrics - on Linux:
for i in {1..20}; do curl http://localhost:8010 > /dev/null; donebrowse to http://localhost:3000
Grafana는 웹 UI에 포트 3000을 사용합니다. 처음 탐색할 때 로그인해야 합니다. 자격 증명은 사용자 이름 admin , 암호 admin 입니다. 처음 로그인할 때 관리자 비밀번호를 변경하라는 메시지가 표시되지만 대신 건너뛰기를 클릭해도 판단하지 않겠습니다. UI가 로드되면 "홈" 대시보드가 표시됩니다. 왼쪽 상단의 홈 링크를 클릭하면 그림 9.13과 같은 대시보드 목록이 표시됩니다. 이미지 갤러리를 클릭하여 앱 대시보드를 로드합니다.
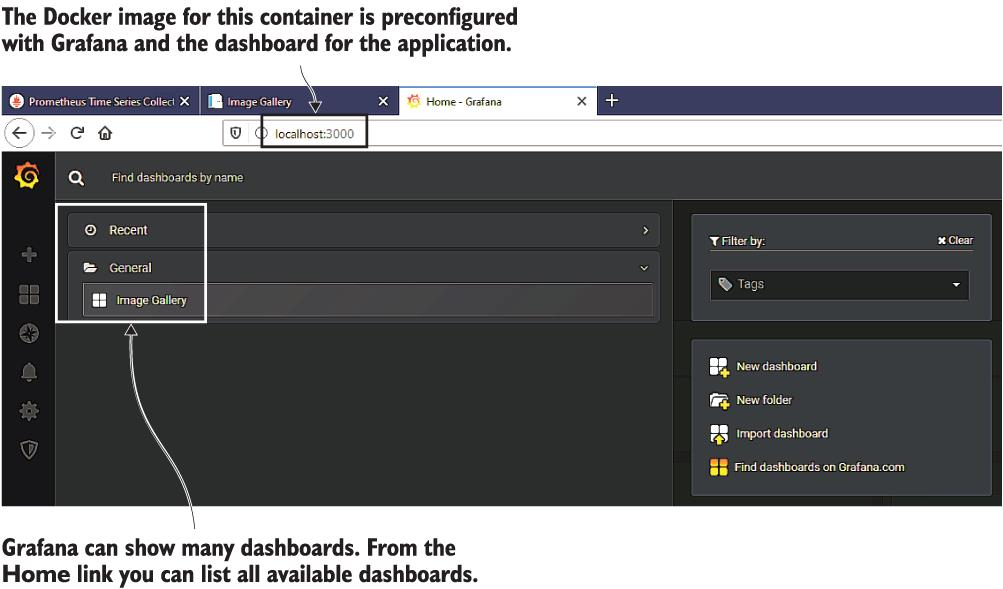
그림 9.13 Grafana에서 대시보드 탐색 - 최근에 사용한 폴더가 여기에 표시됩니다.
앱에 대한 대시보드는 프로덕션 시스템에 적합한 설정입니다. 올바른 모니터링을 위해 필요한 몇 가지 주요 데이터 포인트가 있습니다. Google은 사이트 안정성 엔지니어링에서 이에 대해 설명합니다. 그들의 초점은 "황금 신호"라고 부르는 대기 시간, 트래픽, 오류 및 포화에 있습니다.
기본 쿼리와 올바른 시각화 선택을 통해 스마트 대시보드를 구축할 수 있음을 확인할 수 있도록 첫 번째 시각화 세트를 자세히 살펴보겠습니다. 그림 9.14는 이미지 갤러리 웹 UI의 메트릭 행을 보여줍니다. 보기 쉽도록 행을 잘랐지만 대시보드에서 동일한 행에 나타납니다.
시스템이 얼마나 많이 사용되고 있으며 시스템이 해당 수준의 사용을 지원하기 위해 얼마나 열심히 노력하고 있는지를 보여주는 4가지 메트릭이 있습니다.
- HTTP 200 응답 --시간이 지남에 따라 웹 사이트에서 보낸 HTTP "OK" 응답 수에 대한 간단한 계산입니다. PromQL 쿼리는 앱의 카운터 메트릭에 대한 합계입니다.
sum(image_gallery_requests_total{code="200"}) without(instance)code="500"에 대한 쿼리 필터링이 있는 유사한 그래프를 추가하여 오류 수를 표시할 수 있습니다.
-
진행 중인 요청 -- 주어진 시점의 활성 요청 수를 표시합니다. Prometheus 게이지라서 오르락 내리락 할 수 있습니다. 이에 대한 필터가 없으며 그래프는 모든 컨테이너의 합계를 표시하므로 쿼리는 다른 합계인
sum(image_gallery_in_flight_requests) without(instance)입니다. -
사용 중인 메모리 -- 이미지 갤러리 컨테이너가 사용 중인 시스템 메모리의 양을 보여줍니다. 이것은 이러한 유형의 데이터에 대해 더 쉽게 볼 수 있는 막대 차트입니다. 웹 구성 요소를 확장할 때 각 컨테이너에 대한 막대가 표시됩니다. PromQL 쿼리는 작업 이름에 대해 필터링합니다.
go_memstats_stack_inuse_bytes{job="image-gallery"}이것이 표준 Go 메트릭이고 도커 엔진 작업이 동일한 이름의 메트릭을 반환하기 때문에 필터가 필요합니다.
- 활성 Go루틴 - 구성 요소가 얼마나 열심히 작동하는지에 대한 대략적인 지표 --Go루틴은 Go의 작업 단위이며 많은 것이 동시에 실행될 수 있습니다. 이 그래프는 웹 구성 요소에 갑자기 처리 활동이 급증하는 경우를 보여줍니다. 또 다른 표준 Go 메트릭이므로 PromQL 쿼리는 웹 작업에서 통계를 필터링하고 합계합니다.
sum(go_goroutines{job=\"image-gallery\"}) without(instance)대시보드의 다른 행에 있는 시각화는 모두 유사한 쿼리를 사용합니다. 복잡한 PromQL이 필요하지 않습니다. 표시할 올바른 메트릭을 선택하고 이를 표시할 올바른 시각화만 있으면 됩니다.
이러한 시각화에서 실제 값은 추세보다 덜 유용합니다. 내 웹 앱이 평균적으로 200MB의 메모리를 사용하는지 800MB를 사용하는지 여부는 그다지 중요하지 않습니다. 구성 요소에 대한 메트릭 세트는 이상을 빠르게 확인하고 상관 관계를 찾는 데 도움이 됩니다. 오류 응답 그래프가 상승 추세에 있고 활성 Go루틴 수가 몇 초마다 두 배로 증가하는 경우 문제가 있는 것이 분명합니다. 구성 요소가 포화 상태일 수 있으므로 처리하기 위해 더 많은 컨테이너로 확장해야 할 수도 있습니다.
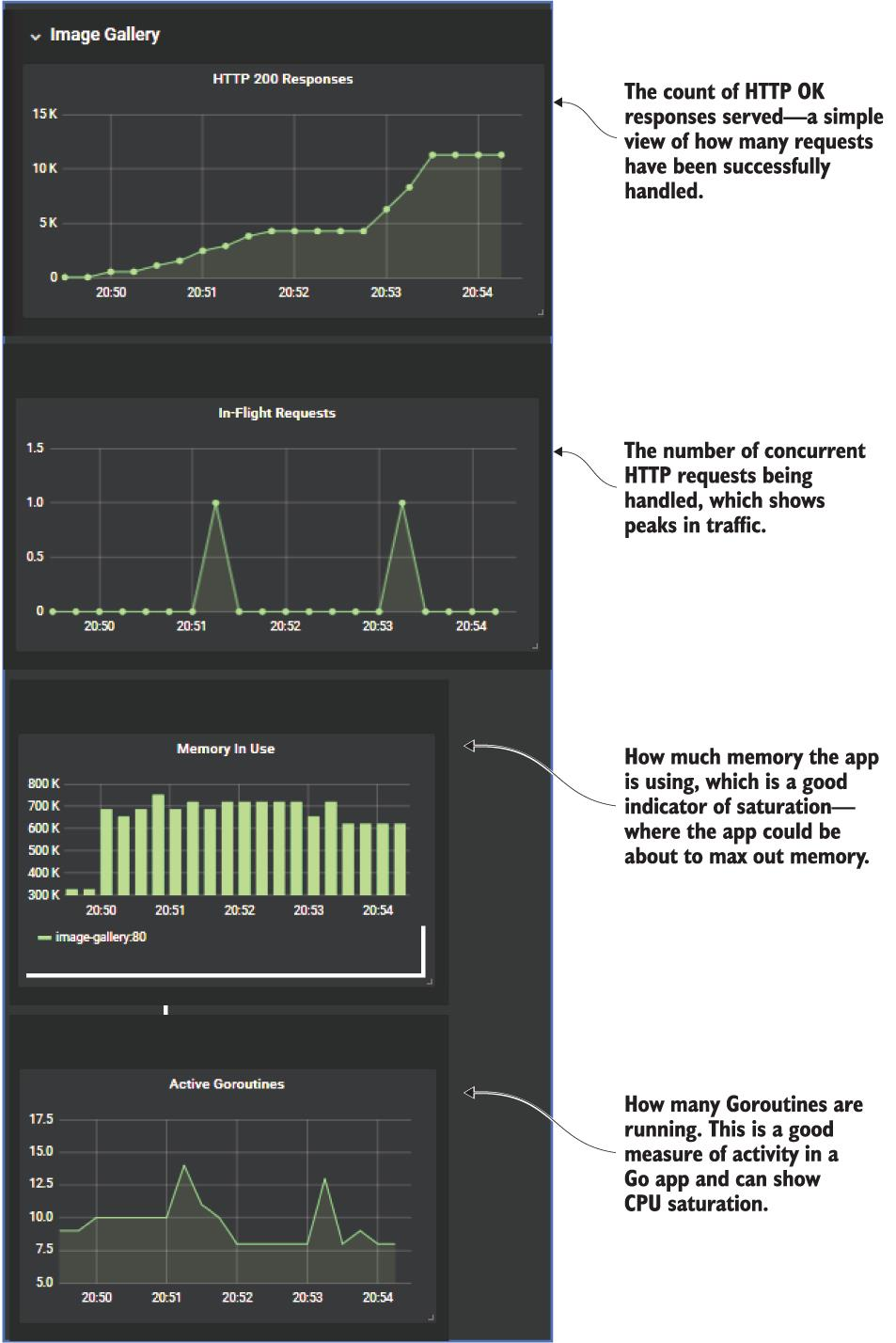
그림 9.14 대시보드 자세히 살펴보기 및 시각화가 황금 신호와 관련되는 방식
Grafana는 매우 강력한 도구이지만 사용하기 쉽습니다. 최신 앱에서 가장 널리 사용되는 대시보드 시스템이므로 학습할 가치가 있습니다. 다양한 데이터 소스를 쿼리할 수 있고 다른 시스템에도 경고를 보낼 수 있습니다. 대시보드 작성은 기존 대시보드 편집과 동일합니다. 시각화(패널이라고 함)를 추가 또는 편집하고 크기를 조정하고 이동할 수 있으며 대시보드를 파일에 저장할 수 있습니다.
TRY Google SRE 접근 방식은 HTTP 오류 수가 핵심 메트릭이며 대시보드에는 없으므로 지금 image-gallery 행에 추가합니다. 앱이 실행되고 있지 않은 경우 다시 실행하고 http://locahost:3000으로 Grafana로 이동한 다음 username은 admin이고 password는admin 으로 로그인합니다.
image-gallery 대시보드를 열고 화면 오른쪽 상단에 있는 패널 추가 아이콘을 클릭합니다. 그림 9.15와 같이 더하기 기호가 있는 막대 차트입니다.
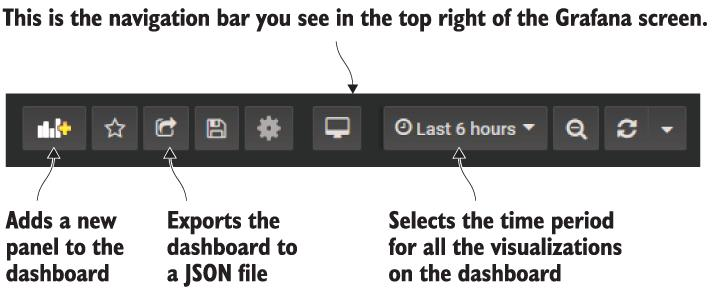
그림 9.15 패널 추가, 기간 선택, 대시보드 저장을 위한 Grafana 도구 모음
이제 새 패널 창에서 Add Query를 클릭하면 시각화의 모든 세부 정보를 캡처할 수 있는 화면이 표시됩니다. 쿼리의 데이터 소스로 Prometheus를 선택하고 메트릭 필드에 다음 표현식을 붙여넣습니다.
sum(image_gallery_requests_total{code="500"}) without(instance)귀하의 패널은 그림 9.16에서와 같이 보일 것입니다. 이미지 갤러리 앱은 시간의 약 10%에 오류 응답을 반환하므로 충분한 요청을 하면 그래프에 일부 오류가 표시됩니다.
Esc 키를 눌러 기본 대시보드로 돌아갑니다.
오른쪽 하단 모서리를 끌어 패널의 크기를 조정할 수 있으며 제목을 끌어 패널을 이동할 수 있습니다. 대시보드가 원하는 대로 표시되면 tool 패널에서 Share Dashboard 아이콘을 클릭할 수 있습니다(그림 9.15 다시 참조). 여기에서 대시보드를 JSON 파일로 내보낼 수 있는 옵션이 있습니다.
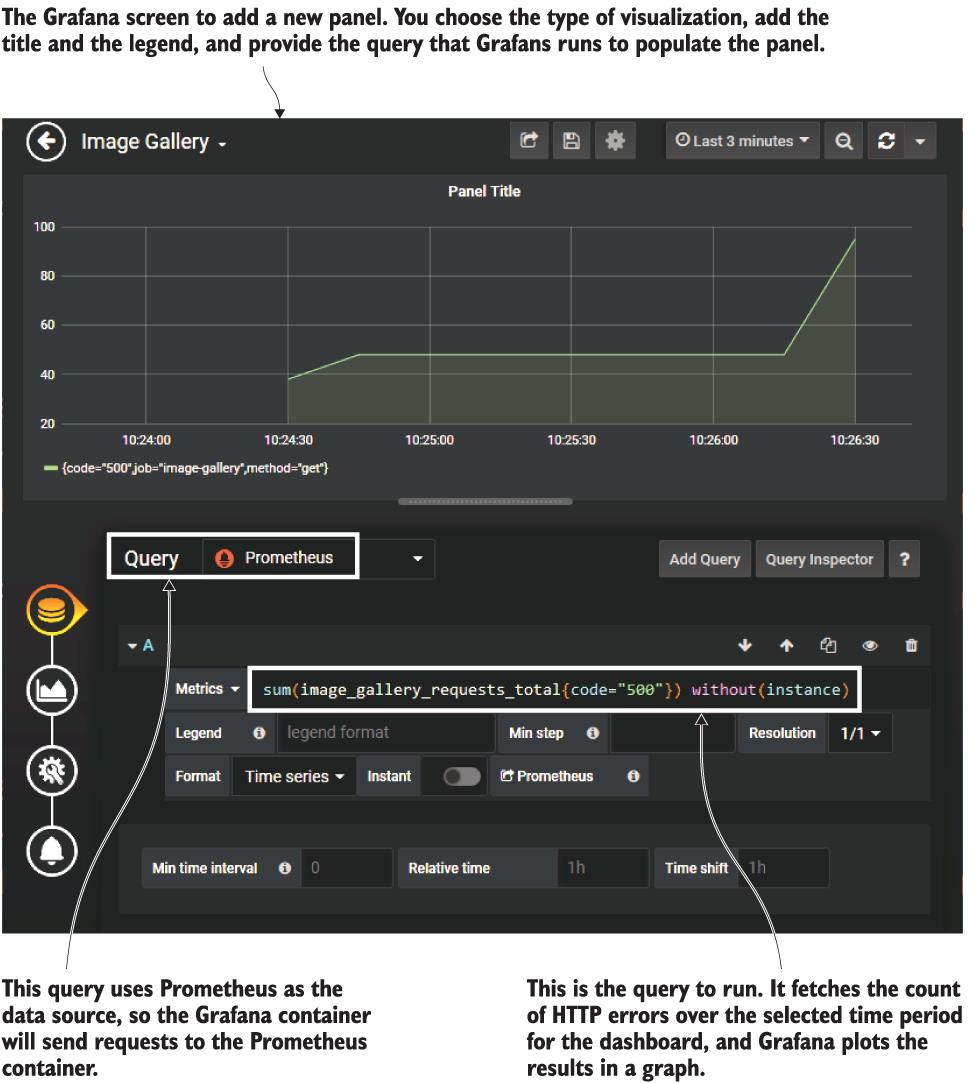
그림 9.16 HTTP 오류를 표시하기 위해 Grafana 대시보드에 새 패널 추가
Grafana의 마지막 단계는 Prometheus를 데이터 소스로 사용하고 앱 대시보드로 이미 구성된 자체 이미지를 패키징하는 것입니다. 목록 9.3은 전체 Dockerfile을 보여줍니다.
목록 9.3 사용자 지정 Grafana 이미지를 패키징하는 Dockerfile
FROM diamol/grafana:6.4.3
COPY datasource-prometheus.yaml ${GF_PATHS_PROVISIONING}/datasources/
COPY dashboard-provider.yaml ${GF_PATHS_PROVISIONING}/dashboards/
COPY dashboard.json /var/lib/grafana/dashboards/이미지는 특정 버전의 Grafana에서 시작한 다음 YAML 및 JSON 파일 세트로 복사합니다. Grafana는 이 책에서 이미 홍보한 구성 패턴을 따릅니다. 기본 구성이 몇 가지 내장되어 있지만 직접 적용할 수 있습니다. 컨테이너가 시작되면 Grafana는 특정 폴더에서 파일을 찾고 찾은 모든 구성 파일을 적용합니다. YAML 파일은 Prometheus 연결을 설정하고 /var/lib/Grafana/dashboards 폴더에 있는 모든 대시보드를 로드합니다. 마지막 줄은 내 대시보드 JSON을 해당 폴더에 복사하므로 컨테이너가 시작될 때 로드됩니다.
Grafana 프로비저닝으로 훨씬 더 많은 작업을 수행할 수 있으며 API를 사용하여 사용자를 만들고 기본 설정을 지정할 수도 있습니다. 여러 대시보드와 Grafana 재생 목록에 함께 넣을 수 있는 모든 대시보드에 액세스할 수 있는 읽기 전용 사용자가 있는 Grafana 이미지를 구축하는 것은 훨씬 더 많은 작업이 아닙니다. 그런 다음 사무실의 큰 화면에서 Grafana를 탐색하고 모든 대시보드에서 자동으로 순환되도록 할 수 있습니다.
9.5 관찰 가능성 수준의 이해
관찰 가능성은 단순한 개념 증명 컨테이너에서 생산 준비로 이동할 때 핵심 요구 사항입니다. 하지만 이 장에서 내가 Prometheus와 Grafana를 소개한 또 다른 아주 좋은 이유가 있습니다. Docker를 배우는 것은 Dockerfiles와 Compose 파일의 역학에 관한 것만이 아닙니다. Docker의 마법 중 일부는 컨테이너를 중심으로 성장한 거대한 생태계와 해당 생태계를 중심으로 출현한 패턴입니다.
컨테이너가 처음 대중화되었을 때 모니터링은 정말 골치 아픈 일이었습니다. 당시 내 프로덕션 릴리스는 오늘날처럼 쉽게 구축 및 배포할 수 있었지만 실행 중일 때는 앱에 대한 통찰력이 없었습니다. 내 API가 여전히 작동하는지 확인하기 위해 Pingdom과 같은 외부 서비스에 의존해야 했고 앱이 올바르게 작동하는지 확인하기 위해 사용자 보고에 의존해야 했습니다. 오늘날 컨테이너 모니터링에 대한 접근 방식은 검증되고 신뢰할 수 있는 방법입니다. 우리는 이 장에서 그 경로를 따랐고 그림 9.17에 접근 방식이 요약되어 있습니다.
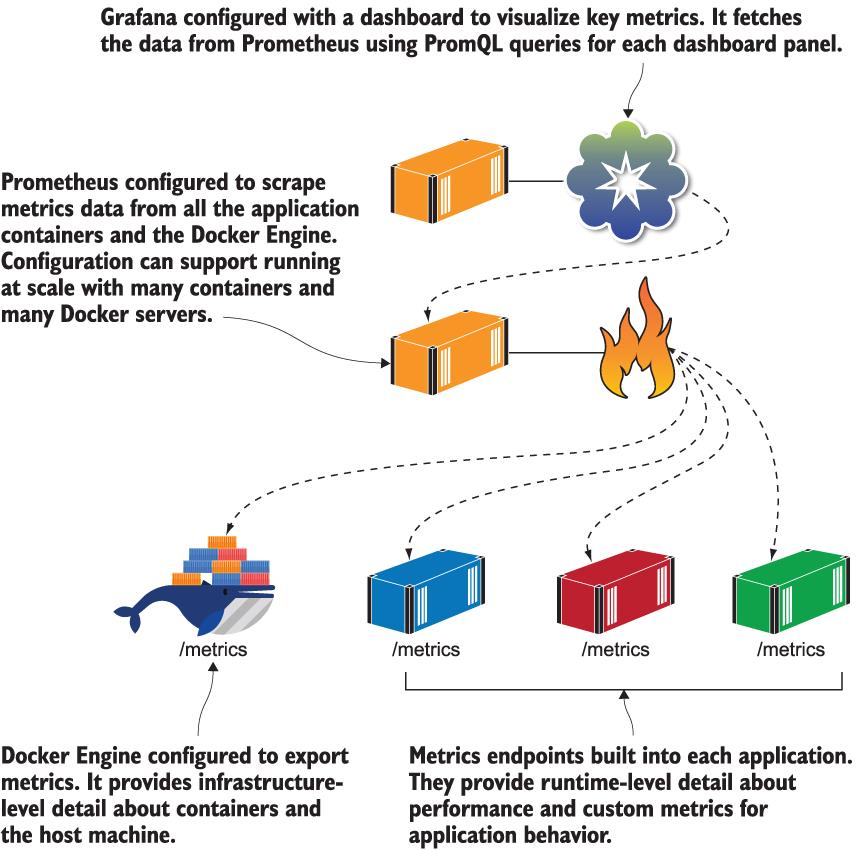
그림 9.17 컨테이너화된 앱의 모니터링 아키텍처
앱의 전체 보기인 image-gallery 앱의 대시보드를 살펴보았습니다. 프로덕션 환경에는 추가 수준의 세부 정보를 제공하는 대시보드가 있습니다. 모든 서버에 대한 여유 디스크 공간, 사용 가능한 CPU, 메모리 및 네트워크 포화도를 보여주는 인프라 대시보드가 있습니다. 각 구성 요소에는 웹 앱의 각 페이지 또는 각 API 끝점을 제공하기 위한 응답 시간 분석과 같은 추가 정보를 표시하는 자체 대시보드가 있을 수 있습니다.
종합 대시보드는 중요합니다. 앱 메트릭에서 가장 중요한 모든 데이터 포인트를 한 화면으로 모아서 문제가 있는지 한 눈에 파악하고 더 나빠지기 전에 회피 조치를 취할 수 있어야 합니다.
9.6 Lab
이 장에서는 이미지 갤러리 앱에 모니터링을 추가했으며 이 실습에서는 할 일 목록 앱에도 동일한 작업을 수행하도록 요청합니다. 소스 코드에 뛰어들 필요가 없습니다. 이미 Prometheus 메트릭이 포함된 앱 이미지의 새 버전을 구축했습니다. diamol/ch09-todo-list 에서 컨테이너를 실행하고 앱을 찾아 일부 항목을 추가하면 /metrics URL에서 사용 가능한 메트릭을 볼 수 있습니다. 랩의 경우 이미지 갤러리와 동일한 위치에 해당 앱을 가져오려고 합니다.
-
Prometheus 컨테이너와 Grafana 컨테이너도 시작하는 앱을 실행하는 데 사용할 수 있는 Compose 파일을 작성합니다.
-
Prometheus 컨테이너는 할 일 목록 앱에서 메트릭을 스크랩하도록 이미 구성되어 있어야 합니다.
-
Grafana 컨테이너는 앱에서 생성된 작업 수, 처리된 총 HTTP 요청 수, 현재 처리 중인 HTTP 요청 수의 세 가지 주요 메트릭을 표시하는 대시보드로 구성되어야 합니다.
이것은 많은 작업처럼 들리지만 실제로는 그렇지 않습니다. 이 장의 연습에서는 모든 세부 사항을 다룹니다. 새로운 응용 프로그램에 대한 메트릭 작업 경험을 제공하기 때문에 작업하기에 좋은 실습입니다.
