1. 마이크로서비스 소개
This book does not blindly praise microservices. Instead, it's about how we can use their benefits while being able to handle the challenges of building scalable, resilient, and manageable microservices.
As an introduction to this book, the following topics will be covered in this chapter:
- 마이크로서비스 경험
- 마이크로서비스 아키텍처
- 마이크로서비스에서 어려운 점
- 디자인 패턴
Software enablers that can help us handle these challenges
Other important considerations that aren't covered in this book
1.1 내 방식
When I first learned about the concept of microservices back in 2014, I realized that I had been developing microservices (well, kind of) for a number of years without knowing it was microservices I was dealing with. I was involved in a project that started in 2009 where we developed a platform based on a set of separated features. The platform was delivered to a number of customers that deployed it on-premises. To make it easy for customers to pick and choose what features they wanted to use from the platform, each feature was developed as an autonomous software component; that is, it had its own persistent data and only communicated with other components using well-defined APIs.
Since I can't discuss specific features in this project's platform, I have generalized the names of the components, which are labeled from Component A to Component F. The composition of the platform into a set of components is illustrated as follows:
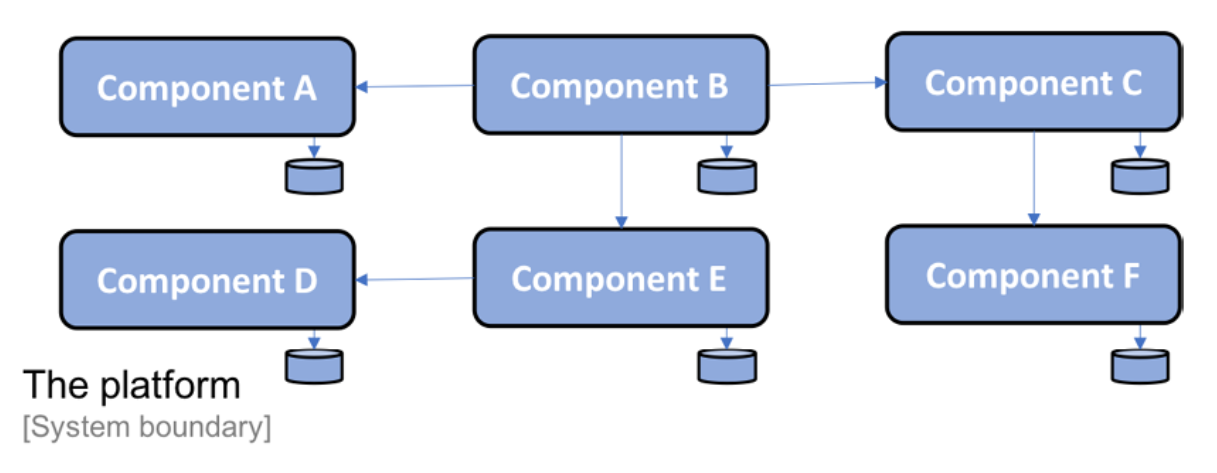
Figure 1.1: The composition of the platform
각 컴포넌트는 자체의 스토리지가 있으며 서로 간에 데이터베이스를 공유하지 않습니다.
컴포넌트는 자바와 스프링을 사용하여 개발되었고 WAR로 패키징하여 웹 컨테이너에 배포하였습니다.
고객의 요구에 따라 하나 또는 그 이상의 서버에 배포되었습니다.
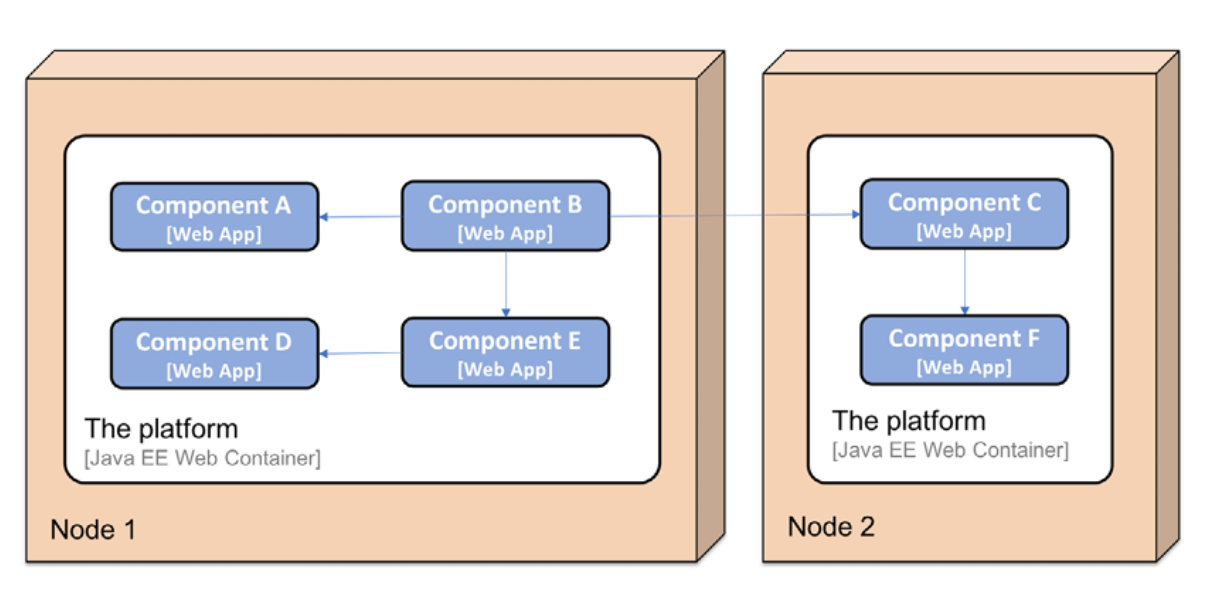
Figure 1.2: A two-node deployment scenario
1.2 자급 컴포넌트의 장점
From this project, I learned that decomposing the platform's functionality into a set of autonomous software components provides a number of benefits:
- A customer can deploy parts of the platform in its own system landscape, integrating it with its existing systems using its well-defined APIs.
The following is an example where one customer decided to deploy Component A, Component B, Component D, and Component E from the platform and integrate them with two existing systems in the customer's system landscape, System A and System B:
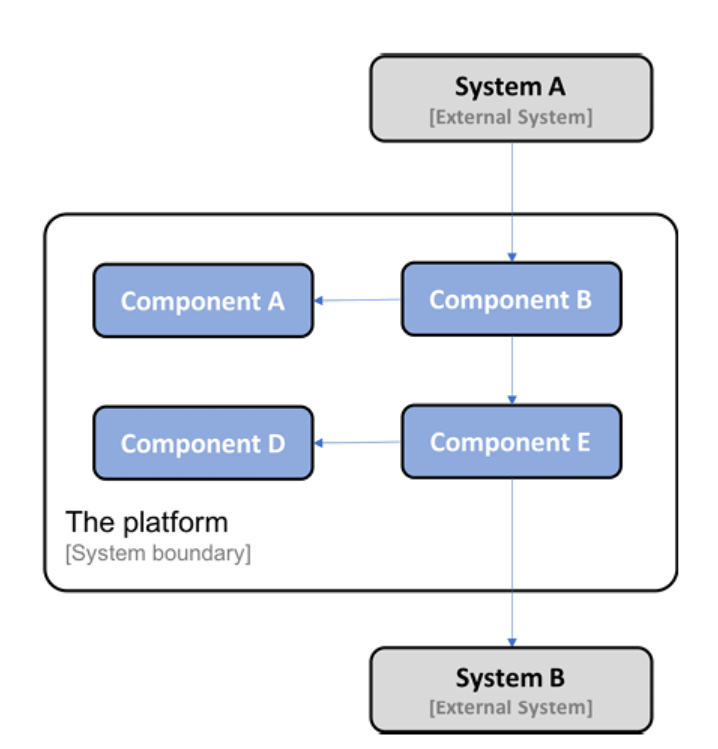
Figure 1.3: 플랫폼 부분 배포
- Another customer can choose to replace parts of the platform's functionality with implementations that already exist in the customer's system landscape, potentially requiring some adoption of the existing functionality in the platform's APIs. The following is an example where a customer has replaced Component C and Component F in the platform with their own implementation:
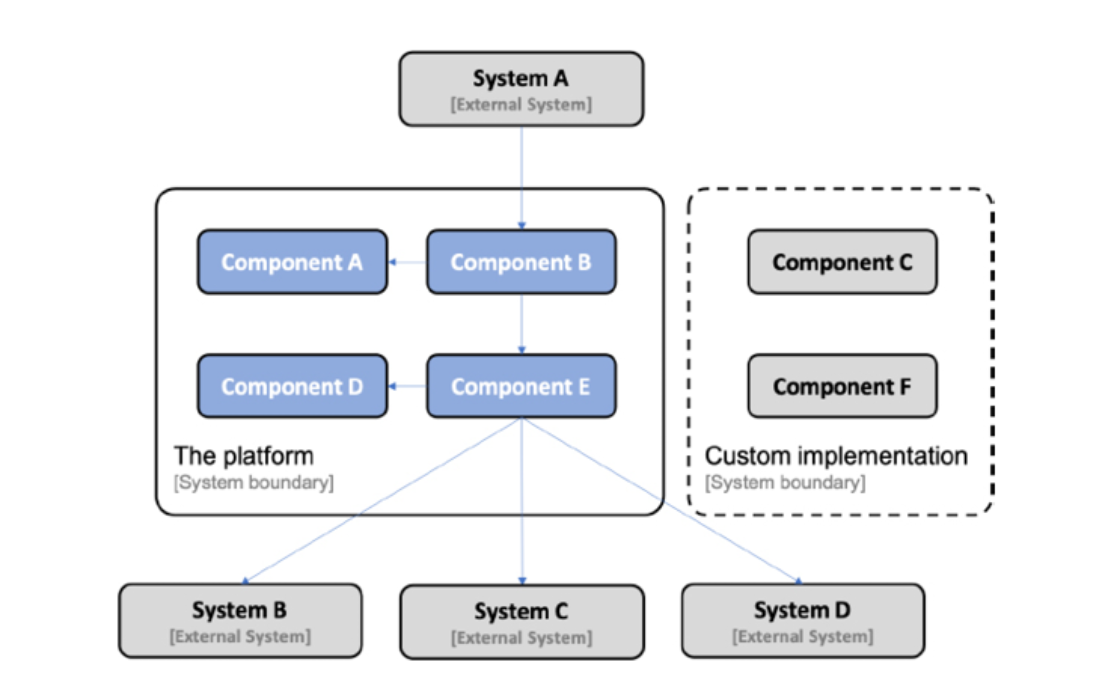
Figure 1.4: 부분 교체
- Each component in the platform can be delivered and upgraded separately. Thanks to the use of well-defined APIs, one component can be upgraded to a new version without being dependent on the life cycle of the other components.
The following is an example where Component A has been upgraded from version v1.1 to v1.2. Component B, which calls Component A, does not need to be upgraded since it uses a well-defined API; that is, it's still the same after the upgrade (or it's at least backward-compatible):
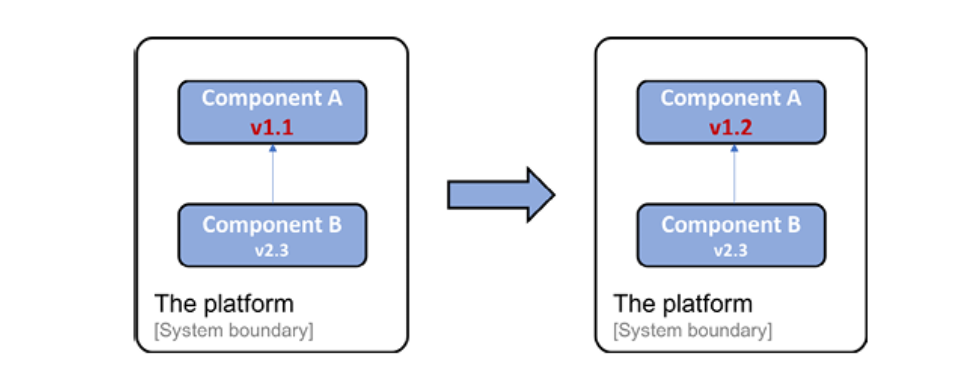
Figure 1.5: Upgrading a specific component
- Thanks to the use of well-defined APIs, each component in the platform can also be scaled out to multiple servers independently of the other components. Scaling can be done either to meet high availability requirements or to handle higher volumes of requests. In this specific project, it was achieved by manually setting up load balancers in front of a number of servers, each running a Java EE web container. An example where Component A has been scaled out to three instances looks as follows:
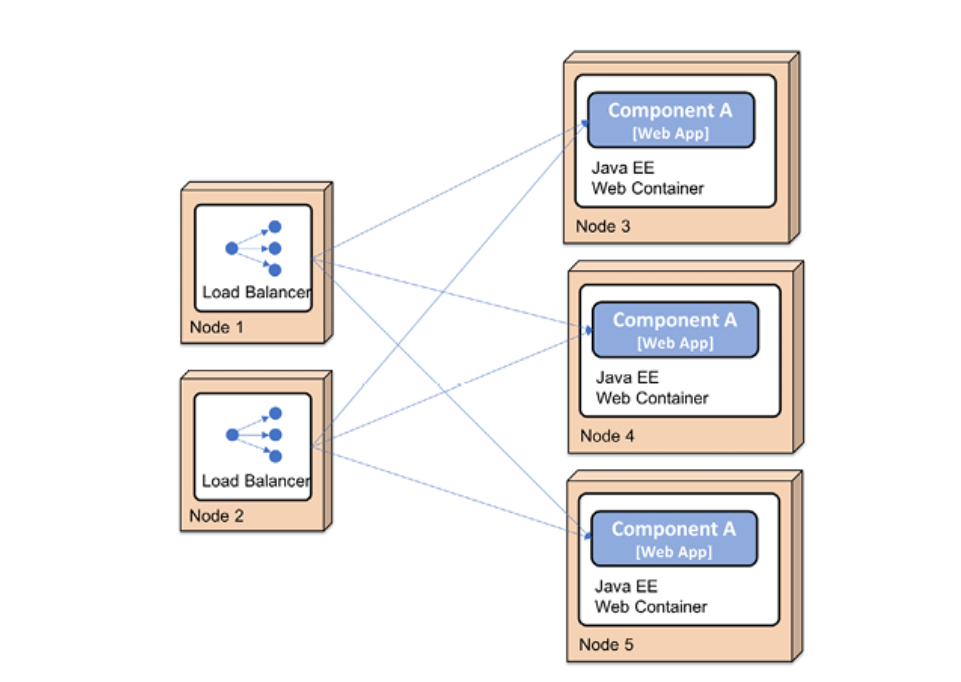
Figure 1.6: Scaling out the platform
자율 컴포넌트의 과제
플랫폼의 분해는 단일 애플리케이션 개발할 때와 색다른 도전이 생깁니다(같은 등급은 아니지만)
-
컴포넌트에 새로운 인스턴스를 추가하면 수동으로 로드 밸런스를 구성해야 하며 새로운 노드를 수동 설정이 필요합니다.
-
플랫폼은 처음에 통신하고 있던 다른 시스템으로 인해 오류가 발생하기 쉬웠습니다. 시스템이 플랫폼에서 전송된 요청에 대한 응답을 적시에 중단하면 플랫폼은 특히 많은 동시 요청에 노출되었을 때 OS 스레드와 같은 중요한 리소스가 빠르게 고갈되었습니다. 이로 인해 플랫폼의 구성 요소가 중단되거나 충돌이 발생했습니다. 플랫폼에서 대부분의 통신은 동기식 통신을 기반으로 하기 때문에 하나의 구성 요소가 충돌하면 계단식 오류가 발생할 수 있습니다. 즉, 충돌하는 구성 요소의 클라이언트도 잠시 후에 충돌할 수 있습니다. 이것을 연쇄적 실패라고 합니다.
-
구성 요소의 모든 인스턴스에서 구성을 일관되고 최신 상태로 유지하는 것이 빠르게 문제가 되어 많은 수작업과 반복 작업이 발생했습니다. 이로 인해 때때로 품질 문제가 발생했습니다.
-
지연 문제 및 하드웨어 사용량(예: CPU, 메모리, 디스크 및 네트워크 사용량) 측면에서 플랫폼 상태를 모니터링하는 것은 모놀리식 애플리케이션의 단일 인스턴스를 모니터링하는 것보다 더 복잡했습니다.
-
분산된 여러 구성 요소에서 로그 파일을 수집하고 구성 요소에서 관련 로그 이벤트를 연결하는 것도 어려웠지만 구성 요소의 수가 미리 정해져 있고 알려져 있었기 때문에 가능했습니다.
시간이 지남에 따라 우리는 자체 개발 도구와 이러한 문제를 수동으로 처리하기 위한 잘 문서화된 지침을 혼합하여 앞의 목록에서 언급한 대부분의 문제를 해결했습니다. 작업 규모는 일반적으로 구성 요소의 새 버전을 릴리스하고 런타임 문제를 처리하기 위한 수동 절차가 바람직하지 않더라도 수용 가능한 수준이었습니다.
마이크로서비스 진입
2014년에 마이크로서비스 기반 아키텍처에 대해 알게 되면서 다른 프로젝트에서도 비슷한 문제로 어려움을 겪고 있다는 사실을 깨닫게 되었습니다. 많은 마이크로서비스 개척자들이 터득한 교훈에서 배우는 것은 매우 흥미로웠습니다.
처음에는 비즈니스 관점에서 매우 성공적으로 앱을 개발했으나 시간이 지남에 따라 이들을 유지 관리하고 발전시키기가 점점 더 어려워졌습니다. 또한 사용 가능한 가장 큰 기계의 기능 이상으로 확장하는 것이 어려워졌습니다(수직 확장이라고도 함). 결국, 개척자들은 모놀리식 애플리케이션을 서로 독립적으로 릴리스 및 확장할 수 있는 더 작은 구성 요소로 분할하는 방법을 찾기 시작했습니다. 소규모 구성 요소의 확장은 수평적 확장을 사용하여 수행할 수 있습니다. 즉, 여러 개의 소규모 서버에 구성 요소를 배포하고 그 앞에 로드 밸런서를 배치합니다. 클라우드에서 수행하는 경우 확장 기능은 잠재적으로 무한합니다. 가져오는 가상 서버 수의 문제일 뿐입니다.
2014년에는 마이크로서비스 개발을 단순화하고 마이크로서비스 기반 아키텍처와 함께 발생하는 문제를 처리하는 데 사용할 수 있는 도구와 프레임워크를 제공하는 여러 새로운 오픈 소스 프로젝트에 대해서도 배웠습니다.
-
Pivotal은 동적 서비스 검색, 구성 관리, 분산 추적, 회로 차단 등과 같은 기능을 제공하기 위해 Netflix OSS의 일부를 래핑하는 Spring Cloud를 출시했습니다. -
Docker와 컨테이너 혁명에 대해서도 배웠습니다. 구성 요소를 배포 가능한 런타임으로 패키징할 수 있을 뿐만 아니라 Docker를 실행하는 서버에서 컨테이너로 실행할 준비가 된 완전한 이미지로 패키징할 수 있다는 것은 개발을 위한 큰 진전이었습니다.
지금은 컨테이너를 격리된 프로세스로 생각하십시오. 4장, 도커를 사용하여 마이크로서비스 배포에서 컨테이너에 대해 자세히 알아볼 것입니다.
-
Docker와 같은 컨테이너 엔진은 프로덕션 환경에서 컨테이너를 사용하기에 충분하지 않습니다. 모든 컨테이너가 제대로 실행되고 있는지 확인하고 여러 서버에서 컨테이너를 확장하여 고가용성과 향상된 컴퓨팅 리소스를 제공할 수 있는 무언가가 필요합니다.
-
컨테이너 오케스트레이터로는
Apache Mesos,Swarm 모드의 Docker,Amazon ECS,HashiCorp Nomad및Kubernetes와 같은 많은 제품이 지난 몇 년 동안 발전했습니다. Kubernetes는 처음에 Google에서 개발했습니다. Google은 2015년 v1.0을 출시할 때 Kubernetes도 CNCF(https://www.cncf.io/)에 기부했습니다. 2018년 동안 Kubernetes는 온프레미스 사용을 위해 사전 패키징되어 대부분의 주요 클라우드 제공업체의 서비스로 제공되는 일종의 사실상 표준이 되었습니다.
Kubernetes에서 설명한 것처럼 Kubernetes는 Kubernetes 프로젝트가 설립되기 10년 이상 동안 Google에서 실제로 사용된 Borg라는 내부 컨테이너 오케스트레이터의 오픈 소스 기반 재작성입니다.
- 2018년에 저는 서비스 mesh가 어떻게 컨테이너 오케스트레이터를 보완하여 마이크로서비스를 관리 가능하고 탄력적으로 만드는 책임에서 추가로 오프로드할 수 있는지 배우기 시작했습니다.
샘플 마이크로서비스 환경
이 책이 내가 방금 언급한 기술의 모든 측면을 다룰 수는 없기 때문에 2014년부터 참여한 고객 프로젝트에서 관리 가능하고 확장 가능하며 탄력적인 협력 마이크로서비스로서 유용하다고 입증된 부분에 초점을 맞출 것입니다.
이 책의 각 장에서는 특정 관심사를 다룰 것입니다. 모든 것이 어떻게 조화를 이루는지 보여주기 위해 이 책 전체에서 발전시킬 소규모 협력 마이크로서비스 세트를 사용할 것입니다. 마이크로서비스 환경은 3장, 협력 마이크로서비스 세트 생성에서 설명합니다. 지금은 다음과 같다는 것만 아는 것으로 충분합니다.
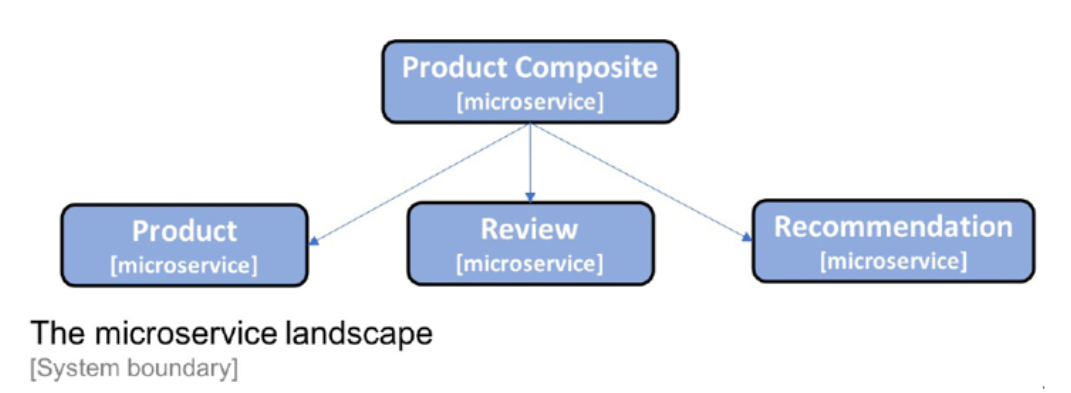
그림 1.7: 이 책에서 사용된 마이크로서비스 기반 시스템 환경
이것은 협력하는 마이크로서비스의 매우 작은 시스템 환경이라는 점에 유의하십시오. 다음 장에서 추가할 주변 지원 서비스는 이러한 소수의 마이크로 서비스에 대해 압도적으로 복잡해 보일 수 있습니다. 그러나 이 책에서 제시하는 솔루션은 훨씬 더 큰 시스템 환경을 지원하는 것을 목표로 합니다.
마이크로서비스의 잠재적인 이점과 과제에 대해 알아보았으므로 이제 마이크로서비스를 정의하는 방법을 살펴보겠습니다.
마이크로서비스 정의
마이크로 서비스 아키텍처는 모놀리식 애플리케이션을 더 작은 구성 요소로 분할하는 것으로 두 가지 주요 목표를 달성합니다.
- 더 빠른 개발, 지속적인 배포 가능
- 수동 또는 자동으로 쉽게 확장 가능
마이크로서비스는 기본적으로 독립적으로 업그레이드, 교체 및 확장 가능한 자율 소프트웨어 구성 요소입니다. 자율 구성 요소로 작동할 수 있으려면 다음과 같은 특정 기준을 충족해야 합니다.
-
비공유 아키텍처를 준수해야 합니다. 즉, 마이크로서비스는 데이터베이스의 데이터를 서로 공유하지 않습니다!
-
API 및 동기식 서비스를 사용하거나 가급적이면 비동기식으로 메시지를 전송하여 잘 정의된 인터페이스를 통해서만 통신해야 합니다. 사용되는 API 및 메시지 형식은 안정적이고 잘 문서화되어야 하며 정의된 버전 관리 전략에 따라 발전해야 합니다.
-
별도의 런타임 프로세스로 배포해야 합니다. 마이크로서비스의 각 인스턴스는 Docker 컨테이너와 같은 별도의 런타임 프로세스에서 실행됩니다.
-
마이크로서비스 인스턴스는 상태 비저장이므로 수신 요청을 해당 인스턴스에서 처리할 수 있습니다.
일련의 협력 마이크로서비스를 사용하면 모놀리식 애플리케이션을 배포할 때와 같이 단일 대형 서버에 강제로 배포하는 대신 여러 개의 소형 서버에 배포할 수 있습니다.
앞의 기준이 충족되었다는 점을 감안할 때 대규모 모놀리식 애플리케이션을 확장하는 것보다 단일 마이크로서비스를 더 많은 인스턴스로 확장하는 것이 더 쉽습니다(예: 더 많은 가상 서버 사용).
클라우드에서 사용할 수 있는 자동 크기 조정 기능을 활용하는 것도 가능하지만 일반적으로 대규모 모놀리식 애플리케이션에는 적합하지 않습니다. 또한 대규모 모놀리식 애플리케이션을 업그레이드하는 것보다 단일 마이크로서비스를 업그레이드하거나 교체하는 것이 더 쉽습니다.
이는 모놀리식 애플리케이션이 6개의 마이크로서비스로 나뉘고 모두 별도의 서버에 배포된 다음 다이어그램으로 설명됩니다. 일부 마이크로서비스는 다른 것과 독립적으로 확장되었습니다.
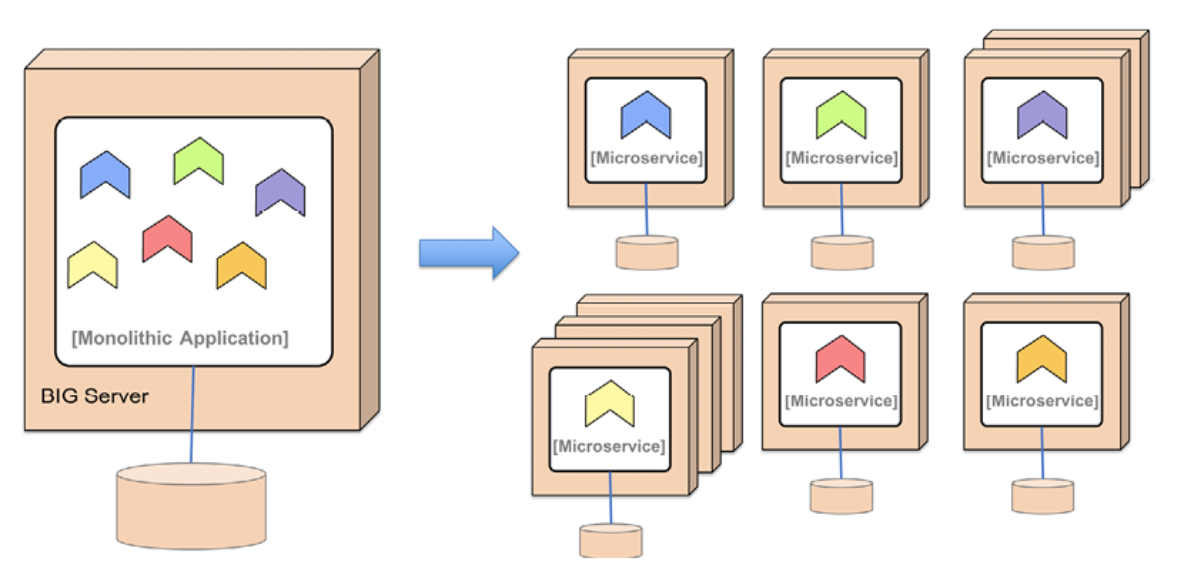
그림 1.8: 모놀리스를 마이크로서비스로 나누기
고객으로부터 매우 자주 받는 질문은 다음과 같습니다.
마이크로서비스는 얼마나 커야 합니까?
다음과 같은 경험 법칙을 사용하려고 합니다.
-
개발자의 머리에 쏙 들어갈 정도로 작음
-
성능과 데이터 일관성을 위태롭게 하지 않을 만큼 충분히 큽니다(서로 다른 마이크로서비스에 저장된 데이터 간의 SQL 외래 키는 더 이상 당연하게 여길 수 있는 것이 아님).
마이크로서비스 아키텍처는 본질적으로 모놀리식 앱을 협력하는 자율 소프트웨어 구성 요소 그룹으로 분해하는 아키텍처 스타일입니다. 더 빠른 개발을 가능하게 하고 더 쉽게 확장할 수 있도록 하는 것입니다.
마이크로서비스를 정의하는 방법을 더 잘 이해하면 마이크로서비스의 시스템 환경에서 발생하는 문제를 자세히 설명할 수 있습니다.
마이크로서비스의 과제
자율 소프트웨어 구성 요소의 과제 섹션에서 우리는 이미 자율 소프트웨어 구성 요소가 가져올 수 있는 몇 가지 과제를 확인했습니다(모두 마이크로서비스에도 적용됨).
-
동기 통신을 사용하는 수많은 작은 컴포넌트는 특히 고부하에서 일련의 장애 문제를 일으킬 수 있습니다.
-
많은 작은 컴포넌트에 대한 구성을 최신 상태로 유지하는 것은 어려울 수 있습니다.
-
처리 중인 요청을 추적하기 어렵고 많은 구성 요소를 포함
-
구성 요소 수준에서 하드웨어 리소스 사용량을 분석하는 것도 어려울 수 있습니다.
-
많은 작은 컴포넌트를 수동으로 구성하고 관리하면 비용이 많이 들고 오류가 발생하기 쉽습니다.
또 다른 단점은 분산 시스템을 형성한다는 것입니다. 분산 시스템은 본질적으로 다루기가 매우 어려운 것으로 알려져 있습니다. Peter Deutsch가 1994년에 다음과 같이 말한 것입니다.
분산 컴퓨팅의 8가지 오류: 기본적으로 모든 사람은 분산 애플리케이션을 처음 구축할 때 다음 8가지 가정을 합니다. 모두 장기적으로 거짓으로 판명되고 모두 큰 문제와 고통스러운 학습 경험을 야기합니다.
- 네트워크가 안정적입니다.
- 대기 시간이 0입니다.
- 대역폭이 무한합니다.
- 네트워크가 안전합니다.
- 토폴로지가 변경되지 않음
- 한 명의 관리자가 있습니다.
- 운송 비용은 0입니다
- 네트워크가 동질적입니다.
– Peter Deutsch, 1994
일반적으로 이러한 잘못된 가정을 기반으로 마이크로서비스를 구축하면 일시적인 네트워크 결함과 다른 마이크로서비스 인스턴스에서 발생하는 문제가 모두 발생하기 쉬운 솔루션이 생성됩니다. 시스템 환경에서 마이크로서비스의 수가 증가하면 문제의 가능성도 높아집니다.
좋은 경험 법칙은 시스템 환경에 항상 문제가 있다는 가정을 기반으로 마이크로서비스 아키텍처를 설계하는 것입니다. 마이크로서비스 아키텍처는 문제를 감지하고 실패한 구성 요소를 다시 시작하는 측면에서 이를 처리하도록 설계해야 합니다.
또한 클라이언트 측에서 요청이 실패한 마이크로 서비스 인스턴스로 전송되지 않도록 합니다. 문제가 수정되면 이전에 실패한 마이크로 서비스에 대한 요청을 재개해야 합니다. 즉, 마이크로서비스 클라이언트는 탄력적이어야 합니다. 물론 이 모든 것은 완전히 자동화되어야 합니다. 많은 수의 마이크로서비스로 인해 운영자가 수동으로 처리하는 것은 불가능합니다!
이 범위는 크지만 지금은 제한하고 마이크로서비스의 디자인 패턴에 대해 알아보겠습니다.
디자인 패턴
이 주제에서는 이전 섹션에서 설명한 대로 디자인 패턴을 사용하여 문제를 완화하는 방법을 다룹니다.
디자인 패턴의 개념은 실제로 꽤 오래되었습니다. 1977년 Christopher Alexander에 의해 발명되었습니다. 본질적으로 디자인 패턴은 특정 컨텍스트가 주어졌을 때 문제에 대해 재사용 가능한 솔루션을 설명하는 것입니다. 설계 패턴에서 시도되고 테스트된 솔루션을 사용하면 솔루션을 직접 개발하는 데 시간을 소비하는 것에 비해 많은 시간을 절약하고 구현 품질을 높일 수 있습니다.
우리가 다룰 디자인 패턴은 다음과 같습니다:
- 서비스 디스커버리
- 에지 서버
- 반응형 마이크로서비스
- 중앙 구성
- 중앙 집중식 로그 분석
- 분산 추적
- 차단기
- 제어 루프
- 중앙 집중식 모니터링 및 경보
이것은 앞서 설명한 문제를 처리하는 데 필요한 디자인 패턴의 최소 목록입니다.
디자인 패턴을 설명하는 데 가벼운 접근 방식을 사용하고 다음에 중점을 둡니다.
- 문제
- 솔루션
- 솔루션 요구 사항
이러한 디자인 패턴의 컨텍스트는 마이크로서비스가 동기 요청 또는 비동기 메시지 전송을 사용하여 서로 통신하는 협력 마이크로 서비스의 시스템 환경입니다.
서비스 디스커버리
서비스 검색 패턴에는 다음과 같은 문제, 솔루션 및 솔루션 요구 사항이 있습니다.
문제
클라이언트는 마이크로서비스와 해당 인스턴스를 어떻게 찾을 수 있습니까?
서비스 인스턴스는 시작할 때 동적으로 할당된 IP 주소를 할당받습니다. 이것은 예를 들어 HTTP를 통해 REST API를 노출하는 서비스에 대한 요청을 클라이언트가 어렵게 만듭니다. 다음 다이어그램을 고려하십시오.
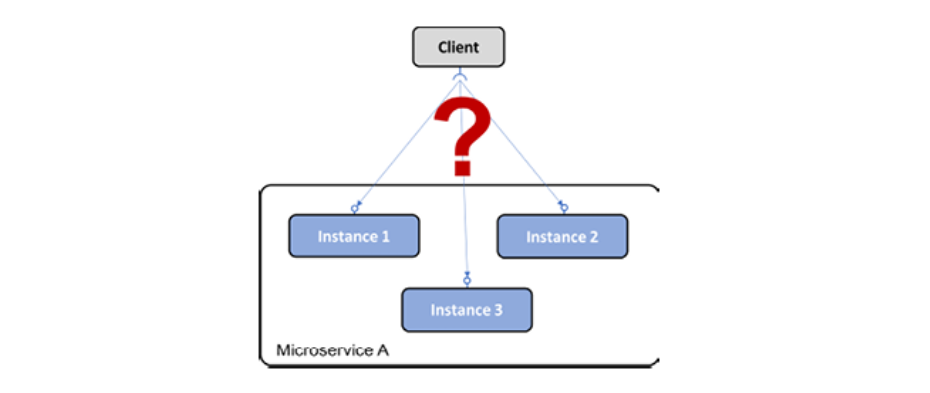
Figure 1.9: 서비스 디스커버리 이슈
해결책
사용 가능한 서비스와 해당 인스턴스의 IP 주소를 추적하는 서비스 디스커버리 컴포넌트를 시스템 환경에 추가합니다.
솔루션 요구 사항
일부 솔루션 요구 사항은 다음과 같습니다.
-
서비스와 해당 인스턴스가 들어오고 나갈 때 자동으로 등록/등록 취소합니다.
-
클라이언트는 서비스에 대한 논리적 끝점에 요청할 수 있어야 합니다. 요청은 사용 가능한 서비스 인스턴스 중 하나로 라우팅됩니다.
-
서비스에 대한 요청은 사용 가능한 인스턴스에 대해 로드 밸런싱되어야 합니다.
-
요청이 라우팅되지 않도록 현재 상태가 좋지 않은 인스턴스를 감지할 수 있어야 합니다.
9장 Netflix Eureka를 사용하여 서비스 검색 추가, 15장, Kubernetes 소개 및 16장, Kubernetes에 마이크로서비스 배포에서 볼 수 있듯이 이 디자인 패턴은 두 가지 다른 전략을 사용하여 구현할 수 있습니다.
-
클라이언트 측 라우팅: 클라이언트는 서비스 디스커버리 서비스와 통신하는 라이브러리를 사용하여 요청을 보낼 적절한 인스턴스를 찾습니다.
-
서버 측 라우팅: 서비스 디스커버리 서비스의 인프라는 모든 요청이 전송되는 리버스 프록시를 노출하고 이를 통해 적절한 마이크로서비스 인스턴스에 요청을 전달합니다.
에지 서버
문제
마이크로서비스의 시스템 환경에서는 많은 경우에 일부 마이크로서비스를 시스템 환경 외부에 노출시키고 나머지 마이크로서비스를 외부 액세스로부터 숨기는 것이 바람직합니다. 노출된 마이크로서비스는 악의적인 클라이언트의 요청으로부터 보호되어야 합니다.
해결책
들어오는 모든 요청이 통과할 시스템 환경에 새 구성 요소인 에지 서버를 추가합니다.
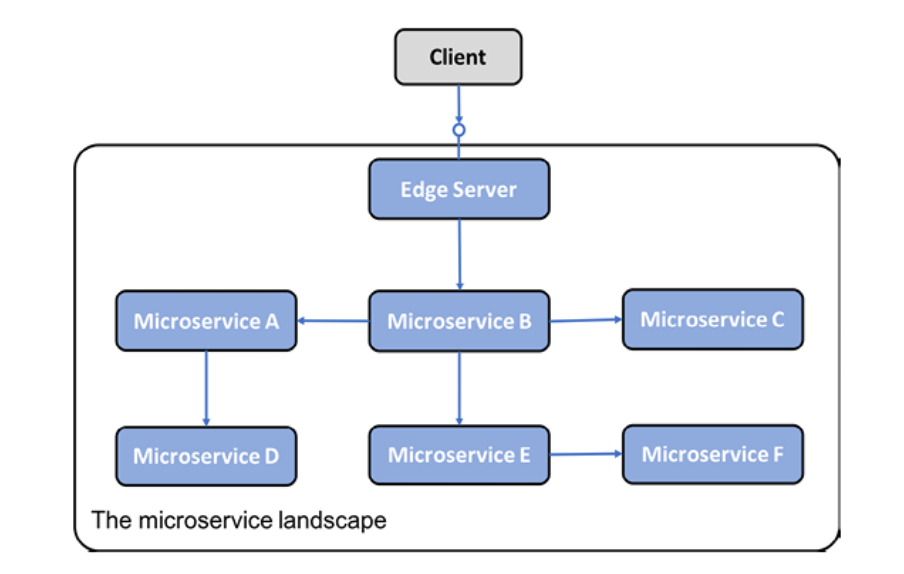
그림 1.10: 에지 서버 디자인 패턴
구현 참고 사항: 에지 서버는 일반적으로 리버스 프록시처럼 작동하며 동적 로드 밸런싱 기능을 제공하기 위해 디스커버리 서비스와 통합될 수 있습니다.
솔루션 요구 사항
-
컨텍스트 외부에 노출되어서는 안 되는 내부 서비스를 숨깁니다. 즉, 외부 요청을 허용하도록 구성된 마이크로서비스로만 요청을 라우팅합니다.
-
외부 서비스를 노출하고 악의적인 요청으로부터 보호합니다. 즉, OAuth, OIDC, JWT 토큰 및 API 키와 같은 표준 프로토콜 및 모범 사례를 사용하여 클라이언트가 신뢰할 수 있는지 확인합니다.
반응형 마이크로서비스
문제
일반적으로 HTTP를 통한 RESTful API와 같은 블로킹 I/O를 사용하여 동기 통신을 구현하는 데 익숙합니다. 블로킹 I/O를 사용한다는 것은 요청 길이만큼 운영 체제에서 스레드가 할당된다는 것을 의미합니다. 동시 요청 수가 증가하면 서버의 OS에서 사용 가능한 스레드가 부족하여 응답 시간이 길어지거나 서버가 충돌하는 문제가 발생할 수 있습니다. 마이크로서비스 아키텍처를 사용하면 일반적으로 협력 마이크로 서비스 체인이 요청을 처리하는 데 사용되는 경우 일반적으로 이 문제가 더욱 악화됩니다. 요청을 처리하는 데 관련된 마이크로서비스가 많을수록 사용 가능한 스레드가 더 빨리 소모됩니다.
해결책
넌블러킹 I/O를 사용하여 다른 서비스, 즉 데이터베이스 또는 다른 마이크로서비스에서 처리가 발생하기를 기다리는 동안 스레드가 할당되지 않도록 합니다.
솔루션 요구 사항
-
가능하면 비동기 프로그래밍 모델을 사용하여 수신자가 메시지를 처리할 때까지 기다리지 않고 메시지를 보냅니다.
-
동기식 프로그래밍 모델을 선호하는 경우 응답을 기다리는 동안 스레드를 할당하지 않고 non-blocking I/O를 사용하여 동기식 요청을 실행할 수 있는 반응형 프레임워크를 사용합니다. 이렇게 하면 증가된 워크로드를 처리하기 위해 마이크로서비스를 더 쉽게 확장할 수 있습니다.
-
서비스는 또한 탄력적이고 자가 치유되도록 설계되어야 합니다. 탄력적이란 의존 서비스 중 하나가 실패하더라도 응답을 생성할 수 있다는 의미입니다. 자가 치유는 실패한 서비스가 다시 작동하면 마이크로서비스가 다시 사용할 수 있어야 함을 의미합니다.
반응형 시스템의 기반은 메시지 기반 시스템이라는 것입니다. 그들은 비동기 통신을 사용합니다. 이를 통해 탄력있고 회복력, 즉 실패에 대한 내성을 가질 수 있습니다. 탄력성과 회복력을 함께 사용하면 반응형 시스템이 항상 적시에 응답할 수 있습니다.
중앙집중식 구성
문제
앱은 일반적으로 환경 변수나 구성 파일과 함께 배포됩니다. 마이크로서비스 아키텍처를 기반으로 하는 시스템 환경, 즉 배포된 마이크로서비스 인스턴스가 많은 경우 몇 가지 의문이 생깁니다.
-
실행 중인 모든 인스턴스에 대한 구성에 대한 전체 그림을 얻으려면 어떻게 해야 합니까?
-
구성을 업데이트하고 영향을 받는 모든 마이크로서비스 인스턴스가 올바르게 업데이트되었는지 확인하려면 어떻게 해야 합니까?
해결책
다음 다이어그램과 같이 새 구성 요소인 구성 서버를 시스템 환경에 추가하여 모든 마이크로서비스의 구성을 저장합니다.
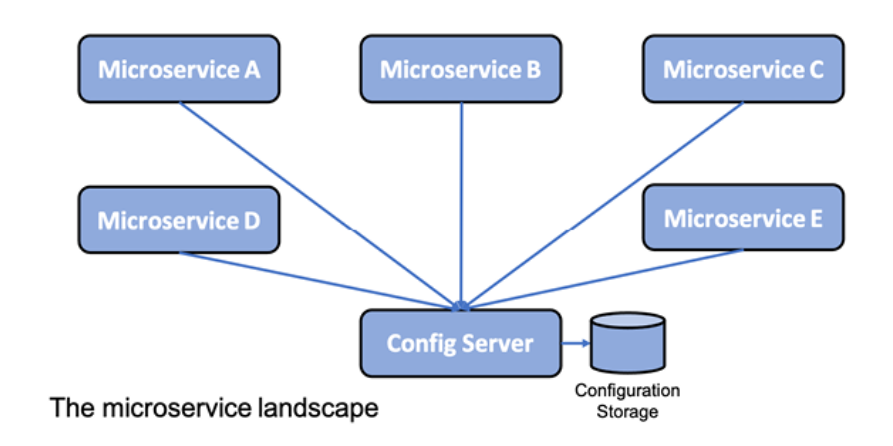
그림 1.11: 중앙 구성 디자인 패턴
솔루션 요구 사항
다양한 환경(dev, test, qa 및 prod)에 대해 서로 다른 설정으로 마이크로서비스 그룹에 대한 구성 정보를 한 곳에 저장할 수 있습니다.
중앙 집중식 로그 분석
중앙 집중식 로그 분석에는 다음과 같은 문제, 솔루션 및 솔루션 요구 사항이 있습니다.
problem
일반적으로 앱은 자신이 실행되는 서버의 로컬 파일 시스템의 로그 파일에 로그 이벤트를 기록합니다. 마이크로서비스 아키텍처를 기반으로 하는 시스템 환경, 즉 다수의 소규모 서버에 다수의 마이크로서비스 인스턴스가 배포되어 있는 경우 다음과 같은 질문을 할 수 있습니다.
-
각 마이크로서비스 인스턴스가 자체 로컬 로그 파일에 쓸 때 시스템 환경에서 무슨 일이 일어나고 있는지에 대한 개요를 보려면 어떻게 해야 합니까?
-
마이크로 서비스 인스턴스에 문제가 발생하고 해당 로그 파일에 오류 메시지를 쓰기 시작하는지 어떻게 알 수 있습니까?
-
최종 사용자가 문제를 보고하기 시작하면 관련 로그 메시지를 어떻게 찾을 수 있습니까? 즉, 어떤 마이크로 서비스 인스턴스가 문제의 근본 원인인지 어떻게 식별할 수 있습니까?
다음 다이어그램은 문제를 보여줍니다.
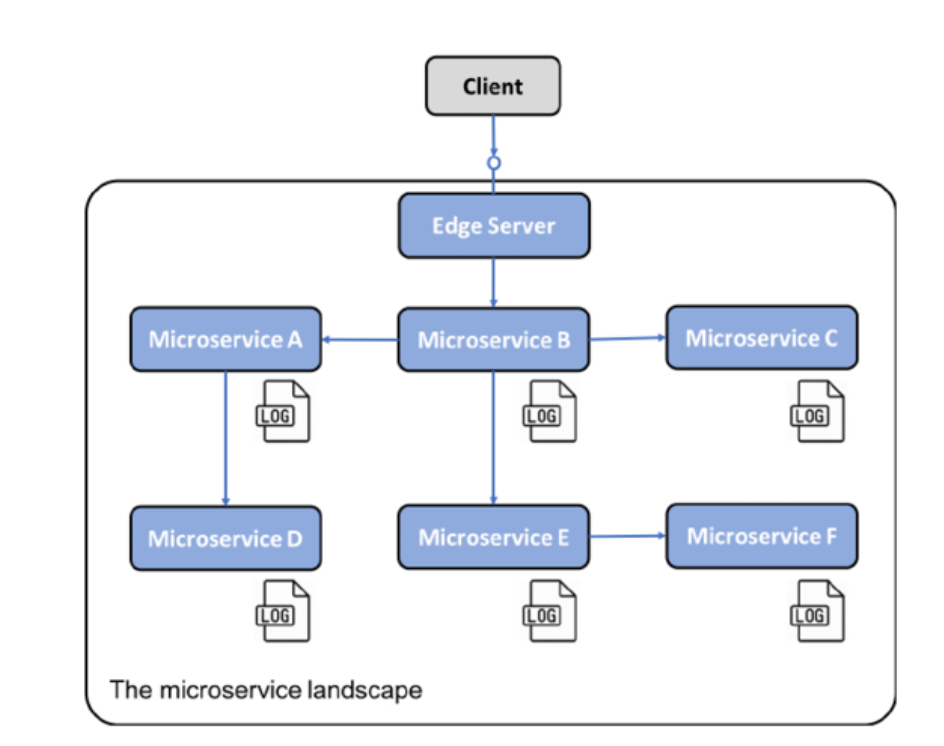
Figure 1.12: 로컬 파일 시스템에 로그를 작성
해결책
중앙 집중식 로깅을 관리하고 다음을 수행할 수 있는 새 구성 요소를 추가합니다.
-
새로운 마이크로서비스 인스턴스 감지 및 로그 이벤트 수집
-
중앙 데이터베이스에서 구조화되고 검색 가능한 방식으로 로그 이벤트를 해석하고 저장
-
로그 이벤트 쿼리 및 분석을 위한 API 및 그래픽 도구 제공
솔루션 요구 사항
일부 솔루션 요구 사항은 다음과 같습니다.
-
마이크로서비스는 로그 이벤트를 표준 시스템 출력인 stdout으로 스트리밍합니다. 이렇게 하면 로그 이벤트가 마이크로 서비스별 로그 파일에 기록될 때와 비교하여 로그 수집기가 로그 이벤트를 더 쉽게 찾을 수 있습니다.
마이크로서비스는 분산 추적 디자인 패턴과 관련된 다음 섹션에 설명된 상관 관계 ID로 로그 이벤트에 태그를 지정합니다. -
정식 로그 형식이 정의되어 로그 이벤트가 중앙 데이터베이스에 저장되기 전에 로그 수집기가 마이크로서비스에서 수집한 로그 이벤트를 정식 로그 형식으로 변환할 수 있습니다. 수집된 로그 이벤트를 쿼리하고 분석하려면 로그 이벤트를 정식 로그 형식으로 저장해야 합니다.
분산 추적
시스템 환경에 대한 외부 요청을 처리하는 동안 마이크로서비스 간에 흐르는 요청 및 메시지를 추적할 수 있어야 합니다.
오류 시나리오의 몇 가지 예는 다음과 같습니다.
-
최종 사용자가 특정 장애에 대한 지원 사례를 제출하기 시작하면 문제를 일으킨 마이크로서비스, 즉 근본 원인을 어떻게 식별할 수 있습니까?
-
한 지원 사례에서 특정 엔터티와 관련된 문제(예: 특정 주문 번호)를 언급하는 경우 이 특정 주문 처리와 관련된 로그 메시지(예: 주문 처리와 관련된 모든 마이크로서비스의 로그 메시지)를 어떻게 찾을 수 있습니까?
-
최종 사용자가 수용할 수 없을 정도로 긴 응답 시간과 관련된 지원 사례를 제출하기 시작하면 호출 체인의 어떤 마이크로서비스가 지연을 일으키는지 어떻게 식별할 수 있습니까?
다음 다이어그램은 이를 설명합니다.
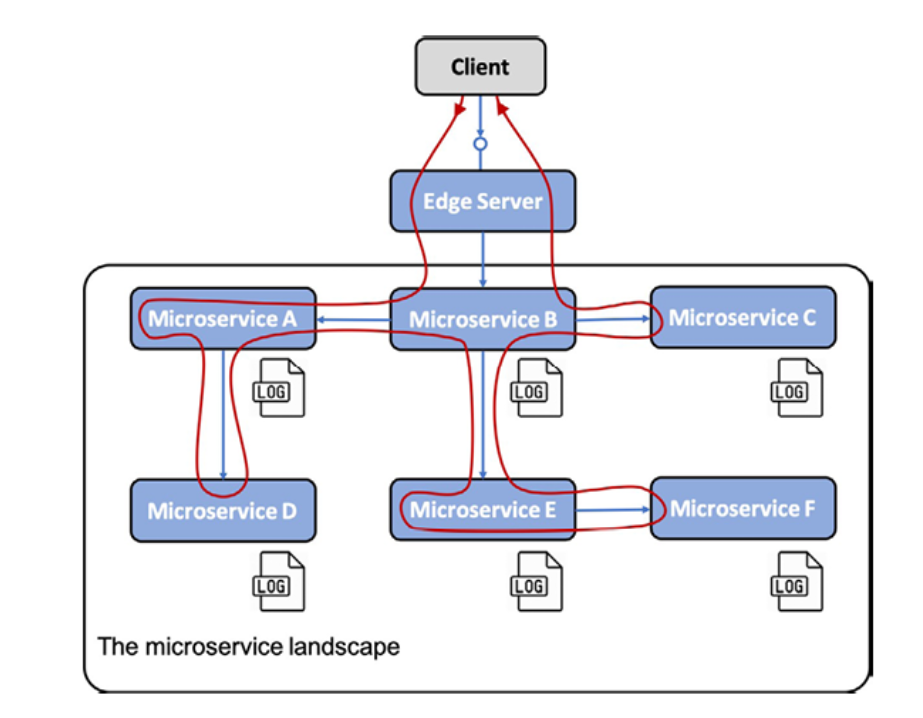
그림 1.13: 분산 추적 문제
해결책
협력하는 마이크로 서비스 간의 처리를 추적하려면 모든 관련 요청 및 메시지가 공통 상관 관계 ID로 표시되고 상관 관계 ID가 모든 로그 이벤트의 일부인지 확인해야 합니다. 상관 관계 ID를 기반으로 중앙 집중식 로깅 서비스를 사용하여 모든 관련 로그 이벤트를 찾을 수 있습니다. 로그 이벤트 중 하나에 비즈니스 관련 식별자에 대한 정보도 포함되어 있는 경우(예: 고객, 제품 또는 주문의 ID) 상관 관계 ID를 사용하여 해당 비즈니스 식별자에 대한 모든 관련 로그 이벤트를 찾을 수 있습니다.
협력하는 마이크로서비스의 호출 체인에서 지연을 분석할 수 있으려면 요청, 응답 및 메시지가 각 마이크로서비스에 들어오고 나가는 시간에 대한 타임스탬프를 수집할 수 있어야 합니다.
솔루션 요구 사항
-
표준화된 이름의 헤더와 같이 잘 알려진 위치의 모든 수신 또는 신규 요청 및 이벤트에 고유한 상관 관계 ID를 할당합니다.
-
마이크로서비스가 나가는 요청을 하거나 메시지를 보낼 때 요청 및 메시지에 상관 관계 ID를 추가해야 합니다.
-
모든 로그 이벤트는 중앙 집중식 로깅 서비스가 로그 이벤트에서 상관 ID를 추출하여 검색 가능하게 만들 수 있도록 사전 정의된 형식의 상관 ID를 포함해야 합니다.
-
요청, 응답 및 메시지가 모두 마이크로서비스 인스턴스에 들어가거나 나올 때 추적 레코드를 생성해야 합니다.
Circuit breaker
동기식 상호 통신을 사용하는 마이크로서비스의 시스템 환경은 일련의 실패에 노출될 수 있습니다. 하나의 마이크로서비스가 응답을 중지하면 해당 클라이언트도 문제가 발생하여 클라이언트의 요청에 응답하지 않을 수 있습니다. 문제는 시스템 환경 전반에 걸쳐 재귀적으로 전파되어 주요 부분을 제거할 수 있습니다.
이는 동기 요청이 블로킹 I/O를 사용하여 실행되는 경우, 즉 요청이 처리되는 동안 기본 OS에서 스레드를 차단하는 경우에 특히 일반적입니다. 많은 수의 동시 요청 및 예기치 않게 느리게 응답하기 시작하는 서비스와 결합하여 스레드 풀이 빠르게 고갈되어 호출자가 중단 및/또는 충돌을 일으킬 수 있습니다. 이 실패는 호출자의 호출자 등에게 불쾌하게 빠르게 퍼질 수 있습니다.
해결책
호출하는 서비스에 문제가 있는 경우 호출자가 보내는 새 요청을 방지하는 회로 차단기를 추가합니다.
솔루션 요구 사항
- 서비스에 문제가 감지되면 회로를 열고 빠르게 실패합니다.
오류 수정을 위한 Probe(반개방 회로라고도 함) 즉, 서비스가 다시 정상적으로 작동하는지 확인하기 위해 정기적으로 단일 요청을 통과하도록 허용합니다.
- Probe가 서비스가 다시 정상적으로 작동하고 있음을 감지하면 회로를 닫습니다. 이 기능은 시스템 환경을 이러한 종류의 문제에 탄력적으로 만들기 때문에 매우 중요합니다. 즉, 자가 치유됩니다.
다음 다이어그램은 마이크로 서비스의 시스템 환경 내에서 모든 동기 통신이 회로 차단기를 통과하는 시나리오를 보여줍니다. 모든 회로 차단기가 닫힙니다. 요청으로 이동하는 서비스에서 문제를 감지한 하나의 회로 차단기를 제외하고 트래픽을 허용합니다. 따라서 이 회로 차단기는 열려 있고 빠른 실패 논리를 사용합니다. 즉, 실패한 서비스를 호출하지 않고 시간 초과가 발생할 때까지 기다립니다. 대신 Microservice E는 응답을 즉시 반환할 수 있으며 선택적으로 응답하기 전에 몇 가지 대체 논리를 적용할 수 있습니다.
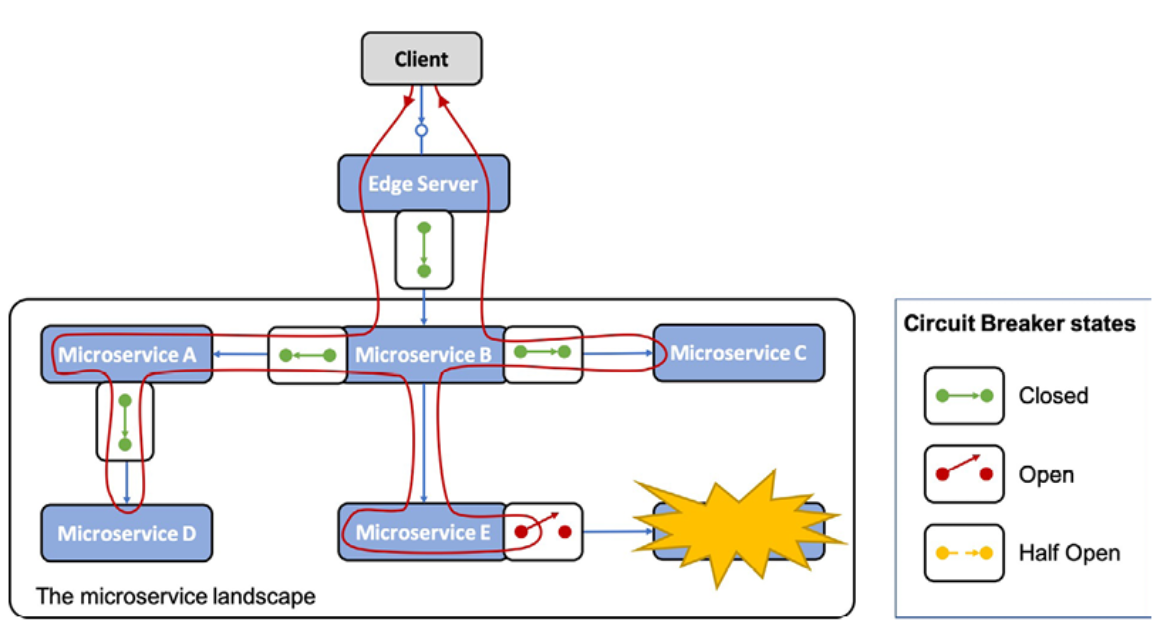
Figure 1.14: The circuit breaker design pattern
제어 루프
많은 수의 마이크로서비스 인스턴스가 여러 서버에 분산되어 있는 시스템 환경에서 충돌하거나 중단된 마이크로서비스 인스턴스와 같은 문제를 수동으로 감지하고 수정하는 것은 매우 어렵습니다.
해결책
새 구성 요소인 제어 루프를 시스템 환경에 추가합니다. 이 프로세스는 다음과 같이 설명됩니다.
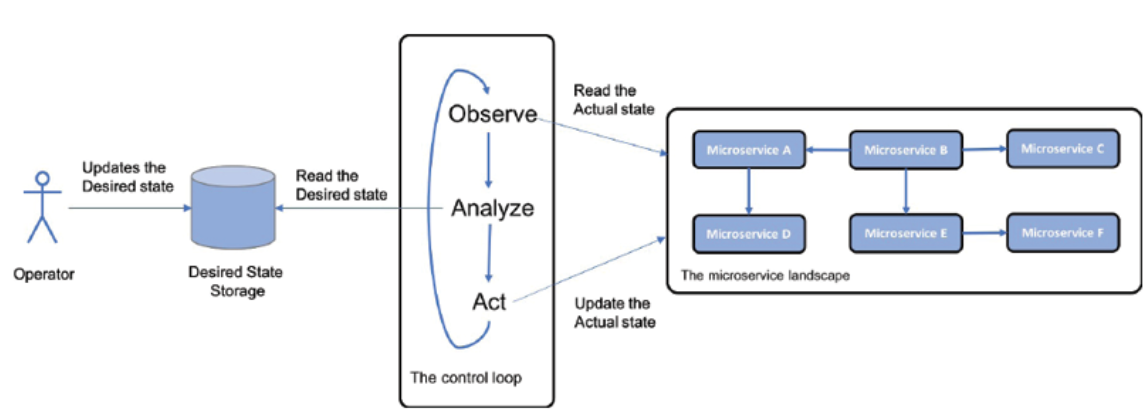
그림 1.15: 제어 루프 디자인 패턴
솔루션 요구 사항
제어 루프는 운영자가 지정한 대로 시스템 환경의 실제 상태를 지속적으로 관찰하여 원하는 상태와 비교합니다. 두 상태가 다르면 실제 상태를 원하는 상태와 같게 만들기 위한 조치를 취합니다.
컨테이너 세계에서 Kubernetes와 같은 컨테이너 오케스트레이터는 일반적으로 이 패턴을 구현하는 데 사용됩니다. Kubernetes에 대한 자세한 내용은 15장, Kubernetes 소개에서 배울 것입니다.
중앙 집중식 모니터링 및 알람
관찰된 응답 시간 및/또는 하드웨어 리소스 사용량이 허용할 수 없을 정도로 높아지면 문제의 근본 원인을 찾기가 매우 어려울 수 있습니다. 예를 들어 마이크로서비스 당 하드웨어 리소스 소비를 분석할 수 있어야 합니다.
해결책
이를 억제하기 위해 각 마이크로서비스 인스턴스 수준에 대한 하드웨어 리소스 사용량에 대한 메트릭을 수집할 수 있는 새로운 구성 요소인 모니터 서비스를 시스템 환경에 추가합니다.
솔루션 요구 사항
-
자동 확장 서버를 포함하여 시스템 환경에서 사용되는 모든 서버에서 메트릭을 수집할 수 있어야 합니다.
-
새로운 마이크로서비스 인스턴스가 사용 가능한 서버에서 시작될 때 이를 감지하고 메트릭 수집을 시작할 수 있어야 합니다.
-
수집된 메트릭을 쿼리하고 분석하기 위한 API 및 그래픽 도구를 제공할 수 있어야 합니다.
-
지정된 메트릭이 지정된 임계값을 초과할 때 트리거되는 경고를 정의할 수 있어야 합니다.
다음 스크린샷은 20장, 마이크로서비스 모니터링에서 살펴볼 모니터링 도구인 Prometheus의 메트릭을 시각화하는 Grafana를 보여줍니다.
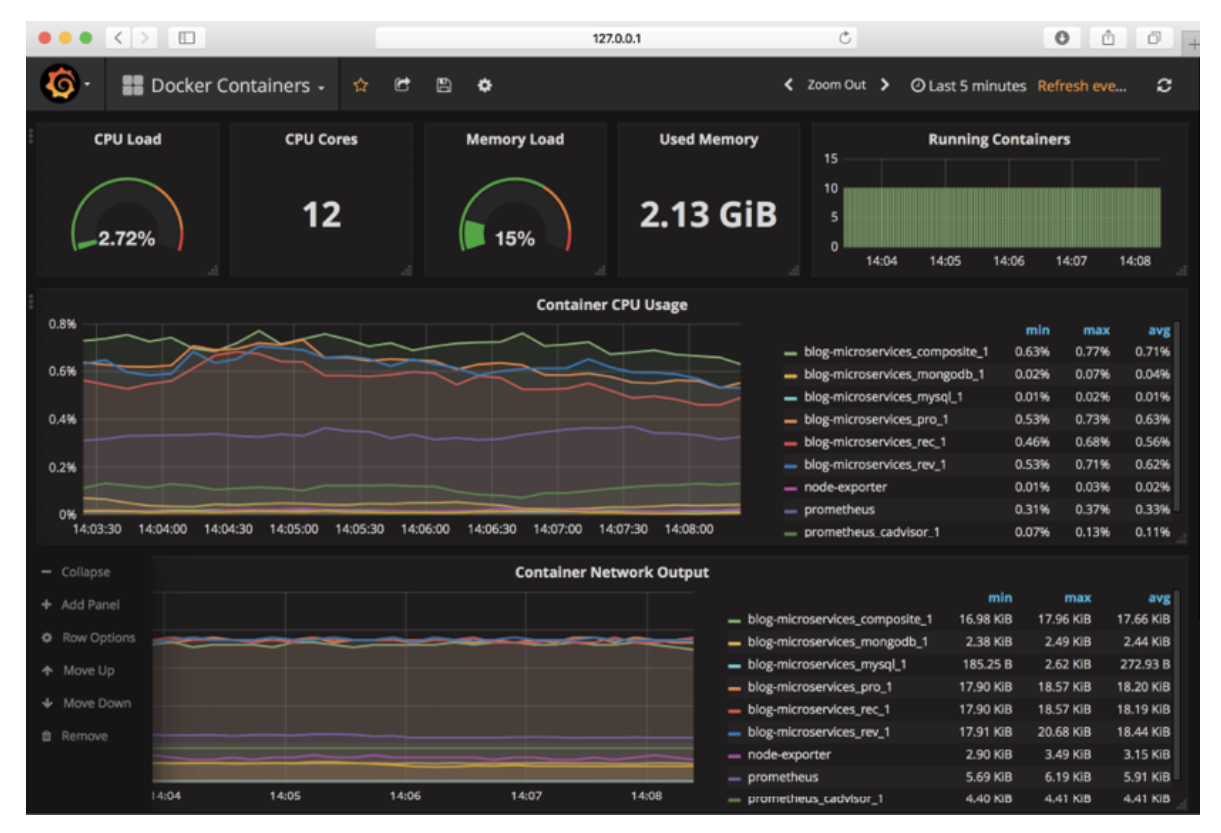
그림 1.16: Grafana로 모니터링
그것은 광범위한 목록이었습니다! 이러한 디자인 패턴이 마이크로서비스의 문제를 더 잘 이해하는 데 도움이 되었다고 확신합니다. 다음으로 소프트웨어 인에이블러에 대해 알아보겠습니다.
Software enablers
이미 언급했듯이 마이크로서비스에 대한 기대치를 충족하고 가장 중요하게는 마이크로서비스와 함께 제공되는 새로운 문제를 처리하는 데 도움이 되는 매우 우수한 오픈 소스 도구가 많이 있습니다.
- Spring Boot
- Spring Cloud/Netflix OSS
- Docker
- Kubernetes
- Istio, 서비스 메시 구현
다음 표는 이 책에서 디자인 패턴을 구현하는 데 사용할 해당 오픈 소스 도구와 함께 이러한 문제를 처리하는 데 필요한 디자인 패턴을 매핑합니다.
Spring Cloud, Kubernetes 또는 Istio는 서비스 검색, 에지 서버 및 중앙 구성과 같은 일부 디자인 패턴을 구현하는 데 사용할 수 있습니다. 우리는 이 책의 뒷부분에서 이러한 대안을 사용할 때의 장단점에 대해 논의할 것입니다.
이 책에서 사용할 디자인 패턴과 도구를 소개하면서 중요하지만 이 텍스트에서 다루지 않는 몇 가지 관련 영역을 살펴봄으로써 이 장을 마무리할 것입니다.
기타 중요한 고려 사항
마이크로서비스 아키텍처를 성공적으로 구현하려면 여러 관련 영역도 고려해야 합니다. 나는 이 책에서 이러한 영역을 다루지 않을 것이다. 대신 여기에서 다음과 같이 간단히 언급하겠습니다.
-
DevOps의 중요성: 마이크로서비스 아키텍처의 이점 중 하나는 제공 시간을 단축하고 극단적인 경우 새 버전을 지속적으로 제공할 수 있다는 것입니다. 그렇게 빨리 제공할 수 있으려면 개발팀과 운영팀이 구축한 만트라에 따라 함께 작동하는 조직을 구축해야 합니다. 즉, 개발자는 더 이상 단순히 새 버전의 소프트웨어를 운영 팀에 전달할 수 없습니다. 대신 개발 및 운영 조직은 하나의 마이크로서비스(또는 관련 마이크로서비스 그룹)의 종단 간 수명 주기에 대한 전적인 책임을 지는 팀으로 조직되어 훨씬 더 긴밀하게 협력해야 합니다. DevOps의 조직적 부분 외에도 팀은 제공 체인, 즉 마이크로서비스를 구축, 테스트, 패키징 및 다양한 배포 환경에 배포하는 단계를 자동화해야 합니다. 이를 delivery 파이프라인 설정이라고 합니다.
-
조직적 측면과 Conway의 법칙: 마이크로서비스 아키텍처가 조직에 미치는 영향에 대한 측면은 다음과 같은 Conway의 법칙입니다.
"시스템을 설계하는 모든 조직은 그 구조가 조직의 커뮤니케이션 구조의 사본인 디자인을 생성할 것입니다."
– 멜빈 콘웨이, 1967
이는 기술 전문성(예: UX, 비즈니스 로직 및 데이터베이스 팀)을 기반으로 대규모 앱을 위해 IT 팀을 구성하는 기존의 접근 방식이 큰 3계층 애플리케이션(일반적으로 별도의 UI를 위한 배치 가능한 단위, 비즈니스 로직 처리를 위한 단위, 큰 DB를 위한 단위. 마이크로서비스 아키텍처를 기반으로 앱을 성공적으로 제공하려면 조직을 관련 마이크로서비스 중 하나 또는 그룹과 함께 작업하는 팀으로 변경해야 합니다. 팀은 해당 마이크로서비스에 필요한 기술(예: 비즈니스 논리를 위한 언어 및 프레임워크 및 데이터 지속을 위한 DB 기술)을 보유해야 합니다.
-
모놀리식 애플리케이션을 마이크로서비스로 분해: 가장 어려운 결정 중 하나는 모놀리식 애플리케이션을 협력 마이크로서비스 세트로 분해하는 방법입니다. 이것이 잘못된 방식으로 수행되면 다음과 같은 문제가 발생합니다.
-
느린 전달: 비즈니스 요구 사항의 변경이 너무 많은 마이크로서비스에 영향을 미치므로 추가 작업이 발생합니다.
-
나쁜 성능: 특정 비즈니스 기능을 수행하려면 다양한 마이크로 서비스 간에 많은 요청을 전달해야 하므로 응답 시간이 길어집니다.
-
불일치 데이터: 관련 데이터가 서로 다른 마이크로 서비스로 분리되기 때문에 시간이 지남에 따라 서로 다른 마이크로 서비스에서 관리하는 데이터에서 불일치가 나타날 수 있습니다.
-
마이크로서비스에 대한 적절한 경계를 찾는 좋은 접근 방식은 도메인 기반 설계와 경계 컨텍스트의 개념을 적용하는 것입니다. Eric Evans에 따르면 제한된 컨텍스트는 다음과 같습니다.
"특정 모델이 정의되고 적용 가능한 경계(일반적으로 하위 시스템 또는 특정 팀의 작업)에 대한 설명"
즉, 제한된 컨텍스트로 정의된 마이크로서비스에는 자체 데이터에 대한 잘 정의된 모델이 있습니다.
-
API 설계의 중요성: 마이크로서비스 그룹이 외부에서 사용 가능한 공통 API를 노출하는 경우 API가 이해하기 쉽고 다음 지침을 준수하는 것이 중요합니다.
-
여러 API에서 동일한 개념을 사용하는 경우 사용하는 명명 및 데이터 유형에 대해 동일한 설명을 가져야 합니다.
-
API가 독립적이지만 통제된 방식으로 발전할 수 있도록 하는 것이 매우 중요합니다. 이를 위해서는 일반적으로 API에 대한 적절한 버전 관리 스키마(예: https://semver.org/)를 적용해야 합니다. 이는 특정 기간 동안 API의 여러 주요 버전을 지원하여 API 클라이언트가 자신의 속도로 새로운 주요 버전으로 마이그레이션할 수 있도록 함을 의미합니다.
-
-
온프레미스에서 클라우드로의 마이그레이션 경로: 오늘날 많은 기업에서 워크로드를 온프레미스로 실행하지만 워크로드의 일부를 클라우드로 이동하는 방법을 찾고 있습니다. 오늘날 대부분의 클라우드 제공업체는 Kubernetes를 서비스로 제공하기 때문에 매력적인 마이그레이션 접근 방식은 먼저 워크로드를 Kubernetes 온프레미스(마이크로서비스로든 아니든)로 이동한 다음 선호하는 클라우드 제공업체에서 제공하는 Kubernetes as a Service 오퍼링에 재배포하는 것입니다. .
-
마이크로서비스를 위한 좋은 설계 원칙, 12-factor 앱: 12-factor 앱(https://12factor.net)은 클라우드에 배포할 수 있는 소프트웨어를 구축하기 위한 설계 원칙의 집합입니다. 이러한 설계 원칙의 대부분은 배포 위치와 방법, 즉 클라우드 또는 온프레미스와 상관없이 마이크로서비스를 구축하는 데 적용할 수 있습니다. 구성, 프로세스 및 로그와 같은 이러한 원칙 중 일부는 이 책에서 다루지만 전부는 아닙니다.
요약
우리는 마이크로서비스가 무엇인지 정의했습니다. 특정 요구 사항이 있는 일종의 자율적인 분산 구성 요소입니다. 우리는 또한 마이크로서비스 기반 아키텍처의 좋은 점과 어려운 점을 살펴보았습니다.
이러한 과제를 처리하기 위해 일련의 디자인 패턴을 정의하고 Spring Boot, Spring Cloud, Kubernetes 및 Istio와 같은 오픈 소스 제품의 기능을 디자인 패턴에 간략하게 매핑했습니다.
지금 첫 번째 마이크로서비스를 개발하고 싶습니까? 다음 장에서는 Spring Boot와 첫 번째 마이크로서비스를 개발하는 데 사용할 보완적인 오픈 소스 도구를 소개합니다.
