타이타닉
설명: 결측치, 이상치, 범주형 데이터 등 데이터 클리닝 실습에 최적
https://www.kaggle.com/c/titanic/data
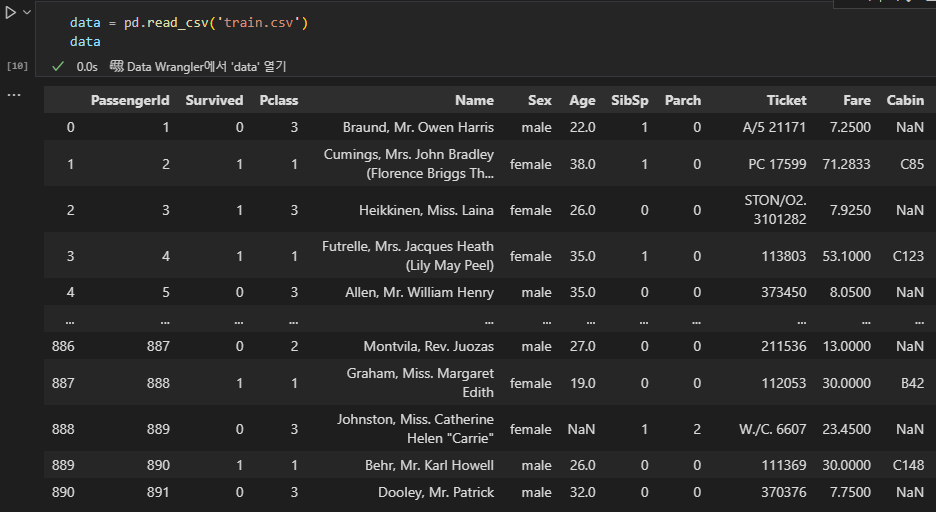
데이터 불러오기
원하는 데이터만 확인하기
head()
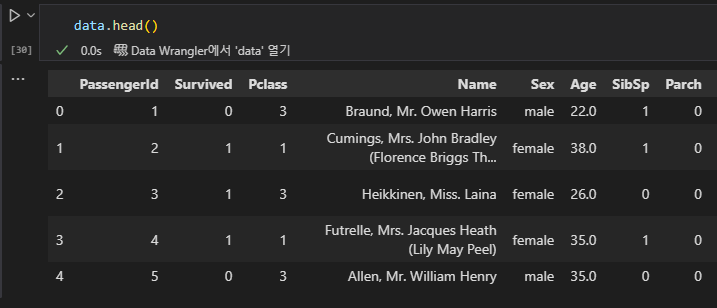
tail()
정보 확인
info()
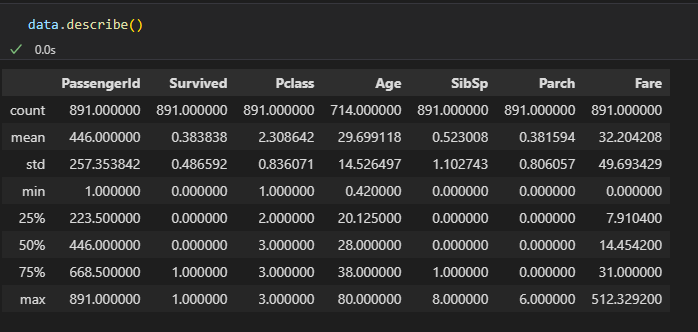
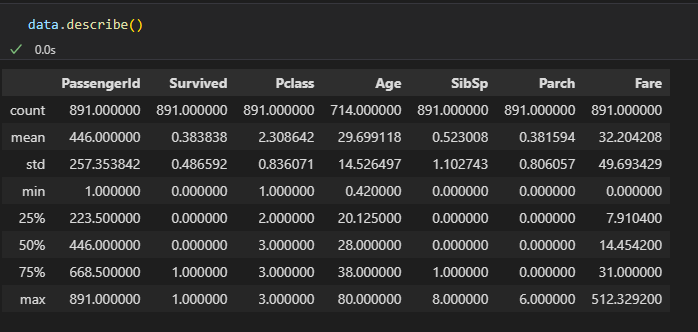
describe()
Non-Null Count: 빈 값이 없는 데이터가 몇 개인지
describe는 통계적 요약을 제공DataFrame & Series
판다스(Pandas) 대표 메서드 10개
-
.describe()
DataFrame이나 Series의 요약 통계 정보를 반환합니다.
수치형 데이터의 경우, 개수(count), 평균(mean), 표준편차(std), 최소값(min), 25%/50%/75% 분위수, 최대값(max) 등을 보여줍니다.
범주형 데이터에도 사용 가능하며, unique(고유값 개수), top(최빈값), freq(최빈값 빈도수) 등을 제공
-
.apply()
사용자 정의 함수나 내장 함수를 DataFrame의 행 또는 열 단위로 적용
예를 들어, 각 요소에 제곱을 적용하거나, 특정 열에 복잡한 변환을 할 때 사용 -
.sort_values()
지정한 열 또는 인덱스를 기준으로 DataFrame이나 Series의 데이터를 정렬
오름차순/내림차순, 여러 열 기준, NULL 값 처리 등 다양한 옵션을 제공
-
.tail()
DataFrame이나 Series의 마지막 n개 행을 반환
기본값은 5개이며, 최근 데이터나 끝부분을 빠르게 확인할 때 유용
-
.replace()
특정 값을 다른 값으로 대체
숫자, 문자열, 리스트, 딕셔너리, 정규표현식 등 다양한 방식으로 치환
-
pd.to_numeric()
데이터를 숫자형(정수 또는 부동소수점)으로 변환
변환 불가능한 값은 오류로 처리하거나 NaN으로 대체 가능. Series, 리스트, 배열 등 다양한 입력을 지원 -
.get_dummies()
범주형(카테고리형) 데이터를 이진(dummy) 변수로 변환합니다.
각 범주마다 새로운 열을 생성하고, 해당 행에 해당하는 범주에만 1, 나머지는 0을 할당합니다. 머신러닝 등에서 범주형 데이터를 숫자로 변환할 때 필수적
-
집계(Aggregation) 관련 메서드
여러 데이터 포인트를 요약하거나 그룹화할 때 사용
대표적으로 groupby()로 그룹을 나눈 뒤, agg(), mean(), sum(), std() 등 집계 함수를 적용여러 함수를 동시에 적용하거나, 열마다 다른 함수를 지정가능
-
.merge()
두 개 이상의 DataFrame을 공통 열이나 인덱스를 기준으로 병합
SQL의 JOIN과 유사하게 inner, left, right, outer 등 다양한 방식으로 병합 -
.value_counts()
Series 내 고유값의 빈도수를 계산하여 반환
정렬, 비율(normalize), NaN 포함 여부(dropna), 구간(bin)별 집계 등 다양한 옵션을 지원
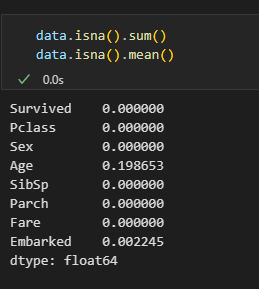
불필요한 컬럼 삭제, 결측치 처리
불필요한 컬럼 제거

결측치 확인