가장 개선 해야할 부분은 핵심 단어 몇 개 말하기가 아닌 '한 문장으로 말하기' 이다.
[1] 배열과 링크드 리스트의 차이점은?
키워드: 인덱스
배열은 처음에 메모리 공간을 정한 뒤 메모리 주소를 부여함. 이게 인덱스
메모리 공간이 정해져있기 때문에 삽입과 삭제는 어려움. O(n)
삭제를 할 때를 예를 들어보자.
공간이 7개 있고, 그 공간에 모두 값이 있다 친다.
0 1 2 3 4 5 6
index 3의 값인 3를 지우면, 값만 지워지고 공간은 안지워진다.
0 1 2 X 4 5 6
그리고 index 4부터 6까지의 값을 쭉 앞으로 당김
0 1 2 4 5 6 X
그리고 index가 6인 공간을 지움대신 인덱스가 있어서 조회 쉬움. O(1)
링크드리스트는 값과 방향으로 이루어져 있음. 조회할 땐 O(n), 양끝이 아닌 값을 수정할 땐 O(n)의 시간복잡도가 됨
그렇다고 배열과 같은 O(n)은 아님.
[2] TCP와 UDP의 차이점은?
키워드: 안정성, 속도
TCP는 안정성이 높고 느리다, 하나라도 데이터가 손실되면 아예 못 받을 수도 있음.
UDP는 TCP와 다르게 두 당사자 간 연결을 하지 않아 데이터가 손실될 가능성이 있지만, 빠름
[3] HTTP와 HTTPS의 차이점?
키워드: 암호화
HTTP는 네트워크를 통해 데이터를 전송하는 데 사용되는 프로토콜(정보를 표현하기 위한 규정된 순서와 구문)임
HTTP는 암호화 되어있지 않기 때문에, 보안에 취약한 반면
HTTPS는 암호화되어있음. 암호화 하는 방법은 2가지인데,
[4] 객체지향 프로그래밍의 4가지 주요 개념은 무엇인가?
- 캡슐화
- 상속
- 다형성
- 추상화
[5] 상속과 다형성(Polymorphism)의 차이점은?
부모클래스를 자식클래스에게 메서드 등등을 물려주는게 상속.
한 부모 클래스에서 여러 자식 클래스가 나오는게 다형성.
[6] SQL과 NoSQL의 차이는 무엇인가요?
키워드: 관계형
관계형/비관계형이란 행, 테이블 또는 키가 포함되냐에 따라 달라짐.
SQL은 관계형, NoSQL은 비관계형이라 더 빠르고 유연
[7] SQL에서 JOIN의 종류와 각각의 차이점은?
구글링 하면 나오는 글.. 굳이 외워야 하낭? 헤헤
사실 구글링 하기 귀찮은거 맞음

INNER JOIN: 두 테이블 모두에서 일치하는 값을 갖는 레코드를 반환.
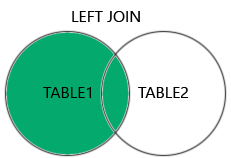
LEFT JOIN: 왼쪽 테이블의 모든 레코드와 오른쪽 테이블의 일치하는 레코드를 반환.
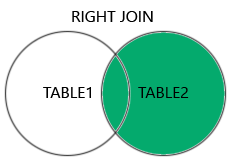
RIGHT JOIN: 오른쪽 테이블의 모든 레코드와 왼쪽 테이블의 일치하는 레코드를 반환.
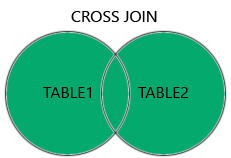
CROSS JOIN: 두 테이블의 모든 레코드를 반환.
[8] 서브쿼리와 조인의 차이점은?
서브쿼리 길고 성능 구림. 그리고 내 기준 가독성도 별로인 것 같음
where절에서 집계함수 안되어서 서브쿼리 쓰는거 봤는데 매우 귀찮아 보임.. 왜 막은건데 대체
요즘은 서브쿼리 써도 join으로 바꿔서 진행된다고 한다. 그러니까 join쓰라고 모 튜터님이..
참고자료
민준튜터님
HTTP / HTTPS 차이
SQL과 NoSQL차이
