https://www.youtube.com/watch?v=-h_uxJiiiqg&list=PL4SIC1d_ab-aOxWPucn31NHkQvNPHK1D1&index=2
위의 강의를 보고 C++을 기초부터 학습하려고 한다.
추후 C++을 통한 알고리즘 구현까지 연습해야한다.
그렇기에 총84개의 강의를 4일안에 끝내고, 나머지를 익히는 것이 좋을듯 하다.
완벽하게 기초부터 다루기 때문에, 배우면서 C#과 다르거나 특이한 부분,
기억해야 하는 것 위주로만 추리려고 한다.
2강 - 자료형
char이 정수형 자료형이다. // C#에선 문자형
char은 1바이트를 담을 수 있고 = 256비트, -128~127까지를 다룬다.unsigned char에 256을 담는다면, 0
unsigned char에 -1을 담는다면, 255
왜냐하면 1111 1111에 0000 0001을 더하면 1 0000 0000인데 뒤 8자리만보임
같은이유로 0000 0000에 1 111 1111을 더하면 1111 1111이다.
그러니까 일단 더하고, 인식하는 수는 현재의 자료형에 맞게 변환하는 것이다.
3강 - 정수형 자료형
0 111 1111은 127이고,
1 000 0001은 -127이다.
컴퓨터는 뺄셈도 덧셈처럼 하는데, 둘이 더하면 0이 되기 때문0 000 0001은 1이고,
1 111 1111은 -1이다.그러니까 char형(8비트)은
MSB를 넣어서 다른 자료형과는 다른 수로 인식을 하는데,
계산을 하고, 결과를 인식하는데 있어서는 똑같다. MSB까지 더해버린다.unsigned char의 255와 char의 -1은 실제로 메모리엔 같은 값이 들어가 있다.
자료형 때문에 인식하는 것만 다르다.2의 보수법
음수를 빠르게 찾는 법은, 양수의 비트의 반대부호로 모두 작성하고, 1만 더하면 된다.
그 이유는, 비트를 반대부호로 작성한것을 양수와 더하면 1111 1111이 되는데,
1만 추가로 더하면 1 0000 0000으로 0이 되어버리므로, 음수가 된다.
4강 - 실수형 자료형
컴퓨터에서 실수는 정확한 실수값이 존재할 수가 거의 없다.
그 이유는 실수를 표현하는 방식에 있어서그런데,
2.856에 대해서 표현하고자 한다면,
정수부분은 1이지만, 실수부분은 2진법으로 표현하기 힘들다.2진수가 증가할 수록 2가 곱해지듯이, 소수로 자릿수가 감소할 수록 2를 나눠준다는 개념으로, 정수부분 1뒤에 덧붙인다.
2진수로 1.1이라면, 2.5를 의미한다.
그 이유는, 소숫점의 2진수가 2개면 자릿수가 증가하는데,
그게 10진수에선 0.5에 해당한다.
그래서 2진수의 0.1이, 10진수에서는 0.5라는걸 기준으로,
0.01은 0.25, 0.001은 0.125, 0.0001은 0.0625 .... 로 나아간다.그래서 0.856을 위의 숫자들로 표현이 가능해야하는데,
우선 0.1(2)하면 0.356(10)을 표현해야하고,
0.11(2)하면, 0.106(10)을 표현해야하고,
0.1101(2)하면, 0.0435....인데보면 알듯이 0.5를 2의 거듭제곱으로 나눈 수로만 표현을 해야하기에
정확한 표현이 불가하다.
따라서 실수를 대상으로 if문을 적는 경우에 특정 값이 아니라,
범위를 조건으로 줘야 할 것이다.추가로 실수는 표현 방법도 기괴한데,
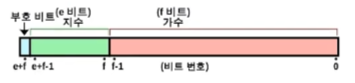
만약 계산한 값이 대충 1.1101(2)로 나왔다고 하면,
0.11101(2)로 앞이 0. 으로 되도록 만들고, 2의 몇승을 해야 0. 이 없어지는지
여기서는 5에 대한 값을 추가로 적는다 2진수로는 101(2)
그래서 맨 앞은 MSB 부호, 그리고 지수 101, 그리고 가수 11101을 적게 된다.
(정해진 비트가 존재해서, 그 사이는 0으로 채움 ex)지수부분-000101)double(8바이트)가 그래서 float(4)보다 더 정확한 실수를 표현할 수 있다.
(계속 작은수라도 빼고빼고 하기때문에)
빼고뺀다는 말에 그럼 무조건 원래의 실수보다 작은수가 나와야 겠다라고 헷갈릴 수 있는데,
그냥 가장 가까운 값을 찾아낸다.
만약 1.14라면 1.140000000100000 으로 나오게 된다.
5강 - 산술연산자
실수에 f를 붙이면 float타입으로 자동으로 인식을 하게 되고,
붙이지 않으면, double로 인식을 하게 된다(8바이트)7강 - 논리연산자
bool은 true, false값이 들어갈 수 있고, 1, 0, 100(=1)도 가능하다.
0은 false를 나타내고, 0이 아닌 모든수는 true를 의미한다.unsigned int isStatus = 0; isStatus |= 1; //비트합 연산자 isStatus |= 2; //... 4 ... 8 ...16 ...32...라고 한다면, 32비트인 int형 각각의 비트를 플래그의 집합체로 쓸 수 있다.
지금 상태는 (0 생략) 0000 0011이 된다.그리고 다음과 같은 구문도 가능하다.
if(isStatus & 2){ //2자리에 비트가 존재한다면 실행 }
isStatus &= ~2; //2인 자리만 0으로 만들어 빼는 구문비트는 쓸 경우가 많이 없지만,
특정 캐릭터의 상태를 표시할 때 쓰면 좋을 것 같다.
이 경우 비트연산자를 써야하고, 11강을 다시 보자.

디버깅에 관한 단축키가 가장 중요한 듯 싶다.
나중에 알고리즘 공부할 때, 많이 써보자
20강 - 배열
int 배열의 초기화는 0
cpp의 경우, 배열의 index를 초과하여 값을 대입했을 때,
우연치않게 관련없는 변수의 주소와 일치하여 값이 들어가는 경우가 존재하는데,
이 경우 오류가 발생하지 않는다. 그러므로 유의해야한다.
typedef int INT; typedef struct one { int a; int b; }AB; int main() { INT a = 1; AB abstruct_1; struct one abstruct_2; one abstruct_3; //이건 C에서 오류가 나는 C++만의 개선점이다. return 0; }위 구조체 예시를 보면 typedef에 대해서 알 필요가 있다.
typedef는 자료형을 다른 이름으로 바꿀 수 있도록 해주는 것이다.
그래서 int 대신 INT로 써도 상관이 없다.
struct의 경우도 마찬가지로,
struct one{} 이라는 사용자가 정의한 자료형을 AB라고 이름붙여 쓸 수 있다.
혹은, struct one을 그대로 쓸 수 있다.
(int를 그대로 쓰듯이)
abstract_3은 C에선 사용 못하는데, C/C++에 모두 쓰이는 코드인
AB를 쓰는 것이 맞다고 생각이 든다. 크게 힘든것도 아니므로.typedef struct one { int a; float b; }AB; int main() { AB abstruct_1; struct one abstruct_2; AB a = { 1.2f, 1 }; //구조체의 초기화, 순서대로 들어간다. return 0; }구조체의 초기화는 위처럼 할 수 있다. 그냥 값을 준 순서대로
a와 b에 들어간다. a는 1.2에서 정수부 1이 되고, b는 1.0이 된다.
자료형에 맞추서 들어가는건 아니었다
22강 - 변수와 메모리
C++ 변수의 종류는 4가지
1. 지역변수
2. 전역변수
3. 정적변수 (static) - later
4. 외부변수 (extern) - laterC++ 메모리영역은 4가지
1. 스택영역
2. 데이터 영역
3. 읽기 전용(코드, ROM) - later
4. 힙 영역 - later1-지역변수는 1-스택영역에 존재한다.
함수내에 존재하는게 지역변수인데, 해당 함수는 Main함수도 그렇고
스택영역에 쭉 쌓였다가 호출이 끝나면 스택에서 사라지는 방식이기 때문이다.2-전역변수는 2-데이터영역에 존재한다.
데이터 영역은 프로그램이 시작과 동시에 생성되고, 종료시에 해제된다.
그렇기에 전역변수도 같은 성질을 갖는다.3-정적변수, 4-외부변수는 모두 2-데이터영역에 존재한다.
다시본다.
C++ 메모리영역은 4가지
1. 스택영역 - 스택영역에 들어온 값들은 스택이 해제되면 사라짐.
2. 데이터 영역 - 프로그램 시작과 동시에 생성, 종료시에 해제.
먼저 정적변수, 외부변수를 설명하기 전에 헤더에 대해서 알아야 한다.
헤더랑 파일을 분리해서 구현할 필요가 있다.
int Add(int, int); //이 부분때문에 헤더가 필요 int main() { printf("%d", Add(1, 3)); } int Add(int a, int b) { return a + b; }Add라는 함수를 만약 main뒤에 놓았을 때,
보통 main부터 실행되므로 정리차원에서 분할구현
C++는 오류를 발생시킨다.
왜냐하면 위에서부터 읽는데 Add라는 함수가 없는데 main에서 미리 썼으므로.
그래서 위처럼 int Add(int, int); 문을 적어서 방지하는데,
이를 헤더에 몰아서 할 수 있다.#include <iostream> #include "func.h" //int Add(int, int); int main() { printf("%d", Add(1, 3)); } int Add(int a, int b) { return a + b; }그래서 위처럼 헤더에 해당 코드를 넣고 include하여 대체할 수 있게 된다.
참고로 #include라는 것은, 해당 파일을 그냥 복사해서 맨 위에 붙여넣겠다는 의미와 같다고 한다.아니면 그냥 헤더에 함수들을 모두 구현해놓으면 #include만 하면 언제든
쓸 수 있게 된다.그리고,
func.h라는 헤더파일에 Add를 #include하고 구현을 한 cpp파일이라도 했다면,
하나의 exe 파일이 되었을 때, 다른 cpp파일에서 Add를 main밑에 구현하지 않아도,
링커가 알아서 연결해준다고도 한다.즉 헤더를 쓰는 이유는, main함수에 모두 구현하지 않고,
개발자들이 코드를 더 손쉽게 관리하기 위함이다.
만약 적에 대한 공통적 기능을 모아놓은 헤더가 존재한다면,
나중에 오크라던지 고블린이라던지 해당 헤더만 include하면 될 것이다.참고로 C++ 컴파일러 에러코드 앞의 L은 링크 단계의 오류이다.
링크단계란 컴파일단계 다음으로, 컴파일단계에서 검사하는 문법적 오류는 없었으나,
링크단계에서 오류가 발생했다는 것이다.

23강 - 분할구현의 문제점
헤더라는 강력한 분할 구현에 대해서 보았다.
헤더에 모든 기능을 구현해 놓고, #include해서 가져와 쓴다면 될텐데
헤더는 왜 또 여러개 만드는 것일까에 대해서 보면
#include는 코드를 복사해오는 개념이라고 했다.
그러므로 참고하는 파일마다마다 모두 복사해야하므로 효율적이지 않다.똑같은 이름의 함수를 여러개 만들경우, 오류가 발생한다.
#include를 하면, 참조한 모든 파일에 이미 구현이 된 같은 함수가
여러개 존재하기 때문에, 링크단계에서 오류가 발생한다.
.
이를 막기 위해선 22강에서 봤듯이,
헤더에 함수의 정의만해두고, 단 하나의 파일에서 해당 함수를 구현을 하고,
다른 파일에선 해당 함수를 구현없이 사용만 하면 된다.//func.h 헤더파일 //여기서 Add를 정의해버리면 생기는 문제 #pragma once int Add(int a, int b) { return a + b; }//그냥 func.cpp이고, 그냥 include만 했다. #include "func.h"보다시피
기존 cpp파일과, 새로만든 func cpp파일 각각에서 #include만 했다.
여러번 정의했다고 오류가 나오는 모습을 볼 수 있다..!
//func.h 헤더를 함수의 정의만 해놓고, #pragma once int Add(int, int);//func.cpp에서만 구현을 해주니 #include "func.h" int Add(int a, int b) { return a + b; }
정상동작한다.다시 가져온
C++ 변수의 종류는 4가지
1. 지역변수
2. 전역변수
3. 정적변수 (static) - later
4. 외부변수 (extern) - laterC++ 메모리영역은 4가지
1. 스택영역
2. 데이터 영역
3. 읽기 전용(코드, ROM) - later
4. 힙 영역 - later여기서 전역변수를 보면,
전역변수는 데이터 영역에 존재했고,
프로그램이 시작됨에 따라 생성되고, 프로그램이 종료해야지만 사라진다.분할 구현에서의 전역변수는 무능하다.
전역변수는 컴파일이 되고 하나로 합쳐져서야 존재를 알릴 수 있는데,
각 파일마다 코드를 보는 컴파일 시점에서는, 정의되지도 않은 변수가 존재하므로 바로 오류를 낼 것이다.그런데 전역변수는 프로그램 시작부터 끝까지 계속 살아있는 존재인데
모순적이게도 전역변수는 모든 파일 전역적으로 쓸 수 없다.
이를 보완할 수 있는게 없을까라는 생각으로 나온 것이생략그러면 헤더에 전역변수만 추가하고 모든 cpp가 #include하면 되지 않을까?
#include는 말그대로 복붙이기 때문에, 각 파일에 전역변수가 생기게 되고,
컴파일시점에서는 문제가 없지만, 파일 각각의 Obj파일이 만들어지고,
그 다음 Exe파일로 합쳐지는 과정에서, 같은 이름의 전역변수가 있다고 서로의 존재가 드러나기 때문에, 오류가 발생하게 된다.

25강 - 정적변수, 외부변수
static은정적이라는 의미,
절대 움직이지 않는다.전역변수 int i를 func.cpp, basic.cpp에 모두 선언해보았다.
당연히 안된다.
왜냐하면 나중에 각 파일의 obj들이 exe로 합쳐졌을 때,
해당 i 가 누구의 i 인지 모르기 때문이다.이제 각각
static int i로 선언문을 main밖에 추가해 보았다. 오류는 없다.
그 이유는 정적이다라는 개념에 맞게, 같은 이름이지만,
이건 basic만의 i 이다, 이건 func만의 i 이다라는 것을 static이라는게 이해시키고 있기 때문이다.
그냥 김용명씨가 아니라,
한국에 사는 김용명씨, 수리남에 사는 김용명씨로 특정할 수 있다는 것이다.
전역변수처럼 쓰이면 해당 파일 내에서만 사는 변수로 특정할 수 있다는 것이다.static의 자신이 설정된 위치에서만 동작한다는 제한적이지만 강력한 특성이다.
하지만, 모든 파일에서 전역적으로 쓰이고자하는,
단 하나의 대표 김용명씨는 만들 수 없었다.static이 함수 안에 지역변수처럼 쓰이는 경우에 대해서도 보자.
#include <iostream> int k; //전역변수 int Test() { //돌때마다 전역변수와 정적변수를 +1하는 함수 static int i = 0; ++k; ++i; return i; } int main() //Test는 총 5번 돌게 된다. { Test(); Test(); Test(); Test(); printf("%d", Test()); k = 0; //이 문장 하나 때문에 static을 쓸 이유가 생긴다. printf("\n%d", k); }보면 Test함수에서 전역, 정적변수를 1씩 증가시킨다.
Test는 총 5번 실행, 각각은 5가 들어가 있어야 하고,
(지역변수처럼 쓰인 정적변수는 해당 함수 내에서만 수정이 가능하다.
추가로, static int i = 0;라는 구문은, Test를 돌때마다 실행하는 것이 아닌,
초기화를 0으로 해라라는 단 한번만 실행되는 구문이다.)굳이 정적변수가 필요하지 않은 같은 기능을 보여주나,
static의 자신이 설정된 위치에서만 동작한다는 제한적이지만 강력한 특성
때문에, 사용하는 경우가 존재한다.k=0으로 바꾸면 곧바로 전역변수의 값이 수정된다.
하지만 전역변수는 접근할 수 없다. 그래서 사용된다.
그리고 스택영역인 함수의 종료에 상관없이 계속 데이터 영역에 남아있게 된다.하지만 다른 파일에서도 쓸 수 있는 단 하나의 정적변수가 되지 않았다.
그렇다면 전역변수가 실패했던 헤더에 넣는다면..?


