전체리뷰를 5일차에 해서
4-5일차 복습만 다시 해보자.
클래스에 대해서 헷갈리는 부분이 많았었다.
접근제한자를 둘 수 있게 된다
접근제한자는 정확하게는 모르겠는데, 코드를 쳐보니
구조체와 클래스에서만 지정할 수 있는 듯 하다.
클래스와 구조체는 C++에서 같다고 보면 되고,
차이점은,
클래스는 기본 접근제한자가 private인데 반해,
구조체는 public인 것 뿐이다.
C++에서 구조체는 C와 다르게 typedef없이 그냥 써도 되며,
C에는 없고, C++에서만 클래스가 구현이 되었다.
Class에는 특이하게 생성자라는 것이 존재하고,
해당 Class자료형으로 객체가 생성이 된다면,
자동으로 생성자가 호출이 된다.
없을 경우, default 생성자라도 호출이 된다. 아무 기능이 없음
new 키워드와 연관있다.
new라는 것은, 힙메모리에 해당 타입만큼 malloc을 하고,
해당 주솟값을 전달한다.
new가 대단한것은, malloc이라는 void포인터는 자료형을 직접 선언했어야 했는데, new는 자료형만 넘겨받아서, 해당 자료형 크기에 맞게 메모리도 할당하면서, 자동으로 그 메모리를 해당 자료형으로 인식하게까지 한다.
반대로, 함수가 완료하고 스택메모리에서 사라지거나,
강제로 메모리를 해제할 때, 소멸자가 자동으로 호출이 되는데,
사용자가 정의하지 않았을경우, default 소멸자라도 호출이 된다.
delete 키워드와 관련이 있다.
iarr = new int[2];
delete[] iarr;위처럼 자료형을 배의 크기로 설정하였다면,
delete[]를 사용한다.
[이 시점에서 헷갈리는 것들]
AB str = {};
AB* pt = &str;
(*pt).i = 1;
(*pt).f = 1.5f;
pt->i = 100;
pt->f = 150.5f;위 둘은 같은 것이다.
구조체를 포인터로 만들고, 해당 구조체의 주소를 저장했을 때,
해당 구조체의 멤버를 접근하기 위해서는 . 을 사용하는데,
해당 주소를 역참조한게 구조체객체이므로, *와 .을 같이 사용한다.
이걸 축약한게 -> 이다.
Test t;
std::cout << t.a;
Test* t = new Test;
std::cout << t->a;코드를 짜다보면, 언제 . 을 써야하고, 언제 ->를 써야하는지 헷갈렸는데,
위처럼 Test라는 구조체를 일반 지역변수로 선언을 했다면,
그냥 그게 객체 그 자체라서 . 으로 접근이 가능하다.
하지만 Test*라는 포인터로 선언을 하면, t에는 해당 구조체의 시작 주소가 들어가게 되고,
포인터이므로 주소를 통해서 멤버변수에 접근하기 위해서는,
역참조 후 . 을 찍어야하는데 이걸 ->라고 하기로 했기 때문에,
위처럼 쓰일 수 있게 된다.
int main()
{
cObj c;
c.setInt(1);
_setInt(&c, 1);
}
---
void setInt(int num) {
a = num;
}
void _setInt(cObj* _this, int num) {
_this->a = num;
}위는 원래 C에서는 _setInt처럼 객체의 주소와, 값을 줘야만 했는데,
C++에서는, c.으로 접근을 하면 알아서 해당 멤버함수에,
본인 객체의 주솟값을 전달해준다. 그리고, 본인 객체인것을 명시할 수 있기 때문에,
this를 붙이지 않고도 멤버변수를 그대로 사용할 수 있다.
int main()
{
cObj c1;
c1.setInt(1);
cObj c2;
c2.setInt(10);
int a = 1, b = 3;
a = b;
c1 = c2; //어떻게 동작하는 것일까?
}그렇다면 위의 c1 = c2; 의 동작은 어떻게 되는 것인가 본다면,
우선 =은 함수라고 보면 된다.
형식은 c1.=(c2) 이런 꼴이라고 인식하면 될 것이다.
그렇게 된다면, c1의 멤버함수 =에,
보이진 않지만, 본인 객체인 c1의 주솟값을 this로 전달하고,
추가 매개변수인 c2를 전달할 것이다.
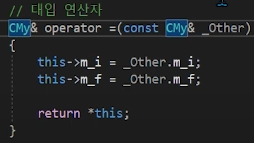
위에서 this->는 생략이 가능하다고 했다.
왜냐면 명시적으로 this가 뭔지 넘겨주었으니까.
멤버변수가 this의 멤버변수인 것을 명시할 수 있으므로.
그래서 c1의 m_i, m_f에 c2의 i,f를 각각 받는데,
원래 방식대로라면,
해당 c2라는 클래스가 현재 지역변수기 때문에, 객체를 그대로 받아도 의미가 없어서,
객체의 주소를 따로 받아서 "&c2로" 매개변수를 CMy* 포인터로 받고, _Other->m_i와 같이 접근해야 했을 것이다.
하지만, 여기서 처음 등장한 & 라는 레퍼런스 자료형은
int& iRef = a;
iRef = 100;위처럼 쓰이는데, a의 주소를 iRef에 저장하고,
그 이후로 iRef는 참조기호없이 a처럼 사용할 수 있게 된다.
그래서 CMy&로 매개변수를 받았다는 것은,
CMy& _Other = c2라는 것이고,
해당 c2객체의 주솟값을 받아서 _Other 에 저장하고,
Other는 결국 c2객체 그대로 처럼 사용할 수 있게 되기 때문에,
아래 식에서 그냥 . 을 찍어서 멤버변수에 접근할 수 있게 된다.
레퍼런스 변수를 간단히 보려면 그냥
포인터-const형이라고 보면 되는데,
한번 정해진 주솟값을 바꿀 수 없기 때문이다. == 연결된 객체를 바꿀 수 없다.
그래서 const레퍼런스변수는, const-포인터-const처럼 보면 되고,
연결된 객체도 못바꾸고, 해당 객체의 값도 못바꾸는 제한만 건 것이다.
해당 =연산의 원리를 생각해보면 되는데,
왼쪽에 오른쪽 값을 대입하는 것 뿐이지, 오른쪽의 값을 굳이 바꿀 필요는 없으므로, const를 붙인 것이다.
그래서 이제 리턴타입만 보면 되는데,
해당 = 연산자가 c1=c2만 있으면 그냥 return값이 없어도 상관없다.
대입하고 끝내면 되니깐
근데, c1=c2=c3 이런 경우에선,
c2=c3를 먼저 계산하고, 해당 값을 c1에 넣어야 하기에
값이라는게 리턴이 되어야 한다.
그래서 리턴자료형은 무조건 있어야하고,
해당 리턴값이 결국 매개변수로 들어가야 하므로,
자료형을 맞춰서 CMy&형으로 리턴하게 된다.
그리고 this라는 현재 바뀐, 왼쪽에 있던 클래스의 주소가
*가 붙어 객체화 되어, 매개변수 &연산에 다시 쓰이게 되는 것이다.
클래스에서, 해당 클래스의 선언부에 함수를 표기해두고,
선언부 외에서 클래스를 구체화 할 때,
반드시 :: 를 사용하여 명시해주어야 한다.
당연한 소리. 선언부 괄호 밖에 나가면 그냥 다른 지역이다.
클래스 템플릿을 만들때 가장 중요한 것중 하나가,
템플릿의 함수들의 구현은 무조건 헤더에 있어야 한다.
템플릿클래스를 헤더와 cpp로 나눠서 구현한다면,
헤더는 #include로 인해서 컴파일타임에 존재를 알리게되고,
cpp파일은 링크타임에 존재를 알리게되는데,
헤더라는게 있고, 기능이 존재하는데 구현이 안되어있다는 것을
컴파일러가 인식을 하고 오류를 발생시키기 때문에, 헤더에 구현되어야 한다.
굳이 분할 구현을 한다면 #include를 활용하여 템플릿을 사용하는 cpp에,
템플릿클래스가 구현된 cpp파일을 #include하여 컴파일타임에 인식시키면 될 것이다.
템플릿을 적용하여 함수선언부 밖에 멤버함수를 정의하면
매우 복잡해보이게 된다.
template<typename T>
void CArr<T>::resizeArr(int size)복잡하지는 않지만,
template를 사용한다는 것을 명시해야하고,
왜냐면 밖에 선언되어서 CArr의 멤버함수임을 CArr을 써서 ::를 붙여서 알려야하는데 CArr이 template를 사용하고 있으므로 명시해야한다.
해당 resizeArr도 결국 template가 적용되어 T를 사용할 수 있게 된다.
namespace는 그냥 협업과정에서의 혼선을 막기위해,
특정 기능이나 변수명을 폴더처럼 묶어서 이름지은 것이다.
그래서 해당 namespace내의 기능을 사용하기 위해선,
YU::cout 이런식으로 클래스외부의 멤버함수 표현처럼 사용하고,
아마 같은 의미이지 않을까 싶다
using을 사용하여, using namespace YU;를 한다면,
그냥 cout으로 사용할 수 있게 된다.
하지만 이는 추천하지 않는다.
그래서 std::cout도 같은 원리로, cout이란 함수이고,
<<를 재정의 하여
std::cout<<"안녕"<<10<<std::endl; "안녕10\n"로 출력이 될 수 있는 것이다.
STL - standard template library
자료형이 구현되어있다.
Vector - 가변배열
List - 리스트
그래서 각각의 기능들을 살펴보았고,
실제로 사용자정의 클래스로 구현하는 시도를 했다.
그 중 Vector.begin();을 하면
가장 처음 노드의 값을 빼온다거나
하는 기능을 위해서 iterator를 사용한다.
반복자라고 하고,
자료구조안의 데이터를 간단하게 접근 및 순회할 용도로 만들어졌다.
자료형마다 iterator관련 함수가 존재하고, 기능은 같지만,
자료구조가 다르기에 작동방식이 다르다.
list<int>::iterator _iter = listInt.begin();
for(_iter; _iter!= listInt.end(); _iter++){
//이렇게 구현
}위처럼 이터레이터를 선언하고 사용하게 된다면,
++를 했을때, Vector의 경우 다음 인덱스를 가리키고,
List의 경우는 다음 노드를 가리키게 된다.
선언부를 보면, 해당 자료형의 멤버로서 존재하는 것을 볼 수 있고,
멤버 클래스로 존재한다고 한다.
template<typename T>
CArr<T>::iterator CArr<T>::begin()
{
return iterator(iarr, 0);
}iterator를 반환하는 begin이라는 함수를 직접 만들어본 것이다.
iterator의 생성자로 현재 자료형객체의 시작값과, 인덱스를 받도록 만들었다.
여기까지 복습을 마치고, 이제 공부를 해보자.
