
어제 map을 만들면서 왜 문자열을 const wchar_t*로 만들어야 하는가
생각을 했었는데, 멍청한 생각이었고,
문자면 그냥 wchar_t를 했어도 됐는데, 문자열이라서, 해당 주소를 넘겨주어서 \0인 null까지 읽어야하기 때문에 포인터로 받아오는 것이다.
_wsetlocale(LC_ALL, L"");
//mapData.end()는 이터레이터 함수.
if (mapiter == mapData.end()) {
//값이 존재하지 않는다.
std::cout << L"값이 존재하지 않습니다." << std::endl;
}
else {
//값이 존재한다.
std::wcout << L"이름 : " << mapiter->second.name << std::endl;
std::wcout << L"나이 : " << mapiter->second.age << std::endl;
std::wcout << L"성별 : ";
if (mapiter->second.gender == MAN) {
std::cout << L"남자" << std::endl;
}
else if (mapiter->second.gender == WOMAN) {
std::wcout << L"여자" << std::endl;
}
else {
std::wcout << L"잘못된 성별" << std::endl;
}
}찾는 값이 만약에 존재한다면,
세부 정보를 표시하도록 하였다.
구현하면서 cout부분에서 출력이 숫자로 되고, 보이지 않는 오류가 존재했는데,
L이라고 2바이트 문자열의 출력을 명시할 때는, wcout으로 2바이트출력을 해야하고,
그랬는데도 출력이 안된다면,
_wsetlocale(LC_ALL, L""); //L"korean"으로 특정할 수도 있다.해당 코드를 작성하면 정상적으로 동작한다.
하지만 여태 만들었던 맵은, 정상이 아니다.
map<const wchar_t*, stdInfo> mapData;이 글의 맨 처음부분을 보면 알 수 있는데,
wchar_t*라는 것은 포인터이고, 주솟값을 받아오는 것이다.
즉,
이름의 사전 순서대로 key값을 정렬하는 것이 아니라,
이름이 저장된 ROM의 주솟값을 정렬하는 것이었다.
그러면 포인터를 쓰지 않고, 문자열을 넣을 수 있는 방법이라는게 있을까?
#include<string>
using std::wstring; //2바이트 문자열
map<wstring, stdInfo> realMap;위처럼 string이라는 헤더를 참조하면 된다.
wstring str;
str = L"한글은";해당 string의 동작방식은,
L"한글"하면 해당 ROM 주소값을 받아서 그대로 저장하는것이 아니라,
string변수가 R-value에서의 문자열의 주소값을 받고,
이를 활용하여 본인이 할당한 공간에 값을 받는다.
str += "세종대왕이";
str += "만든";이런식으로 str에 추가를 할 수도 있다.
그러면 원하는 만큼 string을 넣을 수 있다는 것인데,
메모리공간을 어떻게 관리하는 것일지는 모르겠지만,
동적으로 할당하기 때문에 원하는만큼 넣을 수 있다는 것을 알 수 있다.
굳이 자료형으로 보자면, Vector에 wchar_t를 담는 모습으로 구현이 가능할 것이다.
str[1] = L'ㅋ';
if(str1 < str2)위처럼 값의 변경, 비교연산도 가능하다.
wchar_t처럼 ROM의 주솟값이 아니라 직접 관리하는 메모리를 접근하기 때문.
자체적으로 문자로서 비교하도록 구현이 되어있다.
그래서 결론적으로 string이 map의 key자리에 들어갈 수 있는 이유는,
비교연산이 가능하기 때문이다.
뭐가 더 큰지, 작은지 비교가 가능해서 정렬을 할 수 있기 때문이다.
map<first, second> 자료형 2개는 뭐가 오든 상관이 없다고 했다.
하지만, first인 key값에 해당하는 자료형은 반드시 비교연산이 가능해야하고,
사용자정의 클래스, 구조체의 경우, 오퍼레이터 오버로딩을 하여
비교연산을 구현하지 않았다면, 절대 사용할 수 없다.
class MyClass{
int a;
public:
//const가 붙은 이유는 나중에 설명
bool operator < (const MyClass& _other) const
{
if(a<_other.a)
return true;
else
return false;
}
}
//나머지 >연산 ==연산까지 구현해야 함위처럼 하나하나 연산자를 오버로딩해야만 사용 가능하다.
어찌보면 너무나 당연한 소리이다. key를 비교를 할 수 있어야만 하니깐.
//열거형
enum E {
MON,TUE,WED,THU,FRI=100,SAT,SUN
};
int a = MON;enum이라는 열거형이라는 것이 존재한다.
enum으로 선언하고, 초기화를 위처럼 그냥 이름들을 나열한다.
그러면 순서대로 1,2,3,4~의 값을 가지는데,
중간에 FRI=100 선언하면,
그 다음 이름은 101, 102 이렇게 매핑되는 식이다.
enum class U{
MON, TUE,
}
int b = (int)U::MON;위처럼 enum class라고 적어주는 것이 생겼다.
enum으로 선언해도, 같은 이름이 존재하면 오류가 생겼기 때문에,
enum class로 선언하고, E::MON, U::MON 이렇게
실제 클래스 멤버변수를 구분하듯이 중복되지 않게 사용할 수 있다.
대신에 사용할 때, 자료형도 명시해야만 하는 불편함은 존재한다.
enum class NODE_TYPE{
PARENT, //0
LCHILD, //1
RCHILD, //2
SIZE, //3
}Node* arrNode[(int)NODE_TYPE::SIZE];
NODE_TYPE nt = NODE_TYPE::PARENT;위처럼 enum을 정의하고, 보통 인덱스의 이름처럼 사용한다.
어떤 객체의 타입을 지정할 때에처럼
NODE_TYPE을 설정해둘 수도 있다.
반복적으로 자주 구현되는 기능을 상속받는 것으로,
코드의 재사용을 한다.
상속을 하면, 자식은 해당 부모의 멤버도 가지고 있다고 판단한다.
class CParent {
protected: //protected 접근제한자.
int i;
public:
CParent() : i(0) {};
~CParent() {};
void setInt(int a) {
i = a;
}
};
class CChild : public CParent {
private:
float f;
public :
CChild() :f(0.f){};
~CChild() {};
void setFloat(float b) {
f = b;
i = 10;
}
};위처럼 protected를 사용해야만 상속하는 부분에서도
접근이 가능하다.
보면, i라는 변수를 자식클래스는 선언하지도 않았는데, 대입이 가능하다.
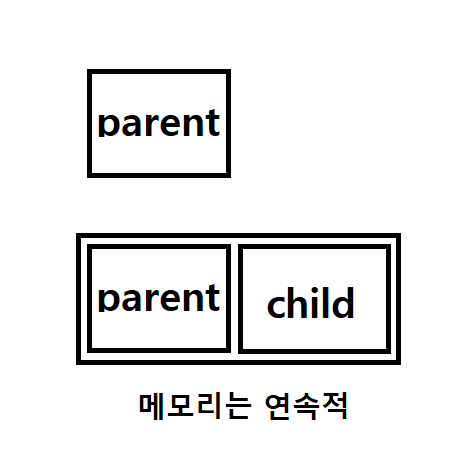
해당 자식 클래스 객체가 만들어지면, 부모의 기능을 가진채로
메모리가 부모-자식 순서대로 만들어진다.
int main()
{
CParent cp;
CChild cc;
cc.setInt(10);
}이렇게 부모쪽의 기능도 사용이 가능하다
현재 오버라이딩을 하지 않았기 때문에, 부모쪽의 기능이 실행된다.
상속에서의 생성자는 어떻게 작동할까?
자식을 생성한다면, 자식만 생성자를 호출할까?
메모리가 부모-자식 순서대로 만들어진다.는 내용을 바탕으로,
부모의 생성자와 자식의 생성자가 각각 호출이 된다.
그렇다면 자식객체를 생성할 때, 어떤 생성자가 먼저 실행되는가?
자식생성자에는 자동으로 부모생성자가 들어가있다.
따라서, 자식생성자를 생성하기 위해서 부모생성자를 모두 끝내고, 자식생성자를 이어서 실행한다.
부모가 먼저 초기화된다.
호출은 자식생성자가 먼저 호출이 된다.
CChild(): CParent(), f(0.f)
{
}이런 느낌인 셈이다.
그래서 자식생성자에 그냥 아무것도 쓰지 않고 자식을 생성하면,
부모는 기본생성자로 초기화된다.
CChild(): CParent(100, "30"), f(0.f)
{
}부모의 생성자를 int, string을 받도록 정의하고
위처럼 명시적으로 사용하면 될 것이다.
public : CChild() :f(0.f) , i(10){ //i = 10; //생성자에 호출하지 않고 초기화 }; ~CChild() {};자식생성자와 부모생성자는 각각 실행이 되는 것이 원칙인데,
위처럼 i(10)을 하는 경우에 오류가 발생한다.
하지만, 주석처럼 i=10 으로 대입하는 경우에는 오류가 발생하지 않는다.
생성자에 명시되는 초기화는 각자 생성자에서만 하라는 나름의 방어체계인 셈이다.
오버로딩 - 함수명이 같지만, 매개변수를 다르게하여 같은 함수명으로 사용하는 것
오버라이딩 - 상속관계에서만 사용가능
void Out() {
printf("부모");
};
void Out() {
printf("자식");
};부모에 하나, 자식에 하나
같은 이름으로 구현을 했는데,
일반적인 상황에서라면, 매개변수도 같기 때문에 오버로딩은 불가하다.
그렇다면, child.Out을 한다면 누굴 호출해야할까?
결론적으로 "자식"이 출력된다.
자식쪽에서 재정의하고, 더 구체화했다라고 보기 때문이다.
child.CParent::Out();그리고 위처럼 오버라이딩을 했음에도,
부모의 out( )을 굳이 호출할 수가 있다.
생성자가 각각 생성되었다면,
소멸자도 부모, 자식이 각각 호출되어야 할 것이다.
소멸자도 자식이 먼저 호출되고, 부모가 먼저 해제될 것이다.
라고 생각을 했는데,
소멸자는 자식이 먼저 호출되고, 자식이 먼저 해제된다.
상속과 포인터의 개념이 쓰인다.
CParent parent;
CChild child;
//둘 중 오류가 나지 않는 것은?
CParent* tmpParent = &chilld; //1
CChild* tmpChild = &parent; //2둘 중 오류가 나지 않는 것은
이걸 참조해보면 알 수 있다.
1번문장은,
tmpParent라는 CParent크기의 포인터를 생성했다.
그러면 해당 포인터의 역참조시에도 해당 CParent로 값을 읽을 것이다.
그 포인터에, child객체의 주솟값을 줬다는 것은,
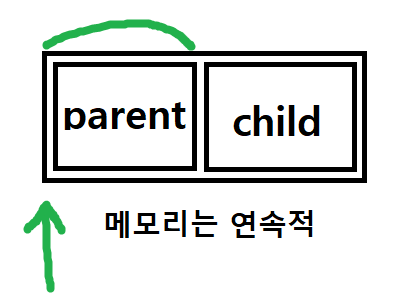
child객체의 시작을 가리키게 되는 것이고,
해당 CParent만큼의 공간을 읽어오고, 해석도 그렇게 한다면,
어짜피 child객체의 parent-child 연속적인 메모리 형태이므로,
가능하다.
반대로 2번의 경우, CChild에, CParent객체를 넣으므로,
남는 공간이 생길 것이고, child가 있어야할 곳에 없기 때문에 문제이다.
그러니까 확대해서 해석해본다면,
가장 최고 조상인 이순신이 존재하고,
해당 이순신의 자식에 자식에 자식에 자식이 와도,
맨 앞의 메모리가 이순신인 것은 변함이 없을 것이다.
항상 맨 앞에는 최상위의 parent가 존재할 것이다.
그래서 모든 파생 자식들을 parent노드에 담을 수 있다.
하지만 해당 parent 포인터에 담긴 주솟값의 실제 객체가
어떤 child인지는 모를것이다.
int main()
{
CParent parent;
CChild child;
CParent* tmpObj = nullptr;
//tmpObj가 parent를 가리킬 경우
parent.Out(); //parent의 out
tmpObj = &parent;
tmpObj->Out();
//tmpObj가 child를 가리킬 경우
child.Out();
tmpObj = &child;
tmpObj->Out();
}위처럼 실행된다면 출력결과는?
부모
부모
자식
부모위처럼 나온다.
tmpObj는 child를 받아서, child의 Out이 나오기를 기대한 것 같지만,
tmpObj는 parent포인터라서 parent부분만을 가지고 있어서
parent.Out을 실행하게 된다.
이게 맞는 작동이긴 한데 다형성이 통일성이 되어버렸다.
이걸 해결하기 위해서 C++에서는 가상함수라는 기능을 제공한다.
virtual void Out() {
printf("부모\n");
};parent의 Out부분에 virtual예약어만 붙였더니
부모
부모
자식
자식위처럼 출력이 된다.
분명 CParent포인터로 받았고, CParent객체로 인식했을텐데
어떻게 CChild로 child인 것을 구별했을까?
일단 부모포인터로 통일시켜서 모든걸 구현했지만,
기능은 자식의 기능을 쓸 수 있는 사기적인 능력이 있다.
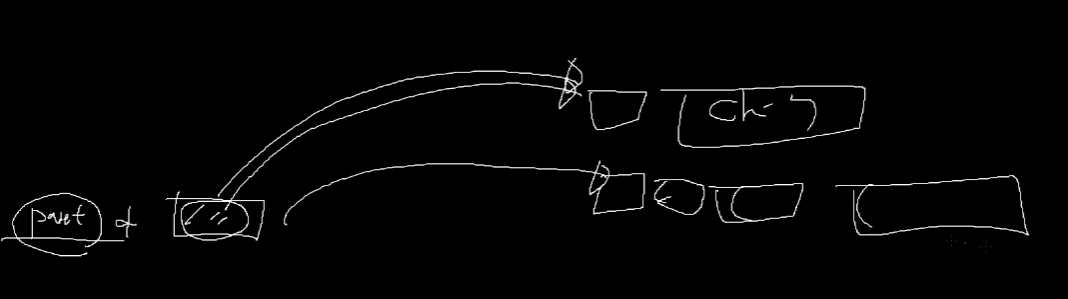
위의 그림처럼,
parent포인터로 선언하면,
분명히 자식객체가 있어도, 맨 앞 parent 부분만 인식하게 된다.
virtual을 붙이면,
virtual이 붙은 가상함수는 가상함수테이블포인터를 생성하게 되고,
각자 객체의 실행될 함수를 가상함수테이블 기록하고 포인터로 연결한다.
해당 가상함수테이블포인터로, 실제 실행될 함수를 찾는 것이다.
설명이 좀 이상해서 개인적으로 추가공부 필요
어쩄든 모든 부모와 자식객체를 부모클래스의 포인터로 통일하여 사용하고, 오버라이딩된 함수들은 virtual을 붙여서 개인적인 기능도 사용이 가능한데,
오버라이딩하지 않은 자식클래스의 개인적인 멤버함수를 사용할 수는 없다.
이를 위해서 필요한 것은 다운캐스팅이라는 것으로,
int main()
{
CParent parent;
CChild child;
//통일성을 위한 CParent*
CParent* tmpObj = nullptr;
//강제형변환
//tmpObj에 real 부모객체를 받는다.
//부모를 CChild로 강제형변환하고, child에서만 가능한 멤버함수를 실행한다.
tmpObj = &parent;
((CChild*)tmpObj)->onlyChildFunc(); //실행되면 안된다.
//다운캐스팅
CChild* castedChild = dynamic_cast<CChild*>(tmpObj);
if (nullptr != castedChild) {
castedChild->onlyChildFunc();
}
else {
printf("캐스팅 안됨, 방어적인 코딩!");
}
}강제형변환방식으로 다운캐스팅해도 되지만,
dynamic_cast라는 안전한 방식이 존재한다.
virtual로 가상함수테이블이 존재할 경우에만 가능한듯하며,
CChild*로 캐스팅에 실패할 경우, nullptr을 반환한다.
강제형변환은 CParent*로 통일 정의되어 부모인지 자식인지 모르는 객체들 중,
이건 무조건 자식일거라고 생각하는 것에 진행하는 것이고,
dynamic_cast방식은, 이걸 자식으로 바꾸는데,
자식이 아니면 nullptr을 반환해라 라는 방어책을 줄 수 있다.
방식의 차이인 것이고, 후자가 주로 쓰인다.
그런데 강제형변환은 실행이 되면 안되는데 자식의 멤버함수가 왜 오류없이 실행되는 것일까

이해가 안되는 부분도 많고,
예시코드도 동작하지 않기에, 추가 공부를 해야만 한다.
C++의 다형성, 가상함수, 다운캐스팅에 대해 추가 공부해보자
