자료구조 관련 함수 + 문자열 + Algorithm.h 함수
1. STL
1-1. STL
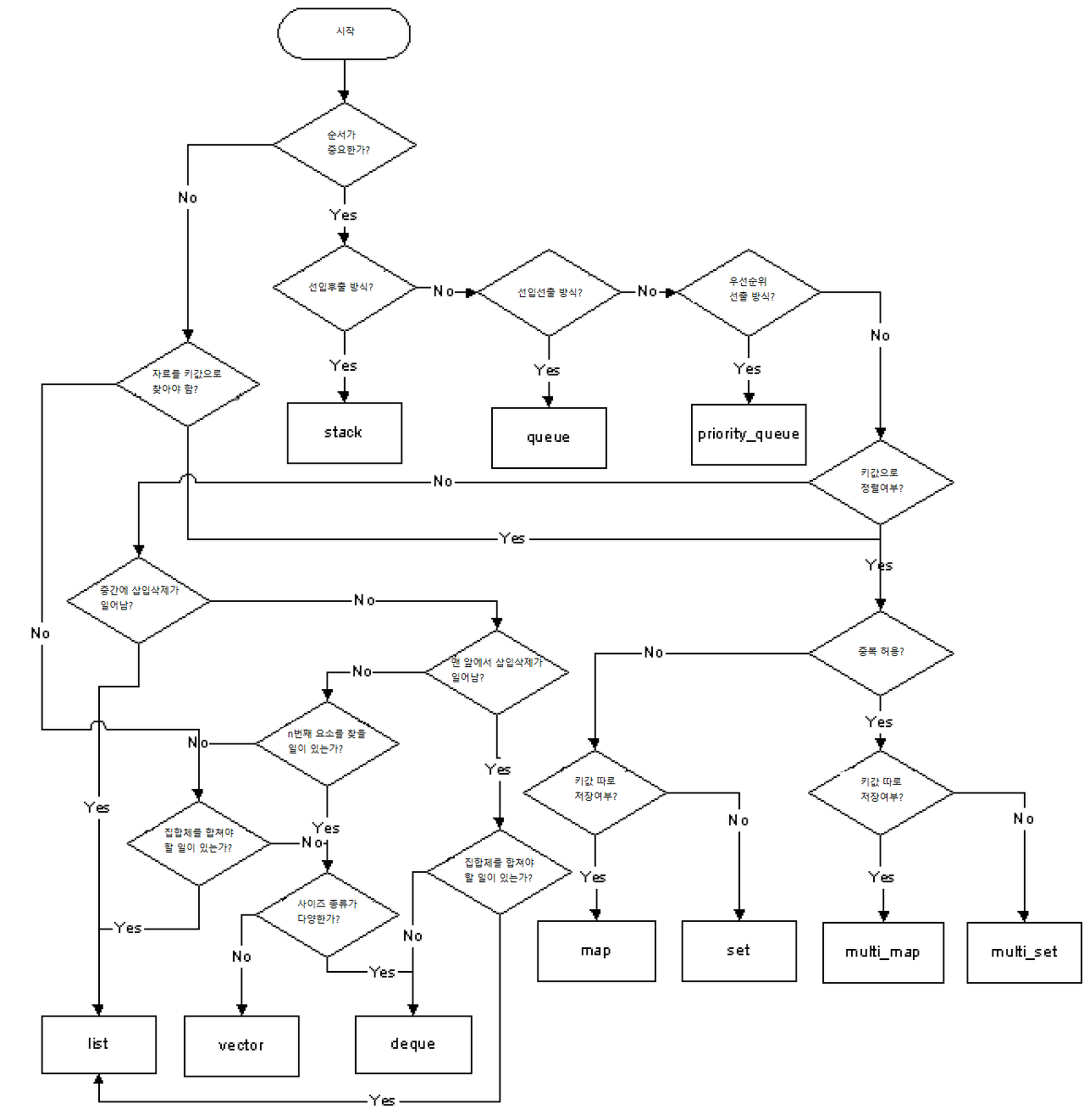
목적에 따른 자료구조의 사용 구분
https://indirect91.tistory.com/27
먼저 가장 위의
Stack / Queue / Priority_Queue
3개는 모두 순서가 중요한 정보의 저장에 쓰이는 자료구조이다.
왼쪽 아래의
List / Vector / Deque 를 본다.
이 3개의 공통점은 못찾겠다.
오른쪽 아래의
Map / Set / Multi_Map / Multi_Set / Unordered_Map
Map/Set 은 중복이 기본적으로 되지 않는 자료구조이지만,
Multi-를 붙이면 중복도 허용하는 것 같다.
참고한 사이트
값만 넣을 수 있다. Clear가 없다. empty는 당연히 end와 비교
A. Stack
#include <stack>
- LIFO인 경우 사용
- DFS 구현 / 괄호 파악 / 백트래킹 등에 사용
- deque기반의 자료형 / clear함수가 없어서 모두 pop해야함
- 삽입 삭제가 무조건 top에서 이루어짐
push / pop / (top)
- stack의 top에 추가/삭제/확인
size / empty
- stack의 크기/비어있는지
B. Queue
#include <queue>
- FIFO인 경우 사용
- BFS 구현
- deque기반의 자료형 / clear함수가 없어서 모두 pop해야함
push / pop / (front/back)
- stack의 top 대신에 front/back이 존재
- 각각 (맨 앞의 값 / 맨 마지막 값)을 확인
size / empty
- stack의 크기/비어있는지
C. Priority_Queue;
#include <queue>
priority_queue<int> pq;
- Max Heap같은 Vector 자료형 / clear 없음
- 자동으로 내림차순 정렬하는 Queue
(가장 큰 값이 Queue의 front) - 비교 기준을 직접 설정할 수 있음
Stack과 같음.
이름은 Queue이지만, top만을 사용.
(들어간 순서가 의미없기 떄문)
top은 참고로 front를 의미, 우선순위가 가장 큰 값.
Sequence Container?
D. List
#include <list>
- 이중 연결 리스트로 구현이 되어있다.
- 순회는 적고, 삽입, 삭제가 자주 일어나는 경우 사용.
따라서 for문으로 순회하는 알고리즘은 비효율적. - 인덱스를 통해서 특정 원소에 접근할 수 있다.
push_front / push_back / insert
- 맨 앞 / 맨 뒤 / 특정 인덱스에 넣을 수 있다.
pop_front / pop_back / erase
- 같은 매커니즘
(front/back)size / empty / clear
E. Vector - 가장 많이 사용되는 듯
#include <vector>
- 벡터의 초기화 방법
vector<int> vec3(vec1.begin(), vec1.end());
vector의 생성에 iterator를 넣으면 다르게 동작한다.
해당 iterator 범위에 해당하는 값들이 복사되어 생성.
- 대표적인 Sequence Container
- 쉽게 말해 가변배열
- capacity를 통해 여유로운 메모리 공간을 잡아두고,
size에 따라 capacity가 더 크게 변하는 방식으로
연속적인 메모리 공간을 사용하게 하는 방식. - 메모리가 부족하면 이전 메모리 블록을 삭제하고,
새로운 메모리 블록을 재할당, 원소값들을 복사. - 특정 인덱스의 값 바로 접근 가능 / 빠름.
push_back / pop_back / (front/back)insert / erase
- 특정 인덱스에 값을 삽입, 삭제
erase(v.begin()+2) = 3번째 원소가 삭제size / empty / clearMyVector[1]
- 인덱스로 바로 접근 가능
vector<vector<int>> v
- 2차원 벡터 가능.
F. Deque
#include <deque>
- 특정 인덱스의 값 바로 접근 가능 / 빠름.
- Vector의 capacity 방식보다 나은 chunk방식으로 확장비용절감
- 새로운 단위의 메모리 블록을 할당하고 원소를 삽입.
- 즉, 연속된 메모리 공간을 사용하지는 않음.
따라서 포인터 연산 불가. - 주로 맨앞과 맨뒤의 원소를 자주 추가 삭제하는 경우 사용.
(중간 원소 삭제는 비효율적) - 이중연결리스트와 유사한 방식인 블럭연결을 활용
(하나가 아닌 여러 값을 저장하는 큰 블럭인듯)
기본적으로 Vector와 같다.
- push_front / pop_front
- 이것만 추가됨.
Associative Container?
H. Map
#include <map>
- Key와 Value의 쌍(=pair)을 저장하는 자료구조
- 키 값이 존재 / 키 중복 X / 자료를 넣자마자 정렬
- 자동으로 (Key값에 따라) 오름차순 정렬
- Value에 따라 정렬하는 방법
- Map의 값을 pair를 원소로하는 Vector에 넣고,
해당 Vector에 sort를 사용하여 정렬.
- 이진트리를 이용한 구조 = 빠른 검색
- 정렬기준은 선언시에 지정할 수 있음.
- MyMap[“ABC”] = 3; 이런식으로 접근 가능
insert / erase
- 맨뒤나 앞에 넣는 개념은 아니므로 insert나 erase 사용
(push / pop 대신)- insert는 pair형태로 넣어야만 함
find
- key값에 해당하는 반복자 리턴.
- 사실 반복자가 의미가 없으므로, 해당 key값이 존재하는지
파악만하는 용도로 보임.size / empty / clear- 추가로 first, second로 각 pair에 접근.
I. Set
#include <set>
- 키가 없어도 됨 / 중복 X / 자료를 넣자마자 정렬
- 자동으로 오름차순 정렬
- 정렬기준은 선언시에 지정할 수 있음.
key를 사용하지는 않지만 Map과 같다.
J. Multi_Map / Multi_Set
#include <map> / #include <set>
- 중복을 허용한다 = 중복이 있어도 insert를 무시하지 않는다.
(이게 끝) - find 등 중복된다면 아무거나 반환한다.
count
- key 값에 해당하는 원소들의 개수 리턴
- 사실 일반 Map에서도 사용할 수 있지만, 의미가 없었다.
K. Unordered_Map / Unordered_Set
#include <unordered_set> / #include <unordered_map>
- 기존 Map, Set이 자동정렬을 하는데,
해당 비용이 크기 때문에 정렬을 굳이 하지는 않는 방식. - 해시함수를 기반으로 원소를 찾는다.
- 중복만 제거하는 경우 사용
1-2. Algorithm.h
#include <algorithm>
정말 여러가지 기능들이 존재하지만,
많이 사용했거나, 사용할 것 같은 것들 위주로만 적는다.
A. Sort
sort(myVector.begin(), myVector.end());
- 정렬시작과 정렬끝+1의 인덱스를 주면 정렬한다.
- 기본적으로 오름차순 정렬
- 역시 3번째 인수에 비교함수를 넣어 내림차순이던지,
조건을 바꿀 수 있다.
std::sort(s.begin(), s.end(), std::greater<int>());- 아니면 위처럼 간단히 greater를 사용하여 내림차순 가능.
B. Reverse
reverse(str.begin(), str.end());
- 매개변수들은 Sort와 의미가 같다.
- 순서를 거꾸로 뒤집는다.
- Sort를 하고 Reverse를 하면 역순이지만,
그냥 Sort만으로 역순정렬을 할 수 있겠다.
C. 이진탐색 관련 함수들
- 무조건 원소들이 정렬되어있어야만 사용가능
liter = lower_bound(myVector.begin(), myVector.end(), 값); - lower_bound
- 해당 값과 일치하는게 없다면, 초과하는 것 중 가장 작은것 위치리턴.
- 없으면 end
- upper_bound
- 일치하는 것 안보고, 초과하는 것 중 가장 작은것 위치리턴.
- 없으면 end
- equal_rangek
- {lower_bound,upper_boundPermalink} pair를 리턴
- binary_search
- 범위 내 해당 값의 유무에 따라 true, false를 리턴.
D. max / min
-
반드시 2개끼리만 비교가능.
-
max_element / min_element
std::max_element(numbers.begin(), numbers.end()); -
해당 범위 내에 max인 위치를 반환.
따라서 값에 접근하기 위해선 *를 붙여야 함.
E. fill
fill(v.begin(), v.end(), 0);
- 보통 2차원 배열의 경우 초기화가 제대로 되지 않아 사용하곤 했다.
copy(&map[0][0], &map[0][0] + 81, &tmp[0][0]); // 복사
위와 같은 느낌으로 사용.
F. Copy
copy(&map[0][0], &map[0][0] + 81, &tmp[0][0]); // 복사
- 이렇게 사용. 원본의 시작, 끝+1 위치를 범위로 두고,
복사할 대상의 시작 위치를 적으면 됨.
2. 기본 함수

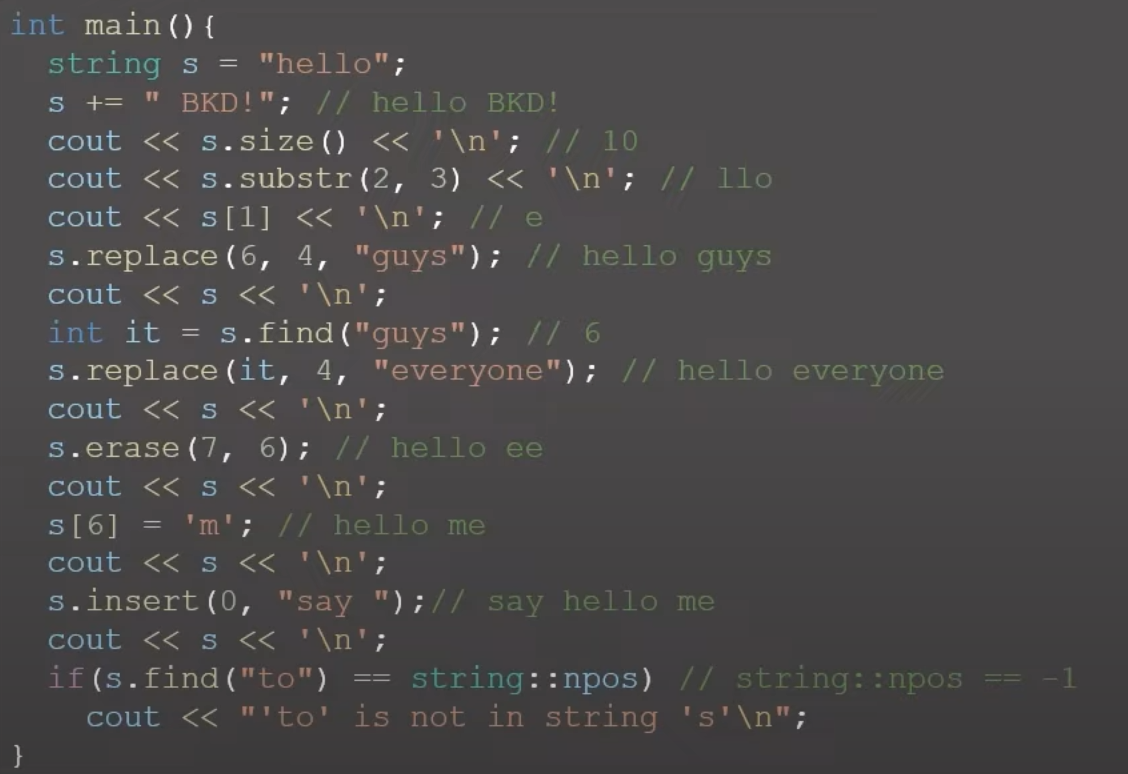
3. 문자열 관련 함수
- 우선 string클래스를 사용하면,
문자열 끝에 '\0' 이 들어가지 않으며,
문자열의 길이를 동적으로 변경 가능.
정리된 사이트
