
모니터링 환경 구성
지금까지의 실습을 통해 Wordpress 애플리케이션을 성공적으로 배포하고, 로드밸런싱이 수행되는 것을 확인했습니다.
이제 Kubernetes는 우리가 배포한 Pod, Service, PV 등의 자원이 관리자가 선언한 상태로 유지되도록 노력할 것입니다.
이전 글에서 Deployment를 통해 배포한 5개의 Pod 에 문제가 생기면 Kubernetes는 해당 Pod를 교체할 것이고, 서비스는 안정적으로 유지될 것입니다.
그런데, Kubernetes는 문제가 생긴 Pod를 고칠 수 있지만 Worker Node 자체에 문제가 생길 경우 문제가 생길 수 있습니다.
예를들어 2대의 Worker Node가 존재하고 각 Worker Node는 5개의 Wordpress Pod를 배포할 수 있는 리소스를 가지고 있다고 가정해보겠습니다.
현재 총 10개의 Wordpress Pod가 2대의 Worker Node에 분산되어 있는데 Worker Node 1대에 문제가 생기면 Kubernetes는 관리자가 선언한 10대의 Pod을 유지하는 것이 불가능합니다.
위의 상황은 동일한 Pod들만 배포되어 있기 때문에 Wordpress 서비스 자체에는 접근이 가능하겠지만, 어떤 중요한 역할을 하는 Pod가 1대의 Worekr Node에만 배포되어 있을 때 그 Worker Node에 문제가 생겨 종료되고 남은 1대의 Worker Node는 문제가 발생해 다른 Worker Node에 배포해야 하는 Pod들을 감당할 리소스가 없다면 서비스를 이용하는데 문제가 될 것입니다.
그렇기 때문에 Kubernetes 환경에서는 Kubernetes Cluster를 구성하고 있는 Control Plane과 Worker Node 서버에 대한 모니터링이 필요합니다.
이번에는 Grafana와 Prometheus라는 모니터링 도구를 이용해 Kubernetes 모니터링 환경을 구성해 보겠습니다.
Grafana + Prometheus 설치
Kubernetes에는Linux의 yum, apt 파이썬의 pip와 같은 패키지를 관리하는 helm이라는 도구가 존재합니다.
helm을 이용해 모니터링 환경을 Kubernetes Cluster에 배포하겠습니다.
# helm에 repository 추가
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update먼저 helm이 Grafana와 Prometheus를 설치할 수 있도록 repository를 추가해줍니다.
다음으로는 helm이 패키지를 설치할 때 설치되는 패키지들에 설정값을 적용해 보겠습니다.
먼저 폴더를 만들어 주겠습니다.
# ~/grafana_prometheus/
$ mkdir grafana_prometheus
$ cd grafana_prometheusroot경로에 grafana_prometheus라는 폴더를 만들었습니다.
이제 설정 파일을 생성하겠습니다.
# prometheus 설정 파일
$ cat <<EOF > values-prometheus.yaml
server:
enabled: true
persistentVolume:
enabled: true
accessModes:
- ReadWriteOnce
mountPath: /data
size: 100Gi
replicaCount: 1
## Prometheus data retention period (default if not specified is 15 days)
##
retention: "15d"
EOF먼저 Prometheus 설정 파일입니다.
시계열 데이터를 수집 후 저장하기 위해 PV를 만들고 저장기간은 15일로 했습니다.
cat << EOF > values-grafana.yaml
replicas: 1
service:
type: LoadBalancer
persistence:
type: pvc
enabled: true
# storageClassName: default
accessModes:
- ReadWriteOnce
size: 10Gi
# annotations: {}
finalizers:
- kubernetes.io/pvc-protection
# Administrator credentials when not using an existing secret (see below)
adminUser: admin
adminPassword: squarebird
EOF다음은 Grafana 설정 파일입니다.
Grafana는 10GB의 디스크를 연결해주고, 계정에 대해 설정하겠습니다.
ID : admin
PW : squarebird
또한, 관리자가 콘솔에 접근해 수집된 데이터를 시각적으로 확인할 수 있도록 로드밸런서를 통해 Grafana를 배포하겠습니다.
이제 해당 모니터링 환경을 Kubernetes 환경에 배포하겠습니다.
# namespace 생성
$ kubectl create ns monitoring
# 배포
# helm install [NAME] [CHART] [flags]
$ helm install prometheus prometheus-community/prometheus -f values-prometheus.yaml -n monitoring
$ helm install grafana grafana/grafana -f values-grafana.yaml -n monitoring먼저 모니터링 환경을 구축할 namespace를 생성합니다.
Kubernetes를 운영할 때, 모든 오브젝트들을 default namespace에 배포하는 것은 현명한 선택이 아닙니다.
용도나 부서와 같은 기준에 따라 적절한 namespace를 생성하여 배포하는 것이 좋습니다.
이번에는 모니터링을 위한 namespace를 생성하여 그곳에 배포하겠습니다.
# monitoring namespace의 모든 오브젝트 확인
$ kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/grafana-7cb8fc447f-9svhx 1/1 Running 0 67s
pod/prometheus-alertmanager-5bb9fdf5b6-ff9md 2/2 Running 0 73s
pod/prometheus-kube-state-metrics-5fd8648d78-8gb8z 1/1 Running 0 73s
pod/prometheus-node-exporter-km8rg 1/1 Running 0 73s
pod/prometheus-node-exporter-lvpfg 1/1 Running 0 73s
pod/prometheus-pushgateway-5846b545ff-qrs5q 1/1 Running 0 73s
pod/prometheus-server-8574f9c49b-25tcf 2/2 Running 0 73s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana LoadBalancer 172.20.35.3 a7cc150189ddf45c2907adf5a333a7c2-939182521.ap-northeast-1.elb.amazonaws.com 80:31122/TCP 68s
service/prometheus-alertmanager ClusterIP 172.20.87.190 <none> 80/TCP 75s
service/prometheus-kube-state-metrics ClusterIP 172.20.177.216 <none> 8080/TCP 75s
service/prometheus-node-exporter ClusterIP 172.20.94.121 <none> 9100/TCP 75s
service/prometheus-pushgateway ClusterIP 172.20.75.243 <none> 9091/TCP 75s
service/prometheus-server ClusterIP 172.20.171.25 <none> 80/TCP 75s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-node-exporter 2 2 2 2 2 <none> 75s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 68s
deployment.apps/prometheus-alertmanager 1/1 1 1 75s
deployment.apps/prometheus-kube-state-metrics 1/1 1 1 75s
deployment.apps/prometheus-pushgateway 1/1 1 1 75s
deployment.apps/prometheus-server 1/1 1 1 75s
NAME DESIRED CURRENT READY AGE
replicaset.apps/grafana-7cb8fc447f 1 1 1 68s
replicaset.apps/prometheus-alertmanager-5bb9fdf5b6 1 1 1 74s
replicaset.apps/prometheus-kube-state-metrics-5fd8648d78 1 1 1 74s
replicaset.apps/prometheus-pushgateway-5846b545ff 1 1 1 74s
replicaset.apps/prometheus-server-8574f9c49b 1 1 1 74s이제 Grafana와 Prometheus가 정상적으로 배포되었는지 확인해보겠습니다.
우선 kubectl get all -n monitoring 명령어를 통해 위에서 생성한 namespace에 배포된 오브젝트들을 확인해 보겠습니다.
일단 모두 문제없이 배포된 것을 확인할 수 있습니다.
prometheus exporter는 Node에서 시계열 데이터를 수집하는 툴이기 때문에 Node당 하나씩 배포되는 DaemonSet으로 배포된 것을 확인할 수 있습니다.

AWS 콘솔의 EBS 탭에서는 제가 위에서 설정한 PV와 PVC가 자동으로 생성된 것을 확인할 수 있습니다.
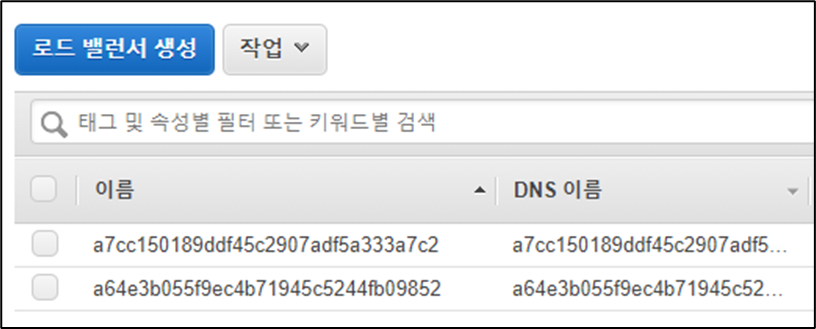
또한 LoadBalancer 화면에서는 a7cc로 시작하는 로드밸런서가 자동으로 생성된 것을 확인할 수 있습니다.
AWS와 같은 클라우드 환경에서 제공하는 완전관리형 Kubernetes 서비스에서는 이처럼 EBS, LoadBalancer와 같은 자원들을 자동으로 생성해 줍니다.
모니터링 환경 확인
그럼 이제 해당 모니터링 환경이 정상적으로 구동되고 있는지 확인하겠습니다.
먼저, helm을 통해 패키지를 배포한 후 오브젝트를 확인한 화면에서 Service 부분을 보겠습니다.
LoadBalancer가 배포되어 있습니다.
해당 로드밸런서에 DNS를 통해 접속해 보겠습니다.
정상적으로 접근에 성공했습니다.
그럼 이제 위의 Grafana 설정파일에서 설정한 ID와 PW로 로그인 해보겠습니다.
접속에 성공했습니다!
다음으로는 Prometheus와 Grafana를 연동하고 대시보드를 구성해 보겠습니다.
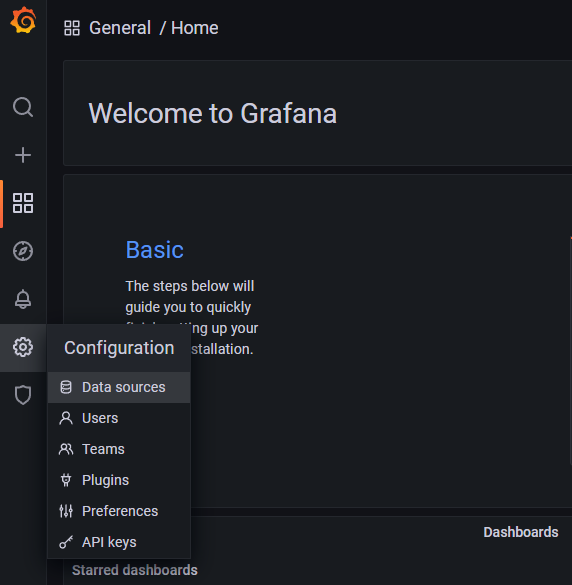
먼저 좌측 네비게이션 메뉴를 통해 Configuration -> Data sources 메뉴로 들어갑니다.

다음으로는 Add data soruce 버튼을 선택합니다.
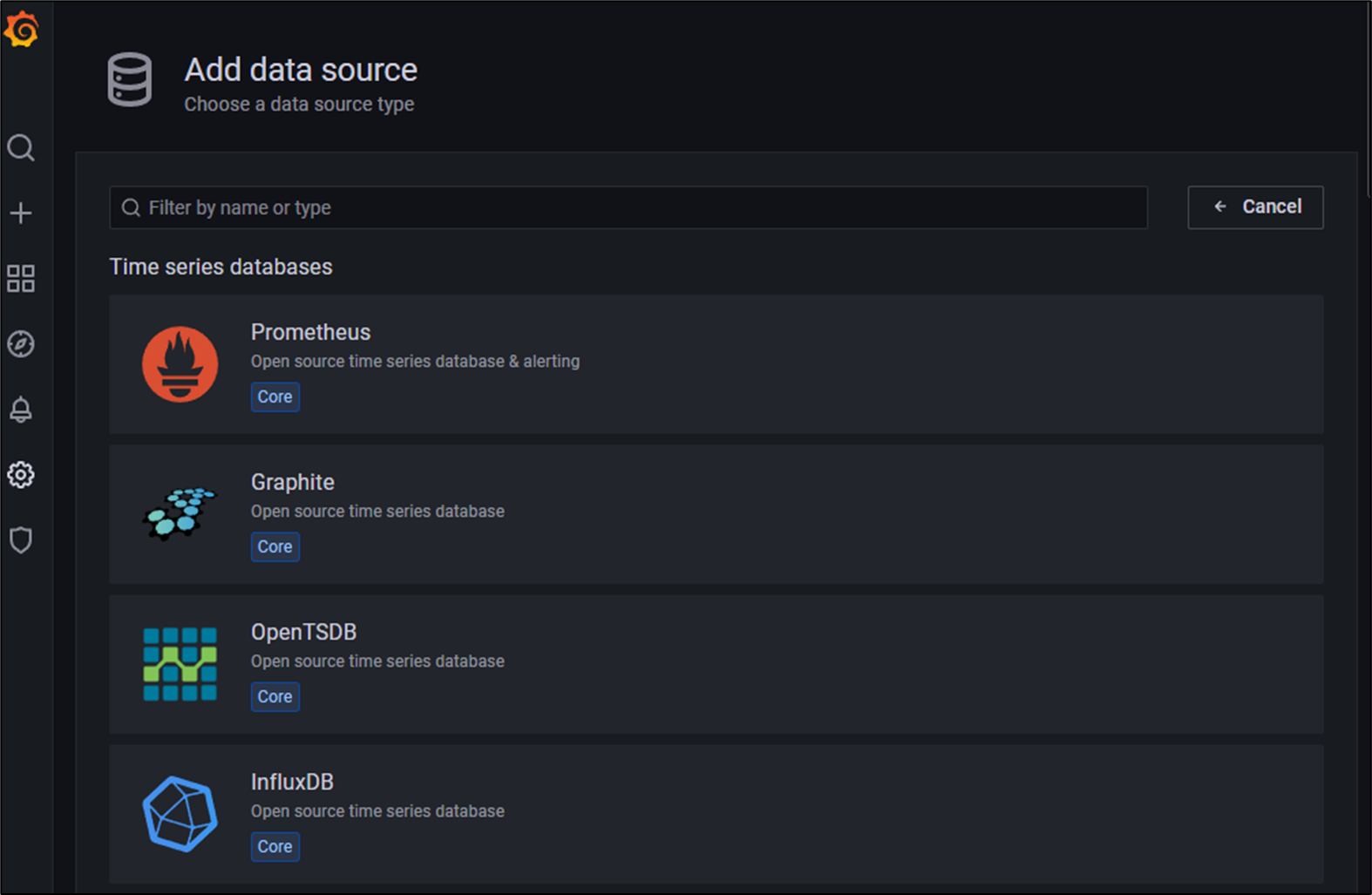
가장 위의 Prometheus를 선택하겠습니다.
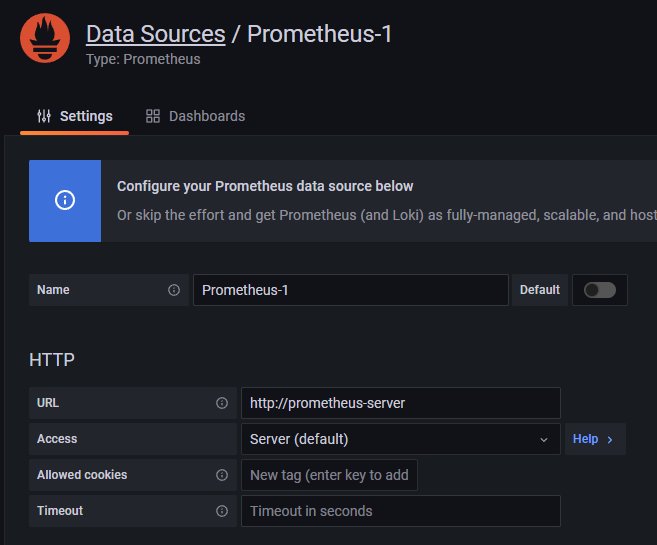
Grafana는 Kubernetes Cluster에 배포된 Prometheus에게서 데이터를 수집해야 합니다.
# monitoring namespace의 모든 오브젝트 확인
$ kubectl get all -n monitoring
... 중략 ...
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana LoadBalancer 172.20.35.3 a7cc150189ddf45c2907adf5a333a7c2-939182521.ap-northeast-1.elb.amazonaws.com 80:31122/TCP 68s
service/prometheus-alertmanager ClusterIP 172.20.87.190 <none> 80/TCP 75s
service/prometheus-kube-state-metrics ClusterIP 172.20.177.216 <none> 8080/TCP 75s
service/prometheus-node-exporter ClusterIP 172.20.94.121 <none> 9100/TCP 75s
service/prometheus-pushgateway ClusterIP 172.20.75.243 <none> 9091/TCP 75s
service/prometheus-server ClusterIP 172.20.171.25 <none> 80/TCP 75s
... 중략 ...위에서 배포한 오브젝트 정보를 보면 prometheus-server라는 Service가 보입니다.
Kubernetes Cluster 내부에서는 core-dns를 이용해 DNS로 통신이 가능하므로 해당 Service 이름을 넣어주겠습니다. 해당 Service의 Cluster IP인 172.20.171.25를 넣어주어도 괜찮습니다.
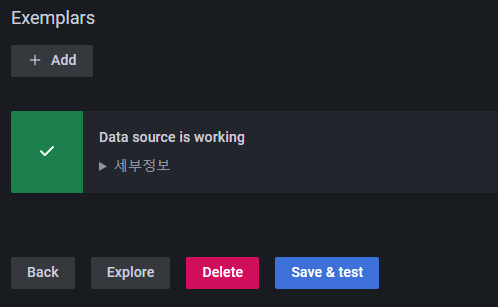
이제 하단에서 Save & Test 버튼을 눌러 정상적으로 데이터를 수집할 수 있는지 확인해줍니다.
이제 마지막으로 대시보드를 구성하겠습니다.
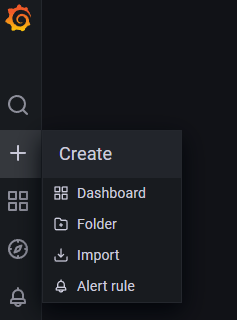
네비게이션 메뉴에서 Create -> Import에 들어가줍니다.
해당 화면에서는 json으로 작성된 설정을 Import 할 수 있습니다.
13770을 입력해 대시보드를 Import 하겠습니다.
다양한 사이트들에서 Import 가능한 대시보드 등의 정보를 찾을 수 있습니다.
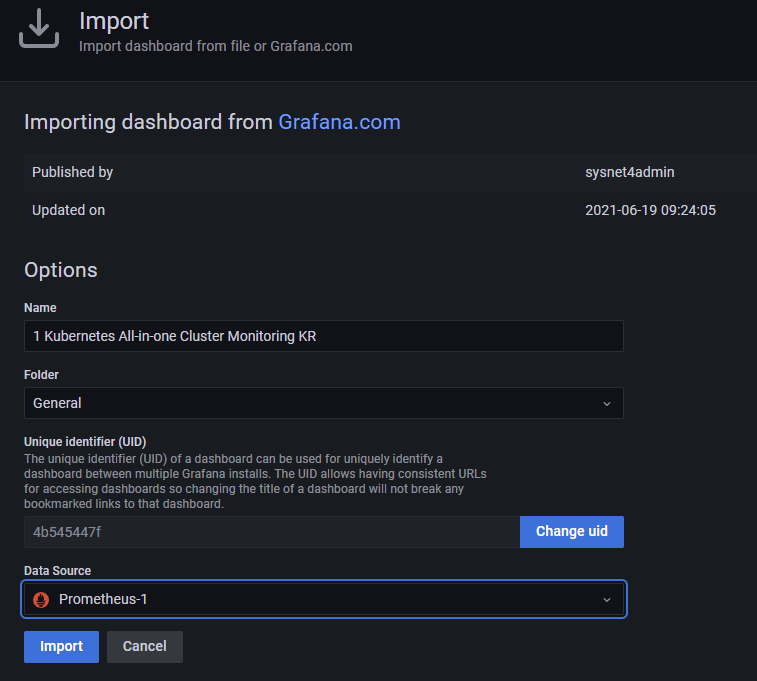
Load 버튼을 눌러 나오는 다음 화면에서, 위에서 생성한 Prometheus와 연동된 Data Source를 설정해줍니다.
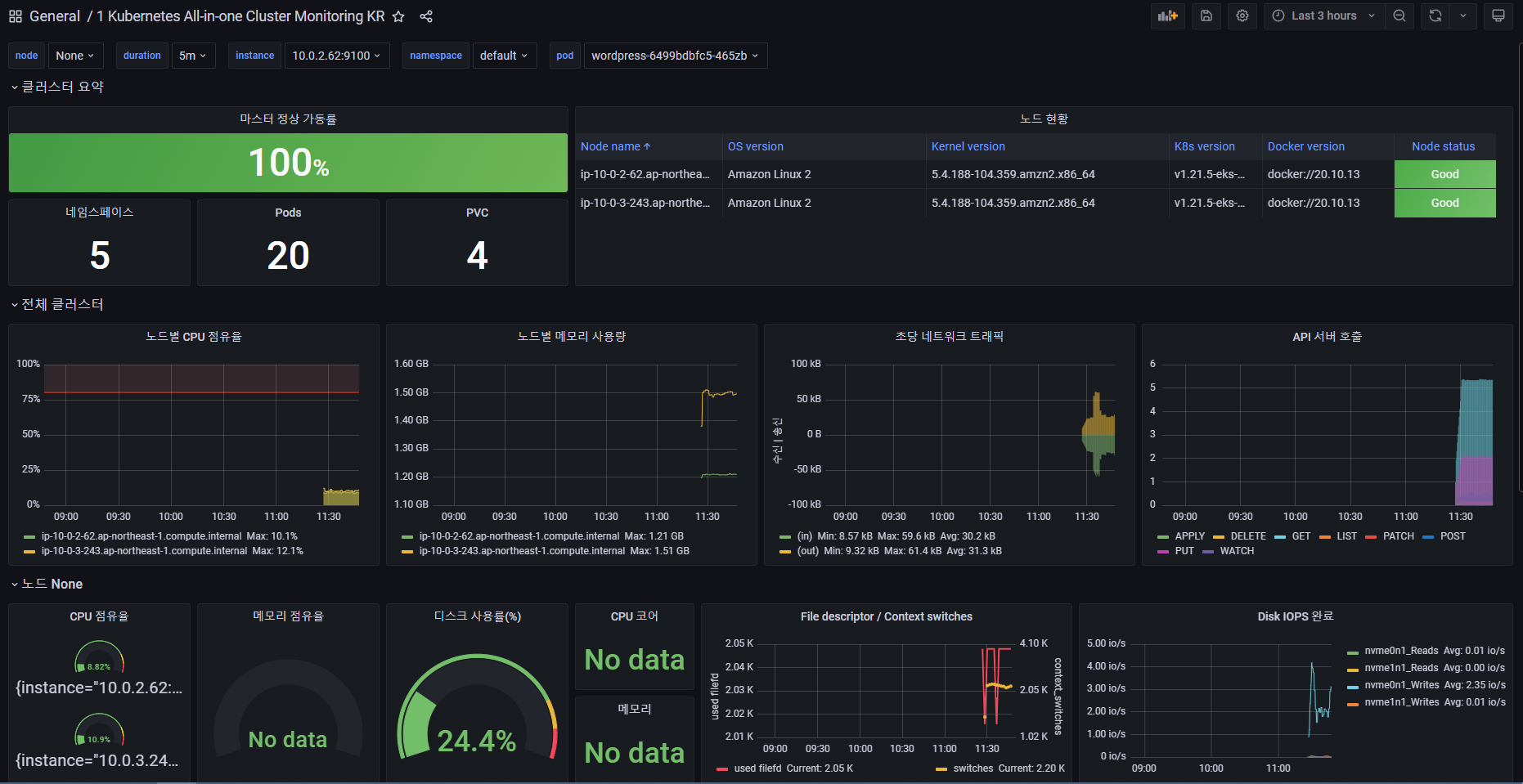
이제 Import 버튼을 누르면 대시보드 정보를 확인할 수 있습니다.
대시보드에서는 Kubernetes Cluster에 어떤 오브젝트들이 몇개 존재하는지, Node의 갯수와 CPU, Memory, Network Traffic, API 호출 등 매트릭 정보를 확인할 수 있습니다.
그럼 이것으로 AWS EKS를 활용한 Wordpress 배포 및 모니터링 실습을 마치겠습니다.
감사합니다.

위처럼 구성하면 대시보드만 구성된 것이고 Wordpress의 매트릭 지표는 수집 못하지않나요??