
etcd
Kubernetes 의 아키텍쳐는 아래와 같습니다.
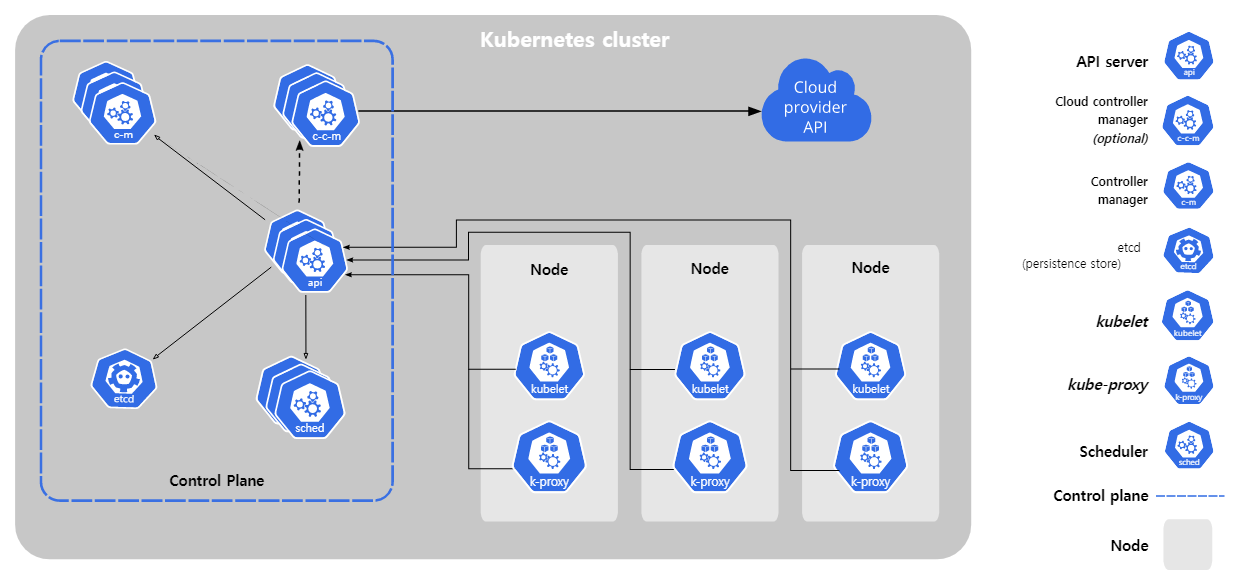
이 아키텍쳐에서 etcd란 Cluster의 모든 상태 정보를 저장하고 있는 저장소입니다.
우리가 kubectl get과 같은 명령어를 통해 얻어오는 모든 정보들은 etcd를 통해서 얻어오는 것입니다.
ex) Nodes, Pods, Configs, Secrets, Accounts, Roles, Bindings 등
etcd의 특징
etcd란 key와 value 형태로 데이터를 저장합니다.
key는 중복되지 않는 고유한 값이어야 하며, key를 알고 있다면 key를 통해 value를 얻을 수 있습니다.
기존의 RDBMS와 같은 데이터베이스 서비스들을 대체할수는 없지만,
빠른속도로 읽기, 쓰기가 가능하기 때문에 설정 데이터와 같은 작은 크기의 데이터를 반복적으로 저장 및 검색하는 용도로 사용하기에는 매우 적합합니다.
etcd는 Kubernetes Cluster의 모든 정보들을 저장하고 있기 때문에 만약 Cluster에 문제가 생겼을 경우 etcd의 데이터를 잘 백업해 두었다면 Cluster를 복구하는것이 가능합니다.
하지만 반대로 다른 모든 컴포넌트들이 멀쩡하더라도 etcd의 데이터가 유실되어버리면 컨테이너 뿐 아니라 Cluster가 사용하는 모든 리소스들을 활용할 수 없게 됩니다.
etcd 데이터의 유실을 방지하기 위해 etcd를 분산하여 구축하면 고가용성(HA)을 확보할 수 있습니다.
etcd 동작 원리
위에서 설명했던 것 처럼 Kubernetes에서 etcd는 매우 중요한 역할을 담당하기 때문에 분산된 환경에 구성하는 것이 좋습니다.
분산된 환경에 구성된 etcd는 하나가 죽더라도 다른 etcd들을 통해 서비스를 정상적으로 제공할 수 있어야 하는데, etcd는 Replicated state machine라는 방법을 통해 이를 제공합니다.
Replicated state machine은 똑같은 데이터를 여러 서버에 계속해서 복제하는 방식입니다.
동작 원리에 대한 글은 kakao 클라우드플랫폼팀 ted님의 글을 참고했습니다.
RSM(Replicated state machine)
RSM은 command가 들어있는 log 단위로 데이터를 처리합니다.
데이터의 write를 log append라고 부르고, 머신들은 받은 log를 순서대로 처리하는 특징을 가지는데, 똑같은 데이터를 복제하는 과정에서 여러가지 문제가 생길 수 있습니다.
RSM이 정상적으로 동작하기 위해서는 아래와 같은 전제조건이 붙습니다.
- 항상 올바른 결과를 리턴해야 함
- 서버가 몇 대 다운되더라도 항상 응답해야 함
- 네트워크 지연이 발생하더라도 로그의 일관성이 깨져서는 안됨
- 모든 서버에 복제되지 않았더라도 조건을 만족하면 빠르게 요청에 응답해야 함
모든 노드가 독립적으로 구성된것이 아닌 RSM이라는 형태로 묶여서 동작하기 때문에 RSM에는 어떤 상태가 위의 전제조건들을 만족하는 올바른 상태인지를 합의하기 위한 모종의 방법이 필요합니다.
이렇게 분산 환경에서 상태를 공유하는 알고리즘을 Consensus Algorithm이라고 부르며, etcd는 그 중 Raft Algorithm을 사용합니다.
Raft Algorithm 알고리즘에 대해서는 나중에 정리하겠습니다.
etcd 배포 방법
쿠버네티스 클러스터에 etcd를 배포하는 방법은 크게 두가지가 있습니다.
scratch를 통한 배포kubeadm을 통한 배포
1. scratch를 통한 배포
etcd binary를 다운로드 받은 뒤 직접 설정해주는 방법이다.
kubeadm을 통해서 Kubernetes를 설치하지 않았을 경우,
etcd를 Master Node에 직접 설치해주어야 한다.
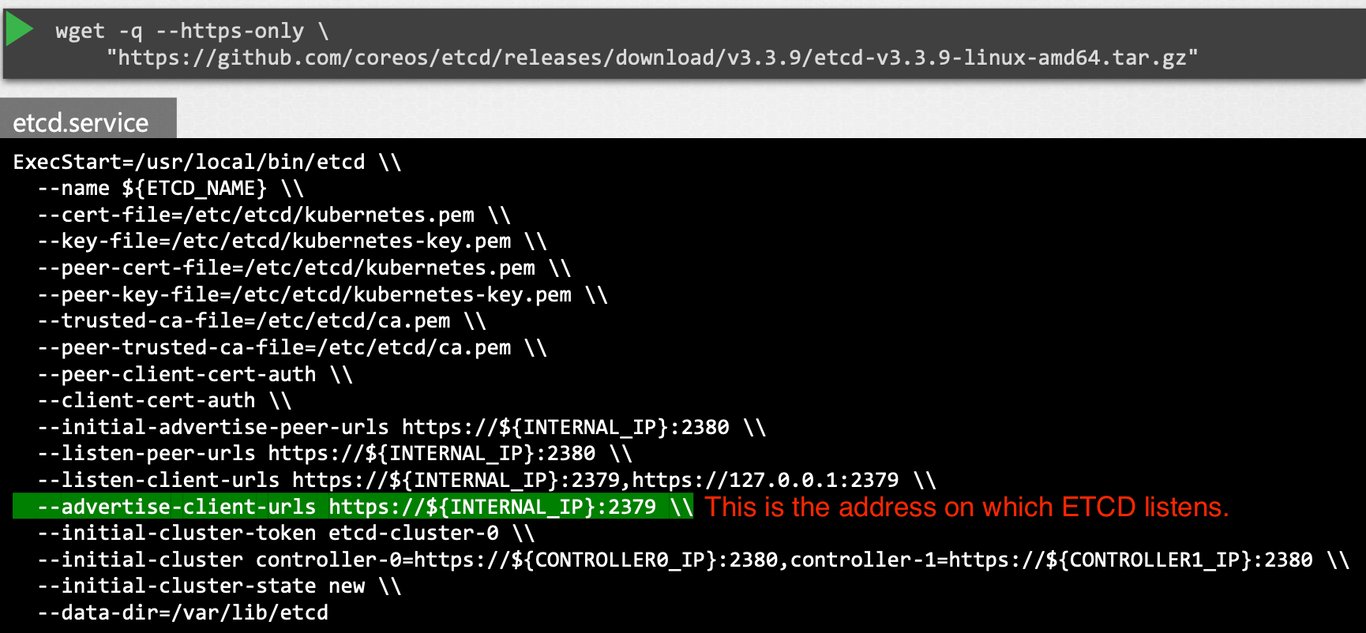
etcd를 설치한 뒤 advertise-client-urls부분에 정보를 입력해주는 방식으로 배포한다.
kube-api-server는 이 url을 통해 etcd에 접근하게 된다.
2. kubeadm을 통한 배포
kubeadmin을 통해 배포를 진행하면 etcd는 Cluster에 Pod의 형태로 자동으로 올라갑니다.
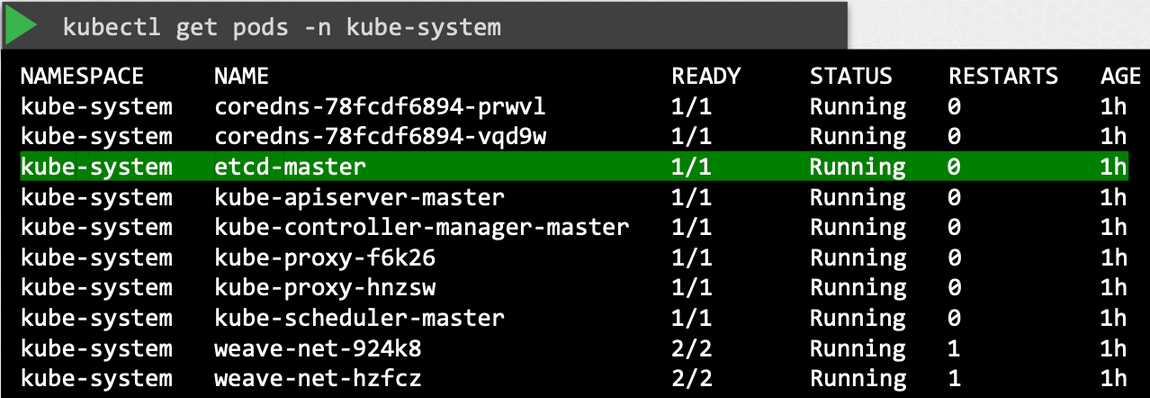
kubectl get pod -n kube-system을 보면 etcd-master라는 이름으로 동작중인 pod을 확인할 수 있습니다.
Cluster를 HA로 배포할 경우 Master Node가 여러개 존재하게 되는데,
이에따라 etcd도 여러 노드에 분산되어 배포됩니다.
이 때, etcd config를 제대로 설정하여 각 인스턴스들이 서로의 존재를 알고 있어야 하는데,
서로의 존재는 initial-cluster 옵션을 통해 인지할 수 있습니다.
