의문점
String 타입의 변수를 선언하는 방법은 두 가지가 있다.
하나는 바로 값을 대입하는 String literal을 이용한 방법,
하나는 new를 이용해 선언하는 방법이다.
원래 나는 String은 특별한 객체이기 때문에 String literal로 선언하면 자동으로 new를 이용해 선언되는 방식으로 알고 있었다.
그런데 아래와 같이 String 변수를 선언했을 때 서로 결과가 다르다.
# 1. 리터럴로 선언했을 경우
String lit1 = "a";
String lit2 = "a";
if(lit1==lit2) {
return true;
} else {
return false;
}
# 2. new를 통해선언했을 경우
String st1 = new String("a");
String st2 = new String("a");
if(st1==st2) {
return true;
} else {
return false;
}과연 1번과 2번은 결과가 같을까?
나는 결과가 둘다 true로 나올 것이라고 생각했지만, 실제로는 1번의 String literal로 선언했을 경우 true, 2번의 new를 통해 선언했을 경우 false가 나왔다.
해결
이렇게 String의 선언 방식에 따라 결과가 다르게 나오는 이유는 위에서 말한 것 처럼 String이 Java에서 굉장히 특별한 객체이기 때문이다.
일반적으로 참조 타입(Reference Type) 변수를 선언하면 Stack 영역에 변수가 선언되고 Heap 영역에 실제 메모리가 할당된다. 이는 new 예약어를 이용해 인스턴스를 생성하는 과정에서 이루어진다.
String 변수도 new를 통해 생성하면 동일하게 Heap 영역에 메모리가 할당된다.
하지만, String 변수를 String literal 방식으로 선언하면 Heap 영역에 내가 선언한 값을 위한 새로운 메모리가 할당되는것이 아닌, 이미 존재하는 String Constant Pool에 내가 선언한 값이 들어가게 된다.
그림으로 나타내보면 이런 형태다.
-
String literal로 선언했을 경우
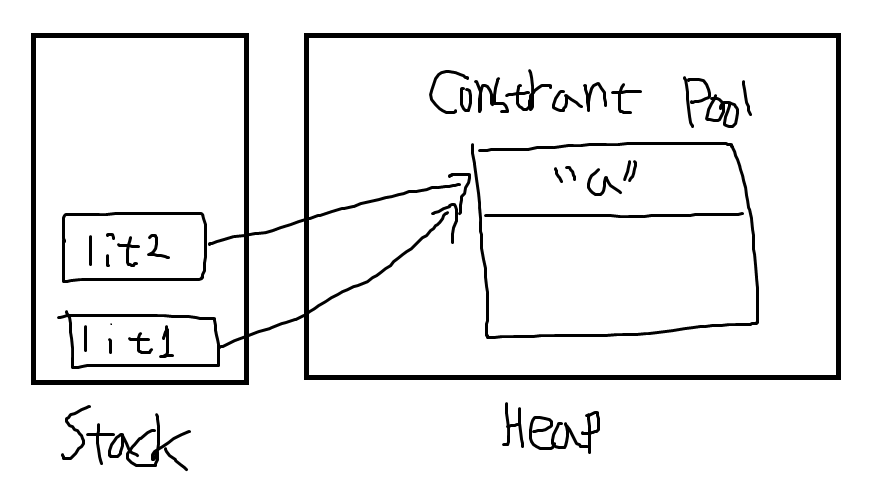
-
new로 선언했을 경우
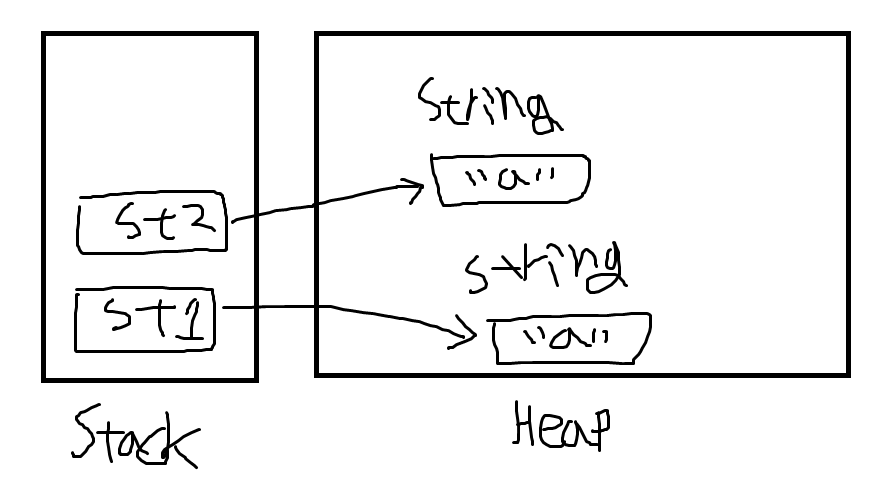
String literal로 선언했을 경우 두 변수가 같은 주소를 가리키고 있기 때문에 true가 리턴되고, new로 선언했을 경우 두 변수가 각각 Heap 메모리에 할당된 다른 주소값을 가리키고 있기 때문에 false가 리턴된다.
왜 쓰는걸까?
그렇다면 상수플은 왜 쓰는걸까?
나는 두 가지의 이유가 있다고 생각한다.
먼저 가장 중요한 이유는 메모리 절약이다.
위에 그림에서 볼 수 있는 것 처럼 같은 문자열일 경우 두 참조 변수가 같은 주소를 가리키기 때문에 새로 Heap 영역에 메모리를 할당하지 않아도 되니 메모리가 절약된다.
다른 이유는 변수의 수명주기와 관련이 있다.
Java의 경우 변수 타입에 따른 수명주기가 존재한다.
그런데 일반적으로 상수로 쓰인 문자열은 다시 쓰일 가능성이 높다고 생각한다.
만약, a라는 값을 가진 String 변수가 A와 B라는 서로 다른 메소드의 지역변수로 선언되었다고 생각해보자.
두 가지의 경우가 있을 것이다.
String literal로 선언했을 경우
먼저 String literfal로 선언했을 경우, 해당 변수는 String Constrant Pool의 주소값을 가리키기 때문에 먼저 선언된 A 메소드를 빠져나와도 수명주기가 끝나지 않는다.
그렇기 때문에 두 번째 B 메소드에서 새로 지역변수로 선언하더라도 새로운 메모리를 할당하는 것이 아닌 기존 String Constrant Pool에 위치한 주소를 가리키게 된다.
new를 이용해 선언했을 경우
new를 통해 선언했을 경우 A 메소드가 종료되면 해당 변수의 수명주기가 끝나 제거된다.
그렇기 때문에 B 메소드에서 새로 지역변수를 선언하면 Heap 메모리를 새로 할당하게 된다.
이게 어떤 차이가 있냐고 할 수도 있지만, 만약 String 변수를 선언하는 부분이 코드에 수없이 많고, 그 중 같은 값을 입력해 선언하는 부분이 많다면 실제로 많은 부하가 일어날 수 있다.
그리고 메모리 절약은 언제나 신경쓰는것이 좋다...
