시작하며
앱을 마이그레이션하며, CleanArchitecture에 대해 많은 고찰을 하게된다. 그러면서 나름 연구를 진행해 보았고 그에 따른 내 일기같은 생각을 적어본다. 진행하기에 앞서, 내 머릿속에 있는 배경지식을 먼저 말한다.
Repository란?
- SSOT원칙에 따라 다양한 데이터 발행처를 추상화 및 오케스트레이션하여 단일 Class를 통해 이를 사용할 수 있게 함
- 앱에서 사용되는 데이터를 도메인 단위로 그룹화한 Class
주저리주저리
로버트 마틴이 쓴 책, 클린아키텍처를 읽어보면 어플리케이션에서 사용하는 핵심 비즈니스 로직을 추출하고 이를 Entity로 개념화한 다음 이를 UseCase를 통해 오케스트레이션하라는 말을 많이 한다. 이때, 핵심 비즈니스 로직이란 무엇인가?
이를 이해하기 위해선 어플리케이션 로직과 핵심 비즈니스 로직을 분리해서 생각해야할 필요가 있다. 어플리케이션 로직은 말 그대로, 앱 또는 서버 어플리케이션이 동작하는 데 필요한 국소적인 로직을 의미한다. 예를 들어, 안드로이드 앱의 어플리케이션 로직 경우
- 네트워크 연결이 잘되었는지?
- 네트워크 API 호출이 실패하지 않았는지?
- 실패했다면 에러처리와 재시도 정책은 어떻게 할것인지?
- 화면 회전에 따른 데이터 소실은 어떻게 대응할 것인지?
- 상세 화면에서 좋아요 누른 후, 뒤로가기 눌러, 메인 리스트화면에 갔을 때, 해당 게시물에 좋아요가 눌려져 있어야 함. 더 나아가 복잡한 UI 백스택 구조에서도 좋아요가 유지돼야 함
등이 있다. 반면, 핵심 비즈니스 로직은 해당 어플리케이션이 수익을 내기 위해, 사용자 가치를 창출하며, 앱이 존재하는 데 필요한 로직을 의미한다. 예를 들어, 내가 진행중인 버디스탁 프로젝트의 예를 들어보자. 이는 친구들과 관계를 기반으로 투자 포트폴리오를 함께 공유하기 위한 어플리케이션이 핵심 가치이며 존재 이유이다. 따라서 이로부터 이어지는 핵심 비즈니스 로직이란 '친구 맺기'가 있으며, 이를 통해 '거래'를 진행하며, 이를 '공유'할 수 있는 기능들이 핵심 비즈니스 로직으로 봐도 무방할 것이다. 하지만 이런걸 안드로이드 앱단에서 구현할 수가 없고, 서버에서 구현할 수밖에 없다. 내가 진행한 주식거래를 친구들이 봐야만 하고, 친구 추가 또한 서버를 반드시 거쳐야만 하기 때문이다. (따라서 Local성격이 강한 앱일수록 CleanArchitecture 사용에 빛을 발한다 생각한다)
앱에서 CleanArchitecture 적용 한계
하지만 이러한 핵심 비즈니스 로직을 앱 관점으로만 구현하기 위해선 문제가 존재하는데, 보통 이를 서버 로직에 많이 위임하는 것이다. 따라서 앱에서는 단순 서버의 API를 호출해서 보여주는 일명, Json 상하차의 기능만 하는 경우도 많다. 따라서 모바일 앱을 포함한, 프론트엔드 어플리케이션에선 클린아키텍처에서 기대하는 Entity기반, UseCase을 작성하기가 애매한 경우가 많다. 이로 인해 나는 안드로이드 앱에서 쓰이는 UseCase와 클린아키텍처에서 쓰이는 UseCase의 개념이 매우 다르다고 생각하며, 동일한 네이밍으로 인해, 클린아키텍처를 학습하는데 큰 장애물이 된다고도 생각한다. 그 이유는 아래와 같다.
- 핵심 비즈니스 로직은 서버로 위임한다 (중요)
- 따라서 어플리케이션의 존재 이유가 되는 핵심 비즈니스 로직이 앱에선 존재하지 않는다.
- 설령 앱에서 이걸 구현한다 하더라도, Repository단에서 충분히 구현 가능한 경우가 많다.
- 그래도 UseCase에서 이를 구현한다 쳐도, '간헐적인 비즈니스 로직의 작성'이 일어난다. 즉, 코드 전체적 맥락으로 봤을 때 일관성이 없다는 말이다.
- 따라서 UseCase는 단순, Repository의 약간의 오케스트레이터역할만 하는 경우가 많다.
- UseCase는 핵심 비즈니스 로직이 담기는 모듈이 아닌, 어플리케이션 로직이 담기는 경우도 비일비재하다.
- 만약 도메인 전용 모듈을 어거지로 작성하기 시작하면, 실무 진행 시, 모델간 매핑 지옥(presentation -> domain <- data)이 발생한다.
즉, 안드로이드 앱 개발자라면 많이 쓰는 UseCase의 역할이 Repository의 간헐적인, 단순한 오케스트레이션 역할에 지나지 않다. 이로 인해 핵심 비즈니스 로직이라기보다 어플리케이션 로직 심지어, 변두리 로직이 되기도 한다. 또한 핵심 어플리케이션 로직이 만들어진다 해도 이런 일이 가끔씩만 일어날 뿐이다. 그렇다면 차라리 네이밍을 UseCase가 아니라, 'Orchestrator'나, 'Resolver'나, 'Manager' 등의 이름으로 불러야하지 않을까? 싶다.
추가로, 클린아키텍처의 고전인 '책'에도 레이어가 그렇게 많지 않다. (물론 앱이 커지면 상황에 따라 레이어가 추가될 수 있긴 하지만 Json 상하차를 하는 앱 입장에서 그렇게 많은 레이어가 필요할까? 라는 의문이 들기도 하고 그렇게 큰 서비스까지 아직 만져보지 못해 의문이 계속 남아있긴 하다.) 책에선 대략 웹 어플리케이션에 한정, 아래와 같은 레이어를 제시한다.
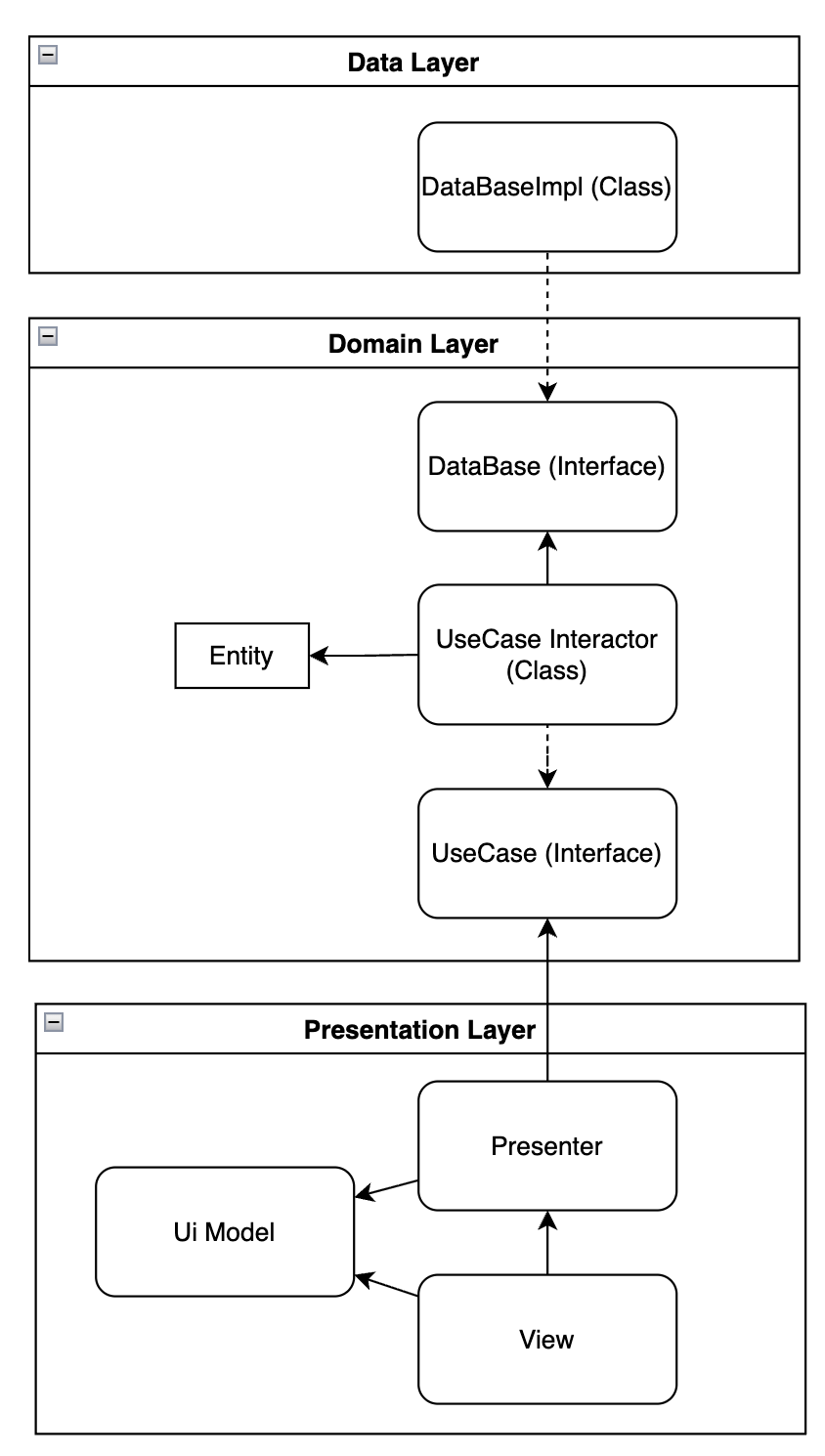
즉, View와 DataBase(interface) 사이에, 2개의 구현체 모듈이 존재하며 이는 Presenter와 UseCase Interactor(Class)가 그것이다. 즉, Presenter를 사용하여 UI 바인딩될 데이터들을 처리(=어플리케이션 로직)해준다. 그 후, Entity에 의존하는 UseCase를 사용하여 핵심 비즈니스 로직을 구현해준다. 이미 저것만으로 웬만한 앱 어플리케이션의 충분한 구현이 가능하지 않을까 싶다.
심지어, Android에선 Repository라는 모듈까지 둔다. (iOS와 React는 Repository를 잘 안두는것 같기도 하다. 그리고 Repository의 책임은 SSOT원칙에 따른 데이터 발행처를 추상화하여, 단일 엔트리 포인트 클래스로 이를 사용하게함이 목적이 있는데, 단순 Remote API만 호출할거면 이 또한 안두는 것도 좋은 선택일수도 있다.) Repository의 책임이라 하면, SSOT도 있지만, '앱에서 사용되는 데이터를 도메인 단위로 그룹화한다.' 라는 책임도 존재한다. 따라서 앱에서 이미 Repository를 쓴다는 것 자체가 도메인 단위로 앱을 구조화했다고도 이해할 수 있다. (ps. Screen + ViewModel의 네이밍 그룹화는 순수 UI 단위라 생각) 가령, 클린아키텍처에서 UseCase를 쓴다할 때, UserUseCase, TradingUseCase, 등 여러가지가 존재할 수 있단점에 비춰봤을 때, 이 또한 Repository와 상당히 유사한 면이 있다. 그래서 UseCase는 더더욱 필요가 없어진다.
추가로, UseCase에서 아래와 같이 사용하는것도 고정관념이라 생각한다.
- invoke 함수를 통해 1개의 UseCase에는 1개의 기능만 담는 것
- 구글 앱 아키텍처 영향받은듯 싶다
- UseCase 네이밍을 반드시 동사로 하는 것
- UseCase는 사용자의 행동과 시나리오를 모델링해야하니 그런게 아닐까 싶다
더 나아가, Android에서 Repository패턴을 도입했을 때, 위 클린아키텍처 다이어그램의 사용성에 더 잘 들어맞는 경향도 있다. UseCase(Interface)와 UseCaseImpl(Class)를 각각 Repository의 Interface와 Class에 치환이 어렵지 않게 가능하듯, Repository 모듈 자체로 도메인 역할 대신할 수 있다고도 본다.
추가
물론, 앱이 OfflineFirst를 지향함으로써 Repository내, 다양한 데이터 소스를 오케스트레이션해 메모리/디스크 캐싱 기반한 데이터 제공 기능이 생긴다면, Repository의 책임이 커질수도 있다. 그에따라, 도메인에 대한 로직까지 섞이면 Repository의 로직의 순수성이 오염될 가능성은 있다. 하지만 OfflineFirst로 작성하지 않으며, Local이 큰 권위를 가지지 않는 앱이며, Remote API만 단순 호출하여 Json 상하차만 하는 앱일 경우, 도메인 로직을 Repository에 작성하는것도 고려해볼 수 있다.
중간 결론
그래서 내가 내린 결론은
1. Local의 권위가 약하며, OfflineFirst와 같이 각종 데이터 소스를 오케스트레이션하지 않으며
2. 단순Remote API호출을 통해 단순 Json 상하차만 하는 앱이라면
UseCase는 강제할 필요도 없으며, 실익도 적으며, 어찌보면 필요가 없을 수도 있단 것이다. Repository라는 모듈은 SSOT에 따른 데이터 발행처 추상화라는 역할도 있지만, 애초에 앱에서 사용되는 데이터를 도메인 단위로 그룹화 하니, 이 또한 도메인의 영향을 가진다고도 볼 수 있고, 따라서 이곳에서 얼마 안되는 Domain 로직을 작성하는것도 고려해볼 수 있다.
CleanArchitecture를 보완하기 위해 나온 Google App Architecture?
안드로이드 앱에선 Entity기반, UseCase 오케스트레이션하는, 그런 깔끔한 CleanArchitecture를 구현하기가 어려운 경우가 많기에(구현한다 해도, Domain에 불필요 모델을 둚으로써 Domain <-> Data 파싱작업만 어마어마하게 하는 경우도 들음) ViewModel에서 간한하게 Repository를 호출하는 구조인, 일명 Google App Architecture가 나온게 아닐까 생각한다. 물론 유명한 토론 논쟁인 [Bug]: Breaking SOLID principles and Clean Architecture.에선 Google App Architecture(이하 GAA)가 CleanArchitecture를 보완하기위해 나왔다고 명시하진 않았다. 하지만 내 생각은 그렇다는 것이다.
- Google개발자분들이 GAA만든 의도는 분명 있다.
- 아까말한대로 CA에선 Entity, UseCase가 필요없는 경우가 많다.
- 그래서 now in android를 보면, Repository에선 비즈니스 로직로 함께 작성되어 있는걸 관찰할 수 있으며, 공식 홈페이지도 그렇게 권장하고있다. (Flow의 중간연산자를 사용한 stream의 결합, when/if를 사용한 분기처리 등)
override fun observeAllForFollowedTopics(): Flow<List<UserNewsResource>> =
userDataRepository.userData.map { it.followedTopics }.distinctUntilChanged()
.flatMapLatest { followedTopics ->
when {
followedTopics.isEmpty() -> flowOf(emptyList())
else -> observeAll(NewsResourceQuery(filterTopicIds = followedTopics))
}
}override fun searchContents(searchQuery: String): Flow<SearchResult> {
// Surround the query by asterisks to match the query when it's in the
// a word
val newsResourceIds = newsResourceFtsDao.searchAllNewsResources("*$sea
val topicIds = topicFtsDao.searchAllTopics("*$searchQuery*")
val newsResourcesFlow = newsResourceIds
.mapLatest { it.toSet() }
.distinctUntilChanged()
.flatMapLatest {
newsResourceDao.getNewsResources(useFilterNewsIds = true, filt
}
val topicsFlow = topicIds
.mapLatest { it.toSet() }
.distinctUntilChanged()
.flatMapLatest(topicDao::getTopicEntities)
return combine(newsResourcesFlow, topicsFlow) { newsResources, topics
SearchResult(
topics = topics.map { it.asExternalModel() },
newsResources = newsResources.map { it.asExternalModel() },
)
}
}특히, 아까 내가 Repository에서 도메인 로직을 작성할 수 있다 했는데, 그걸 GAA에서도 따르고 있다고 강하게 추측되는 부분이 있다. 그것은 now in android의 Repository에서 사용되는 모델을 보면 뭔가 도메인틱하다는 점이다.(예. SearchResult, UserData, Topic등..) 보통, Repository에서 반환하는 모델은 접미사로 Dto가 붙는데, Repository에서 사용되는 모델들은 마치 CA의 도메인 모델처럼 불필요한 접두사나 접미사가 없다.
val userData: Flow<UserData>
fun getTopics(): Flow<List<Topic>>
fun searchContents(searchQuery: String): Flow<SearchResult>결론
이러한 사고를 거쳐 나만의 논리 흐름을 만들면 아래와 같다.
- 최소 Android에서, CA에 기반한 Entity뿐만 아닌, UseCase까지 쓸모없는 경우가 많다.
- 물론 앱이 OfflineFirst를 지향하거나, Local작업이 많다면 Entity와 UseCase에 기반한 CA를 써봄직 하다.
- 그게 아닌, Remote API 권위가 강한 앱이라면 Entity/UseCase는 쓸모없는 경우가 많다.
- 이유는 무지몽매하게 도메인 레이어를 작성한다 했을 경우, 무분별한 데이터 mapper 지옥이 발생할 수 있기 때문이다.
- 따라서 난, 기존 Android CA에서 사용하는 UseCase라는 네이밍을 바꿔야한다고 본다. (예. 'Orchestrator' 'Resolver')
- 이유는 UseCase는 핵심 비즈니스 로직인 Entity 를 다루는 것이 아닌, 단순 Repository 오케스트레이션 위주로 진행되기 때문이다.(이는 CA에서 기대하는 Domain 로직이 아님) UseCase 네이밍은 혼동이 올 수 있다.
- 이를 해결하기 위한 방법은 무지몽매한 UseCase사용이 아닌, 앱에서 사용하는 데이터를 도메인 단위로 그룹화 한 Repository내, 비즈니스 로직 작성에 그 해답을 찾을 수 있다고 본다.
- 이를 보완하기 위해 나온 것이 GAA라고 나는 생각한다. 이를 방증하는 게, 공식 홈페이지와 now in android 소스코드를 봤을 때, Repository내 각종 비즈니스 로직(Flow스트림 결합, when/if 처리 등)을 처리하고 있다. 또한 신기하게도 Repository에서 사용되는 모델이 CA의 도메인에서 사용되는 모델처럼 불필요 접두사/접미사가 없다.
상황에 따라 적합한 아키텍처를 선택하는 건 개발자의 몫이다. 하지만, 요구사항에 맞춰 어떤 기술적 선택지가 있다는걸 알고 적절히 취사선택할 수 있다면 더 좋은 결과를 얻을 수 있겠다.
