시작하며
안드로이드 앱 개발에서도 생각보다 공유자원 동기화가 많이 들어간다. 단순히 Now In Android와 같은 샘플앱을 보고 따라치는 정도에선 딱히 못느낄수도 있다. 하지만 StateFlow.update메서드를 보면 그 내부적으로 CAS를 활용하는것 또한 알 수 있다. 또한 이 CAS의 동작원리를 알게되면 ViewModel안에서 UiState를 하나의 공유자원으로 설정하고 UI를 효과적으로 동기화한다는것 까지 이해할 수 있다. StateFlow.update가 내부적으로 CAS를 기반으로 공유자원 업데이트함을 이해했다면, 이를 응용하여 AtomicType또한 사용할 수 있다 생각한다.
Race Condition이란?
정의는 아래와 같다.
멀티스레드 환경에서 하나의 공유자원을 읽고 쓸 때, 데이터 무결성이 깨지는 상태
여러 스레드에서 접근하는 하나의 필드 또는 메서드 블럭을 공유자원이라고 한다. 또한 멀티 스레드에서 이들을 접근할 때, 무결성이 깨지는 경우가 있는데 아래 그림으로 설명한다.
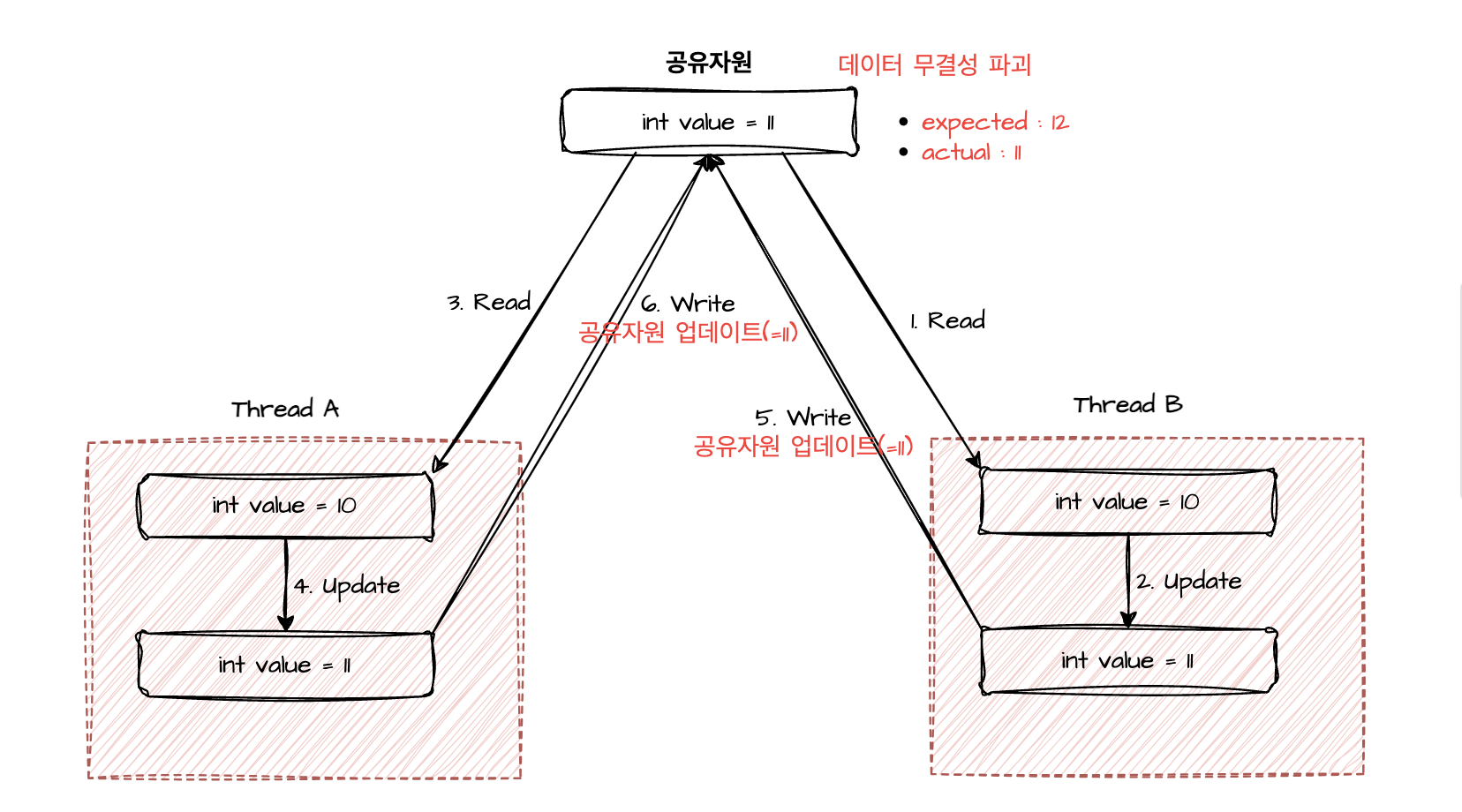
하나의 공유자원이 있다. 그리고 이를 A,B스레드에서 동시에 접근하여 공유자원 'value'를 업데이트하려는 상황이다.
우선 Thread B에서 공유자원을 읽어온다. 그 후, 연산을 수행하여 읽어온 공유자원을 10에서 11로 만들었다. 다만 아직, 공유자원에 쓰기 작업은 하지 않았다.
하지만 이때 동시에 Thread A에서 공유자원을 읽어오고 동일하게 연산을 수행해 10에서 11로 만들었다. 하지만 이 작업이 끝나자 마자, Thread B에선 연산 완료한 값을 공유자원에 업데이트를 시도한다.
결국 공유자원은 10에서 11로 변경되었다. 하지만 변경 완료 후, Thread A가 해당 공유자원 업데이트를 시도하였다.
이 상황은 어떤 상황일까? 분명, Thread A와 Thread B에서 공유자원을 각각 +1 연산을 진행하였기에, 해당 공유자원은 10에서 12가 되어야함이 맞다. 하지만 최종 결과값은 11이 되었다. 즉, 공유자원의 무결성이 파괴된 것이다. 위 상황을 샘플코드로 나타낸다면 어떨까? 바로 아래와 같다.
var counter = 0 // 공유 변수
suspend fun main() {
val n = 1000 // 코루틴 개수
val k = 1000 // 각 코루틴에서 증가시킬 횟수
val time = measureTimeMillis {
coroutineScope {
repeat(n) {
launch(Dispatchers.Default) {
repeat(k) {
counter++ // 동시에 접근하는 공유 자원
}
}
}
}
}
println("Expected Counter: ${n * k}")
println("Actual Counter: $counter")
println("Completed in $time ms")
}[결과]
Expected Counter: 1000000
Actual Counter: 993847
Completed in 45 ms
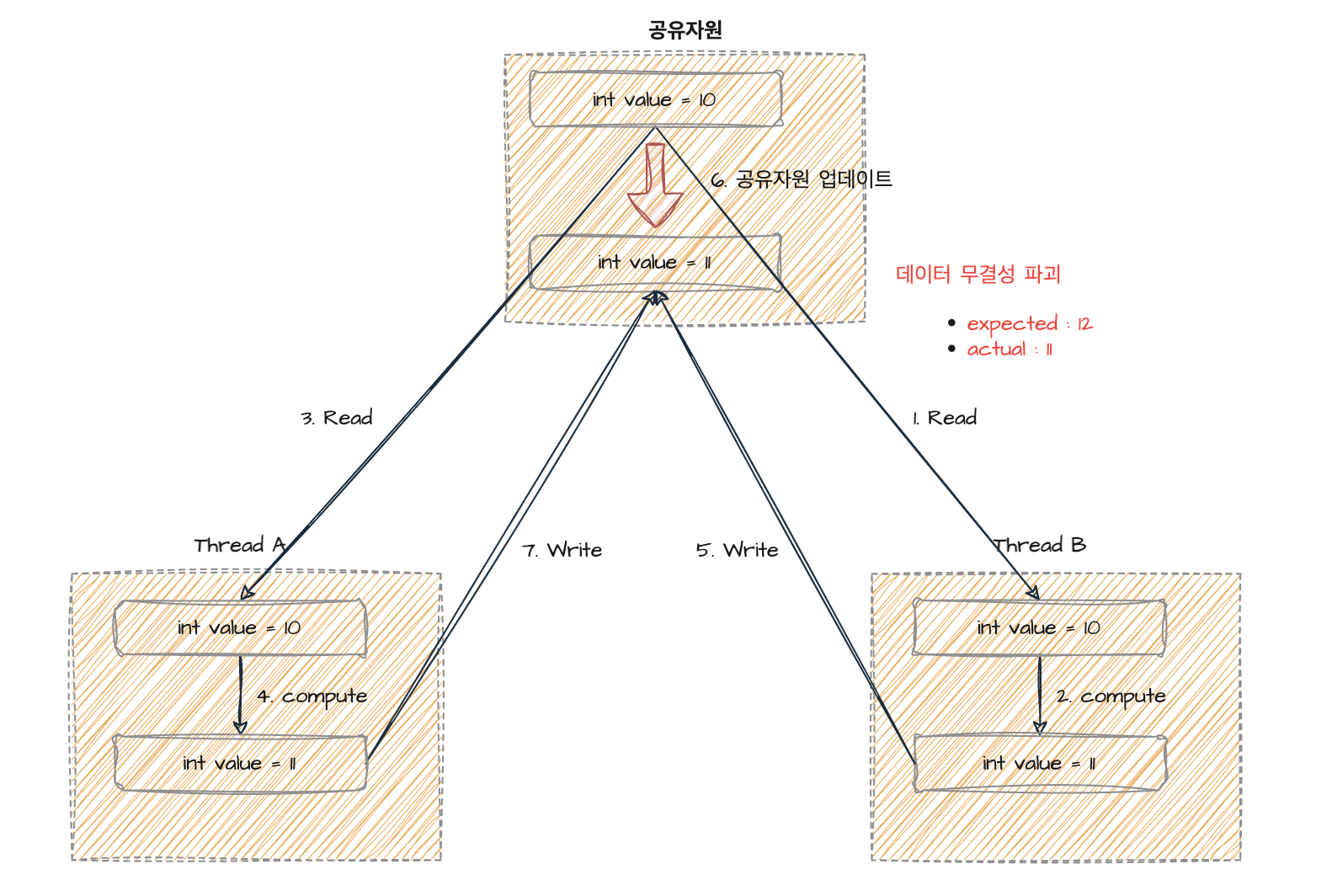
위 코드를 실행시켰을 때, 예상되는 값은 분명, 1000000이다. 하지만 그보다 작은 수인 993847과 같은 결과가 출력된다. (결과는 항상 다름) 왜 그럴까? 이는 코루틴을 사용한 멀티스레드 환경에서 공유자원인 counter변수를 제대로 갱신하지 못했기 때문이다. 즉, 위 그림과 연관지어 설명한다면, Thread A와 B에서 거의 동시에 값을 읽은 후, B에서 먼저 공유변수를 업데이트한다. 그 후, A가 동일한 공유변수를 업데이트했지만 이는 Thread B에 의해 동기화된 이전의 값을 참조해 진행한 연산이므로 결국 공유변수엔 동일한 값만 2번 업데이트가 된 것이다. 그렇다면 위와 같은 공유자원을 업데이트하려면 어떤 솔루션을 써야할까?
CAS(Compare And Swap)
synchronized나 mutext를 활용한 동기화 방법 또한 존재한다. 하지만 이 포스팅에선 CAS만 진행한다. CAS란 Compare And Swap의 약어로, 공유자원이 변경되었는지 비교 후, 변경되었다면 해당 공유자원에 쓰기작업을 진행하지 않고 변경되지 않았다면 진행하는걸 의미한다. 이를 그림으로 표현하자면 아래와 같다.
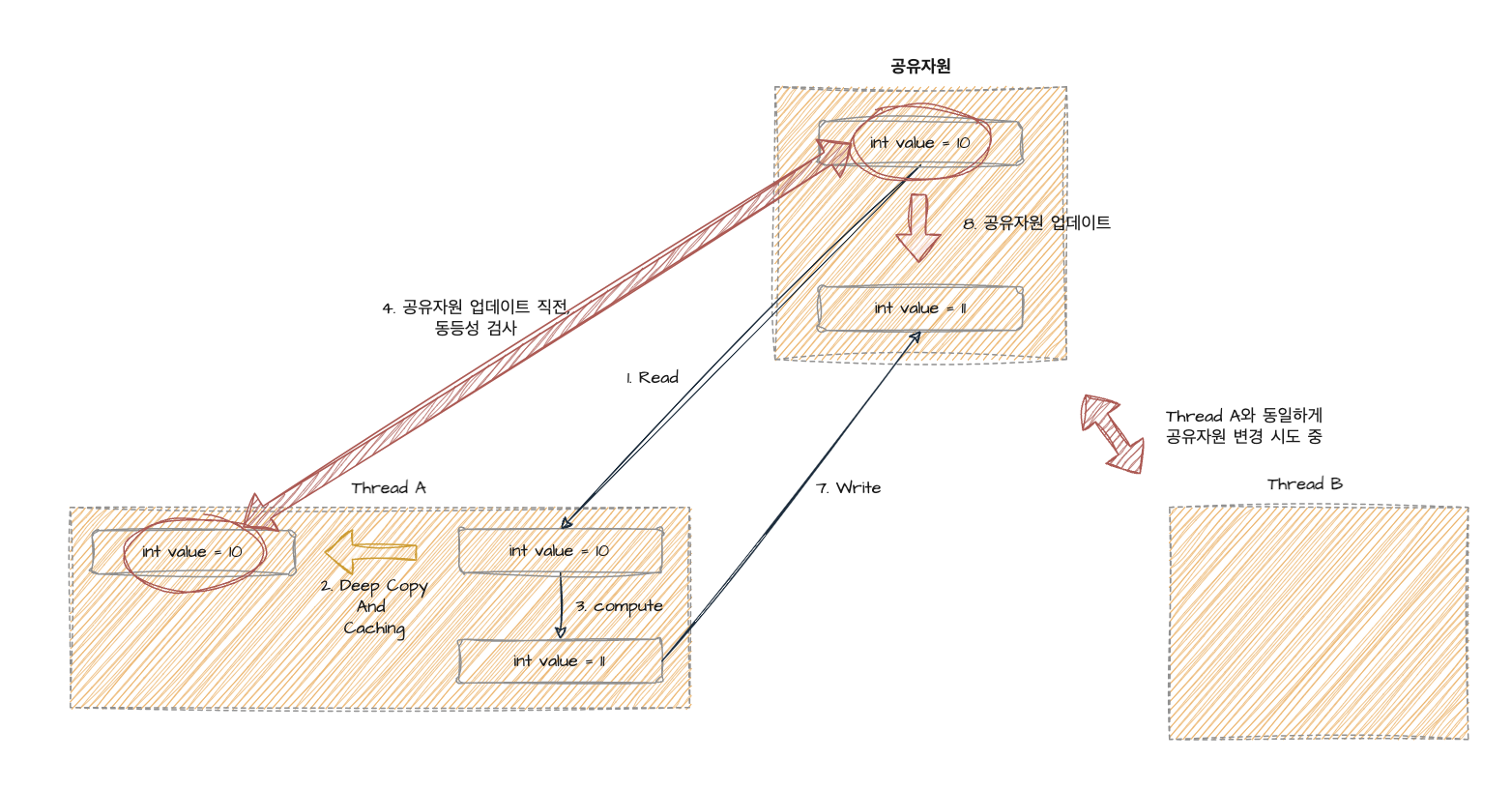
[깊은 복사 vs 얕은 복사]
- 깊은 복사 : 필드의 값 뿐만 아니라, 메모리 주소까지 복사함을 의미한다.
- 얕은 복사 : 필드의 값만 복사됨을 의미한다.
우선 첫 번째로는 위 프로세스와 동일하게 공유자원을 읽는다. 하지만 그 후 차이가 존재한다. 이는 읽어온 공유자원을 깊은 복사하여 캐싱해놓 작업이 추가됨을 의미한다. 그 후, 읽어온 공유자원에 연산을 수행한다. 하지만 이때 바로 공유자원에 쓰는 작업은 하는게 아니라, 이전에 캐싱해두었던 값과 현재 공유자원의 값에 동등성 비교를 진행한다. 만약 동등하다 나왔다는건 무엇을 의미할까? 그것은 바로 해당 공유자원이 다른 스레드에 의해 갱신되지 않았다는 것이고, 그 순간에 진행하는 공유자원 업데이트는 무결성을 보장해준다는 것이다.
하지만 만약 동등성 비교를 실패한다면 어떨까? 그것은 예상했겠지만 다른 스레드에 의해 해당 공유자원이 변경되었다는 것이고 이는 데이터 무결성이 파괴되었다는걸 의미한다. 따라서 그 상태에선 공유자원을 업데이트를 진행하면 안된다. 그럼 어떻게 해야할까?
바로, 공유자원을 읽어오는 작업부터 다시 시작해야한다는 것이다. 즉, 위 그림에 표시한 1번부터 7번까지의 과정을 처음부터 다시 진행해야 한다는 것이다. 언제까지? 깊은 복사를 적용한 캐싱값과 공유자원 현재값이 동일해 질때까지 말이다. 그렇다면 이제 이를 기반으로 안드로이드에서 가장 친숙한 CAS를 구현한 API인 StateFlow.update와 AtomicType를 순차적으로 알아보자.
StateFlow.update
필자는 StateFlow.update를 아래와 같이 정의했다.
상태값을 원자적으로 업데이트하기 좋은 Hot Flow
혹시나 StateFlow에 대한 자세한 설명이나, 위 정의가 어떻게 도출되었는지 궁금하다면 필자가 작성해놓은 StateFlow와 SharedFlow의 차이를 참고하면 좋다.
아무튼, StateFlow.update의 내부를 살펴보면 아래와 같다.
/**
* Updates the [MutableStateFlow.value] atomically using the specified [function] of its value.
*
* [function] may be evaluated multiple times, if [value] is being concurrently updated.
*/
public inline fun <T> MutableStateFlow<T>.update(function: (T) -> T) {
while (true) {
val prevValue = value
val nextValue = function(prevValue)
if (compareAndSet(prevValue, nextValue)) {
return
}
}
}위 부분만 이해해도 많은걸 얻어갈 수 있다. 우선 DOC주석을 먼저 보자. 위 DOC주석에 첫 시작으로 'Updates the [MutableStateFlow.value] '라고 말하고 있다. 이는 StateFlow가 가진 내부 상태 프로퍼티인 value를 의미하며 이는 곧 해당 클래스 내, 정의된 공유자원을 의미한다.
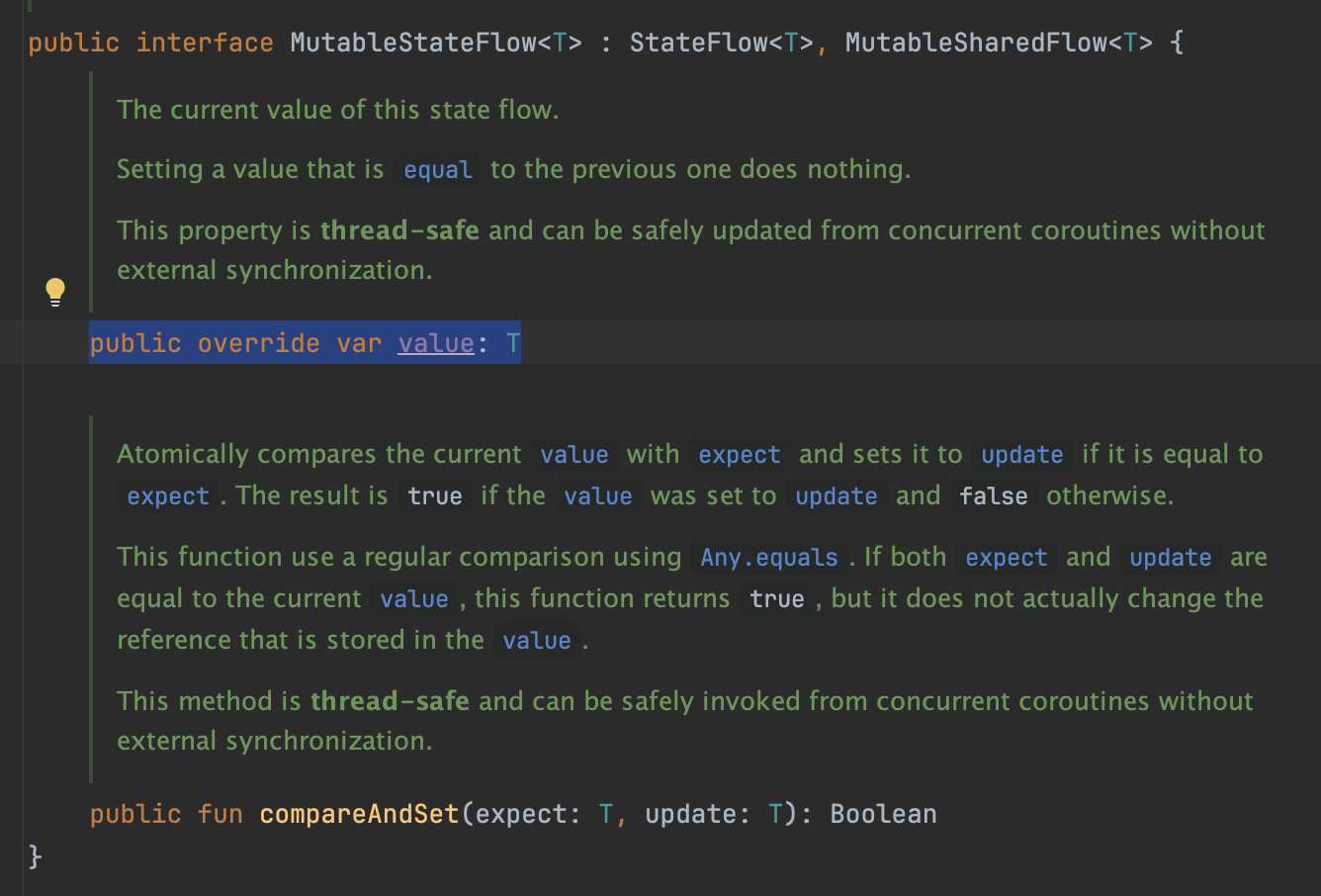
즉, StateFlow는 클래스 내, 정의된 'value' 네이밍의 공유자원을 중심으로 원자성 보장 로직을 진행하는 것이다.
아무튼, 다시 StateFlow.update메서드 내부로 다시 돌아오자. 해당 메서드 내부엔 prevValue라는 프로퍼티를 신규 정의하여 value값을 얻어오는걸 볼 수 있다. 왜 굳이 이렇게까지 진행하지? 란 생각이 들 수 있지만, 이는 추후 공유자원의 최신값 변경 여부 비교를 위한 '공유자원 캐싱작업'을 의미한다.
그 후, compareAndSet메서드 내부를 들어다보면?
/**
* Atomically compares the current [value] with [expect] and sets it to [update] if it is equal to [expect].
* The result is `true` if the [value] was set to [update] and `false` otherwise.
*
* This function use a regular comparison using [Any.equals]. If both [expect] and [update] are equal to the
* current [value], this function returns `true`, but it does not actually change the reference that is
* stored in the [value].
*
* This method is **thread-safe** and can be safely invoked from concurrent coroutines without
* external synchronization.
*/
public fun compareAndSet(expect: T, update: T): Boolean위에 설명된 DOC주석을 간단히 요약해보면 아래와 같다
expect파라미터 즉, 공유자원을 캐싱한
prevValue를 통해 공유자원의 최신값인 'value'와 동등성 비교작업을 진행한다. 동일하다면 'update'파라미터로 들어온 값으로 공유자원을 갱신하고, 그렇지 않다면 갱신하지 않는다.
StateFlow.update를 사용해 공유자원 무결성이 보장되는지 확인할 수 있는 간단한 코드는 아래와 같다.
fun dataIntegrityTest() {
val _counter = MutableStateFlow(0)
repeat(1000) {
viewModelScope.launch(Dispatchers.Default) {
_counter.update { _counter.value + 1 } // 1000 나옴
_counter.value += 1 // 321과 같은 값 나옴
}
}
}공유자원 '_counter'변수가 있다. 이를 업데이트하는데 두 가지 방법으로 진행한다. 첫 번째는 단순 .value를 사용한 일반적인 값 갱신법이고, .update를 사용한 원자적인 값 갱신이다. 당연한 결과이겠지만, 원자적인 값 갱신은 데이터 무결성이 보장되는 로그가 출력된다.
ViewModel에서의 UiState를 공유자원으로 관리하기
MVVM또는 MVI아키텍처 패턴을 사용하면, ViewModel에서 UiState를 사용해 UI의 상태관리를 진행하는게 일반적이다. 이때, UiState는 공유자원으로 볼 수 있다. 그 이유는 두 가지가 있다. 첫 번째는 UiState의 갱신은 viewModelScope.launch로 시작되는 코루틴들에 의해 실행되기 때문이다. 두 번째는 UiState의 갱신 작업이 원자적인 값 갱신을 보장해주는 update메서드를 사용하기 때문이다. 따라서 우리가 알지 못하게 UiState를 갱신하는 작업도 멀티스레드 환경에서 공유자원을 갱신한다는것을 인지할 필요가 있다.
data class MainUiState(...)
@hiltViewModel
class MainViewModel @Inject(): ViewModel() {
private val _uiState = MutableStateFlow(MainUiState())
val uiState = uiState.asStateFlow()
fun a() {
// 스레드에서 공유자원인 uiState동기화
viewModelScope.launch {
_uiState.update { it.copy() }
}
}
fun b() {
// 스레드에서 공유자원인 uiState동기화
viewModelScope.launch {
_uiState.update { it.copy() }
}
}
}AtomicType
compareAndSet을 활용하여 원자성을 보장해주는 또 다른 솔루션으로 AtomicType이 있다. 이는 아래와 같은 클래스가 있다.
- AtomicReference
- AtomicInteger
- AtomicIntegerArray
- AtomicLong
- AtomicLongArray
위 클래스들 또한 내부적으로 StateFlow.update와 비슷하게 공유자원의 원자성을 보장해준다. AtomicType클래스도 첫 초기화 할 때, StateFlow처럼 초기값 설정이 가능하다. 그리고 이는 내부에 공유자원으로 관리된다. 아래 코드는 AtomicReference의 일부로 필요한 부분만 발췌했다.
public class AtomicReference<V> implements java.io.Serializable {
private volatile V value;
/**
* Creates a new AtomicReference with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicReference(V initialValue) {
value = initialValue;
}
}우선 AtomicRererence또한 StateFlow.update와 동일하게 첫 생성자 파라미터를 통해 value값을 공유자원으로 설정하는걸 볼 수 있다. 아래 그림은 성공적으로 AtomicReference객체가 초기화된 후, compareAndSet또한 내부적으로 value값이 이전 캐싱한 값과 동일한지 비교 후 설정하는 코드 및 DOC주석이다.
fun main() {
private val hello = AtomicReference<User?>(null)
// 클릭하고 들어가보면...?
hello.compareAndSet(...)
}
/**
* Atomically sets the value to {@code newValue}
* if the current value {@code == expectedValue},
* with memory effects as specified by {@link VarHandle#compareAndSet}.
*
* @param expectedValue the expected value
* @param newValue the new value
* @return {@code true} if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(V expectedValue, V newValue) {
return VALUE.compareAndSet(this, expectedValue, newValue);
}이 또한 요약하면 위와 동일한데, 현재 공유자원인 value가 expectedValue와 동일하다면 이를 newValue로 설정하라는 코드이다.
ViewModel에서 StateFlow가 아닐 경우 AtomicType으로 상태관리
ViewModel에서 UiState로 상태관리가 가능한 이유는 StateFlow를 사용하기 때문이고 이는 내부적으로 CAS를 통한 공유자원 무결성을 보장해주기 때문이다.
하지만 ViewModel에서 UiState가 아닌 경우 즉, StateFlow 사용이 부적절하여 그 이외 방법으로 상태값을 관리해야할 경우가 생길수도 있다. 필자의 경우를 예로 들어볼까 한다. ViewModel에서 수신받은 푸쉬 메시지를 통해 이를 UI 상태값에 영향을 줘야하는 상황이다. 하지만 이는 ViewModel에서 캐싱해야만 하는 상황인데, 이런 경우 내부적으로 CAS를 StateFlow.update와 비슷하게 사용하는 AtomicType를 쓰면 좋은 방법일 수 있다.
대표적인 예로 AtomicReference로 이를 설명해볼까 한다. AtomicReference는 상태값을 원자적으로 갱신할 때 updateAndGet()을 사용한다. 이를 내부적으로 살펴보면 StateFlow.update와 비슷하다는 점을 쉽게 알 수 있다.
/**
* Atomically updates (with memory effects as specified by {@link
* VarHandle#compareAndSet}) the current value with the results of
* applying the given function, returning the updated value. The
* function should be side-effect-free, since it may be re-applied
* when attempted updates fail due to contention among threads.
*
* @param updateFunction a side-effect-free function
* @return the updated value
* @since 1.8
*/
public final V updateAndGet(UnaryOperator<V> updateFunction) {
V prev = get(), next = null;
for (boolean haveNext = false;;) {
if (!haveNext)
next = updateFunction.apply(prev);
if (weakCompareAndSetVolatile(prev, next))
return next;
haveNext = (prev == (prev = get()));
}
}AtomicReference내부이다. DOC주석을 읽어보면 StateFlow.update와 상당히 유사함을 알 수 있다. 'current value'를 주어준 람다함수 반환값으로 설정하며, 업데이트 실패 시, 공유자원을 읽어 캐싱하는 작업부터 다시 시작한다는 주석을 볼 수 있다. 따라서 ViewModel에서 UiState갱신하는것 외의 방법으로 상태값을 원자적으로 관리하고자 하면 AtomicReference.updateAndGet메서드 사용을 고려해봄직 하다.
@HiltViewModel
class MainViewModel @Inject constructor() : ViewModel() {
private val pushData = AtomicReference<AuthenticationPushDto.Dialog?>(null)
init {
viewModelScoope.launch {
launch {
// 첫 초기화 시, MainUiState 초기화
}
launch {
// A라는 스트림으로부터 받은 데이터로 pushData가 원자적으로 업데이트 된다.
observeFlowA
.catch {}
.collect {
pushData.updateAndGet {
it.copy(...)
}
}
}
launch {
// B라는 스트림으로부터 받은 데이터로 pushData가 원자적으로 업데이트 된다.
observeFlowA
.catch {}
.collect {
pushData.updateAndGet {
it.copy(...)
}
}
}
}
}위 코드를 대략적으로 설명해볼까 한다. 앱이 시작했을 경우, 푸쉬 메시지를 A스트림으로부터 다운스트림 받는다. 그리고 이는 ViewModel내, 'pushData'로 캐싱된다. 하지만 이 'pushData'는 여러 스트림으로부터 받을 수 있는데, 이는 멀티 스레드 환경에서의 공유자원 갱신이라 볼 수 있다. 따라서 'pushData'를 공유자원의 원자적 업데이트를 가능하게 해주는 AtomicReference를 적용한 것이다. 이제 이를 사용하여 값을 갱신해준다면, 몇개의 스레드로부터 'pushData'가 갱신되는지와는 관련 없이 데이터 무결성을 유지해줄 것이다.
마치며
놓치며 개발하기 쉬운 ViewModel내에서의 멀티스레드 동기화 기법에 대해 다뤄보았다. 필자가 놓친 부분이었기도 했고, 최근에 깨닳은 부분이다. 도움이 많이 되었으면 좋겠다.
