
1. Equals()와 Hashcode()의 관계
1.1. Equals()
많은 Kotlin/JVM 개발자들이 헷갈리는 개념 중 하나가 ==, ===, 그리고 equals()의 차이이다. 우선, Kotlin에서는 아래의 규칙을 따른다.
- 값 비교 :
equals()or==호출 - 참조 비교 :
===
반면, java의 경우는 다르다.
- 참조 비교 :
equals()or==호출 (Object객체 기준) - 값 비교 :
equals()를 새롭게 오버라이딩하는 방식으로 가능(eg.,String()orInteger등...)
Java식 예시로 살펴보자:
String a = new String("hello");
String b = new String("hello");
System.out.println(a == b); // false (참조 비교)
System.out.println(a.equals(b)); // true (값 비교)위에서도 말했다시피 equals()의 기본 구현은 Object 클래스의 참조를 비교(this == obj)하는 방식이다. 즉, Object 하위 클래스가 직접 equals()를 오버라이드하지 않는 한, 참조 비교를 진행한다는 것이다.
// Object.java
public boolean equals(Object obj) {
return (this == obj);
}하지만 우리가 많이 사용하는 String()의 경우, 내부적으로 '값'을 비교할 수 있도록 equals()가 오버라이딩 되어있는것도 확인할 수 있다.
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
// BEGIN Android-changed: Implement in terms of charAt().
/*
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
*/
String anotherString = (String)anObject;
int n = length();
if (n == anotherString.length()) {
int i = 0;
while (n-- != 0) {
if (charAt(i) != anotherString.charAt(i))
return false;
i++;
}
return true;
}
// END Android-changed: Implement in terms of charAt().
}
return false;
}마찬가지로, Integer, data class 같은 클래스들은 '값'을 비교할 수 있도록 equals()가 오버라이딩 되어있으며, 이를 통해 '값'을 통한 비교가 가능해지는 것이다.
👉 핵심 요약:
Object.equals()의 기본 구현은 참조 비교.String,Integer,data class등은 값을 기준으로equals()를 재정의해 둠.- Kotlin의
==는 내부적으로equals()를 호출하므로 값 비교로 보임.
1.2. HashCode()
hashCode()는 객체의 해시값(정수)을 반환하며, 해당 객체의 ID와 비슷한 역할을 할 수 있다. 또한 이는 equals()와 함께 자바의 컬렉션에서 매우 중요하게 동작하는데, 특히 JRE환경에서 제공해주는 프레임워크 라이브라리인 HashMap, HashSet의 동작에 핵심적인 영향을 준다.
위 자료구조를 사용하며, 새로운 값을 넣었다 가정하자. 이때 이들에게 hashCode()가 호출되어 Int값이 추출되고 이들이 버킷의 인덱스 값으로 지정된다. 그 후, 값에 해당하는 부분이 배열의 bucket으로 위치하게 된다. 즉, hashcode()를 통해 요소들의 위치가 결정된다는 것이고, 이는 곧, 위치의 빠른 탐색도 가능하단 뜻이다. 따라서 JRE에서 제공해주는 라이브러리의 동작 일관성 보장을 위해 equals()와 hashcode()의 규약을 지켜야 한다.
ps. kotlin개발자의 경우, 주로 data class를 사용하고, equals(), hashcode()를 자동으로 오버라이딩하기에 잘 사용을 안할수도 있다.
[📌 equals()와 hashCode()의 규칙]
규칙 1.a.equals(b)가 true면,a.hashCode() == b.hashCode()여야 한다. (항상!)
규칙 2. 반대로a.hashCode() == b.hashCode()라고 해서a.equals(b)가 true라는 보장은 없다. (충돌 가능성)
규칙1. a.equals(b)가 true면, a.hashCode() == b.hashCode()여야 한다. (항상!)
아래는 규칙1 을 어겼을 때의, 비정상 동작을 구현한 코드로, data class가 아닌, 일반 class에서 equals()만 오버라이딩 하였다.
class User(val name: String) {
override fun equals(other: Any?): Boolean {
return other is User && name == other.name
}
// hashCode 생략
}즉, equals()를 통한 동등성 비교는 true가 나올지라도, 객체를 식별하는 hashCode()는 생략되어, 다른 값이 출력된다. 따라서 동일 값의 객체가 중복 저장된다.
ps. HashSet은 요소들의 중복을 허용하지 않는 자료구조여야 한다.
val set = HashSet<User>()
set += User("Alice")
set += User("Alice")
println(set.size) // 2 → hashCode가 다르므로 같은 객체로 인식 못 함왜 이런 문제가 발생한걸까?
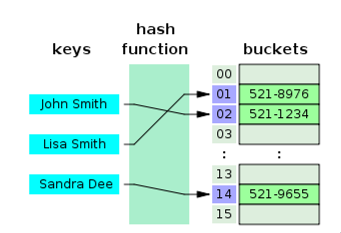
문제 발생 원인을 알기 전, HashSet의 내부 동작 원리를 알아야한다. 이 자료구조는 내부적으로 배열로 이뤄져있으며,(HashMap도 동일) index와 bucket이 존재한다. 동작방식은 아래와 같다.
- 위 자료구조에 객체를 넣는다.
- 객체에 오버라이딩 돼있는
hashcode()가 호출되며,bucket의index로 할당된다. - 객체의 값이 해당
index에 매핑돼있는bucket으로 이동한다. - 이후, 객체를 '검색'할 경우, 검색하려는 객체의
hashcode()를 조회 후,index부분에 바로 접근한다. - 접근에 성공할 경우, 검색하려는 객체와
bucket에 있는 객체에equals()를 호출하여 동등성 여부를 검사한다.
즉, set += User("Alice")코드를 2번 진행할 때, User객체의 hashcode()는 다르게 출력하기때문에 그렇다. 따라서 위 2번 단계 즉, hashcode()로 변환하고 set하는 과정에서 각각의 User객체는 다른 index의 bucket으로 매핑되어 객체가 추가 저장된 것이다. 이런 이유로, User객체의 hashCode()는 값과는 무관한 난수를 출력할 것이므로, contains()를 호출했을 때 무조건적으로 false를 반환하게 된다.
규칙 2. 반대로 a.hashCode() == b.hashCode()라고 해서 a.equals(b)가 true라는 보장은 없다. (충돌 가능성)
해시값은 버킷 후보를 좁히기 위한 정수 지표일 뿐, 최종 동등성 판단은 equals가 한다. 따라서 만약, 서로 다른 객체가 동일한 해시값(충돌)을 가진다면, 이 둘은 같은 bucket에 들어간다. 하지만 같은 bucket내부에서 이 둘을 equals로 비교할 때, 만약 다르다면, 1개의 bucket내에서 2원소가 중복으로 저장된다. 왜냐하면, 해시함수 자체의 충돌은 항상 발생할 수 있기 때문이다.
ps. 그래서 해시 함수 알고리즘이 충돌이 많이 나는 녀석이라면 성능이 O(1) → 최악 O(n)으로 급락할 수 있다(버킷에 객체가 몰리기 때문).
// 예시 1: 실제 충돌(String “FB” vs “Ea”)
fun main() {
val a = "FB"
val b = "Ea"
println(a.hashCode()) // 2236 (JVM에서 동일)
println(b.hashCode()) // 2236
println(a == b) // false
// 해시충돌이 났지만, equals에선 true이다.
val set = hashSetOf<String>()
set += a
set += b
println(set.size) // 2 ✅ (해시 충돌이 발생해도, 1개의 bucket에서 2개의 원소가 저장된다.)
}위 로그는 같은 해시를 출력하고 있지만 equals가 달라, 서로 다른 원소로 남는다는걸 볼 수 있다.
// 예시 2: “나쁜” hashCode 구현(충돌 유발)
class User(val name: String) {
// 의도적으로 모든 객체를 같은 버킷에 몰아넣는 최악의 구현
override fun hashCode(): Int = 0
// data class의 equals는 name으로 동등성 비교(기본 동작 유지)
}
fun main() {
val set = hashSetOf<User>()
set += User("Alice")
set += User("Bob")
println(set.size) // 2 ✅ (equals가 다르므로 둘 다 저장)
println(set.contains(User("Bob"))) // true지만, 내부 탐색이 느려질 수 있음
}규칙 1은 지켜지긴 한다(동등하면 해시도 동일: 0). 하지만 해시 분산이 0이라 모든 원소가 한 버킷에 모여 탐색·삽입 성능이 급격히 저하된다.
요점 정리
- 동일 해시값 ⇒ 같은 버킷 “후보”로만 보낼 뿐, 중복 여부는 equals가 결정한다.
- 충돌은 허용되지만, 분산이 나쁜 hashCode는
hashSet내부에서 한 버킷으로 요소가 몰려, 성능 문제를 만든다. - 따라서 커스텀할 땐 동등하면 같은 해시, 다르면 가급적 다른 해시를 지향해 필드들의 해시를 적절히 조합하자.
2. int의 박싱과 언박싱
Kotlin에서 Int는 기본 정수 타입으로 사용되며, 마치 Java의 int처럼 동작한다. 하지만 이는 실제 JVM 상에서 boxed Integer로 변환될 수 있다.
2.1. 제네릭 타입의 사용
JDK 1.5버전 이전까진 제네릭 타입이 존재하지 않았지만, 1.5(=JDK 5)이후 버전엔 제네릭 타입이 생겼다. 하지만 이를 바로 도입하기엔 자바 바이트코드의 JDK 하위호환성(자바 언어 명세에 있음) 문제가 있었다. 예를 들어, JDK 1.2버전으로 만들어진 바이트코드는 JDK 21에서의 동작을 보장해야 한다는 것이다. 이는 곧, JDK 5의 신규 제네릭 프로젝트는 제네릭 기능을 신규 기능으로써 사용 가능하지만, 제네릭을 표현할 수 없는 바이트코드의 동작도 보장해야함을 의미했다. 이러한 제약 안에서 자바진영이 택할 수 있는 방안은 2가지였다.
- 제네릭 타입 콜렉션 API를 신규 추가한다.
- 기존 콜렉션 API에 제네릭 기능을 붙임과 동시에, 이들의 하위호환성을 지원한다.
[1. 제네릭 문법 추가에 따른, 제네릭 타입 콜렉션 API를 신규 추가한다.]
기존에 존재하는 ArrayList, Vector, Map 와 함께, 신규 API가 추가될 때, 중복 API들이 존재하게 된다. 즉, ArrayList<T>, Vector<T>, Map<T>들이 신규 추가된다는걸 의미하며, 이는 기존의 것들과 중복이 되며, 자바를 쓰는 개발자 뿐만 아니라 언어 JDK 유지보수에도 문제가 예상되었다. 그만큼, 해당 방법은 좋은 방법이 아니기에 진행되지 않았다.
[2. 기존 콜렉션 API에 제네릭 기능을 붙임과 동시에, 이들의 하위호환성을 지원한다.]
따라서 ArrayList는 제네릭 원시타입으로, ArrayList<T>는 제네릭 파생타입이라는 부모 관계를 정립함으로써 ArrayList<T>는 ArrayList로도 컴파일할 수 있는 방식이 채택됐다. 따라서 자바코드를 따라쳐보면 알겠지만 ArrayList<T>는 ArrayList로도 바꿔쓸 수 있다.
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>(); // 제네릭 파생타입1
ArrayList<Integer> list2 = new ArrayList<>(); // 제네릭 파생타입2
ArrayList list; // 제네릭 원시타입
list = list1; // 제네릭 파생타입을 원시타입으로 상위캐스팅
list.add("helloWorld");
list = list2; // 제네릭 파생타입을 원시타입으로 상위캐스팅
list.add(123);
}위 코드를 보면 알겠지만 제네릭 파생타입(=ArrayList<String>) 객체는 제네릭 원시타입(=ArrayList)객체로 다시 초기화할 수 있다. 그리고 제네릭 원시타입(=Object타입)객체로 모든 참조타입 객체를 add()하는것을 볼 수 있다. 따라서 이러한 타입소거방식의 단점은 제네릭 타입을 상위 Object타입으로의 변환이 가능하여 안정성이 떨어질 수도 있다는 점이다. (하지만 ArrayList를 사용할 때, 제네릭타입을 안쓰는건 일반적이지 않긴 하다)
어쨋든, JDK의 옛 버전과 최신 버전의 하위호환성 유지를 위해, ArrayList<T>와 같은 코드를 javac로 컴파일하면 해당 코드는 타입 소거 즉, Object타입으로 변환된다. 하지만 이렇게 Object타입으로 변환된 코드가 결국, <T>타입임을 보장해야만 하는데, 이때 바로 형변환이 들어간다. (코틀린으로 치면 as String)
public static void main(String[] args) {
Object obj = new ArrayList<String>(); // 타입 소거 후 Object로 저장
String s = (String) ((ArrayList) obj).get(0); // 꺼낼 때 String 캐스팅
}하지만, ArrayList<int>타입은 어떨까? 우선, int는 원시타입이며, 메모리에 적재되는 장소는 Stack영역이다. 반면, Object타입은 참조타입이며 메모리는 Heap이다. 따라서 이 둘 사이의 형 변환은 불가능하며, 이는 자바에서 큰 문제가 되었다. 따라서 ArrayList<int>와 같은 원시 타입의 제네릭 타입을 컴파일하기 위해서, 자바진영은 좀 조악한 방법을 사용했는데, 그것이 바로 boxing타입을 활용한 것이다.
| Kotlin 타입 | Nullable 여부 | JVM 타입 | 비고 |
|---|---|---|---|
Int | Int | int | primitive |
Int? | Integer | Integer | boxed |
Long | Long | long | primitive |
Long? | Long | Long | boxed |
Float | Float | float | primitive |
Float? | Float | Float | boxed |
Double | Double | double | primitive |
Double? | Double | Double | boxed |
Boolean | Boolean | boolean | primitive |
Boolean? | Boolean | Boolean | boxed |
Char | Char | char | primitive |
Char? | Character | Character | boxed |
String | 항상 객체형 | java.lang.String | 무조건 참조형 |
따라서 아래와 같이 List<Int>타입을 Java 바이트코드로 확인하면 List<Integer>로 변경됨을 확인할 수 있으며, 이는 원시타입을 그에 대응되는 방식 타입으로의 변환함을 의미한다.
val list = listOf(1,2,3)👉 ByteCode로 아래와 같이 바뀐다.
Integer[] var1 = new Integer[]{1, 2, 3};2.2. Nullable 타입 사용
Java의 프리미티브 타입에는 Nullable을 표현할 수 없다. 따라서 Lombok등을 추가 활용하여 @Nullable, @Notnull등을 표시해주는데, 이들은 보일러플레이트의 느껴지기도 한다. 하지만 Kotlin은 랭기지 레벨에서 이들을 지원해준다. 만약, 프리미티브 타입이 Nullable할 경우, 이들을 Integer와 같은 타입으로 박싱한다.
val a: Int? = 10
print(a)👉 ByteCode로 아래와 같이 바뀐다.
Integer a = 10;
System.out.print(a);2.3. Any / Object와 같은 상위 타입의 사용
최 상위 타입을 사용할 때에도 int 대신 Object와 같은 타입으로 박싱이 발생한다.
val a: Any = 10
print(a)👉 ByteCode로 아래와 같이 바뀐다.
Object a = 10;
System.out.print(a);즉, 개발자는 원시타입 Int를 사용한다 해도, JVM에선 이들을 표현하기 위해 적절히 Integer, Object등으로 박싱하여 사용한다.
3. 확장 함수의 컴파일 방법
Kotlin의 확장 함수는 문법적으로 클래스에 메서드를 추가하는 것처럼 보인다. 하지만 실제로는 정적(static) 함수로 변환되며, 첫 번째 인자로 수신 객체(this)가 전달된다.
fun String.greet(): String {
return "Hello, $this!"
}👉 ByteCode로 아래와 같이 바뀐다.
public static String greet(String receiver) {
return "Hello, " + receiver + "!";
}즉, 확장 함수는 컴파일 시 클래스에 실제로 추가되지 않고, 정적(static) 함수로 변환되어 애플리케이션 어디에서든 호출할 수 있게 된다. 결국 확장 함수는 문법적으로만 멤버 함수처럼 보이도록 설계된 것일 뿐이다.
