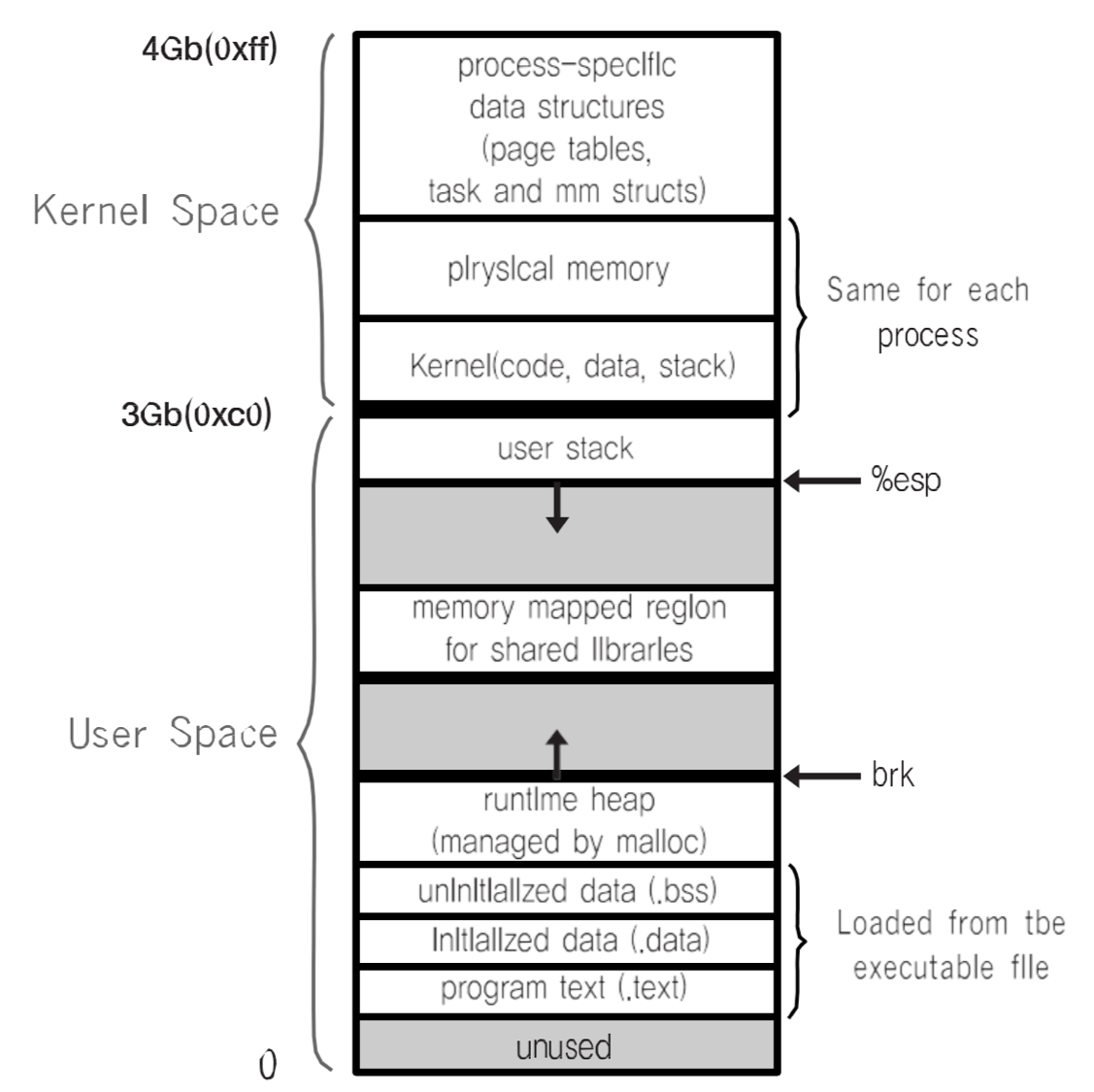
일단 가상 메모리의 구조를 머릿속에 넣어두고 생각하자.
malloc()은 동적으로(= 런타임에) 가상 메모리의 힙(heap) 영역에 메모리를 할당해준다.
배열을 정해진 크기로 사용할 수 없거나,
보통 1MB 정도의 크기를 갖는 스택(stack) 영역을 초과하는 양의 배열이 필요할 때,
우리는 malloc()을 통해 스택에는 할당된 힙 영역을 가리키는 포인터만 남기고,
배열 자체는 힙으로 넘길 수 있다.
32비트 x86 리눅스 프로세스의 가상 주소 공간 구조를 기준으로 기본 개념을 짚어보자.
32비트 체계는 한 번에 32비트의 데이터를 처리할 수 있는 시스템을 말한다.
즉, CPU 레지스터의 크기가 32비트라는 뜻이며, 1워드(word)는 32비트 = 4바이트다.
이 경우 2³² = 4,294,967,296 = 4GB의 정보를 표현할 수 있다.
프로세스당 하나씩 주어지는 가상 메모리 역시 최대 4GB까지 주소를 할당할 수 있다.
(이게 부족해서 64비트 체계가 등장했다.
이론적으로는 64비트 시스템에서 2⁶⁴ = 16EB(엑사바이트)의 정보를 표현할 수 있다.
하지만 현실적으로는 이걸 다 쓰지 않고, 운영체제(OS)와 하드웨어(HW)가
부분적으로만 주소 공간을 할당하고 사용한다.)
가상 주소 공간의 맨 윗부분은 커널을 위해 예약되어 있다.
리눅스는 기본적으로 커널 공간을 위쪽 1GB로 설정하기 때문에 그런 그림이 나오지만,
운영체제 또는 커널 빌드 설정에 따라 커널/유저 공간의 비율은 조절 가능하다는 점도 기억하자.
(예를 들어, 윈도우 x86의 기본 설정은 커널 공간을 위쪽 2GB로 잡는다.)
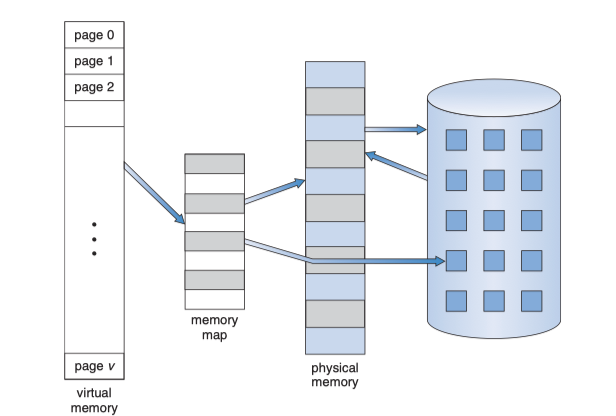
가상 메모리(Virtual Memory)는 실제 물리 메모리와 사용자 논리 메모리를 분리한 개념이다.
페이지(page)는 커널 영역이든 유저 영역이든 상관없이,
가상 주소 공간 전체를 일정한 크기(보통 4KB)로 나누어 관리한다.
그리고 논리적인(가상) 페이지를 물리적인 페이지 프레임에 매핑하는 일은 MMU(Memory Management Unit)가 담당한다.
단, 커널 영역은 일종의 공유 객체처럼 모든 프로세스가 동일한 물리 메모리를 공유하지만,
유저 모드에서는 접근할 수 없도록 보호되어 있다.
가상 메모리를 규정된 크기의 블록 단위로 분할하여 관리하는 시스템을
VM 시스템(Virtual Memory System)이라고 하며,
이는 캐싱 도구(페이지 적중/오류/할당), 메모리 보호 및 관리 등 다양한 역할을 수행한다.
(CS:APP 9.3 ~ 9.5 참고. 9.6의 주소 번역(Address Translation) 부분도 함께 보면 좋다.)
메모리 정렬(Alignment) 규칙은 데이터가 메모리에 저장될 때,
데이터 타입 크기에 따라 특정 경계에 맞춰 정렬되어야 한다는 것이다.
정렬이 필요한 이유는 CPU는 정렬된 주소에 대해 빠르게 접근할 수 있게 설계되어 있고,
명령어/레지스터/데이터 폭에 따라 정렬 단위가 정해지기 때문이다.
malloc, 스택 변수, 구조체 멤버 등 모두 이걸 만족해야 오류 없이 동작하고, 성능도 좋다.
패딩(Padding)은 정렬을 맞추기 위해 컴파일러가 자동으로 삽입하는 빈 공간이다.
| 시스템 | 레지스터 크기 | 주 연산 단위 | 대표 정렬 |
|---|---|---|---|
| 32비트 (x86) | 4바이트 | 32비트 int/pointer | 8바이트 정렬 |
| 64비트 (x86_64) | 8바이트 | 64비트 pointer, double | 16바이트 정렬 |
64bit 체계에서는 주소는 항상 16의 배수이고, 32bit 체계에서는 항상 8의 배수이다.
(64비트 시스템은 8바이트 단위로 동작하지만,
추가로 SIMD(SSE, AVX 등)까지 고려하면 16바이트 정렬이 안전하고 빠르다.)
malloc()은 사용자가 어떤 타입의 데이터를 담을지 모르기 때문에
가장 까다로운 정렬 조건(최대 align 요구)을 만족시켜서 구현한다.
| 8바이트 정렬 → 주소의 하위 3비트가 0 | 16바이트 정렬 → 주소의 하위 4비트가 0 |
|---|---|
| (addr % 8 == 0, 2³ = 8) | (addr % 16 == 0, 2⁴ = 16) |
메모리 할당기 구현
│
├── 1. 제약 조건 (요구사항)
│ ├── 임의의 요청 순서 처리
│ ├── 요청에 즉시 응답
│ ├── 힙만 사용 (정적/전역 공간 사용 X)
│ ├── 블록 정렬 보장 (Alignment)
│ └── 할당된 블록은 수정 불가 (Compacting X)
│
├── 2. 성능 목표
│ ├── 처리량(Throughput) 극대화
│ └── 메모리 이용도(Peak Utilization) 최대화
│
├── 3. 메모리 단편화
│ ├── 내부 단편화 (Internal Fragmentation)
│ │ └── 정렬/최소 크기 강제로 인해 낭비
│ └── 외부 단편화 (External Fragmentation)
│ └── 가용 공간은 충분하지만 연속된 블록 없음
│
├── 4. 기본 설계 요소
│ ├── 블록 크기 조정 (Alignment + Padding)
│ ├── 블록 정렬 기준 (보통 8 or 16 바이트)
│ └── 최소 블록 크기 설정
│
├── 5. 가용 블록 관리 방식
│ ├── 묵시적 리스트 (Implicit Free List)
│ ├── 명시적 리스트 (Explicit Free List)
│ └── 분리 가용 리스트 (Segregated Free Lists)
│ └── (option) Blocks Sorted by Size
│
├── 6. 할당 전략
│ ├── First Fit (최초 적합)
│ ├── Next Fit (다음 적합)
│ └── Best Fit (최적 적합)
│
├── 7. 블록 분할 (Splitting)
│ └── 큰 가용 블록을 요청 크기만큼 잘라 쓰고 나머지는 가용 상태로 유지
│
└── 8. 블록 병합 (Coalescing)
├── 반환된 블록이 인접한 가용 블록과 이어질 경우 병합
│ └── 오류 단편화(flase fragmentation) 해소
├── 연결 수행 시점 전략 (즉시 / 지연)
└── 경계 태그 (footer) 활용만약 할당기가 추가적인 힙 메모리가 필요할 때는, 우선 커널에게 메모리 요청을 보내기 위해 sbrk() 또는 mmap() 시스템 호출을 사용한다. 일반적으로 작은 요청(수 킬로바이트~수 메가바이트 수준)은 sbrk()를 통해 기존 힙 영역을 위로 확장하면서 처리한다. 반면, 매우 큰 요청(예: 수십~수백 MB 이상)이 들어오면 mmap()이 사용되며, 이때는 heap과 별개의 memory-mapped 영역(보통 힙보다 위, 스택보다 아래 위치)에 익명 메모리 페이지를 직접 매핑해 사용한다. 이는 힙의 연속성 유지나 단편화 문제를 피하고, 빠른 free() 처리와 캐시 최적화에 유리하다.

| 이름 | 설명 | free block 관리 방식 | 탐색 속도 | 삽입/삭제 비용 | 포함 관계 |
|---|---|---|---|---|---|
| Implicit Free List | 모든 블록 순회. free/allocated 구분만 header로 확인. (가장 단순) | 별도 없음 (전체 순회) | 느림 | 없음 | 최하위 (가장 단순) |
| Explicit Free List | free block만 별도로 관리. next/prev 포인터 추가. | 단일 free list | 빠름 | 약간 증가 (포인터 수정 필요) | Implicit 개선 |
| Segregated Free List | block 크기에 따라 여러 explicit list로 나눔. | 다수 free list | 매우 빠름 | 관리 복잡성 증가 | Explicit을 세분화 |
| Blocks Sorted by Size | free list를 크기 순으로 정렬하여 관리. (best-fit 최적화에 유리) | (위 구조에 추가 적용 가능) | 매우 빠름 | 삽입/삭제 느림 (정렬 유지 필요) | 별도 옵션 (Explicit, Segregated 모두 적용 가능) |
기본적으로 가용 블록(free block) 관리 방식을 고민한 후,
일정 크기의 블록 요청이 들어왔을 때 어떤 크기의 가용 블록에 넣을지를 결정하는 배치 전략,
선택한 가용 블록을 어느 정도까지 할당할지를 고려하는 블록 분할 전략,
인접한 가용 블록들을 합치는 블록 병합 전략을 설계해야 한다.
블록의 기본 구조
[ Header | Payload | Footer (optional) ]잠깐 짚고 넘어갈 부분이 있다.
블록이 allocate되었다가 free되었다고 해서, 그 내부의 데이터가 모두 사라지는 것은 아니다.
free된 블록은 header의 할당 비트만 변경되며, payload를 포함한 나머지 데이터는 초기화되지 않는다.
따라서 블록 내에 남아 있는 정보를 기반으로, 다양한 할당 및 병합 전략을 설계할 수 있다.
footer는 header의 정보를 그대로 복사해 둔 것이다.
footer는 이전 블록의 정보를 확인할 때 사용되며,
이러한 방식으로 블록을 병합하는 기법을 boundary tag coalescing이라고 부른다.
헤더의 포맷 예시(32bit system)
[ 29비트: 크기 | 1비트: 미사용 | 1비트: 미사용 또는 이전 블록의 alloc 여부 | 1비트: 현재 블록의 alloc 여부 ]간단한 헤더 포맷을 예로 들어 추가 설명하겠다.
header와 footer의 크기 역시 alignment 규칙에 따라 word size 단위로 결정된다.
여기서는 하위 3비트를 flag 용도로 사용하는데,
block size가 8바이트 단위로 정렬되므로 하위 3비트가 항상 0이 되는 특성을 이용한 것이다.
header에는 블록의 메타데이터가 저장된다.
블록 크기 (size) / 이전 블록의 할당 여부 (prev alloc, 선택적으로 사용) / 현재 블록의 할당 여부 (alloc)
작은 크기의 블록을 많이 사용하는 경우,
각 블록마다 footer를 붙이면 메모리 낭비가 커질 수 있다.
이런 상황에서는 prev alloc 정보를 header에만 기록하고,
할당 시에는 header만 사용하고 free될 때만 footer를 만들어주는 방식을 선택할 수 있다.
명시적/묵시적 방식 추가 설명, segregate나

와,, 이게 말록이구나!