웹 서버와 동적/정적 콘텐츠 제공 방식
웹 서버는 클라이언트(브라우저 등)와 HTTP 프로토콜을 사용해 통신한다. 클라이언트는 서버에 정적 콘텐츠 혹은 동적 콘텐츠를 요청하며, 요청 방식에 따라 서버의 응답 방식이 달라진다.
- 정적 콘텐츠(static content): 서버는 클라이언트의 요청을 받으면 디스크에서 해당 파일을 읽어 클라이언트로 전송한다.
- 동적 콘텐츠(dynamic content): 서버는 요청을 처리하기 위해 자식 프로세스(child process)를 생성하고, 그 안에서 프로그램을 실행하여 출력 결과를 클라이언트에게 반환한다.
이때 사용되는 것이 CGI (Common Gateway Interface) 표준이다. CGI는 다음과 같은 정보를 다룰 수 있는 규칙들을 정의한다.
- 클라이언트가 서버에 전달하는 프로그램 인자
- 서버가 자식 프로세스에 전달하는 환경 정보
- 자식 프로세스가 클라이언트에 출력 결과를 전달하는 방법
이러한 구조를 바탕으로, 정적 및 동적 콘텐츠를 모두 제공하는 웹 서버는 수백 줄의 C 코드만으로도 구현 가능하다. 이는 웹 통신의 본질이 클라이언트-서버 모델 + 소켓 통신 + 간단한 프로토콜 해석에 있음을 보여준다.
내가 궁금해서 찾아본 QnA
[1] 브라우저가 웹사이트를 처음 열었을 때
- 사용자가
https://www.google.com에 접속하면 브라우저는 내부적으로 다음 순서를 따른다:getaddrinfo()로 도메인을 IP 주소로 변환 (DNS 질의 포함)socket()호출로 TCP 소켓 생성connect()를 통해 서버에 3-way handshake 요청- 서버는
listen()상태에서 대기 중이므로,accept()로 연결 수락 후connfd반환 - 이 연결을 통해 서버는 HTML과 이미지, JS 등의 리소스를 응답하고 브라우저는 이를 화면에 렌더링
[2] 이후 같은 도메인에서 검색이나 이동이 발생했을 때
- HTTP/1.0 이라면 기본적으로 요청-응답 이후 TCP 연결을 끊는다 → 검색을 할 때마다 새로운
socket()과connect()호출 - HTTP/1.1 이상 이라면 기본적으로 Persistent Connection 유지:
- 서버가
Connection: keep-alive헤더를 응답에 포함하면, - 브라우저는 기존 TCP 연결을 재사용하여 요청을 보냄 (같은
connfd에서rio_readlineb()등으로 다시 처리) - 단, 서버가 연결을 닫거나 일정 시간이 지나면 새로운 연결을 다시 수립함
- 서버가
[3] 다른 도메인(예: naver.com)으로 이동했을 때
- 새로운 DNS 질의(
getaddrinfo("www.naver.com"))를 통해 IP 주소 획득 - 별도의
socket()및connect()로 새로운 TCP 연결 생성 - 이 연결은 완전히 독립적인 소켓이며, 서버 측에서도 다른 프로세스 혹은 다른
listenfd에서 수락됨
[4] 브라우저의 "뒤로 가기" 버튼을 눌렀을 때
- 대부분의 경우 캐시된 페이지를 재활용 하며, 네트워크 요청이 발생하지 않음
- 발생해도 다음과 같은 캐시 제어 정책에 따름:
200 (from cache): 완전히 로컬에서 렌더링304 Not Modified: 서버에 조건부 요청 (If-Modified-Since,If-None-Match등)을 보내고 변경 없음 판단 시 캐시 사용
- 따라서 "뒤로 가기"는 소켓 재연결 없이도 동작하는 브라우저 레벨 히스토리 복원 에 해당
[5] 로그인 상태에서 새 탭을 열었을 때 로그인 유지 이유
- 로그인 정보는 TCP 연결이 아닌 HTTP 쿠키 에 저장됨
- 쿠키는 브라우저의 도메인 단위 저장소 에 기록되며, 같은 브라우저 프로세스에서 새 탭을 열더라도 다음 요청에 자동 첨부됨
- 따라서 새로 열린 탭에서 새로운 TCP 연결이 생성되더라도 로그인 상태는 쿠키를 통해 유지됨
[6] 같은 URL이라도 접근 경로(링크 클릭 vs 직접 입력)에 따른 차이
- HTTP 요청에 포함되는
Referer헤더가 다름:- 링크 클릭 시:
Referer는 이전 페이지의 URL - 주소창 직접 입력 또는 즐겨찾기 클릭 시:
Referer는 빈 문자열이거나 존재하지 않음
- 링크 클릭 시:
- 서버는 이 값을 이용해 사용자 유입 경로, 광고 성과 측정, A/B 테스트 등을 수행할 수 있음
[7] 동일한 URL 요청 시 브라우저가 캐시를 사용할지 서버에 다시 요청할지 결정하는 기준
- 서버 응답의 헤더에 따라 달라짐:
Cache-Control: no-cache: 무조건 서버 재확인ETag: 클라이언트는If-None-Match로 조건부 요청 수행, 변경 없으면304응답Expires: 기한 전까지는 재요청하지 않음
- 같은 URL이라도 HTTP 메서드(GET/POST), 헤더, 쿠키 상태, 캐시 제어 값에 따라 네트워크 요청 여부가 결정됨
[8] 브라우저에서 하나의 HTML 요청이 만들어내는 다수의 연결
- 브라우저는 HTML 본문 외에도 CSS, JS, 이미지 등 수십 개의 리소스를 병렬로 요청함
- HTTP/1.0: 한 연결당 하나의 리소스 → 다수의
socket()호출과connect()필요 - HTTP/1.1: Persistent Connection + 파이프라이닝 가능 → 같은 연결 재사용
- HTTP/2: 하나의 TCP 연결 내에서 멀티플렉싱 을 통해 동시에 여러 요청/응답 처리
[9] keep-alive 연결은 언제 끊기는가?
- HTTP/1.1에서 기본적으로
Connection: keep-alive지만 무한히 유지되진 않음 - 서버는 일정 시간(
timeout) 동안 추가 요청이 없으면 연결을 닫음 - 클라이언트도 명시적으로
Connection: close를 보낼 수 있음 close후에는 새로운 요청 시 새로운 TCP 연결을 열게 됨
[10] HTTP와 TCP의 관계, 그 사이에서 발생할 수 있는 문제들
- HTTP는 TCP 위에서 동작하는 텍스트 기반 프로토콜
- TCP는 바이트 스트림이므로, HTTP 메시지의 경계를 보장하지 않음
- 예: 2개의 HTTP 요청이 하나의 TCP 세그먼트로 묶일 수도 있고 반대로 쪼개질 수도 있음
- 따라서 웹 서버는 버퍼 기반으로
\r\n또는 헤더 길이를 기준으로 정확히 메시지를 파싱해야 함
[11] 서버는 동시에 여러 연결을 어떻게 처리하나?
- 전통적 방식:
accept()후fork()또는pthread_create()로 각 연결을 분기 처리 - 현대적 방식:
select(),poll(),epoll()등을 사용한 I/O Multiplexing- 비동기/논블로킹 소켓
- 이벤트 기반 서버 (예: Node.js, Nginx)
- 이 모든 방법은 클라이언트 수 증가에 대응하기 위한 확장성 확보 방식임
[12] HTTPS의 등장으로 생기는 차이점
- HTTPS는 HTTP 메시지를 TLS를 통해 암호화하여 전송
socket()후connect()까지는 같지만, 이후 TLS Handshake를 통해 인증서 교환 및 키 협상이 추가됨- 이후부터는 애플리케이션 레벨에서는 평문처럼
GET /,Host:등을 보내더라도 실제 전송은 모두 암호화됨 - HTTPS에서는 중간 프록시가 내용 파악 불가 , 캐시 활용도 제한됨
웹 서버(CS:APP 11.5)
웹 기초
웹은 HTTP(Hypertext Transfer Protocol)라는 텍스트 기반 애플리케이션 계층 프로토콜을 통해 클라이언트와 서버가 통신하는 구조다. 클라이언트인 브라우저는 서버와의 인터넷 연결을 열고 콘텐츠를 요청한 뒤, 서버가 응답을 보내고 연결을 종료하면 그 내용을 화면에 출력한다. 이 과정은 매우 단순한 요청-응답 패턴으로 이루어진다.
웹 서비스가 FTP와 같은 전통적인 파일 전송 서비스와 구별되는 가장 큰 특징은, 콘텐츠가 HTML(Hypertext Markup Language)이라는 언어로 작성된다는 점이다. HTML은 텍스트와 그래픽 요소들을 화면에 어떻게 표시할지를 지시하는 태그(tag)로 구성되며, 예를 들어 <b>Make me bold!</b>는 해당 텍스트를 굵게 표시하라는 지시다.
하지만 HTML의 진정한 힘은 문서 안에 하이퍼링크(hyperlink)를 포함할 수 있다는 점에 있다. 하이퍼링크는 인터넷상의 다른 호스트에 있는 콘텐츠를 참조할 수 있게 해준다. 예컨데 <a href="http://www.cmu.edu/index.html">Carnegie Mellon</a>이라는 태그는 'Carnegie Mellon'이라는 텍스트를 강조 표시하며, 사용자가 이를 클릭하면 브라우저는 CMU 서버에 저장된 index.html 파일을 요청하고, 응답을 받아 화면에 표시한다.
웹 컨텐츠
웹 서버와 클라이언트가 주고받는 웹 콘텐츠는 MIME 타입이 명시된 바이트 시퀀스로 구성된다. 서버는 이러한 콘텐츠를 두 가지 방식으로 제공할 수 있다. 첫째, 디스크에 저장된 파일을 그대로 반환하는 정적 콘텐츠(static content) 방식이 있다. 예를 들어 HTML, 이미지, CSS 파일 등이다. 둘째, 실행 가능한 프로그램을 실행한 결과(실행파일이 런타임에 만든 출력)를 반환하는 동적 콘텐츠(dynamic content) 방식이 있으며, 이는 CGI 방식 등으로 서버에서 프로그램을 실행하고 그 출력을 클라이언트에게 전달한다.
각 콘텐츠는 고유한 URL(Uniform Resource Locator)로 식별되며, 이는 서버 주소, 포트, 파일 경로, 그리고 필요시에는 프로그램 인자까지 포함한다. 예를 들어, http://host:port/path/to/file 같은 URL에서 클라이언트는 호스트와 포트를 통해 서버에 접속하고, 서버는 그 뒤의 경로를 해석해 파일을 찾는다. (? 로 파일 이름과 인자를 구분, &로 인자 연결)
서버는 URL의 경로(접미사)를 분석하여 정적 혹은 동적 콘텐츠인지를 판별하는데, 이는 서버마다 다르며 보통 cgi-bin과 같은 특정 디렉토리에 따라 결정된다. 또한 /만 있는 요청은 index.html 같은 기본 파일로 확장되어 처리된다.
HTTP 트랜잭션
HTTP 트랜잭션은 클라이언트와 서버 간의 요청(request)과 응답(response)을 텍스트 기반의 애플리케이션 계층 프로토콜인 HTTP를 통해 주고받는 과정을 말한다. 이 프로토콜은 단순하고 사람이 읽기 쉬운 형식으로, telnet 같은 도구를 통해 수동으로도 요청을 생성해 확인할 수 있다.
// 정적 컨텐츠를 제공하는 HTTP 트랜잭션의 예
1 linux> telnet www.aol.com 80 # 클라이언트가 Telnet 명령어로 AOL 웹 서버(포트 80)에 TCP 연결 시도
2 Trying 205.188.146.23... # Telnet이 도메인명을 IP 주소(IPv4)로 변환하여 접속 시도 중
3 Connected to aol.com. # TCP 연결 성공
4 Escape character is '^]'. # Telnet 세션을 종료할 때 사용할 이스케이프 문자 안내
5 GET / HTTP/1.1 # 요청 라인: 루트 페이지(/)를 요청하는 HTTP/1.1 GET 요청
6 Host: www.aol.com # 필수 요청 헤더: 요청한 호스트 이름 (HTTP/1.1에서 필수)
7 # 빈 줄: 헤더 종료를 나타내며, 본문이 없음을 의미 (GET 요청의 경우 일반적)
8 HTTP/1.0 200 OK # 응답 라인: HTTP/1.0 기반 응답이며, 상태 코드 200은 정상 처리 의미
9 MIME-Version: 1.0 # MIME 버전 정보 (콘텐츠의 형식을 설명하기 위한 사양)
10 Date: Mon, 8 Jan 2010 4:59:42 GMT # 응답이 생성된 시간 (표준 형식, GMT 시간대)
11 Server: Apache-Coyote/1.1 # 서버 소프트웨어 정보 (서버 식별용)
12 Content-Type: text/html # 응답 본문의 MIME 타입 (HTML 문서임을 명시)
13 Content-Length: 42092 # 응답 본문의 바이트 수 (클라이언트는 이 길이만큼 읽으면 됨)
14 # 빈 줄: 응답 헤더 종료를 알림
15 <html> # 응답 본문 시작: HTML 페이지의 첫 줄
16 ... # 생략된 HTML 콘텐츠 (총 766줄)
17 </html> # HTML 문서 종료
18 Connection closed by foreign host. # 서버가 연결을 종료함 (HTTP/1.0은 기본적으로 비지속 연결)
19 linux> # Telnet 클라이언트도 종료됨, 셸로 복귀// 동적 HTML 컨텐츠를 제공하는 HTTP 트랜잭션의 예
1 linux> telnet kittyhawk.cmcl.cs.cmu.edu 8000 # 클라이언트: kittyhawk 서버의 8000번 포트로 TCP 연결 시도
2 Trying 128.2.194.242... # telnet: 해당 호스트의 IP 주소로 DNS 해석 후 접속 시도
3 Connected to kittyhawk.cmcl.cs.cmu.edu. # telnet: 서버와의 TCP 연결이 성공적으로 이루어짐
4 Escape character is ’^]’. # telnet: 연결 중 명령어를 빠져나오는 특수 키 안내
5 GET /cgi-bin/adder?15000&213 HTTP/1.0 # 클라이언트: CGI 프로그램 호출 요청 (파일명과 인자 포함한 GET 요청)
→ URI: /cgi-bin/adder 프로그램을 15000, 213 인자와 함께 실행 요청
6 # 클라이언트: 빈 줄을 통해 요청 헤더 종료 (필수, HTTP 규격상)
7 HTTP/1.0 200 OK # 서버: 정상 처리 응답 (200 상태 코드)
8 Server: Tiny Web Server # 서버: 응답 헤더로 서버 종류 명시 (Tiny 서버 사용 중)
9 Content-length: 115 # CGI 프로그램: 응답 본문의 총 바이트 수 (115바이트)
10 Content-type: text/html # CGI 프로그램: 응답 콘텐츠의 MIME 타입은 HTML
11 # CGI 프로그램: 빈 줄로 응답 헤더 종료 표시
12 Welcome to add.com: THE Internet addition portal. # CGI 프로그램: HTML 본문 시작 – 첫 줄
13 <p>The answer is: 15000 + 213 = 15213 # CGI 프로그램: 실제 계산 결과가 포함된 HTML 문단
14 <p>Thanks for visiting! # CGI 프로그램: 마지막 안내 문구 포함 HTML 문단
15 Connection closed by foreign host. # 서버: CGI 출력 완료 후 연결 종료
16 linux> # 클라이언트: telnet 종료됨, 프롬프트로 돌아감
HTTP 요청은 클라이언트가 서버에 특정 리소스를 요구하기 위해 보내는 메시지로, 요청 라인, 요청 헤더, 그리고 빈 줄로 구성된다. 요청 라인은 보통 GET /index.html HTTP/1.1 형태를 가지며, 여기서 GET은 요청 메서드, /index.html은 요청하려는 리소스의 경로(URI), HTTP/1.1은 사용하는 프로토콜 버전을 의미한다. 이어지는 요청 헤더들은 클라이언트의 브라우저 정보나 허용 가능한 콘텐츠 형식 등을 전달하며, 특히 Host 헤더는 HTTP/1.1에서 필수로 포함되어야 하고, 요청 대상 서버의 도메인 이름을 명시한다. 마지막 빈 줄은 헤더의 끝을 나타내며, 이후에 본문(body)이 따라올 수도 있다. POST 요청의 경우가 바로 이런 예로, 클라이언트가 서버에 데이터를 전송할 필요가 있을 때 사용된다. 예를 들어 로그인 정보나 폼 데이터를 서버로 보낼 때, POST 요청은 요청 본문에 그 데이터를 포함시켜 전송한다. 이때 Content-Type이나 Content-Length 같은 헤더가 함께 사용되어, 본문의 데이터 형식과 길이를 서버에 알린다. 모든 HTTP 요청의 각 줄은 \r\n으로 끝나야 하며, 이는 HTTP 명세에서 정한 필수 형식이다.(\r 커서를 줄의 맨 앞으로 이동시킴, \n 현재 위치에서 줄을 바꿈)
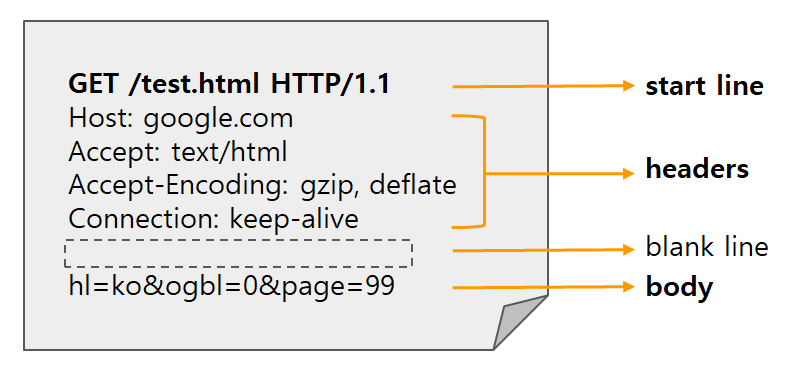
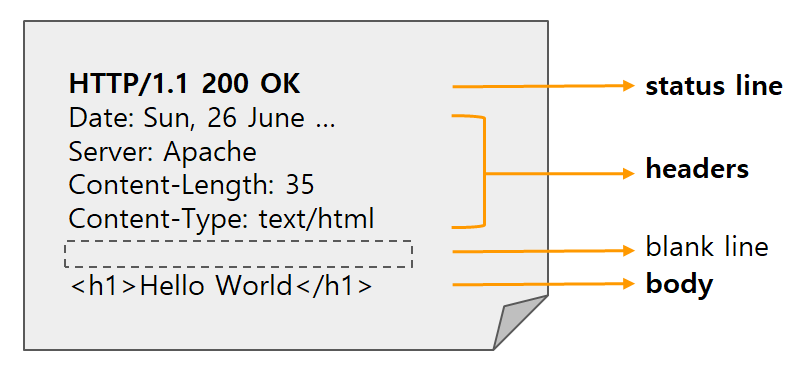
HTTP 응답은 서버가 클라이언트의 요청에 대해 보내는 메시지로, 응답 라인, 응답 헤더, 빈 줄, 응답 본문으로 구성된다. 응답 라인은 예를 들어 HTTP/1.0 200 OK와 같은 형식으로, 서버가 응답하는 HTTP 버전, 상태 코드(예: 200은 성공), 상태 메시지를 포함한다. 응답 헤더는 Content-Type, Content-Length 등의 메타데이터를 담고 있으며, 이는 클라이언트가 응답 내용을 어떻게 해석할지 결정하는 데 도움을 준다. Content-Type은 MIME 타입을 명시하며, Content-Length는 본문의 크기를 바이트 단위로 제공한다. 빈 줄 이후에는 HTML 문서와 같은 실제 콘텐츠가 응답 본문으로 포함되며, 클라이언트는 이를 파싱해 화면에 출력한다. 이와 같은 구조 덕분에 브라우저는 텍스트 기반의 요청과 응답만으로도 웹 페이지를 정확히 렌더링할 수 있다.

동적 컨텐츠의 처리
웹 서버가 동적 콘텐츠를 제공하려면 단순히 파일을 읽어 반환하는 것과는 달리 여러 추가 작업이 필요하다. 클라이언트가 동적 콘텐츠를 요청할 때는, 실행할 프로그램과 인자를 함께 전달해야 하며, 서버는 이 요청을 해석해 프로그램을 실행하고 그 출력을 클라이언트에게 반환해야 한다. 이를 가능하게 해주는 표준이 바로 CGI (Common Gateway Interface) 다.
클라이언트는 GET 요청에서 인자를 URI의 일부로 전달한다. 예를 들어 adder?15000&213 같은 형식에서 ? 뒤가 인자이며, 여러 인자는 &로 구분된다. 공백과 같은 특수문자는 %20 같은 문자열로 인코딩된다.
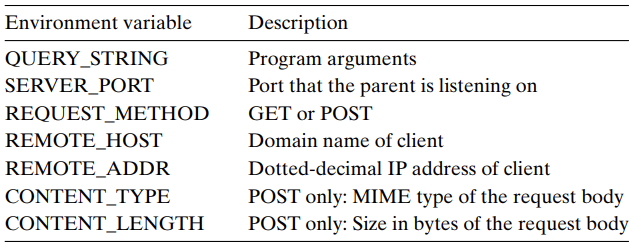
서버는 이 요청을 받아 fork()로 자식 프로세스를 만든 뒤, execve()로 CGI 프로그램을 실행한다. 이때 서버는 QUERY_STRING이라는 환경 변수를 설정하고, 여기에 15000&213처럼 클라이언트가 넘긴 인자를 넣는다. CGI 프로그램은 실행 중에 getenv("QUERY_STRING")처럼 환경 변수에서 이 값을 읽을 수 있다.
CGI는 이 외에도 CGI 프로그램이 알아야 할 정보(요청 메서드, 서버 이름, 사용자 에이전트 등)를 위해 다양한 환경 변수를 정의한다. 예를 들어 REQUEST_METHOD, CONTENT_TYPE, SCRIPT_NAME 등이 있다.
CGI 프로그램의 출력은 표준 출력(stdout)을 통해 클라이언트로 직접 전달된다. 서버는 exec 전에 dup2()를 사용해 자식 프로세스의 stdout을 클라이언트 소켓 디스크립터로 리디렉션한다. 따라서 CGI 프로그램이 printf() 등을 호출하면, 그 출력은 그대로 웹 브라우저에 전달된다.
CGI 프로그램은 반드시 응답 헤더를 스스로 생성해야 한다. 서버는 콘텐츠의 타입이나 길이를 알 수 없기 때문에, CGI 프로그램이 Content-type과 Content-length 같은 HTTP 응답 헤더와 빈 줄을 직접 출력해야 한다. 그 뒤에 본문을 출력하는 구조다. 이는 정적 콘텐츠와 가장 큰 차이점 중 하나다.
Tiny Web Server 구현하기

멋있어요 100님!!