
What is Data Observability? 5 Key Pillars To Know In 2023 에서 발췌한 내용을 아래 정리합니다.
Data Observability tool 에 대해서 알고싶다면 아래 아티클을 참조하세요.
Data Observability 는 데이터의 상태를 완전히 이해하는 조직의 능력이다. Data Observability는 DevOps 에서 학습한 모범 사례를 data pipeline observablity에 적용하여 data downtime 을 제거한다.
- Data Observablity tools
- automated monitoring
- automated root cause analysis
- data lineage
- data health insights to detect, resolve, and prevent data anomalies.
Data downtime — periods of time when data is partial, erroneous, missing, or otherwise inaccurate — only multiplies as data systems become increasingly complex, supporting an endless ecosystem of sources and consumers.
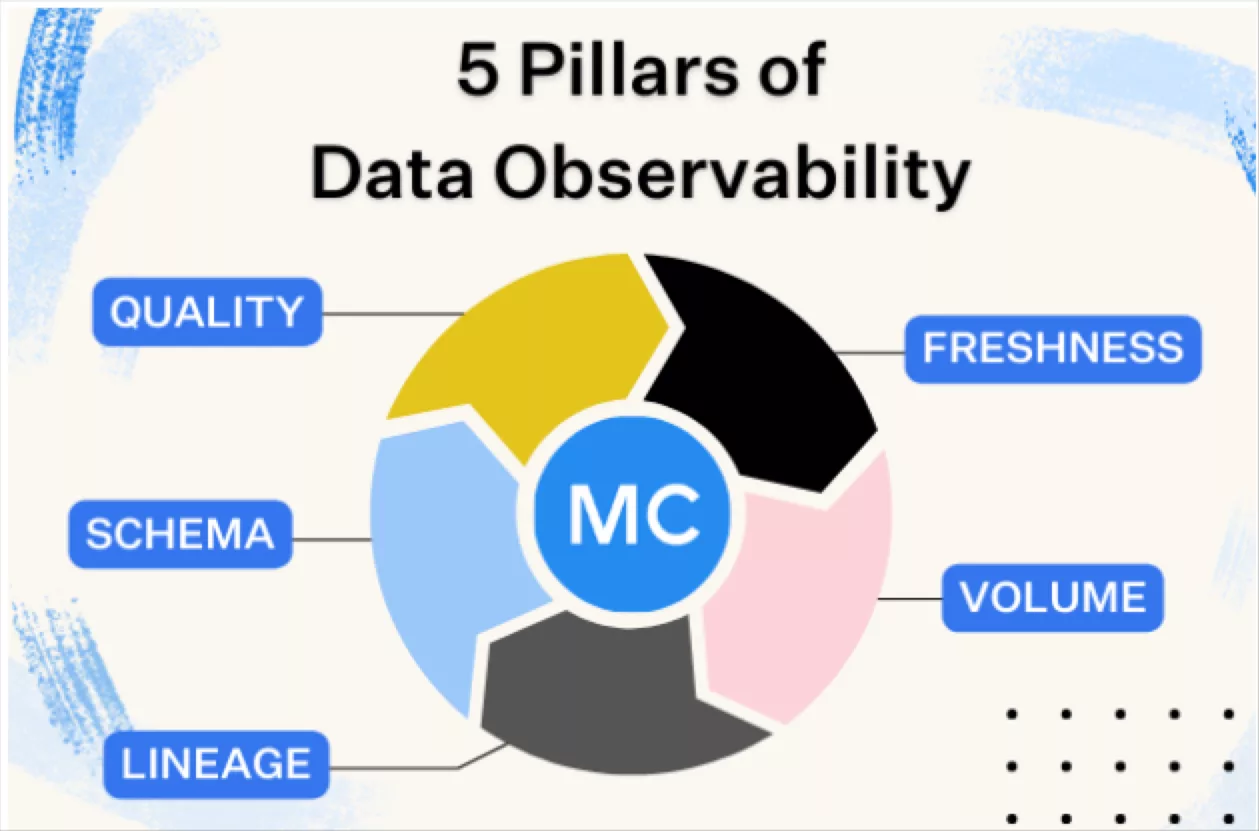
- Freshness
- 데이터 테이블이 얼마나 최신 상태인지, 테이블이 업데이트되는 주기를 이해한다
- Freshness는 의사 결정과 관련해 특히 중요, 결국 오래된 데이터는 기본적으로 시간/비용 낭비
- Quality
- 데이터 파이프라인은 제대로 작동하지만, 그 파이프라인을 통과하는 데이터 흐름이 쓰레기일 수 있다
- Quality 는 데이터 자체와 NULL 의 비율, 고유 비율, 데이터가 허용 범위 내에 있는지 등의 측면
- Quality 는 데이터에서 기대할 수 있는 것을 기반으로 테이블을 신뢰할 수 있는지 여부에 대한 통찰력을 제공
- Volume
- Volume은 테이블의 완전성을 나타내며 데이터 소스의 상태에 대한 통찰력을 제공
- 즉, 2억 행의 로우가 갑자기 500만 행으로 바뀌면 즉시 알아야한다
- Schema
- 스키마의 변경은 종종 깨진 데이터로 나타날 수 있으므로 테이블을 변경하는 사람과 시기를 모니터링하는 것이 데이터 에코시스템의 상태를 이해하는데 기본이 된다
- Lineage
- 데이터가 깨지면 "어디에서?" 라는 질문이 첫번째이다
- Data Lineage 는 어떤 업스트림 소스와 다운스트림 수집기가 영향을 받았는지, 데이터를 생성하는 팀과 데이터에 접근하는 사람을 알려줌으로서 답을 제공
Data observability is as essential to DataOps as observability is to DevOps
조직이 성장하고 조직을 지원하는 기본 기술 스택이 더욱 복잡해짐에 따라(moving from a monolith to a microservices architecture), 소프트웨어 엔지니어링 부서의 DevOps 팀이 시스템 상태에 대한 지속적인 펄스를 유지하고 CI/CD 접근 방식을 배포하는 것이 중요해졌다.
소프트웨어 엔지니어링 어휘에 가장 최근에 추가된 Observability는 이러한 필요성을 말하며 소프트웨어 애플리케이션 중단 시간을 방지하기 위한 모니터링, 추적 및 분류를 나타낸다.
데이터 엔지니어링 팀은 ETL 파이프라인을 모니터링하고 데이터 시스템 전체에서 데이터 downtime 위해 유사한 프로세스와 도구가 필요했다.
Why is data observability important?
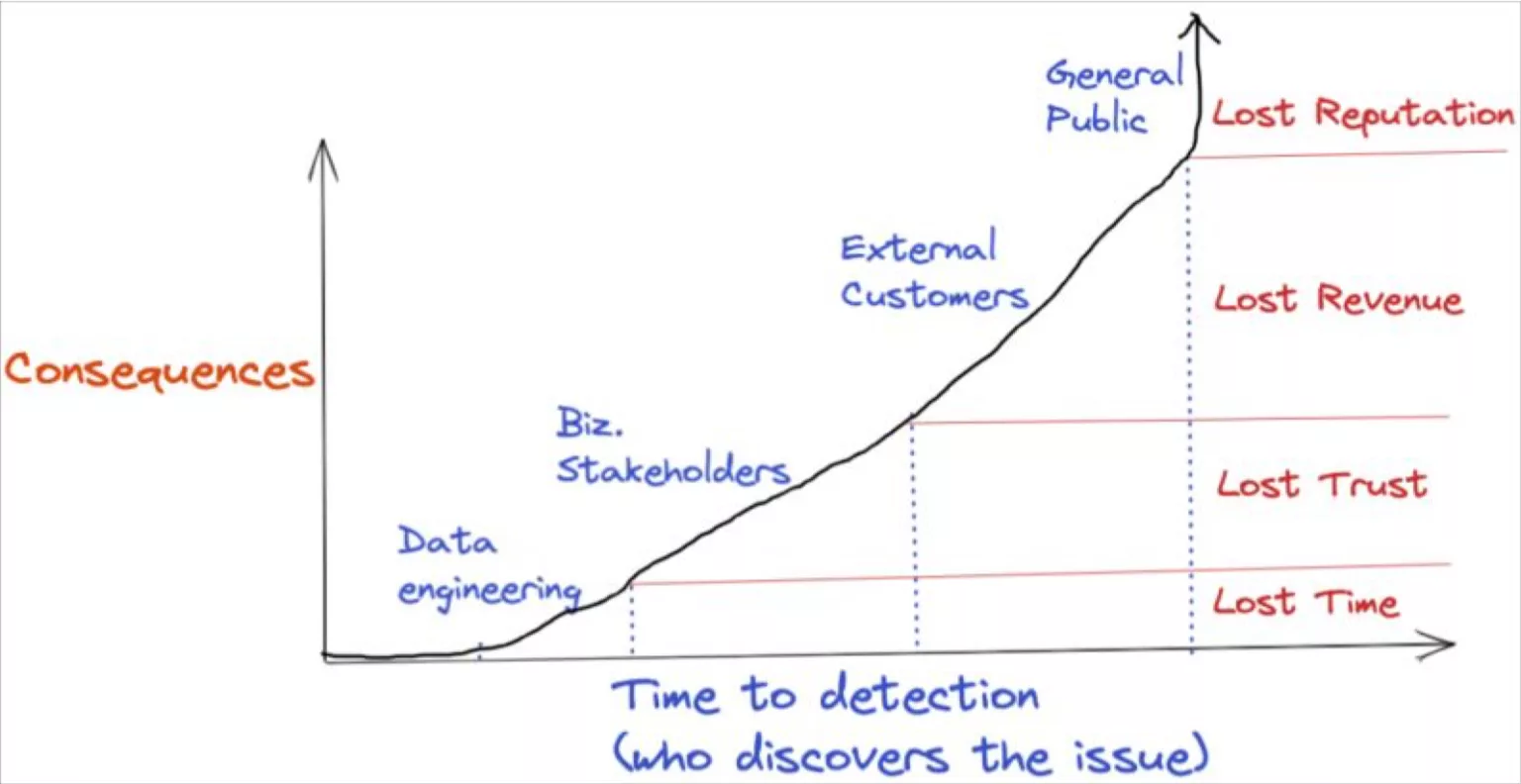
데이터 엔지니어와 개발자에게는 data downtime 시간이 시간과 리소스 낭비를 의미하기 때문에 Data Observability가 중요하다. 데이터 소비자의 경우, data downtime이 의사 결정에 대한 자신감을 떨어트리게한다.
그런 의미에서 데이터 파이프라인 모니터링 및 Data Observablity의 가치는 정말 귀중하다.
The key features of data observability tools
Data observability tool 은 보통 아래와 같은 기능을 제공한다.
- 기계 학습 모델을 사용하여 환경과 데이터를 자동으로 학습
- anomaly detection 을 사용하여 문제가 발생할 때 알려줌
- 개별 Metric 뿐만 아니라 데이터에 대한 전체적인 보기와 특정 문제의 잠재적 영향을 고려
- 풍부한 컨텍스트 제공
- 데이터 안정성의 문제를 받는 이해 관계자와의 효과적인 커뮤니케이션 제공
- Data observability tools shouldn’t stop at “field X in table Y has values lower than Z today.”
- 선제적으로 변경 및 수정이 이루어질 수 있도록 데이터에 대한 풍부한 정보를 노출하여 처음부터 문제가 발생하 않도록 합니다.
Data observability vs. data testing
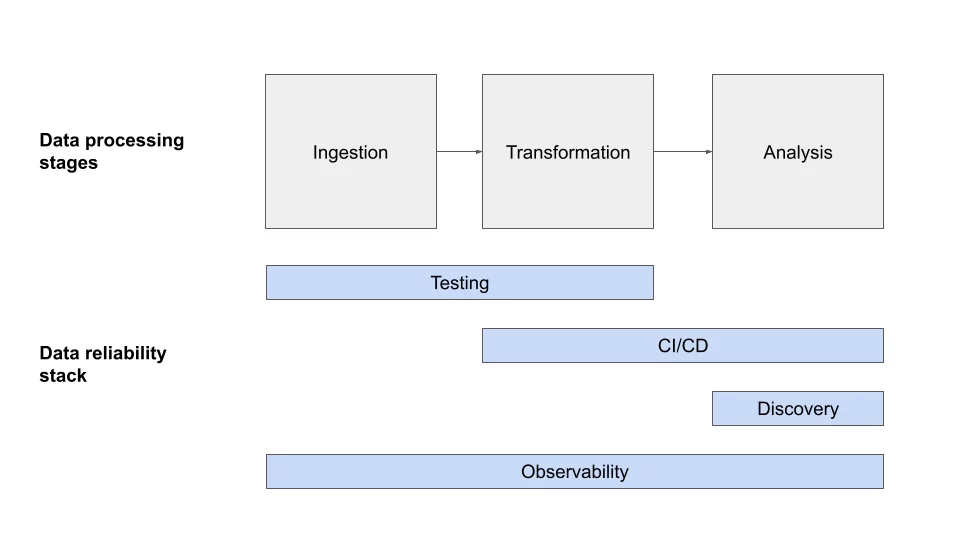
소프트웨어 엔지니어가 unit test 를 사용하여 버그가 있는 코드를 프로덕션으로 푸시하기 전에 식별하는 것과 유사하게 데이터 엔지니어도 종종 테스트를 활용하여 잠재적인 Data Quality 문제가 다운스트림으로 이동하는 것을 감지하고 방지한다.
이 접근 방식은 실현 불가능한 너무 많은 데이터를 수집하기 전까지는 (대부분) 괜찮지만, 엄격한 테스트 체제에도 불구하고 일관된 data quality 문제를 겪는 수많은 데이터 팀을 만날 수 있다.
최고의 테스트 프로세스조차 불충분한 이유는 예측할 수 있는 것(known unknowns)와 예측할 수 없는 것(unknown unknowns)의 두 가지 유형의 데이터 품질 문제가 있기 때문이다.
일부 팀은 대부분의 예측할 수 있는 부분을 다루기 위해 수백개의 테스틑 실시하지만 예측할 수 없는 부분을 다루는 효과적인 방법이 없다. Data Observablity가 적용되는 예측할 수 없는 부분의 몇 가지 예는 다음과 같다.
- 하룻밤 사이에 5만개의 로우를 50만개로 바꾸는 JSON 스키마에 대한 우발적인 변경
- ETL 에 의도하지 않은 변경이 발생하여 일부 테스트가 실행되지 않아 며칠 동안 눈에 띄지 않음
- 현재 비즈니스 로직을 반영하도록 최근에 업데이트되지않은 테스트
“For example, if the null percentage on a certain column is anomalous, this might be a proxy of a deeper issue that is more difficult to anticipate and test.”
Data observability vs. data monitoring

데이터 자체를 모니터링하는 것은 ML 뿐만 아니라 사용자 지정 룰에 따라 할 수 있다.
하지만 우리는 data quality 자체를 모니터링 할 필요가 있다. 그 이유는 데이터 파이프라인이 정상적으로 동작해도 데이터 자체가 쓰레기일 수 있기 때문이다.
For example, the data values may be outside the normal historical range or there could be anomalies present in the NULL rates or percent uniques. Monitoring the data itself can be done automatically with machine learning as well as by setting custom rules, for example if you know a monetary conversion rate can never be negative.
Data observability vs Data quality
Data observability 는 data quality 를 가능하게 하고 향상시킵니다. Data quality는 보통 accuracy, completeness, consistency, timeliness, validity, uniqueness 6가지 차원으로 표현된다.
Data observability Solution 을 사용하면 데이터 팀은 더 높은 Data quality 를 보장할 수 있다.
Data quality vs data reliability
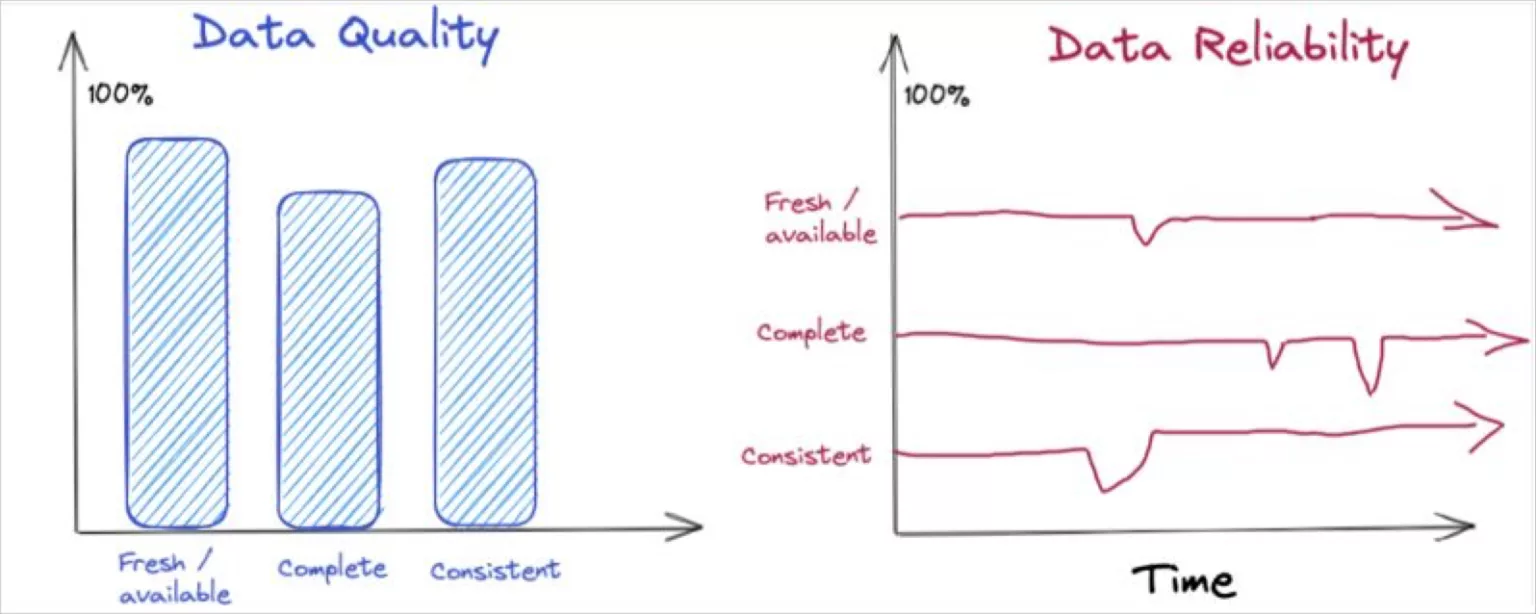
Data quality 를 해결하려면 특정 시점을 넘어서 생각하고 다양한 실제 조건에서 시간이 지남에 따라 Quality가 어떻게 변하는지 고려해야한다. 그게 진정한 Data Reliability 라고 볼 수 있다.
신뢰할 수 있으려면 휴일 트래픽 급중 및 제품 출시 기간 동안 시간에 지남에 따라 이러한 품질을 유지할 수 있어야한다. 신뢰도를 해결할 때, 단순히 데이터 품질(시간과 공간의 한 지점)을 측정해서는 안된다. 이 뿐만 아니라 예상되는 수준의 품질 및 서비스를 설정하고 데이터 품질을 신속하게 진단할 수 있어야한다.
