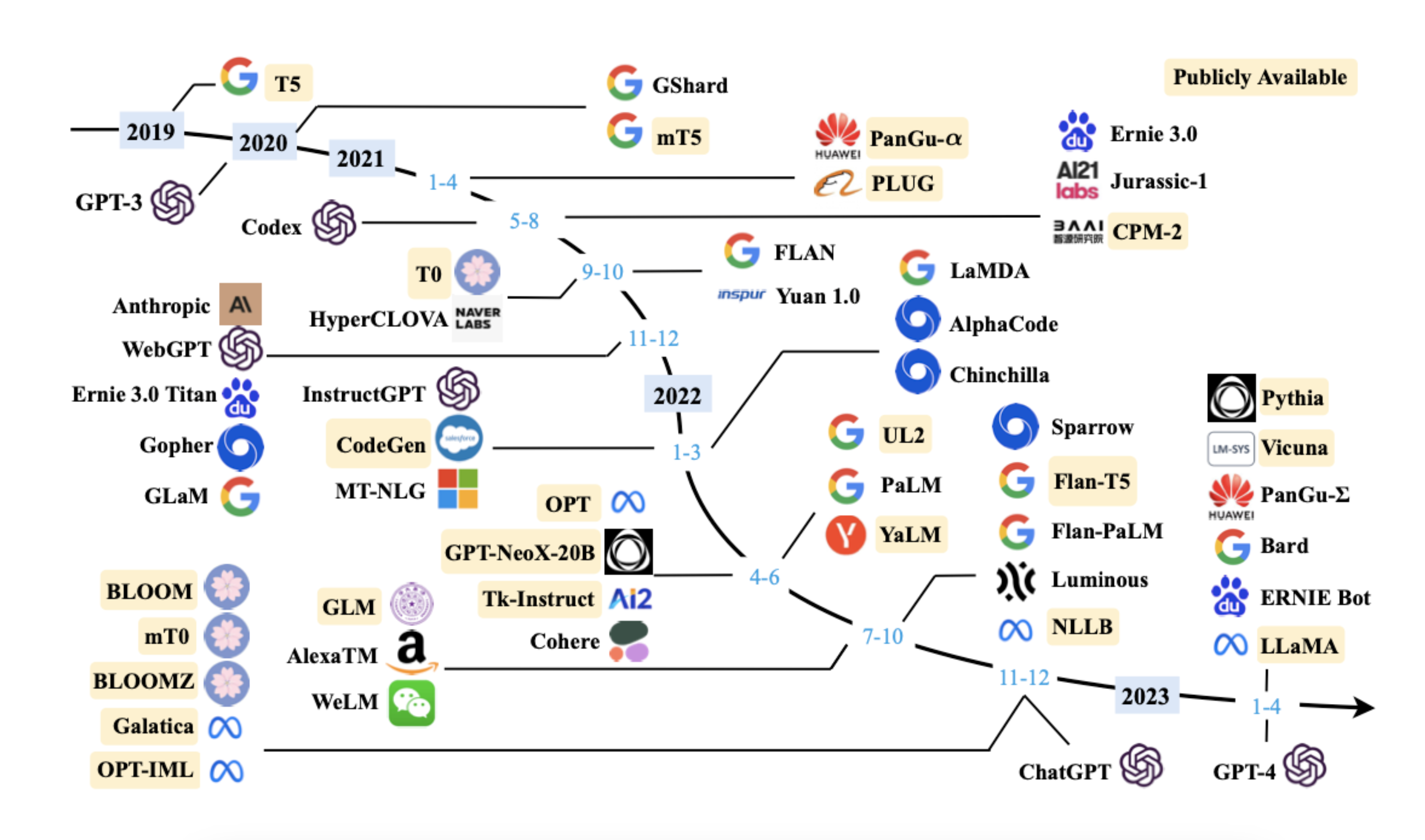
ChatGPT 를 시작으로 많은 LLM 들이 탄생하고 있다.
그 중에서도 오늘은 Open source LLM 을 다뤄보려한다.
LLaMa(Large Language Model Meta AI)
LLaMa 는 Meta AI 에서 공개한 LLM 이다.
알파카(Alpaca),비큐냐(Vicuna)등의 파생형 모델들의 탄생들에 기여- 폐쇄형 소스 모델의 적절한 대체재
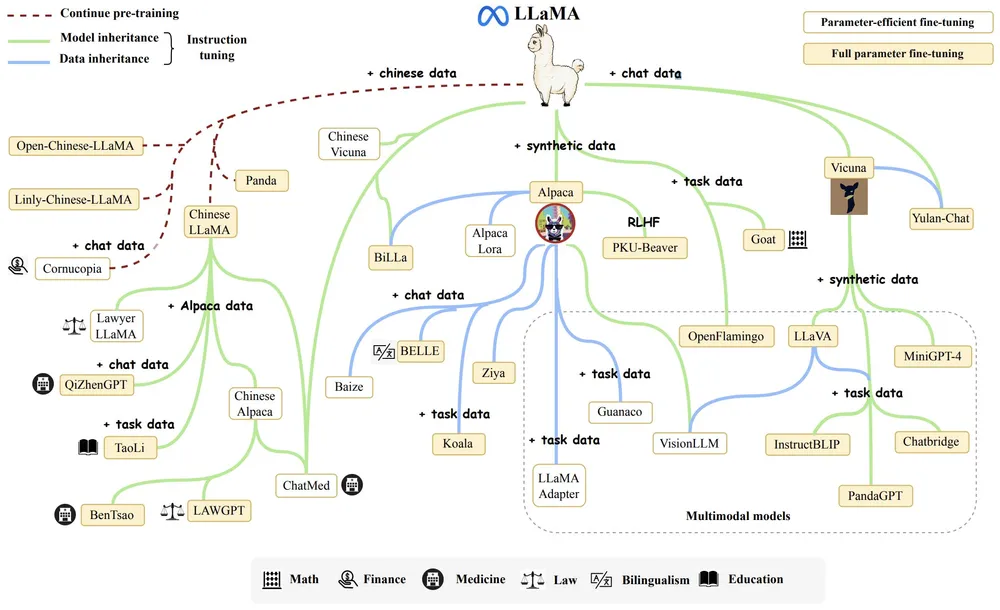
최근 구글의 최대의 경쟁자는 OpenAI가 아닌 오픈소스 AI라고 주장하는 구글 내부 문서가 공개 유출되었다. 문서 중에 일부를 발췌했는데, 아래와 같다고 합니다. 비슷한 이유로 관련 종사자들이 Open source LLM 에 열광하는 이유가 아닐까 생각이 듭니다.
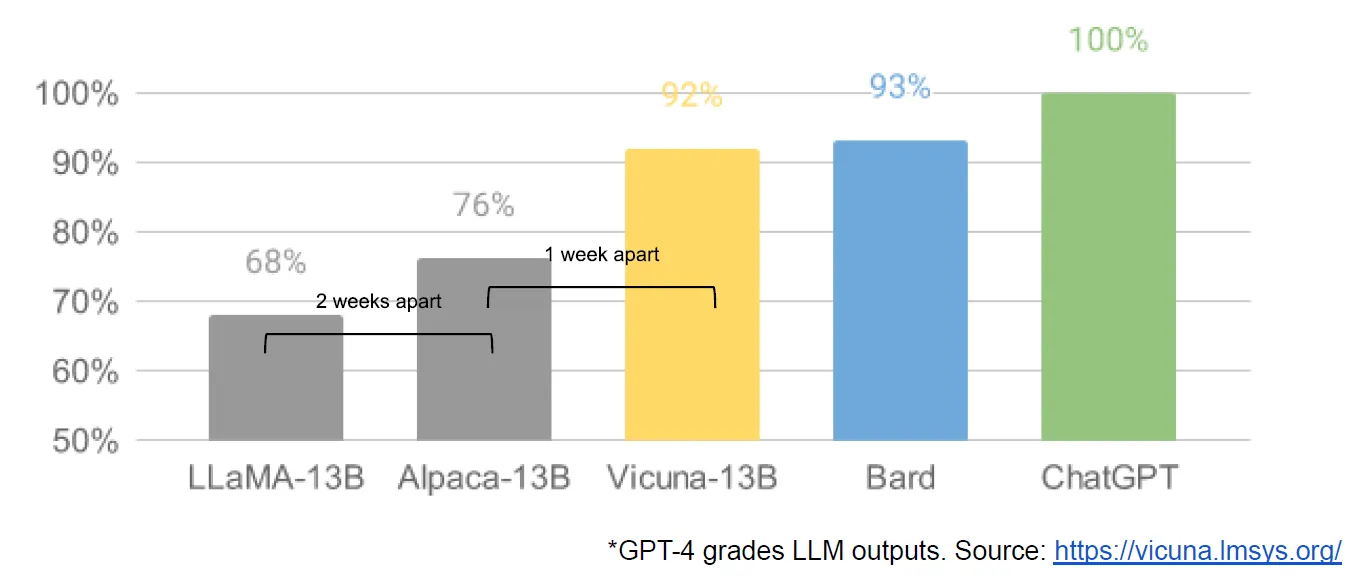
이와 같은 주장의 배경에는 Meta의 LLaMA가 한정적인 researcher들에게 공개된 후, 마치 캄브리아기 대폭발을 연상시키듯 LLaMA를 기반한 오픈소스 AI 모델들이 탄생하고 있기 때문이다. 유출된 구글 내부 문건은 Vicuna-13B의 결과를 인용하면서 LLaMA-13B 기반 Vicuna-13B가 구글의 Bard와 거의 차이가 없는 성능 결과를 보이며, 더 작은 비용과 파라미터로 이를 달성하고 있다는 점을 지적하고 있다.
2023년 7월에 LLaMa 2 가 공개되었다.
기존에 연구용 목적으로 한정적으로 오픈했던 LLaMa 와 달리 연구/상업적 용도로 모두 무료이다.
- Meta and Microsoft Introduce the Next Generation of Llama
- https://labs.perplexity.ai/ 에서 Llama 2 를 Chat 으로 사용해볼 수 있다.
- 특징
- 공개된 데이터셋에 대해서만 학습
- llama 2 는 연구 또는 상업적 용도로 무료 (오픈소스)
- 하이퍼 파라미터 규모에 따른 3가지 모델 제공
- Chat Llama / Code Llama / Llama Guard
- 사용방법
- https://ai.meta.com/llama/ 에 접속하여 모델 Access 신청
- llama github 에서 직접 모델을 다운로드 하거나 Hugging Face 를 통해서 접근이 가능하다.
- Hugging Face 를 통한 접근은 Meta 에서 모델 Access 를 신청할 때, Hugging Face 와 동일한 이메일로 신청을 해야한다.
- Llama 2 is here - get it on Hugging Face
Parameter Efficient Fine-Tuning(PEFT)
PEFT 이란 결국 Fine-Tuning 방식이며 아래와 같은 특징을 가진다.
- 모델의 모든 파라미터를 튜닝하는 것이 아닌 일부 파라미터만을 튜닝
- 모델의 성능을 적은 자원으로도 높게 유지하는 방법론
- 적은양 파라미터(예를 들면 0.01%)를 학습함으로써 빠른 시간 내에 새로운 문제를 거의 비슷한 성능으로 풀 수 있게 하자는게 주된 목표
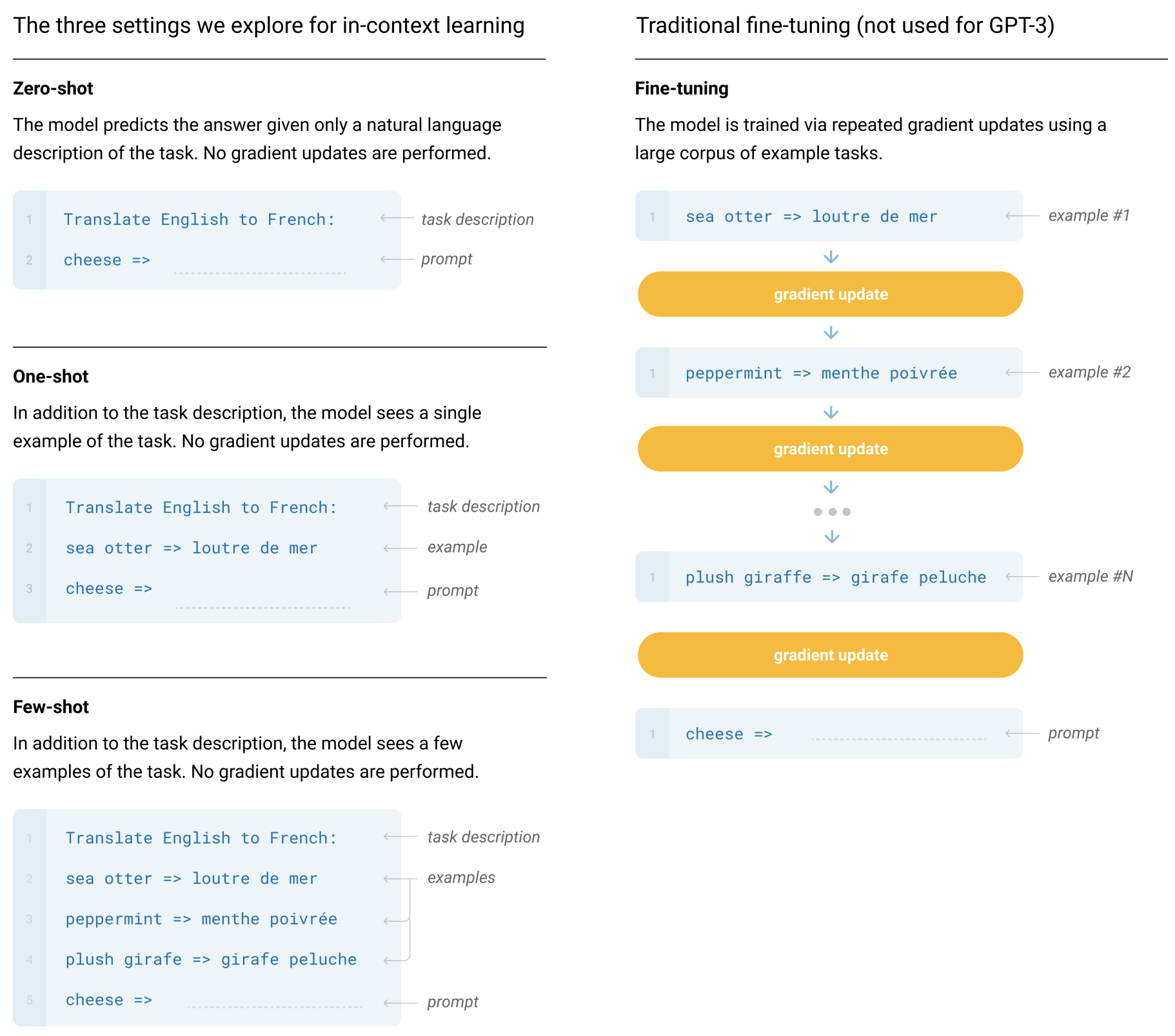
위와 같이 ICL (In-Context Learing) 으로 모델을 튜닝할 필요없이 몇 가지 예제만 넣어주면 쉽게 풀고자하는 문제를 풀 수 있게 되지만, 아래와 같은 단점들을 보완하는 대안적인 패러다임중 하나라고 생각하면 됩니다.
- 매번 미리 예제를 넣기때문에 계산비용, 메모리비용, 저장비용 발생
- 어떤 연구에서는 incorrect labels 을 예제로 넣어줘도 잘 동작하기때문에 ICL 결과를 신뢰하기 힘들다. 라는 연구도 있었음
현재 PEFT 방법론 중에 가장 유명한 방법론이 LoRA 입니다. 해당 방법론을 개선한 다른 방법론들 (IA3 등등..) 도 현재 계속 나오고 있는 중인데, 오늘은 LoRA 만 보고 넘어가겠습니다.
PEFT: LoRA (Low-Rank Adaptation)
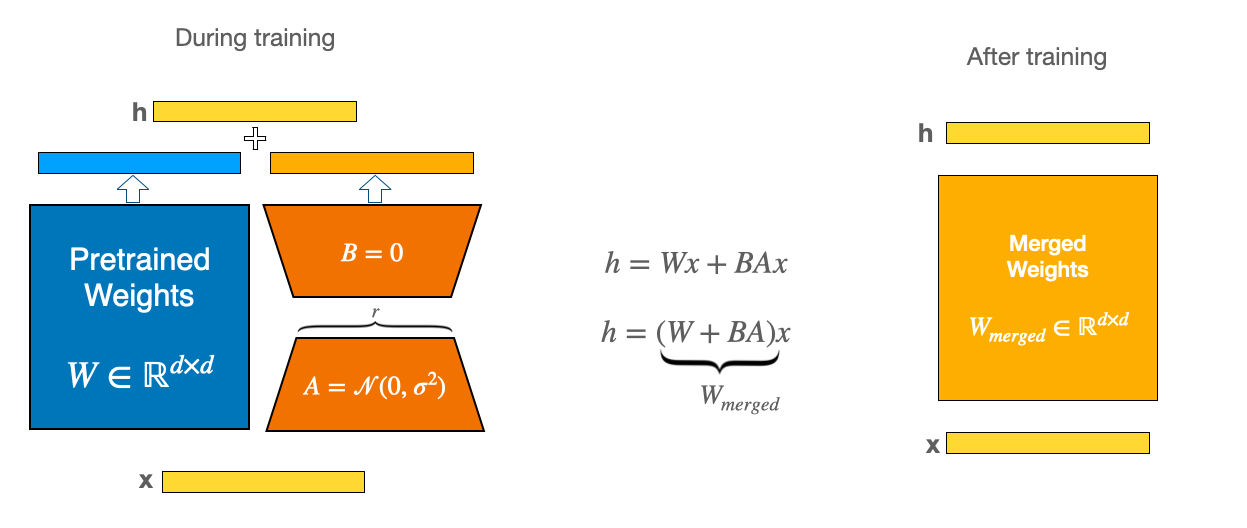
- 적은 양의 파라미터로 모델을 튜닝하는 방법론이기 때문에 적은수의 GPU로 빠르게 튜닝할 수 있다는 장점
아래와 같이 Hugging Face 에서 공개한 PEFT 라이브러리를 통해 쉽게 적용할 수 있습니다.
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282Alpaca
- Alpaca: A Strong, Replicable Instruction-Following Model
- https://github.com/tatsu-lab/stanford_alpaca
- 스탠퍼드 대학의 CRFM (Center for Research Foundation Models)는 학술 연구 목적으로 Meta의 LLaMA-7B 모델을 finetuning한 Alpaca라는 모델을 공개했다.
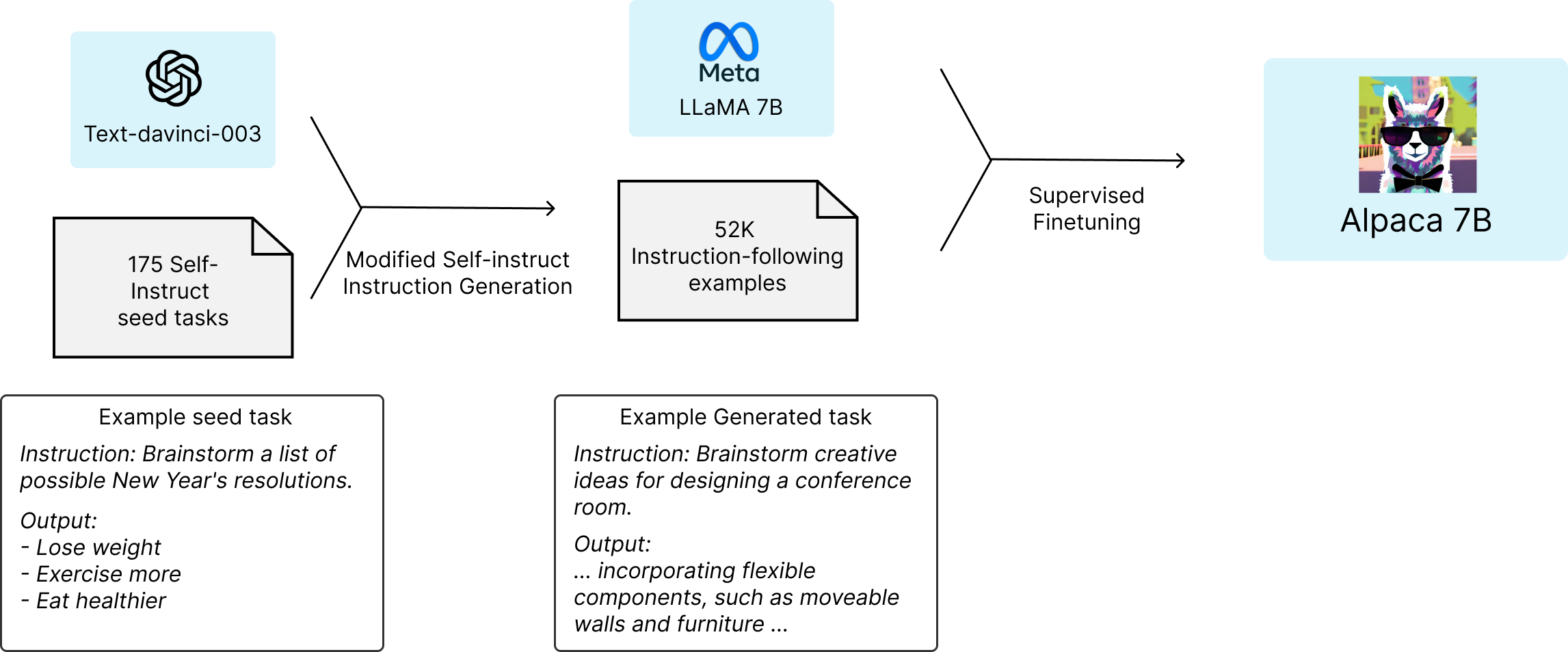
- pretrained language model : LLaMa 7B
- high-quality instruction-following data
- self-instruct 를 시드로 GPT-3.5(text-davinci-003) 에게 ICL 로 전달하여 instructions 을 생성하도록 함 (self-instruction)
기존 Alpaca 의 경우, fine tuning 을 하기위해 요구되는 리소스 문제로 해당 문제를 우회하고자 LoRA 를 사용하는 개발이 진행되고 있다. 저자는 아래 글을 참고했다.
Vicuna
Google 이 언급한 Vicuna 도 LLaMa 에서 파생된 LLM 이다.
Vicuna-13B는 Meta의 LLaMA와 Stanford의 Alpaca에 영감을 받아 UC Berkeley, UCSD, CMU, MBZUAI(Mohamed Bin Zayed Univ. of AI)가 공동으로 개발한 오픈소스 챗봇으로 ShardGPT로 부터 수집된 사용자들의 대화로 LLaMA를 fine-tuning한 모델- ShardGPT : 사용자 프롬프트와 ChatGPT의 해당 답변 결과를 서로 공유할 수 있는 웹사이트
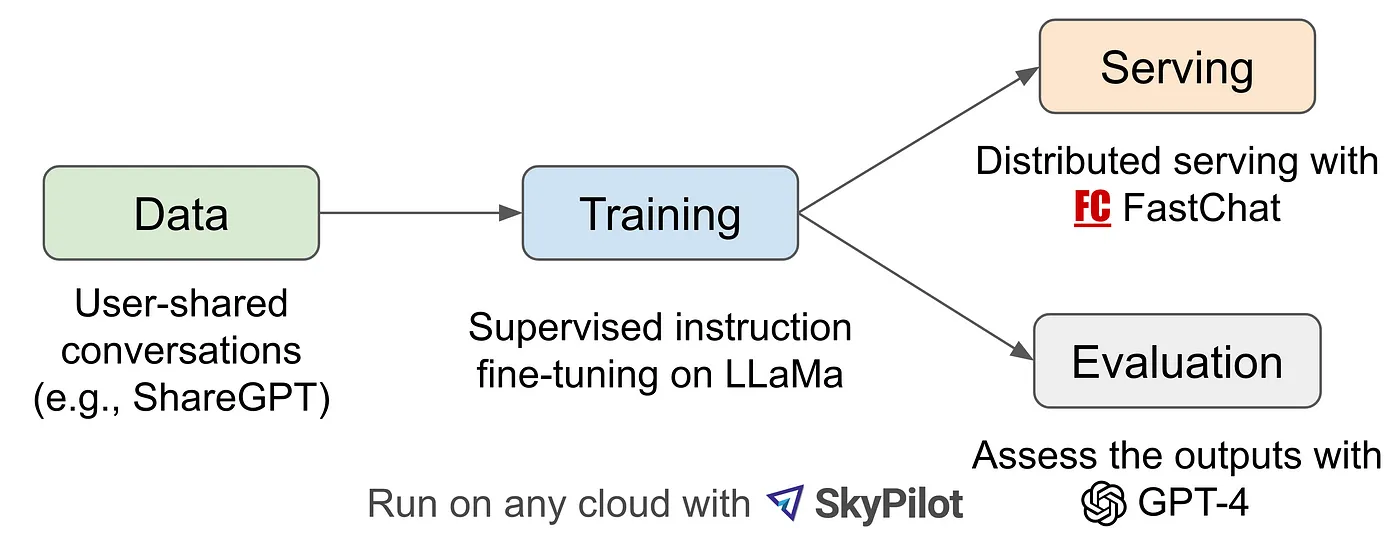
- pretrained language model : LLaMa 2
- high-quality instruction-following data : ShareGPT
FastChat 에서 오픈소스로 사용할 수 있으며 Hugging Face 에서도 접근이 가능하다.
기타
Open source LLM 관련 벤치마크를 확인하기위해 아래를 참고할 수 있다.
- LLM을 위한 벤치마크 플랫폼인 Chatbot Arena
- https://arena.lmsys.org/ 에서 확인 가능
- https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard 투표 결과는 여기서 확인 가능
- https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- https://llm-leaderboard.streamlit.app/
