
Application Layer
- application layer가 새로운 응용 계층을 만들 가능성이 있기 때문에 실용적이고 중요
24.1 Client-Server Model
Iterative server
- 같은 일을 반복처리 하는 서버
Request Queue
+-----------------+
| | | | ...
+-----------------+- queue에서 한 번에 하나씩 request를 꺼내서 처리
- 매우 간단히 구현 가능
- 무한 Loop를 돌며 계속 서비스함
- 요청이 오기 전까지 멈춰서 기다리다가 요청이 오면 accept 해서 처리하고 다음 요청까지 또 기다림
사용
- 하나의 request를 금방 처리 가능한 경우 적합
ex) Time 계산, echo - 하지만 request 처리가 오래 걸리면 다른 요청 처리가 느려짐 → 병렬처리 필요
- TCP 같은 방식으로 오면 처리 시간이 오래 걸림
Concurrent Server
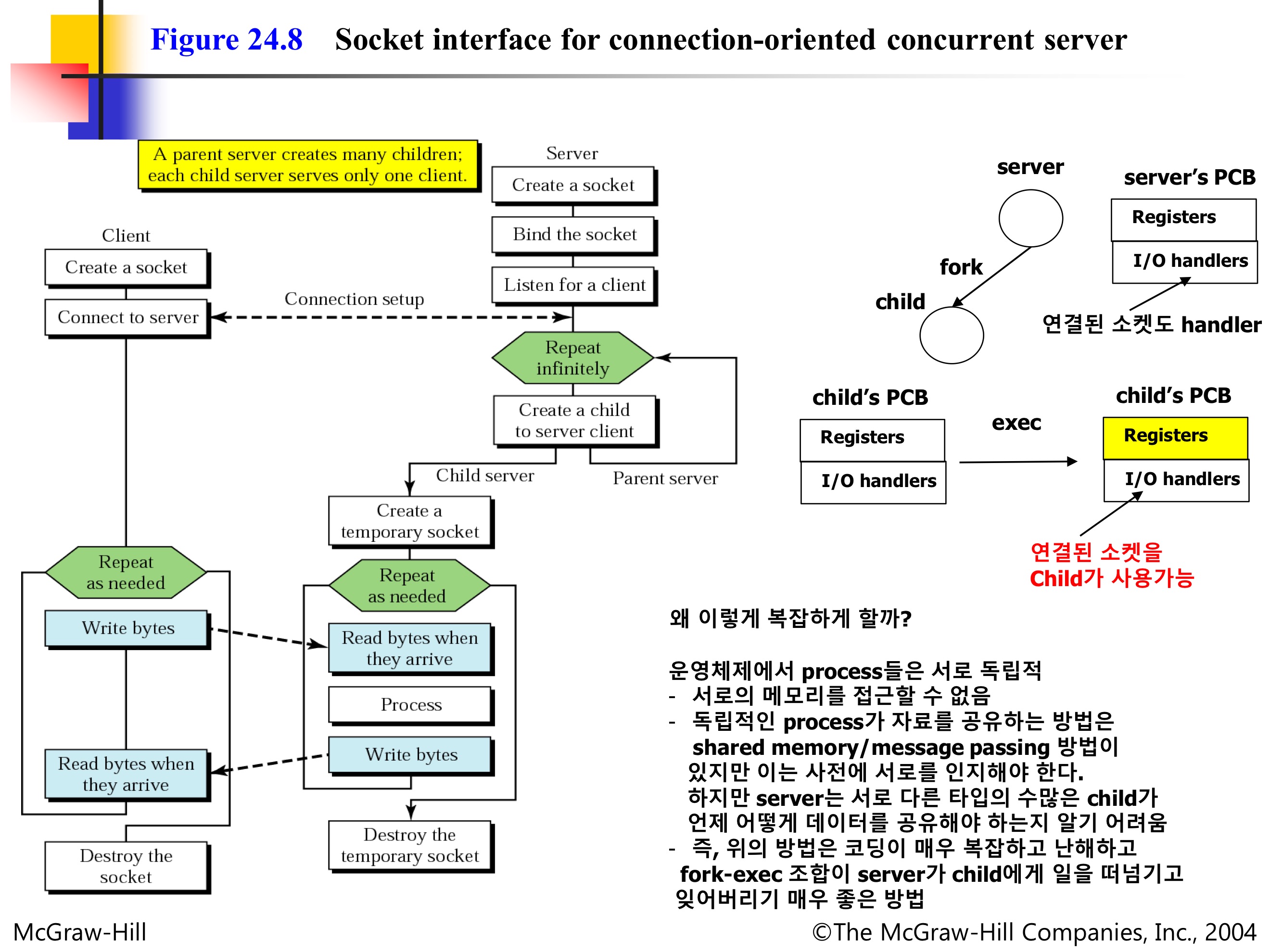
1. Process-based Concurrent Server
기본 동작 원리
- 클라이언트 요청이 올 때마다 새로운 서버 프로세스를 생성
- 각 클라이언트마다 별도의 자식 프로세스가 담당
- 서버 프로세스는 즉시 다음 요청을 받기 위해 루프로 돌아감
- 여러 클라이언트가 동시에 처리되어 전체 서비스 시간이 크게 단축됨
장점
- 예시: 각 요청이 3초씩 걸리는 작업 4개가 있을 때
- Iterative 방식: 3+6+9+12 = 총 12초 소요
- Concurrent 방식: 동시 처리로 약 5초 안에 완료
프로세스 간 데이터 공유 문제
- 프로세스들은 서로 독립성을 유지해야 하며 메모리를 직접 공유할 수 없음
- 프로세스 간 데이터를 주고 받기 위해서는 Shared memory나 Message passing 방식을 사용해야 함
- 소켓 같은 시스템 리소스를 새로운 프로세스에 전달해야 하는 문제 발생
기존 IPC 방식의 한계
- Shared Memory나 Message Passing 방식은 사전에 협의하여 설계해야 함
- 클라이언트-서버는 독립적으로 개발되므로 이런 방식 적용 불가능
즉, 새로운 프로세스를 생성할 때
fork()시스템 콜을 사용하여 이러한 문제를 해결
fork()의 특징
- 기존 프로세스(부모)의 완전한 복사본(자식)을 생성
- 부모-자식 관계가 성립하여 리소스 공유가 가능
- fork() 호출 시 부모는 자식 PID를, 자식은 0을 반환받음
exec()호출 시 프로세스의 모든 코드(text)와 데이터가 손실되고 새로운 프로그램의 실행파일로 교체됨
의문점
fork()를 통해 생성된 프로세스는 서로 같기 때문에, 프로세스가 다른 기능을 하게 하려면exec()를 통해 실행 파일을 엎어야 함- 어차피 실행 파일을 엎을 거면 애초에 그냥 새로운 실행파일로 프로세스를 직접 생성하는 것이 더 효율적일 것 같은데, 왜 굳이
fork()로 복사한 후exec()로 덮어쓰는 방식을 사용하는가?
fork + exec 조합을 사용하는 이유
- fork()를 하면 부모 프로세스의 자원을 자식 프로세스가 그대로 사용할 수 있기 때문
- 기존 프로세스 조작 API를 그대로 사용하여 자식 프로세스 환경 설정 가능
- 자식 프로세스 설정을 위한 별도 API 군이 불필요
- 부모 프로세스가 더 이상 필요 없는 경우 exec만 단독 사용 가능
- 같은 실행파일의 추가 프로세스가 필요한 경우 fork만 사용 가능
이러한 유연성 때문에 fork + exec 조합이 UNIX 시스템의 표준 방식으로 자리 잡음
Process-based Concurrent Server의 한계
- 동시에 많은 요청이 오면 그만큼 많은 프로세스가 생김
ex) 동시 요청 500개 → 최대 500개 프로세스 생성- Context Switching 오버헤드가 매우 큼 -> 성능 저하 발생
- 즉, 대규모의 동시 접속자 처리 불가능
- 이를 해결하기 위해 멀티 스레드 컨셉 등장
2. Multi-threaded Server
Thread의 정의
- Thread of Execution (실행의 실)
- 코드 실행 흐름을 실처럼 표현한 개념
특징
- 스레드는 스택 영역만 새로 만들고, 코드, 데이터, 힙 영역은 공유함
- 요청이 올 때마다 프로세스를 생성하는 방식은 성능 저하 문제가 있기 때문에,
create_thread()를 통해 스레드를 새로 생성하는 방식을 사용 - 즉, 요즘에는 멀티 스레드 방식의 서버를 주로 사용
대규모 요청 처리
- 100만명 같이 대규모의 요청을 처리하기 위해서는 멀티스레드 서버를 대량 배치해야 함
- 각 서버마다 IP 주소가 다름
단일 진입점의 필요성
- 사용자에게 "서버 1번, 2번, 3번 중 선택하세요"라고 할 수 없음
- 유저 입장에서는 주소를 하나의 가상 서버를 제공해야 함
- ex) www.naver.com처럼 하나의 주소로만 접근하는 것
- 클러스터를 통해 지리적으로 한 군데의 일을 하나의 곳에서 처리되도록 구현
클러스터 방식
클러스터 개념
- 지리적으로 한 군데 모아서 하나의 일을 처리하도록 구성한 서버 집합
- "글로벌 금융 허브 클러스터"처럼 집중화된 서비스 제공
클러스터의 장점
- 가용성: 하나의 노드가 고장나도 시스템 지속 동작
- 확장성: 필요에 따라 노드 추가 가능
- 부하 분산: 작업을 여러 노드로 분산
로드 밸런서 (Load Balancer) 구조
로드 밸런서의 역할
- www.naver.com 주소를 가진 단일 서버가 프론트에 위치
- 실제 처리는 하지 않고 요청을 뒤쪽 서버들에 분배만 함
- L4 스위치(Layer 4 Switch) 역할 수행
L4 스위치 특징
- TCP/UDP 헤더를 분석하여 적절한 서버로 라우팅
- IP와 포트 정보를 보고 스위칭 수행
- 보안 및 필터링 목적으로도 활용
데이터베이스 분리 구조
데이터 동기화 문제
- 각 서버가 개별 DB를 가지면 재고 관리 등에서 동기화 문제 발생
- 한 서버에서 상품 구매 시 모든 서버의 DB를 업데이트해야 함
백엔드/프론트엔드 분리 해결책
- 데이터베이스 전용 백엔드 서버를 별도 구성
- 프론트엔드 서버들은 백엔드에서 로우 데이터만 받음
- 프론트엔드에서 UI 가공 및 렌더링 처리
탄력적 확장 (Elastic Scaling)
수요 대응 확장
- 크리스마스 시즌: 서버 수를 1000개, 2000개, 5000개, 10000개까지 증가
- 시즌 종료 후: 수요 감소에 따라 서버 수 축소
- 가상화 및 클라우드 기술을 활용한 동적 리소스 관리
현대적 구현
- 컨테이너 기반 오케스트레이션으로 서버 인스턴스 관리
- 스레드 풀 방식으로 효율적인 리소스 활용
- 클라우드 인프라를 통한 자동 스케일링
24.2 Socket Interface
- Burkley 대학에서 socket 라이브러리를 만듦
- 표준화 종류는 1. 공식적으로 표준, 2. 비공식적 표준이 있는데 이는 비공식적 표준으로 널리 쓰임
- 점차 Socket 라이브러리가 다양해짐
- 기존 socket은 C언어로 구현되었는데 소켓 라이브러리가 객체지향 패러다임을 따라가게 되면서, 각 언어에 따른 다양한 형태의 소켓 라이브러리가 등장
Socket types
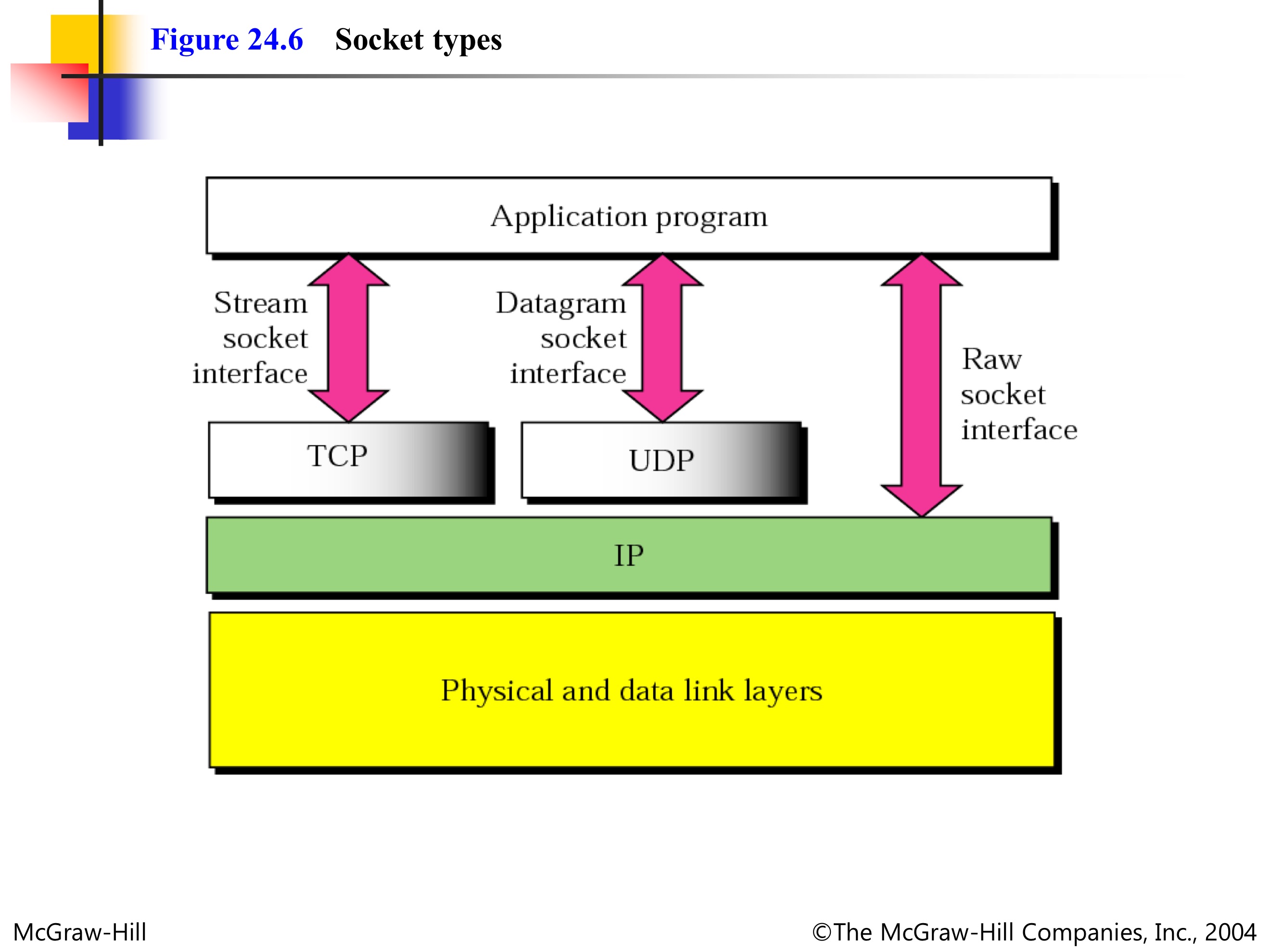
- Stream socket interface 라이브러리를 사용하면 TCP 통신
- Datagram socket interface 라이브러리를 사용하면 UDP 통신
Socket Structure
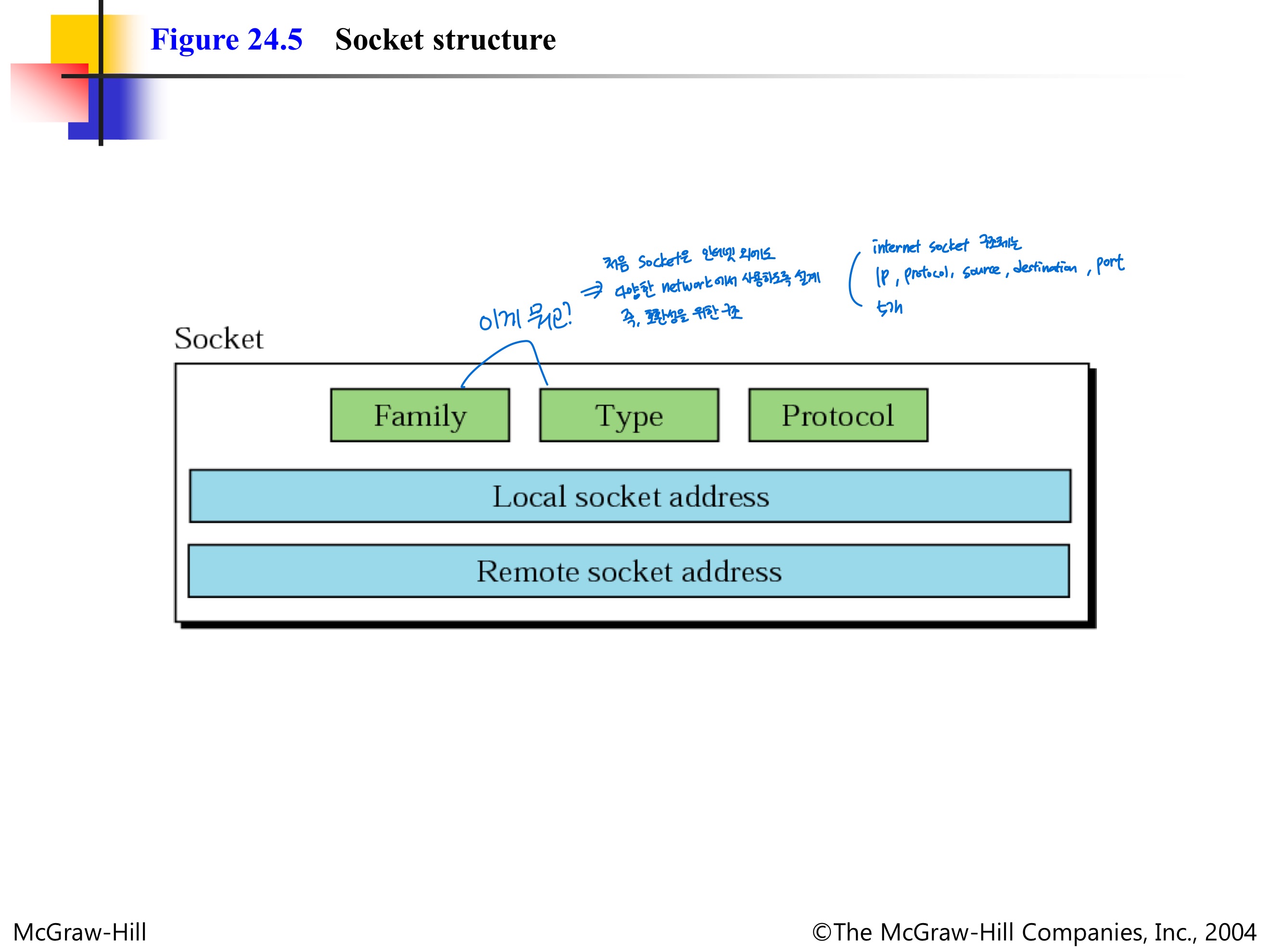
- Socket은 다음 5가지로 구성됨
- Family
- Type
- Protocol
- Local socket address
- Remote socket address
- socket은 인터넷 외에도 다양한 network에서 사용하도록 설계됨
즉, 호환성을 위한 구조
- Internet socket 구조체는 다음 5가지로 구성됨
- Protocol, Source IP, Source Port, Destination IP, Destination Port
